
Últimas noticias Resultados de MLPerf han sido publicados, con NVIDIA brindando el más alto rendimiento y eficiencia desde la nube hasta el perímetro para la inferencia de IA. MLPerf sigue siendo una medida útil para el rendimiento de la IA como punto de referencia independiente de terceros. La plataforma de IA de NVIDIA ha estado en la parte superior de la lista de capacitación e inferencia desde el inicio de MLPerf, incluidos los últimos puntos de referencia de MLPerf Inference 3.0.
Últimas noticias Resultados de MLPerf han sido publicados, con NVIDIA brindando el más alto rendimiento y eficiencia desde la nube hasta el perímetro para la inferencia de IA. MLPerf sigue siendo una medida útil para el rendimiento de la IA como punto de referencia independiente de terceros. La plataforma de IA de NVIDIA ha estado en la parte superior de la lista de capacitación e inferencia desde el inicio de MLPerf, incluidos los últimos puntos de referencia de MLPerf Inference 3.0.
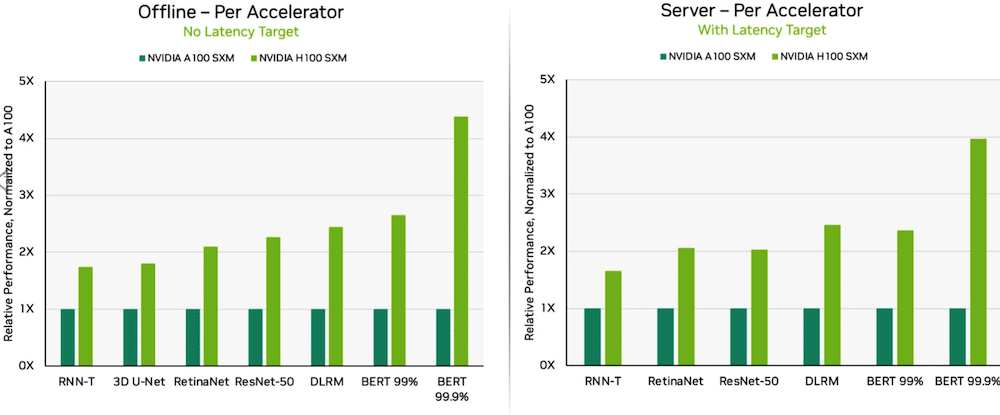
Gracias a las optimizaciones de software, las GPU NVIDIA H100 Tensor Core que se ejecutan en los sistemas DGX H100 brindaron el rendimiento más alto en cada prueba de inferencia de IA, un 54 por ciento más que el debut en septiembre. En el sector de la salud, las GPU H100 generaron un aumento del rendimiento del 31 % en 3D-UNet, el punto de referencia de MLPerf para imágenes médicas.

Dell PowerEdge XE9680 con GPU 8X H100
Impulsada por su Transformer Engine, la GPU H100, basada en la arquitectura Hopper, se destacó en BERT. BERT es un modelo para el procesamiento del lenguaje natural desarrollado por Google que aprende representaciones bidireccionales de texto para mejorar significativamente la comprensión contextual del texto sin etiquetar en muchas tareas diferentes. Es la base de toda una familia de modelos similares a BERT, como RoBERTa, ALBERT y DistilBERT.
Con IA generativa, los usuarios pueden crear rápidamente texto, imágenes, modelos 3D y mucho más. Las empresas, desde nuevas empresas hasta proveedores de servicios en la nube, están adoptando IA generativa para habilitar nuevos modelos comerciales y acelerar los existentes. Una herramienta de IA generativa que ha estado en las noticias últimamente es ChatGPT, utilizada por millones de personas que esperan respuestas instantáneas después de consultas y entradas.
Con el aprendizaje profundo implementado en todas partes, el rendimiento de la inferencia es fundamental, desde las plantas de producción hasta los sistemas de recomendación en línea.
Las GPU L4 ofrecen un rendimiento impresionante
En su viaje inaugural, Nvidia L4 Las GPU Tensor Core se desempeñaron a más de 3 veces la velocidad de las GPU T4 de la generación anterior. Los aceleradores de GPU L4, empaquetados en un factor de forma de bajo perfil, están diseñados para ofrecer un alto rendimiento y una baja latencia en casi cualquier plataforma de servidor. Las GPU L4 Tensor ejecutaron todas las cargas de trabajo de MLPerf y, gracias a su compatibilidad con el formato FP8, los resultados fueron excelentes en el modelo BERT que exige mucho rendimiento.
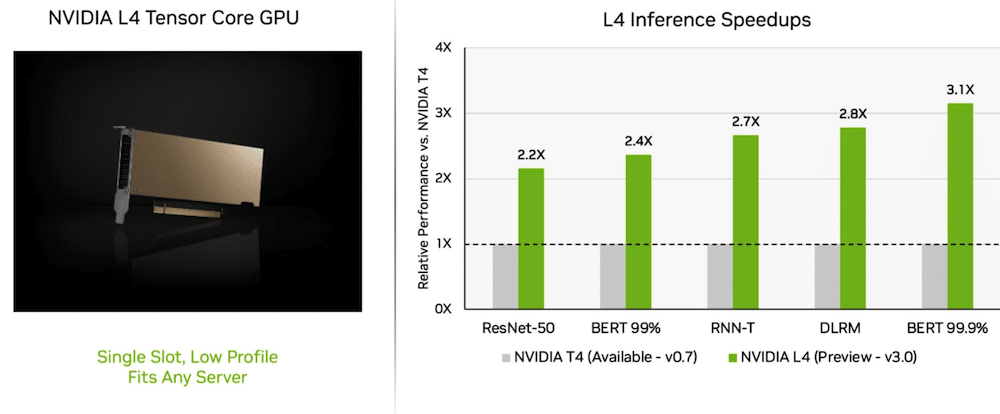
Además del rendimiento extremo de la IA, las GPU L4 ofrecen una decodificación de imágenes hasta 10 veces más rápida, un procesamiento de video hasta 3.2 veces más rápido y un rendimiento de representación en tiempo real y gráficos más de 4 veces más rápido. Los aceleradores, anunciados en GTC hace un par de semanas, están disponibles a través de fabricantes de sistemas y proveedores de servicios en la nube.
¿Qué Red-División?
La plataforma de IA de pila completa de NVIDIA demostró su valía en una nueva prueba de MLPerf: ¡punto de referencia de la división de red!
El punto de referencia de la división de red transmite datos a un servidor de inferencia remoto. Refleja el escenario predominante de usuarios empresariales que ejecutan trabajos de IA en la nube con datos almacenados detrás de firewalls corporativos.
En BERT, los sistemas NVIDIA DGX A100 remotos entregaron hasta el 96 por ciento de su rendimiento local máximo, en parte ralentizado mientras esperaban que las CPU completaran algunas tareas. En la prueba ResNet-50 para visión por computadora, manejada únicamente por GPU, alcanzaron el 100%.
Las redes NVIDIA Quantum Infiniband, NVIDIA ConnectX SmartNIC y software como NVIDIA GPUDirect desempeñaron un papel importante en los resultados de la prueba.
Orin mejora en el Edge
Por separado, el sistema en módulo NVIDIA Jetson AGX Orin generó ganancias de hasta un 63 % en eficiencia energética y un 81 % en rendimiento en comparación con los resultados del año pasado. Jetson AGX Orin proporciona inferencia cuando se necesita IA en espacios confinados a bajos niveles de energía, incluidos los sistemas alimentados por batería.
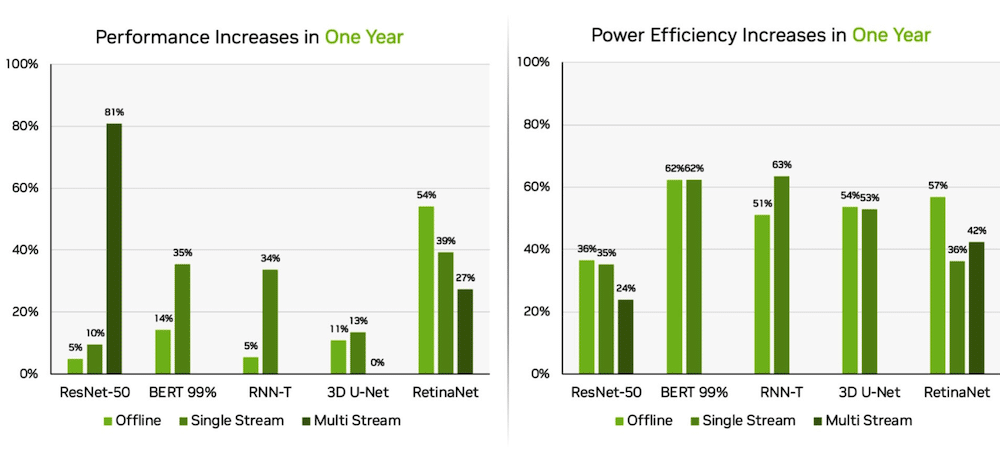
El Jetson Orin NX 16G, un módulo más pequeño que requiere menos energía, se desempeñó bien en los puntos de referencia. Entregó hasta 3.2 veces el rendimiento del procesador Jetson Xavier NX.
Ecosistema de IA de NVIDIA
Los resultados de MLPerf muestran que NVIDIA AI está respaldada por un amplio ecosistema de aprendizaje automático. Diez empresas presentaron resultados en la plataforma NVIDIA en esta ronda, incluidos los fabricantes de sistemas y servicios en la nube de Microsoft Azure, ASUS, Dell Technologies, GIGABYTE, H3C, Lenovo, Nettrix, Supermicro y xFusion. Su trabajo ilustra que los usuarios pueden obtener un gran rendimiento con NVIDIA AI tanto en la nube como en servidores que se ejecutan en sus propios centros de datos.
Interactuar con StorageReview
Boletín | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed