
Meta Platforms hat das NVIDIA DGX A100-System für den AI Research SuperCluster (RSC) ausgewählt. Bei vollständiger Bereitstellung wird Metas RSC voraussichtlich das größte NVIDIA DGX A100-System sein. Der AI Research SuperCluster (RSC) trainiert bereits neue Modelle, um die KI voranzutreiben.
Meta Platforms hat das NVIDIA DGX A100-System für den AI Research SuperCluster (RSC) ausgewählt. Bei vollständiger Bereitstellung wird Metas RSC voraussichtlich das größte NVIDIA DGX A100-System sein. Der AI Research SuperCluster (RSC) trainiert bereits neue Modelle, um die KI voranzutreiben.
Meta Research SuperCluster

Der KI-Forschungs-SuperCluster von Meta verfügt über Hunderte von NVIDIA DGX-Systemen, die in einem NVIDIA Quantum InfiniBand-Netzwerk verbunden sind, um die Arbeit seiner KI-Forschungsteams zu beschleunigen.
Es wird erwartet, dass RSC noch in diesem Jahr vollständig ausgebaut wird und Meta damit KI-Modelle mit mehr als einer Billion Parametern trainieren wird. RSC wird Fortschritte in Bereichen wie der Verarbeitung natürlicher Sprache machen, um beispielsweise schädliche Inhalte in Echtzeit zu identifizieren. Neben der Leistung im großen Maßstab nannte Meta extreme Zuverlässigkeit, Sicherheit, Datenschutz und die Flexibilität, „eine breite Palette von KI-Modellen“ zu handhaben, als Schlüsselkriterien für RSC.

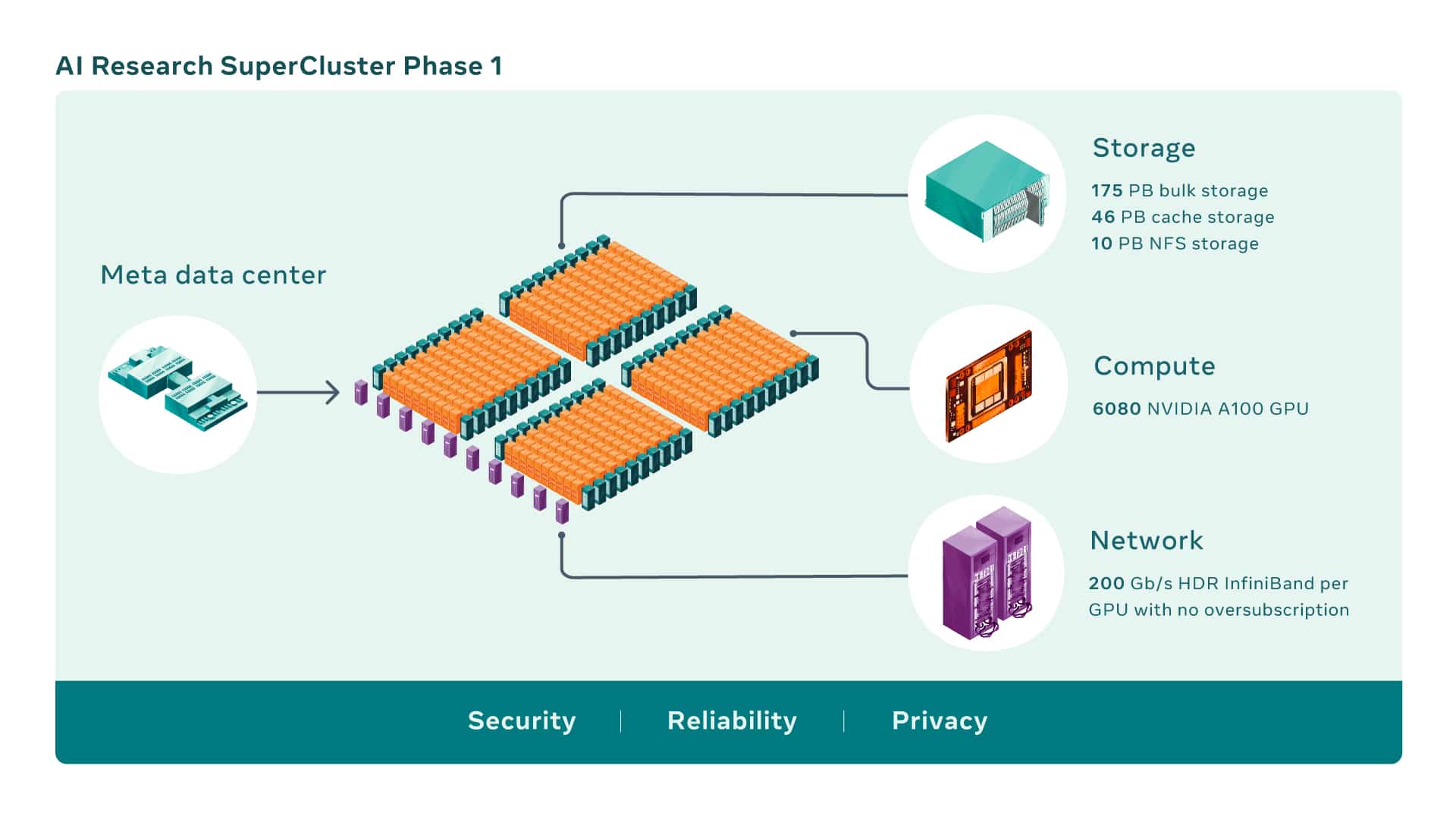
KI-Supercomputer entstehen durch die Kombination mehrerer GPUs zu Rechenknoten, die dann über eine leistungsstarke Netzwerkstruktur verbunden werden, um eine schnelle Kommunikation zwischen diesen GPUs zu ermöglichen. RSC umfasst heute insgesamt 760 NVIDIA DGX-A100 Systeme als Rechenknoten für insgesamt 6,080 GPUs – wobei jede A100-GPU leistungsstärker ist als die im vorherigen System verwendete V100.

Die GPUs kommunizieren über eine NVIDIA Quantum 200 Gbit/s InfiniBand zweistufige Clos-Fabric, die keine Überbelegung aufweist. Die Speicherschicht von RSC verfügt über 175 Petabyte Pure Storage FlashArray, 46 Petabyte Cache-Speicher in Penguin Computing Altus-Systemen und 10 Petabyte Pure Storage FlashBlade.


Frühe Benchmarks zu RSC im Vergleich zur alten Produktions- und Forschungsinfrastruktur von Meta haben gezeigt, dass es Computer-Vision-Workflows bis zu 20-mal schneller ausführt, die NVIDIA Collective Communication Library (NCCL) mehr als neunmal schneller ausführt und umfangreiche NLP-Modelle trainiert dreimal schneller. Das bedeutet, dass ein Modell mit Dutzenden Milliarden Parametern das Training in drei Wochen abschließen kann, verglichen mit neun Wochen zuvor.
Wenn RSC fertiggestellt ist, wird die InfiniBand-Netzwerkstruktur 16,000 GPUs als Endpunkte verbinden, was es zu einem der größten Netzwerke dieser Art macht, die bisher bereitgestellt wurden. Darüber hinaus kann das entwickelte Caching- und Speichersystem 16 TB/s an Trainingsdaten verarbeiten und diese auf bis zu 1 Exabyte skalieren.

Während RSC heute in Betrieb ist, geht seine Entwicklung weiter. Sobald die zweite Phase des RSC-Aufbaus abgeschlossen ist, wird erwartet, dass er der schnellste KI-Supercomputer der Welt sein wird und eine Rechenleistung von fast 5 Exaflops mit gemischter Genauigkeit erreichen wird.

Bis 2022 wird daran gearbeitet, die Anzahl der GPUs von 6,080 auf 16,000 zu erhöhen und so die KI-Trainingsleistung um mehr als das 2.5-fache zu steigern. Die InfiniBand-Struktur wird erweitert, um 16,000 Ports in einer zweischichtigen Topologie ohne Überbelegung zu unterstützen. Das Speichersystem wird über eine angestrebte Lieferbandbreite von 16 TB/s und eine Kapazität im Exabyte-Bereich verfügen, um der gestiegenen Nachfrage gerecht zu werden.
Beteiligen Sie sich an StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | Facebook | TikTok | RSS Feed