
![]() Investigadores de la Universidad Carnegie Mellon han publicado un estudio que se centró en la confiabilidad en el campo de los SSD, el estudio se titula "Un estudio a gran escala de las fallas de la memoria flash en el campo". El estudio se realizó utilizando los centros de datos de Facebook a lo largo de cuatro años y millones de horas operativas. El estudio analiza cómo se manifiestan los errores y tiene como objetivo ayudar a otros a desarrollar nuevas soluciones de confiabilidad flash.
Investigadores de la Universidad Carnegie Mellon han publicado un estudio que se centró en la confiabilidad en el campo de los SSD, el estudio se titula "Un estudio a gran escala de las fallas de la memoria flash en el campo". El estudio se realizó utilizando los centros de datos de Facebook a lo largo de cuatro años y millones de horas operativas. El estudio analiza cómo se manifiestan los errores y tiene como objetivo ayudar a otros a desarrollar nuevas soluciones de confiabilidad flash.
Investigadores de la Universidad Carnegie Mellon han publicado un estudio que se centró en la confiabilidad en el campo de los SSD, el estudio se titula "Un estudio a gran escala de las fallas de la memoria flash en el campo". El estudio se realizó utilizando los centros de datos de Facebook a lo largo de cuatro años y millones de horas operativas. El estudio analiza cómo se manifiestan los errores y tiene como objetivo ayudar a otros a desarrollar nuevas soluciones de confiabilidad flash.
Como hemos estado diciendo durante algún tiempo aquí en StorageReview, flash ofrece varios beneficios de rendimiento, beneficios de densidad y menor consumo de energía, siendo el costo el mayor inconveniente. Si bien muchos SSD afirman tener una buena longevidad y confiabilidad, hasta ahora no se han realizado estudios de campo importantes.
Aunque no se mencionaron proveedores específicos ni unidades específicas, Facebook usa muchos en su nivel de datos calientes, el estudio tomó nota del tipo de plataforma en la que se usaron las SSD (esto se definió como una combinación de la capacidad del dispositivo utilizada en el sistema , la tecnología PCIe utilizada y la cantidad de SSD en el sistema), estas fueron plataformas de etiquetas AF. Las plataformas variaban en capacidad de 720 GB a 3.2 TB, tenían dos generaciones de PCIe (versión 1 y 2), algunas empleaban un SSD, otras empleaban dos, y la cantidad de tiempo en funcionamiento oscilaba entre medio año y más de dos años.
Los investigadores utilizaron registros para realizar un seguimiento de la operación SSD similar a los datos SMART. Los valores sin procesar se recopilaron una vez por hora, se analizaron en un formulario que se podía seleccionar en una tabla de Hive y, luego, un grupo de máquinas realizó una agregación en paralelo de los datos almacenados en Hive mediante trabajos de MapReduce. A partir de esto, los investigadores pudieron monitorear la tasa de errores de bits, la tasa de fallas de SSD y el recuento de errores, la correlación entre diferentes SSD (particularmente en plataformas que tenían más de una SSD) y el papel de los factores internos y externos.
Las conclusiones extraídas del estudio incluyen:
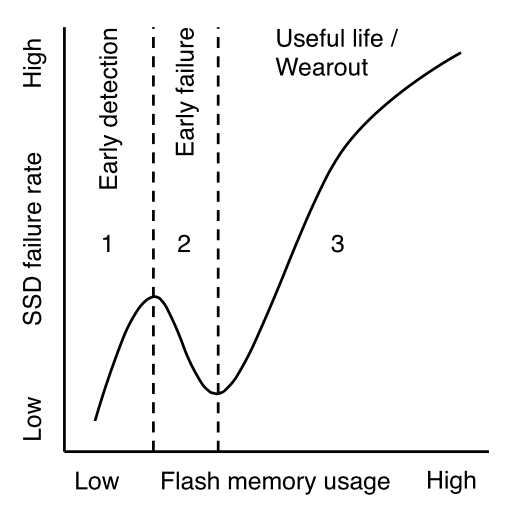
- Los SSD pasan por varios períodos de falla distintos (detección temprana, falla temprana, vida útil y desgaste) durante su ciclo de vida, correspondientes a la cantidad de datos escritos en los chips flash.
- El efecto de los errores de perturbación de lectura no es una fuente predominante de errores en los SSD examinados.
- La disposición de datos escasos en el espacio de direcciones físicas de una SSD (por ejemplo, datos asignados de forma no contigua) conduce a altas tasas de falla de la SSD; el diseño de datos densos (por ejemplo, datos contiguos) también puede afectar negativamente la confiabilidad en ciertas condiciones, probablemente debido a patrones de acceso adversarios.
- Las temperaturas más altas conducen a mayores tasas de fallas, pero lo hacen de manera más notoria para los SSD que no emplean técnicas de regulación.
- La cantidad de datos que se informa que el software del sistema escribe puede exagerar la cantidad de datos que realmente se escriben en los chips flash, debido al almacenamiento en búfer a nivel del sistema y las técnicas de reducción del desgaste.
Si bien el estudio no establece que una unidad o tipo de unidad sea mejor que otra, sigue siendo una mirada interesante sobre cómo funcionan las SSD en el mundo real bajo un uso intensivo. Este estudio abre la puerta tanto a estudios futuros que analicen el uso de SSD como a nuevas tecnologías que podrían hacer que los SSD sean aún más confiables o duren mucho más.

Por su parte, Facebook ha seguido evolucionando los diseños de sus servidores para adaptarse a puntos de datos como los derivados del estudio de Carnegie Mellon. Su recientemente anunciado plataforma de yosemite es un ejemplo oportuno de cómo Facebook está aprovechando flash en factores de forma no tradicionales, al menos para el centro de datos, para obtener el mejor perfil de rendimiento con un gran énfasis en el TCO.
Suscríbase al boletín de StorageReview