
Meta Platforms har valt NVIDIA DGX A100-systemet för AI Research SuperCluster (RSC). När det är fullt utplacerat förväntas Metas RSC vara det största NVIDIA DGX A100-systemet. AI Research SuperCluster (RSC) utbildar redan nya modeller för att främja AI.
Meta Platforms har valt NVIDIA DGX A100-systemet för AI Research SuperCluster (RSC). När det är fullt utplacerat förväntas Metas RSC vara det största NVIDIA DGX A100-systemet. AI Research SuperCluster (RSC) utbildar redan nya modeller för att främja AI.
Meta Research SuperCluster

Metas AI Research SuperCluster har hundratals NVIDIA DGX-system kopplade till ett NVIDIA Quantum InfiniBand-nätverk för att påskynda arbetet för dess AI-forskarteam.
RSC förväntas vara helt utbyggt senare i år och Meta kommer att använda det för att träna AI-modeller med mer än en biljon parametrar. RSC kommer att göra framsteg inom områden som naturlig språkbehandling för jobb som att identifiera skadligt innehåll i realtid. Förutom prestanda i stor skala, nämnde Meta extrem tillförlitlighet, säkerhet, integritet och flexibiliteten att hantera "ett brett utbud av AI-modeller" som sina nyckelkriterier för RSC.

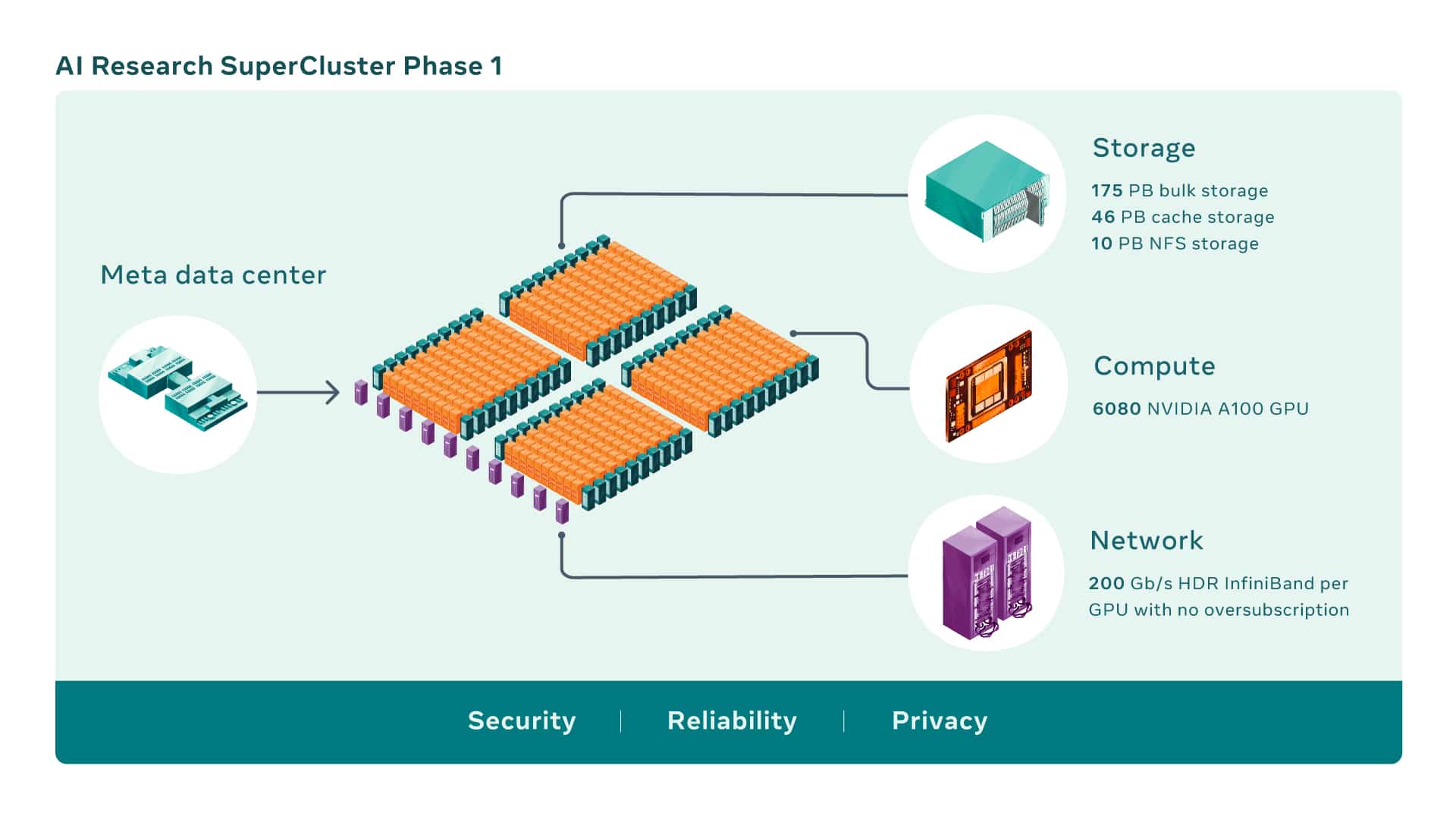
AI-superdatorer byggs genom att kombinera flera GPU:er till beräkningsnoder, som sedan kopplas samman med ett högpresterande nätverkstyg för att möjliggöra snabb kommunikation mellan dessa GPU:er. RSC omfattar idag totalt 760 NVIDIA DGX-A100 system som dess beräkningsnoder, för totalt 6,080 100 GPU:er — där varje A100 GPU är kraftfullare än VXNUMX som användes i det tidigare systemet.

GPU:erna kommunicerar via en NVIDIA Quantum 200 Gb/s InfiniBand Clos-tyg i två nivåer som inte har någon överteckning. RSC:s lagringsnivå har 175 petabyte Pure Storage FlashArray, 46 petabyte cachelagring i Penguin Computing Altus-system och 10 petabyte Pure Storage FlashBlade.


Tidiga riktmärken på RSC, jämfört med Metas äldre produktions- och forskningsinfrastruktur, har visat att den kör datorseende arbetsflöden upp till 20 gånger snabbare, kör NVIDIA Collective Communication Library (NCCL) mer än nio gånger snabbare och tränar storskaliga NLP-modeller tre gånger snabbare. Det betyder att en modell med tiotals miljarder parametrar kan avsluta träningen på tre veckor, jämfört med nio veckor tidigare.
När RSC är färdigt kommer InfiniBand-nätverksstrukturen att ansluta 16,000 16 GPU:er som slutpunkter, vilket gör det till ett av de största sådana nätverken som hittills har distribuerats. Dessutom kan det designade cache- och lagringssystemet tjäna 1 TB/s träningsdata och skala upp det till XNUMX exabyte.

Medan RSC är igång idag, fortsätter utvecklingen. När fas två av utbyggnaden av RSC är klar, förväntas den vara den snabbaste AI-superdatorn i världen, med nästan 5 exaflops av beräkningar med blandad precision.

Arbetet kommer att fortsätta till och med 2022 för att öka antalet GPU:er från 6,080 16,000 till 2.5 16,000, vilket ökar AI-träningsprestanda med mer än 16 gånger. InfiniBand-tyget kommer att utökas för att stödja XNUMX XNUMX portar i en tvåskiktstopologi utan överabonnemang. Lagringssystemet kommer att ha en målleveransbandbredd på XNUMX TB/s och kapacitet i exabyte-skala för att möta ökad efterfrågan.
Engagera dig med StorageReview
Nyhetsbrev | Youtube | Podcast iTunes/Spotify | Instagram | Twitter | Facebook | TikTok | Rssflöde