
Meta fortsätter sin AI-innovation genom strategiska investeringar i hårdvaruinfrastruktur, avgörande för att utveckla AI-teknologier. Företaget avslöjade nyligen detaljer om två iterationer av sitt 24,576 3-GPU datacenterskalakluster, som är avgörande för att driva nästa generations AI-modeller, inklusive utvecklingen av Llama XNUMX.
Meta fortsätter sin AI-innovation genom strategiska investeringar i hårdvaruinfrastruktur, avgörande för att utveckla AI-teknologier. Företaget avslöjade nyligen detaljer om två iterationer av sitt 24,576 3-GPU datacenterskalakluster, som är avgörande för att driva nästa generations AI-modeller, inklusive utvecklingen av Llama XNUMX. Detta initiativ är en grund för Metas vision att skapa öppna och ansvarsfullt byggda artificiell allmän intelligens (AGI) tillgänglig för alla.
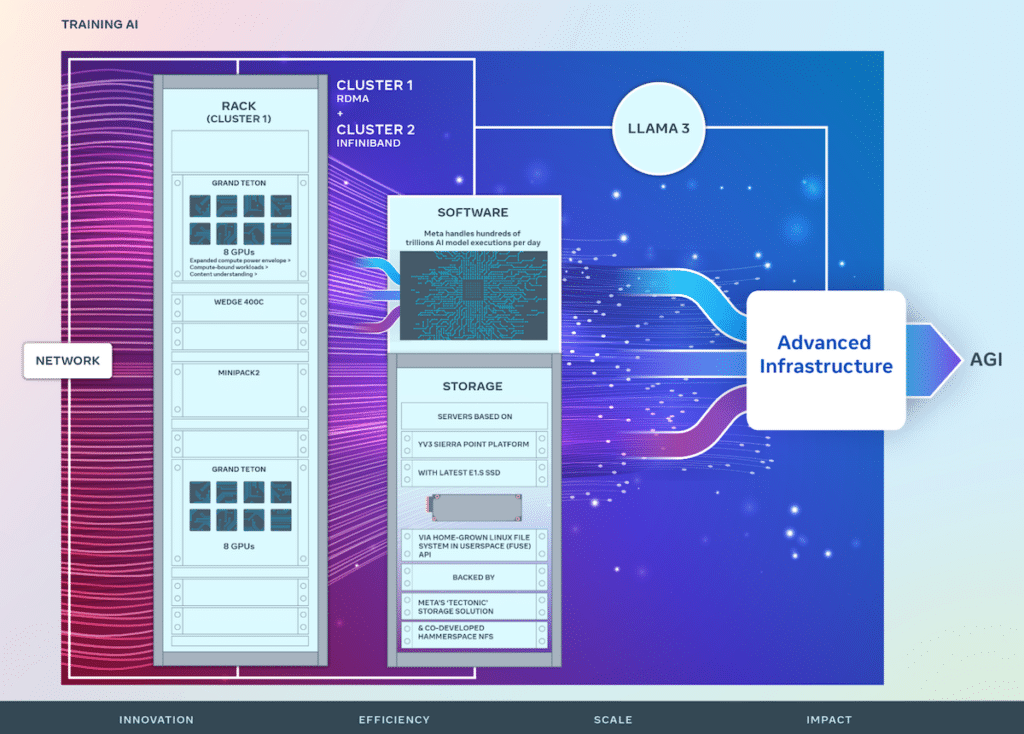
Foto med tillstånd av META Engineering
Under sin pågående resa har Meta förfinat sitt AI Research SuperCluster (RSC), som ursprungligen avslöjades 2022, med 16,000 100 NVIDIA AXNUMX GPU:er. RSC har varit avgörande för att främja öppen AI-forskning och främja skapandet av sofistikerade AI-modeller med applikationer som spänner över många domäner, inklusive datorseende, naturlig språkbehandling (NLP), taligenkänning och mer.
Med utgångspunkt i RSC:s framgångar förbättrar Metas nya AI-kluster end-to-end AI-systemutveckling med tonvikt på att optimera forskar- och utvecklarupplevelsen. Dessa kluster integrerar 24,576 100 NVIDIA Tensor Core HXNUMX GPU:er och utnyttjar högpresterande nätverkstyger för att stödja mer komplexa modeller än tidigare möjligt, vilket sätter en ny standard för GenAI-produktutveckling och forskning.
Metas infrastruktur är mycket avancerad och anpassningsbar och hanterar hundratals biljoner AI-modeller dagligen. Den skräddarsydda designen av hårdvara och nätverkstyger säkerställer optimerad prestanda för AI-forskare samtidigt som effektiv datacenterdrift bibehålls.
Innovativa nätverkslösningar har implementerats, inklusive ett kluster med fjärrstyrd direktminnesåtkomst (RDMA) över konvergerat Ethernet (RoCE) och ett annat med NVIDIA Quantum2 InfiniBand-tyg, båda klarar av 400 Gbps sammankopplingar. Dessa teknologier möjliggör skalbarhet och prestandainsikter som är avgörande för utformningen av framtida storskaliga AI-kluster.

Grand Teton introducerades under OCP 2022
Metas Grand Teton, en egendesignad, öppen GPU-hårdvaruplattform, bidrar till Open Compute Project (OCP) och förkroppsligar år av AI-systemutveckling. Den slår samman kraft-, kontroll-, beräknings- och strukturgränssnitt till en sammanhållen enhet, vilket underlättar snabb implementering och skalning inom datacentermiljöer.
För att ta itu med den ofta underdiskuterade men ändå kritiska rollen av lagring i AI-träning, har Meta implementerat ett anpassat Linux Filesystem in Userspace (FUSE) API som stöds av en optimerad version av den "Tectonic" distribuerade lagringslösningen. Denna installation, ihopkopplad med det samutvecklade Hammerspace parallella nätverksfilsystemet (NFS), ger en skalbar, högkapacitetslagringslösning som är nödvändig för att hantera de enorma datakraven för multimodala AI-träningsjobb.
Metas YV3 Sierra Point-serverplattform, uppbackad av Tectonic och Hammerspace-lösningar, understryker företagets engagemang för prestanda, effektivitet och skalbarhet. Denna framsynthet säkerställer att lagringsinfrastrukturen kan möta nuvarande krav och skala för att tillgodose de växande behoven hos framtida AI-initiativ.
När AI-system växer i komplexitet fortsätter Meta sin innovation med öppen källkod inom hårdvara och mjukvara, och bidrar avsevärt till OCP och PyTorch, och främjar därigenom samarbete inom AI-forskningssamhället.
Designen av dessa AI-träningskluster är integrerade i Metas färdplan, som syftar till att utöka sin infrastruktur med ambitionen att integrera 350,000 100 NVIDIA H2024 GPU:er i slutet av XNUMX. Denna bana belyser Metas proaktiva inställning till infrastrukturutveckling, redo att möta de dynamiska kraven från framtida AI-forskning och tillämpningar.
Engagera dig med StorageReview
Nyhetsbrev | Youtube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | Rssflöde