
Fungible is changing the way storage platforms are designed by removing limitations of existing storage architectures with the release of the Fungible Storage Cluster, FSC 1600 high-performance storage node. The Fungible Storage Cluster delivers a high-performance, low latency NVMe/TCP disaggregated storage solution that is fully transparent to high-level applications. Powered by the Fungible DPU™, the Fungible Storage Cluster (FSC) is a high-performance, secure, scale-out disaggregated all-flash storage platform.
Fungible is changing the way storage platforms are designed by removing limitations of existing storage architectures with the release of the Fungible Storage Cluster, FSC 1600 high-performance storage node. The Fungible Storage Cluster delivers a high-performance, low latency NVMe/TCP disaggregated storage solution that is fully transparent to high-level applications. Powered by the Fungible DPU™, the Fungible Storage Cluster (FSC) is a high-performance, secure, scale-out disaggregated all-flash storage platform.

Fungible FS1600 Flash Array
A Data Processing Unit (DPU) is essentially a system on a chip. Typically, a DPU is comprised of a multi-core microprocessor, a network interface, and acceleration engines that offload data-centric tasks such as networking, storage, virtualization, security, and analytics functions. DPUs and SmartNICs continue to gain popularity in enterprise and cloud provider data centers.
The Fungible FSC1600 Storage Cluster
The FS1600 is powered by two Fungible Data Processing Units. A unique Fungible innovation, the DPU represents a new class of microprocessors designed from the ground up to deliver unrivaled performance and efficiency in running infrastructure services.

Fungible FS1600 Internals
While most storage platforms are x86-based, the FS1600 is rooted in foundational Fungible DPU technology. Designed specifically to run data-centric workloads more efficiently than CPUs, the DPU enables the FS1600 to deliver higher performance. The FS1600 features a random read rate of 13M IOPS Raw block read performance (4KB), throughput of 75 GB/s per node, and read latencies of +10μs for performance much more efficient than direct-attached storage (DAS) systems, delivering a 96.5% Performance Efficiency Percentage (PEP).

The DPU hardware accelerators include compression, erasure coding, encryption, regular expression, deep packet inspection, and DMA, operating at a line rate of 800 Gb/s. With erasure coding, if a node fails, data is rebuilt using parity and data chunks from other nodes, while the host provides an alternative path to access the data through multi-pathing. The FS1600, compliant with NVMe/TCP and management software through Container Storage Interface (CSI) for Kubernetes and Openstack for VMs, can be a drop-in replacement for existing storage systems. There are no requirements for special agents that use host CPU resources; only a standard NVMe/TCP driver is required. And existing applications require no changes.
S1 & F1 DPU Models
There are two Fungible DPU models: the S1 DPU and the F1 DPU. The Fungible family of processors leverage the same hardware and software co-design and share the same programming model. However, while the F1 DPU is designed for high-performance standalone appliances such as storage, security, AI, and analytics servers, the S1 DPU maximizes performance within a standard PCIe adapter’s footprint and power envelope.

The Fungible S1 DPU is optimized for combining data-centric computations within server nodes and efficiently moving data among nodes. Data-centric computations are characterized by stateful processing of data streams at high rates, typically by networking, security, and storage stacks.

Fungible FS1600 Rear Ports
The S1 DPU facilitates data interchange among server nodes through its TrueFabric™ technology. TrueFabric is a large-scale IP-over-Ethernet fabric protocol providing total network cross-sectional bandwidth with low average and tail latency, end-to-end QoS, congestion-free connectivity, and security among server nodes. The TrueFabric protocol is fully standards-compliant and interoperable with TCP/IP over Ethernet, ensuring that the data center Spine-Leaf network can be built with standard off-the-shelf Ethernet switches.
FunOS
The data plane for both the S1 and F1 DPU runs FunOS™, a purpose-built operating system written in high-level programming languages (ANSI-C). FunOS runs the networking, storage, security, virtualization, and analytics stacks. The control plane runs a standard OS (e.g., Linux) and contains agents that allow a cluster of both S1 and F1 DPUs to be managed, controlled, and monitored by a set of REST APIs. These REST APIs can be integrated into standard or third-party orchestration systems such as Kubernetes CSI plugins, OpenStack, OpenShift, etc.
By combining these key capabilities into a single solution, the Fungible DPU family of processors enables hyper-disaggregation and pooling of compute and storage resources–delivering a high-performance, massively scalable composable infrastructure for next-generation data centers!
What Makes Up a Cluster
The FSC™ comprises a cluster of two or more Fungible FS1600 storage target nodes and three Fungible Composer nodes. The Fungible Composer software manages the control plane, a centralized management solution that configures, manages, orchestrates, controls, and deploys the Fungible Storage Cluster. The Composer nodes provide services such as storage, network management, telemetry, node management for log collection, and an API gateway providing external access to the services provided by the Fungible Composer.

The Fungible Storage Cluster delivers a high-performance, low latency NVMe/TCP disaggregated storage solution that is fully transparent to high-level applications. Each FS1600 supports up to 24 U.2 NVMe/TCP SSDs, and the performance scales linearly from as small as 70TB to multiple-PBs.
Use Cases
Cloud-native storage for Hyper Disaggregation: The FSC offers cloud providers an alternative to conventional storage. By disaggregating storage, the FSC enables independent scaling of compute and storage, increased utilization, reduced server SKU, reduced management complexity, and increased agility.
Artificial Intelligence / Machine Learning: Modern AI/ML workloads typically require massive parallelism in performance, low latency, and large capacity. The FSC, combined with highly scalable parallel file systems, eliminates storage bottlenecks to achieve unprecedented performance, latency, and efficiency for these modern workloads.
Cloud-native high-performance databases: Many of today’s high-performance scale-out databases deploy DAS to meet latency requirements. These databases typically offer durability through clustered redundancy schemes such as replica sets or primary-secondary configurations. If a server fails, data is preserved on another server. The FSC preserves DAS-like latencies while offering improved storage utilization and clustered redundancy but at a lower capacity overhead.
Simplified IT Management
In addition to all the performance benefits that come with the FS1600 and Fungible DPUs, there is also a simplified management approach. Fungible delivers a management tool for multi-tenant, secure data centers via a single pane of glass. The Fungible Composer dashboard will make an IT administrator’s day more productive and provides information needed to effectively manage the day-to-day data center functions.
Fungible Composer
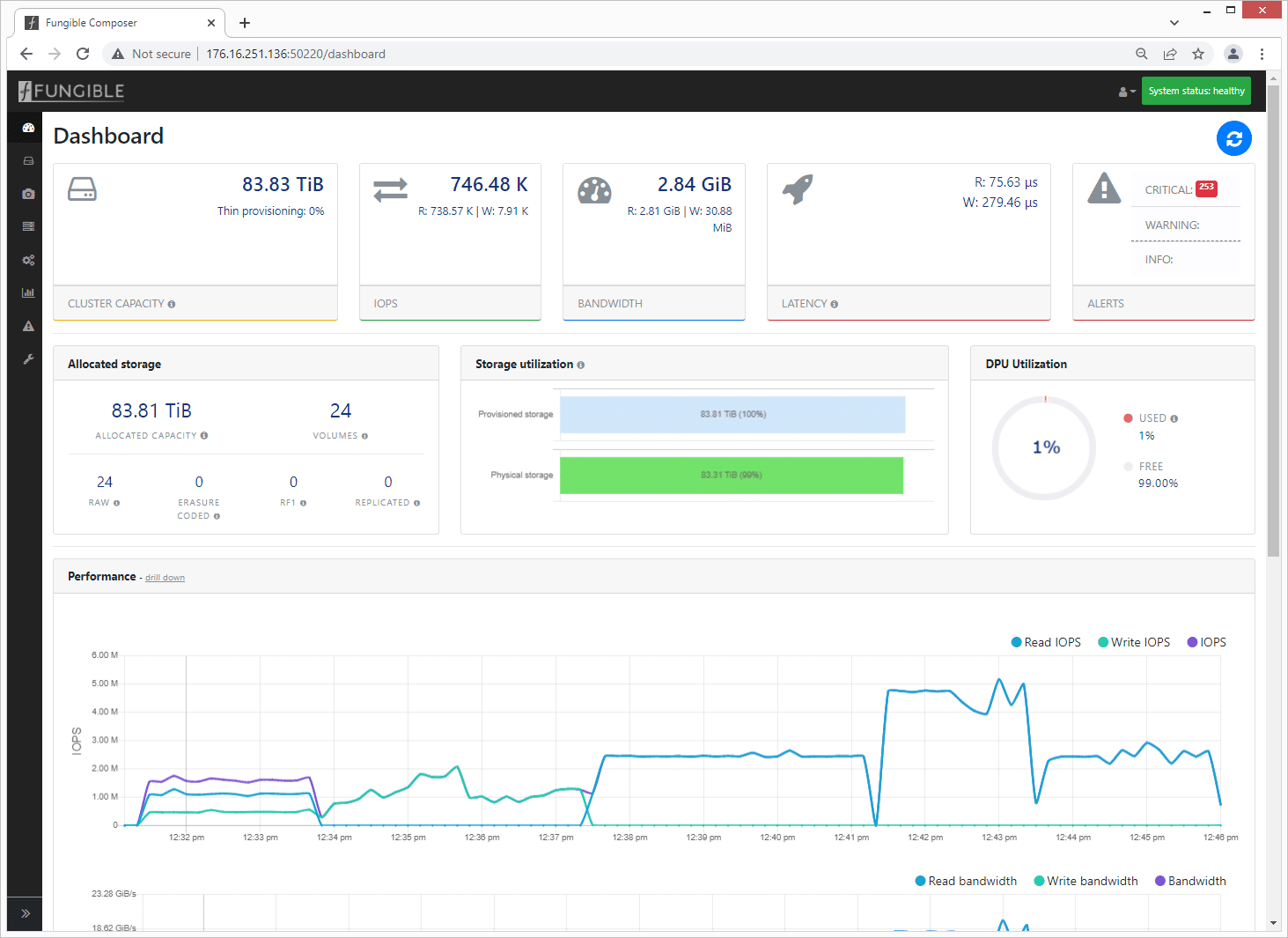
The Fungible Composer dashboard is simple to use with plenty of detail for tracking, management, configuration, and performance monitoring. The top tab will indicate the attached system, with a full display of cluster detail, IOPS, storage details, as well as any alarms that need attention.
The icons on the left side of the display provide immediate access to specific management tools.
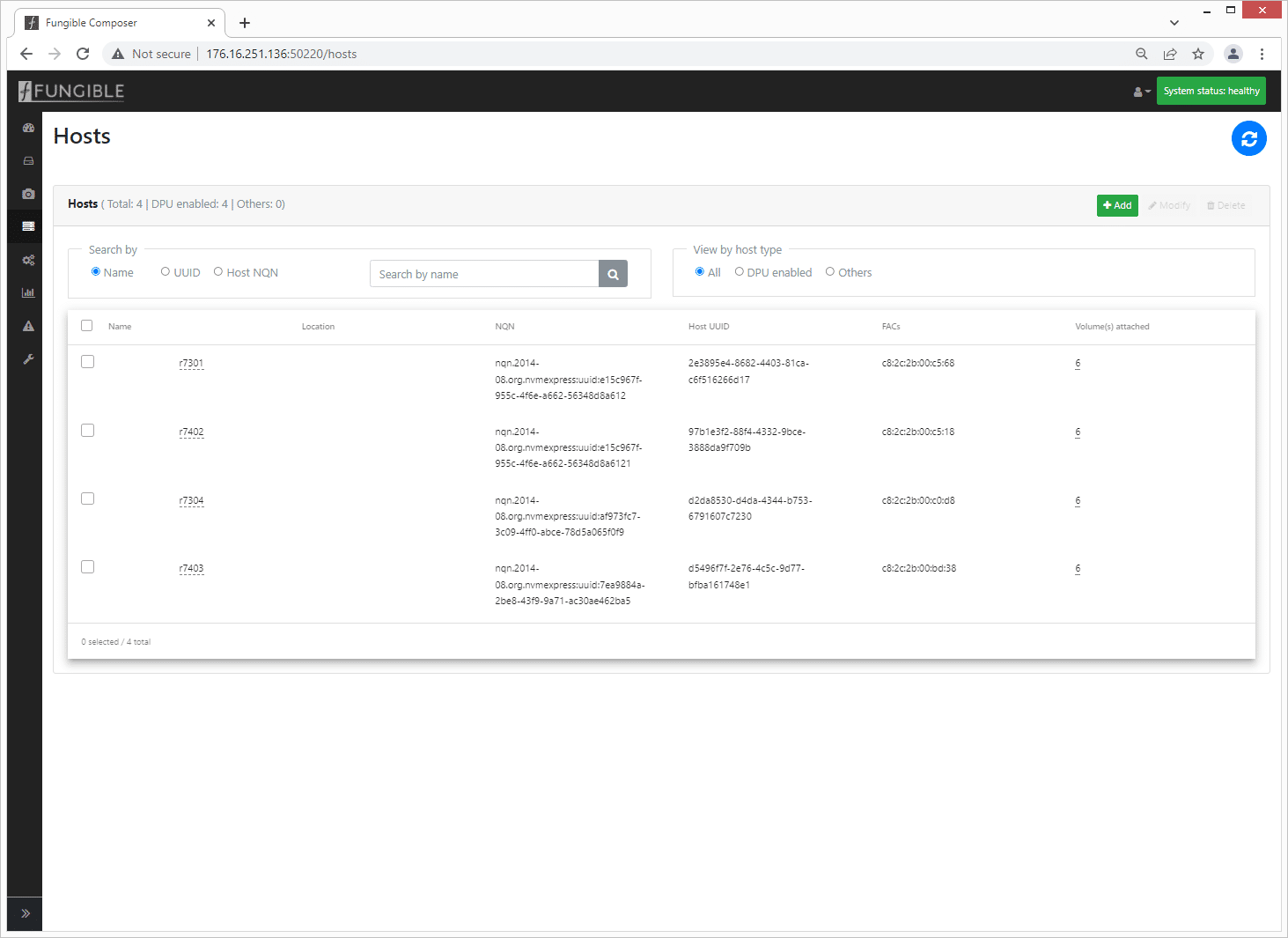
Depending on the detail provided when deploying fungible devices, the host table will give the administrator a quick view of the attached hosts with options to drill down to a specific host.
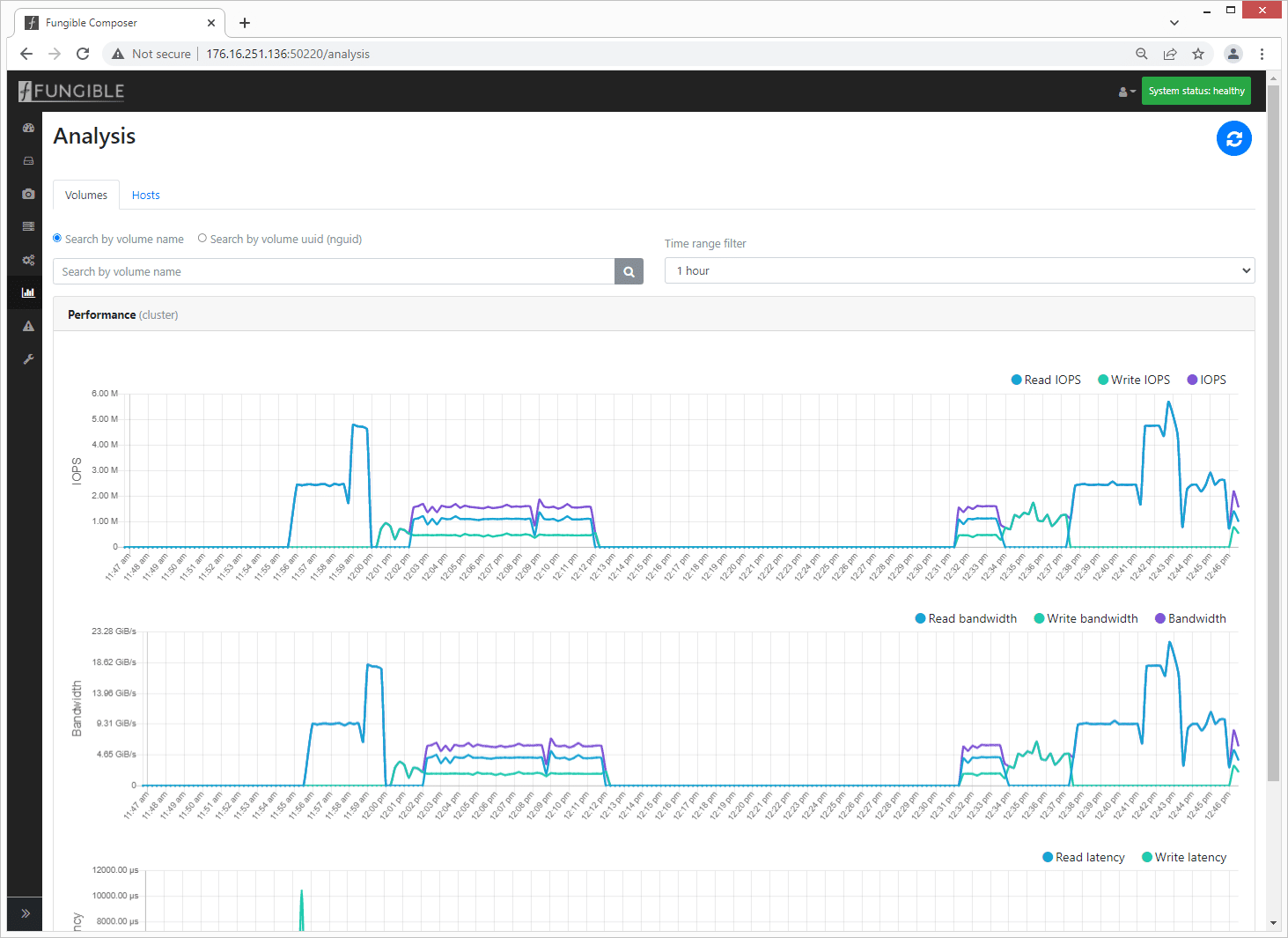
For performance data, by selecting the analysis icon, the screen will populate with details for cluster performance, giving a quick view into IOPS, bandwidth, and latency.
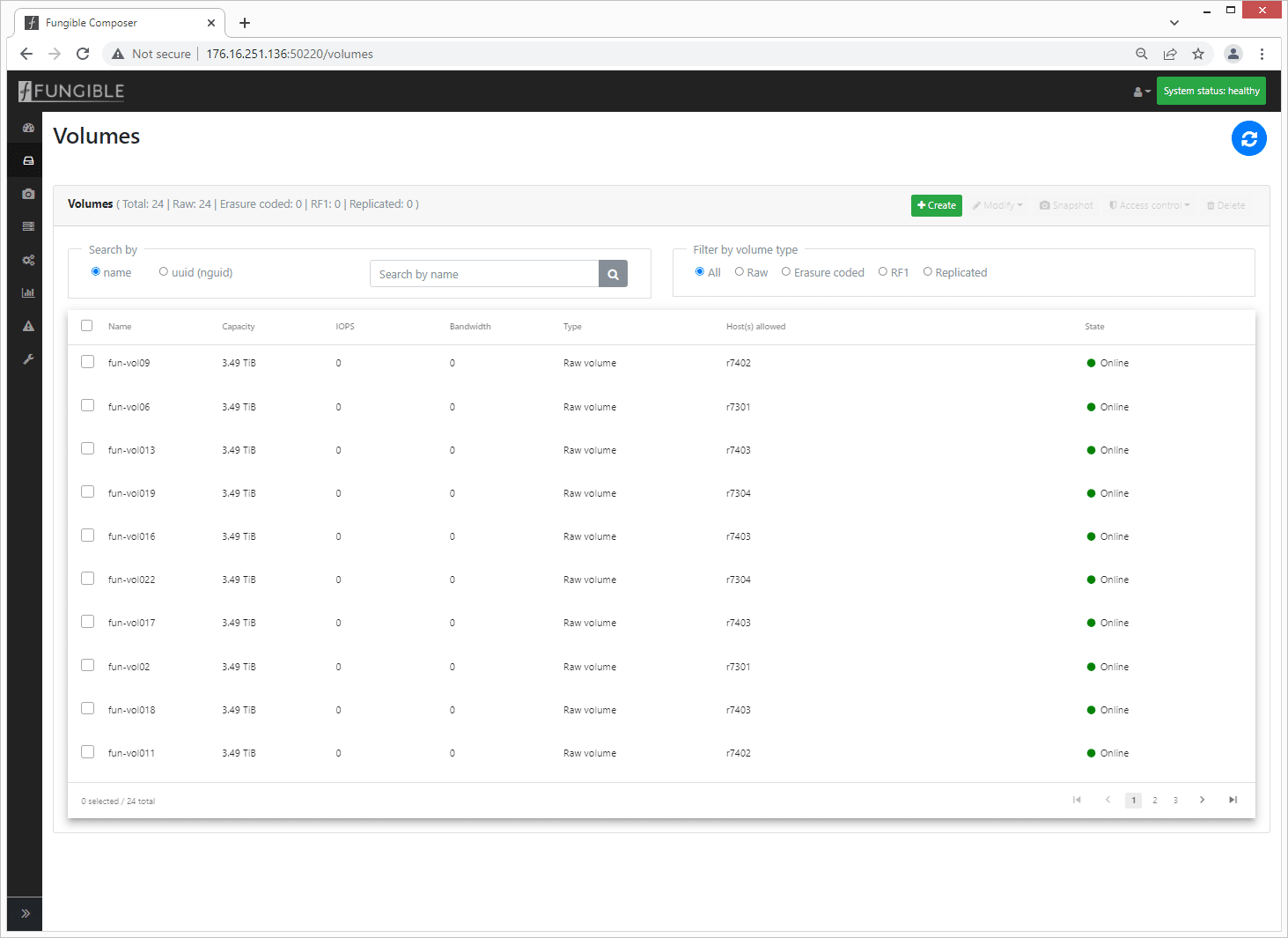
The volume detail provides a quick overview of the health of each volume. From here you can drill down to individual volumes for more detail.
Deployment Details
1 x Fungible FSC1600
- 8 x 100GbE connections
- 24 x 3.84TB NVME devices
4 x Dell R740xd
- 1 x Fungible FC200
- 1 x 100GbE connection
- 1 x NVIDIA ConnectX-5
- 1 x 100GbE connection
- 2 x Intel Xeon Gold 6130 CPU @ 2.10GHz
- 1 256GB DRAM
Volumes
- 192 100G RAW volumes total
- 16 x 4K RAW volumes per host
- 16 x 8K RAW volumes per host
- 16 x 16K RAW volumes per host
Testing Process
Testing preparation included preconditioning all volumes with a write workload to fill them before initiating test workloads. Volumes were sized to align with the block size of the workload applied. For testing, 4K, 8K, and 16K volumes were used for the 4K random, 8K random and 64K sequential workloads, respectively. We leveraged the NVMe over TCP protocol and with a single node, storage was tested without a protection scheme.
Each FIO iteration between the Fungible DPUs or the 100GbE NICs was balanced to offer a similar latency profile. The 100GbE NIC workload was then increased to drive higher performance, resulting in more latency and CPU utilization.
During the initial testing stage, the FIO jobs were linked to the NUMA node where the cards were installed. The DPU or NIC was swapped and located in the same PCIe slot between each test. No special tuning outside of setting the server BIOS profile to Performance was needed at the server level. For each loadgen, we installed Ubuntu 20.04.2 Live Server.
Fungible FS1600 Summary Performance Results
Fungible FC200 IOPS
| Workload | Host 1 | Host 2 | Host 3 | Host 4 |
| 4k reads | 2019k | 2015k | 2016k | 2012k |
| 4k writes | 2244k | 2020k | 2280k | 2203k |
| 64 reads | 167k | 166k | 166k | 166k |
| 64k writes | 161k | 168k | 164k | 186k |
| 8k 70r/30w | 1118k/479k | 1105k/474k | 1075k/461k | 1117k/479k |
Fungible FC200 Bandwidth
| Workload | Host 1 | Host 2 | Host 3 | Host 4 |
| 4k reads | 7886MiB/s | 7871MiB/s | 7873MiB/s | 7858MiB/s |
| 4k writes | 8766MiB/s | 7890MiB/s | 8905MiB/s | 8606MiB/s |
| 64 reads | 9.80GiB/s | 10.1GiB/s | 10.2GiB/s | 10.1GiB/s |
| 64k writes | 8732MiB/s | 10.2GiB/s | 11.3GiB/s | 11.4GiB/s |
| 8k 70r/30w | 8732MiB /3743MiB/s | 8632MiB/3699MiB/s | 8395MiB/3598MiB/s | 8729MiB /3741MiB/s |
100GbE NIC IOPS
| Workload | Host 1 | Host 1 Ramped | Host 2 | Host 3 | Host 4 |
| 4k reads | 980k | 2019k | 1108k | 1102k | 1120k |
| 4k writes | 968k | 2776k | 494k | 1025k | 1011k |
| 64 reads | 140k | 118k | 125k | 141k | 140k |
| 64k writes | 72.5k | 179k | 40.1k | 100k | 47.0k |
| 8k 70r/30w | 498k/213k | 1147k/491k | 597k/256k | 567k/243k | 595k/255k |
100GbE NIC Bandwidth
| Workload | Host 1 | Host 1 Ramped | Host 2 | Host 3 | Host 4 |
| 4K Read |
3828MiB/s | 7887MiB/s | 4330MiB/s | 4303MiB/s | 4374MiB/s |
| 4K Write |
3783MiB/s | 10.6GiB/s | 1931MiB/s | 4005MiB/s | 3950MiB/s |
| 64K Read | 8761MiB/s | 7269MiB/s | 7804MiB/s | 8832MiB/s | 8753MiB/s |
| 64K Write |
4529MiB/s | 10.9GiB/s | 2505MiB/s | 6251MiB/s | 3000MiB/s |
| 8K 70R/30W | 3889MiB/1667MiB/s | 8958MiB/3839MiB/s | 4663MiB/1998MiB/s | 4427MiB/1897MiB/s | 4646MiB/1991MiB/s |
The Fungible FS1600 is a Performer
We knew going into this review that the Fungible FS1600 was fast; that was not in doubt. Although the single cards in each host were saturated, including the DPU and NIC, the array still had performance to spare. The primary focus was how the NICs and DPUs compare for NVMe/TCP workloads utilizing the same storage array with similar testing scenarios. DPUs have brought incredible benefits to the storage market. They can offload activity away from the CPU, freeing it to handle other tasks like application workloads using that I/O or bandwidth. By narrowing our focus to a single host, we see those benefits.
Fungible DPU
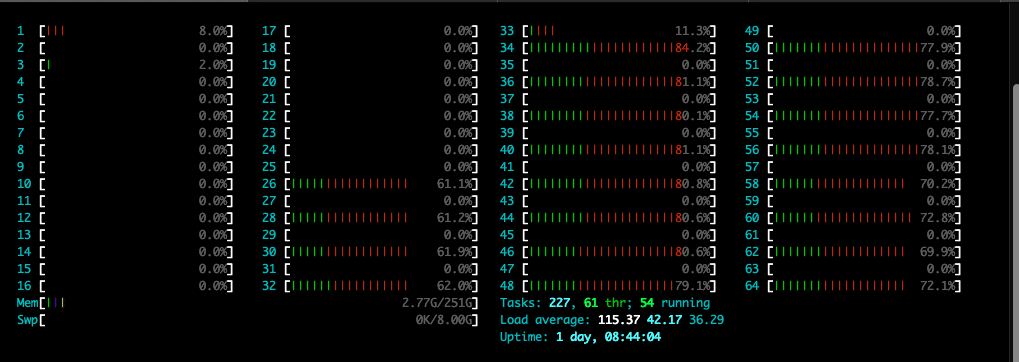
Off the bat, if you keep each workload’s average latency similar, you can see the DPU can drive roughly twice as much performance as the NIC. Here we measured 2.02M IOPS 4K random read from the Fungible DPU, with an average latency of 0.474ms. Looking at the real-time CPU usage during this workload, we can see the workload is contained to the CPU cores specified in the FIO workload.
fio –group_reporting –time_based –runtime=10m –rw=randread –bs=4k –iodepth=5 –numjobs=12 –ioengine=libaio –direct=1 –prio=0 –cpus_allowed_policy=split –cpus_allowed=25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63 –randrepeat=0
100GbE NIC
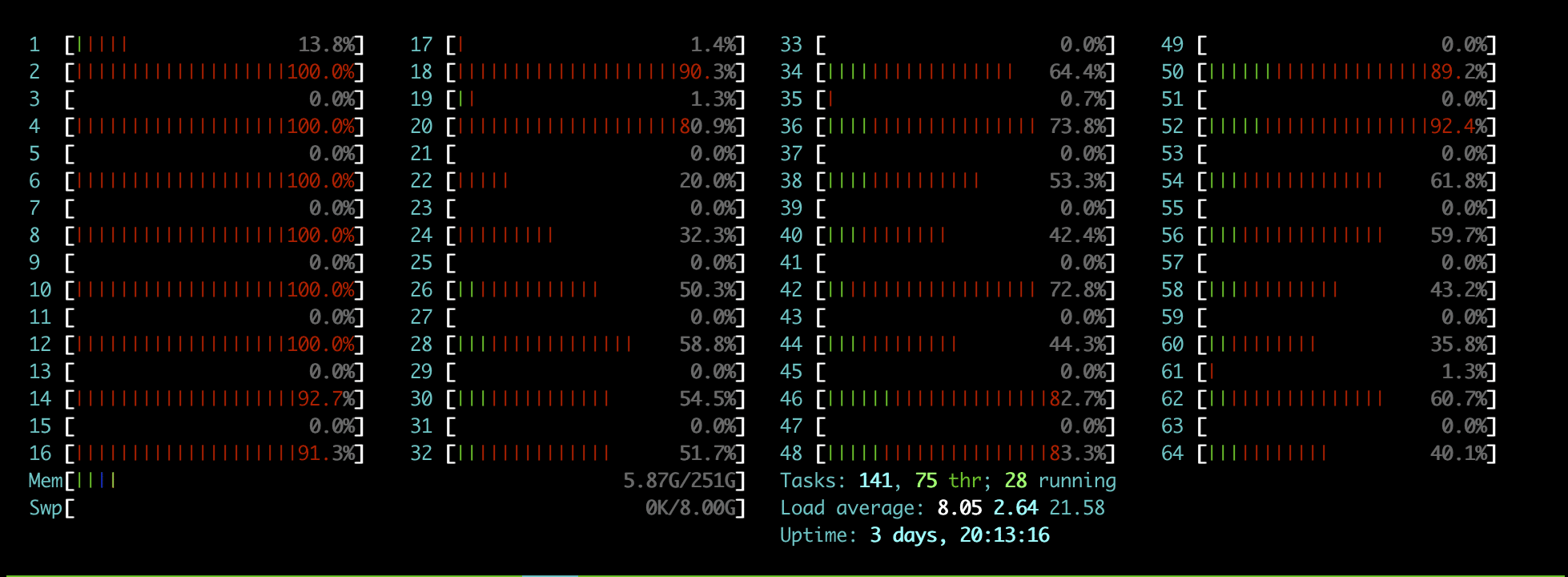
Next, we moved to the 100GbE NIC, which is able to drive 980k IOPS with an average latency of 0.39ms. The IO depth and number of jobs were reduced from the DPU to keep latency in check, but looking at the CPU usage, you quickly see where the benefits of the DPU come in. While the NIC was assigned the same CPU cores in the FIO job, it had much broader system utilization. There is a trade-off between CPU being leveraged for back-end processes (NICs, adapters, etc.) in a production server vs. front-end processes like application workloads. Here we see the NIC driver consuming CPU cycles while the DPU kept internalized.
fio –group_reporting –time_based –runtime=10m –rw=randread –bs=4k –iodepth=4 –numjobs=6 –ioengine=libaio –direct=1 –prio=0 –cpus_allowed_policy=split –cpus_allowed=25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63 –randrepeat=0
100GbE NIC Ramped
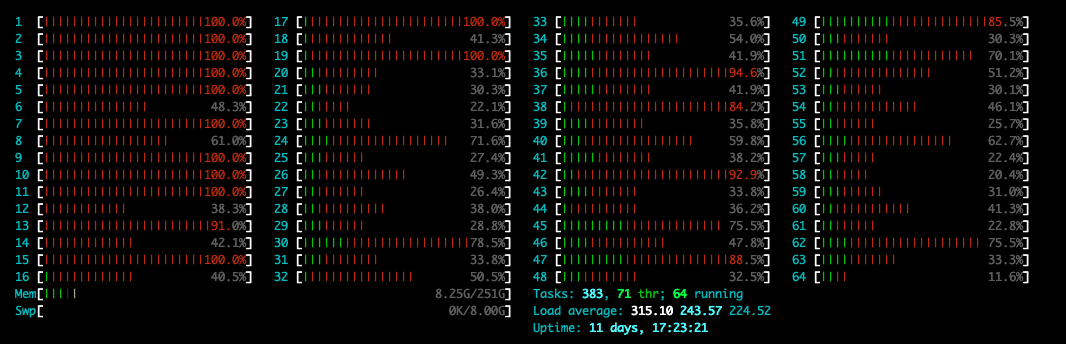
Finally, we moved to the tuned 100GbE NIC workload, which could get up to the same performance level as the DPU, around 2.02M IOPS. The cost of that higher speed, though, is latency, which picked up significantly to 2.6ms and higher peak latency. This was from scaling the iodepth from 4 to 16, and the number of jobs from 6 to 20. While the focus might be centered on the increased latency, looking at the CPU usage, you can see that almost all system resources are being focused on the I/O activity, not leaving much for other processes. For businesses trying to make their server deployments more dense and efficient, it’s easy to see that not all I/O are created equal and how DPUs are quickly changing the storage market.
fio –group_reporting –time_based –runtime=10m –rw=randread –bs=4k –iodepth=16 –numjobs=20 –ioengine=libaio –direct=1 –prio=0 –cpus_allowed_policy=split –cpus_allowed=14-63 –randrepeat=0
Final Words
We’ve been working with the Fungible FS1600 and their DPUs for a number of weeks now. While the array itself doesn’t require any fancy cabling or changes, we wanted to be thorough in the analysis to deeply understand the impact of DPUs. It’s not that DPUs themselves are brand new, but they are finally becoming commercially available in enterprise-grade solutions, not just science projects. And to be clear, DPU implementations aren’t all the same, so understanding the infrastructure and performance implications in design decisions is critical.
In this DPU world, Fungible stands out as quite unique. They went after a custom solution when the company started back in 2015, taking on significant cash to build the company in late 2016. This was roughly when Mellanox announced their first version of a DPU, dubbed BlueField. While it could be argued Fungible would have done well to adopt BlueField, going their own way has resulted in a substantive technology and leadership advantage. Fungible has full control over its stack and can easily leverage DPUs at both the client and target. Or not, the decision resides with the customers. But in our testing, we see significant advantages in going end-to-end with Fungible.
Fungible coming in with DPUs leveraged in the storage array and host completes a picture that offers a huge benefit in terms of performance. DPUs offload resources that would otherwise be tasked to the system processor, which presents an interesting combo when used on both sides of the equation. When you’re able to leverage the Fungible FC200 in place of a traditional NIC, you see huge significant gains with I/O speed as well as lower CPU usage. Looking at our 4K random read transfer alone, the FC200 was able to drive over 2M IOPS at 0.474ms of latency, while the NIC could do around 1M IOPS at 0.39ms. Ramping up the NIC to drive 2M IOPS was possible but at a significant cost of latency and system resources.

Fungible FC200 DPU
DPUs as a class have tremendous potential when it comes to unlocking the native performance available in flash storage. While this is already a true statement today, the math gets even more favorable for DPUs as technology like Gen5 SSDs and faster interconnects come to market. Paying the x86 premium to manage PCIe lanes just doesn’t make sense when it comes to applications that can take advantage of these components and legacy architectures just aren’t as scalable.
Fungible has compelling hardware and software with the FS1600 storage node and Accelerator Cards. They’ve also recently set their sights on disaggregating GPUs, offering customers a more complete stack for HPC and AI workloads. There will be multiple winners in the quickly emerging DPU space, but Fungible is certainly one to keep an eye on. Organizations that need the most out of their storage, should definitely take an FS1600 for a spin.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | Facebook | TikTok | RSS Feed