
Stora språkmodeller erbjuder otroliga nya möjligheter, och utökar gränsen för vad som är möjligt med AI. Men deras stora storlek och unika utförandeegenskaper kan göra dem utmanande att använda kostnadseffektivt. NVIDIA TensorRT-LLM har öppnats för att påskynda utvecklingen av LLM.
Stora språkmodeller erbjuder otroliga nya möjligheter, och utökar gränsen för vad som är möjligt med AI. Men deras stora storlek och unika utförandeegenskaper kan göra dem utmanande att använda kostnadseffektivt. NVIDIA TensorRT-LLM har öppnats för att påskynda utvecklingen av LLM.
Vad är NVIDIA TensorRT-LLM?
NVIDIA har arbetat nära med ledande företag, inklusive Meta, AnyScale, Cohere, Deci, Grammarly, Mistral AI, MosaicML, nu en del av Databricks, OctoML, Tabnine och Together AI för att accelerera och optimera LLM-inferens.

Dessa innovationer har integrerats i öppen källkod NVIDIA TensorRT-LLM programvara som släpps under de kommande veckorna. TensorRT-LLM består av TensorRT djupinlärningskompilatorn och inkluderar optimerade kärnor, för- och efterbehandlingssteg och kommunikationsprimitiver för flera GPU/multinod för banbrytande prestanda på NVIDIA GPU:er. Det gör det möjligt för utvecklare att experimentera med nya LLM:er, och erbjuder toppprestanda och snabba anpassningsmöjligheter utan att kräva djup C++ eller NVIDIA CUDA-kunskap.
TensorRT-LLM förbättrar användarvänligheten och utökbarheten genom ett modulärt Python-API med öppen källkod för att definiera, optimera och exekvera nya arkitekturer och förbättringar allteftersom LLM:er utvecklas och kan enkelt anpassas.
MosaicML har till exempel lagt till specifika funktioner som den behöver ovanpå TensorRT-LLM sömlöst och integrerat dem i deras befintliga serveringsstack. Naveen Rao, vice vd för teknik på Databricks, konstaterar att "det har varit en absolut bris."
NVIDIA TensorRT-LLM prestanda
Att sammanfatta artiklar är bara en av många tillämpningar av LLM. Följande riktmärken visar prestandaförbättringar från TensorRT-LLM på den senaste NVIDIA Hopper-arkitekturen.
Följande figurer återspeglar artikelsammanfattningar med en NVIDIA A100 och NVIDIA H100 med CNN/Daily Mail, en välkänd datauppsättning för att utvärdera sammanfattningsprestanda.
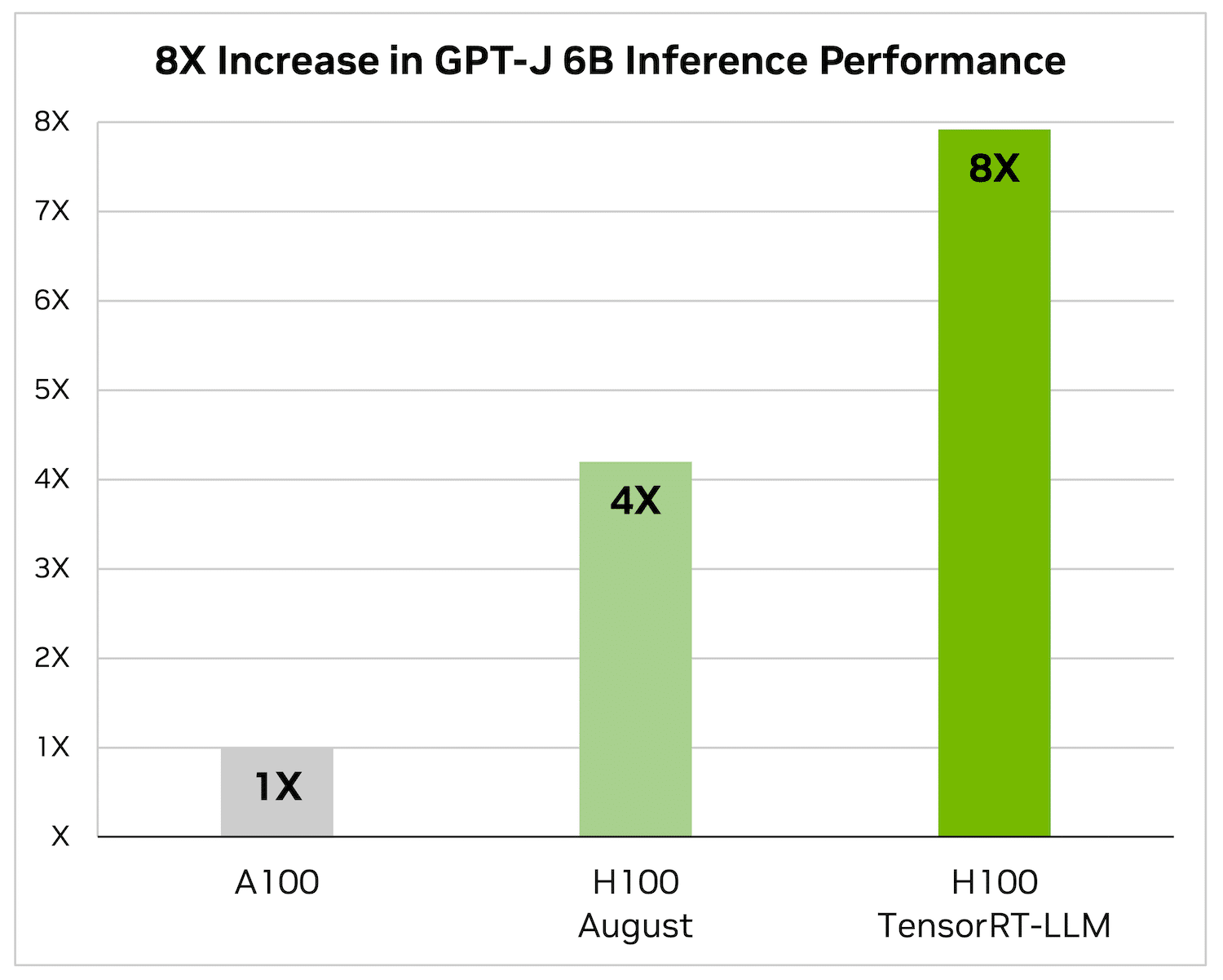
Enbart H100 är 4x snabbare än A100. Att lägga till TensorRT-LLM och dess fördelar, inklusive batchning under flygning, resulterar i en 8X ökning för att leverera den högsta genomströmningen.
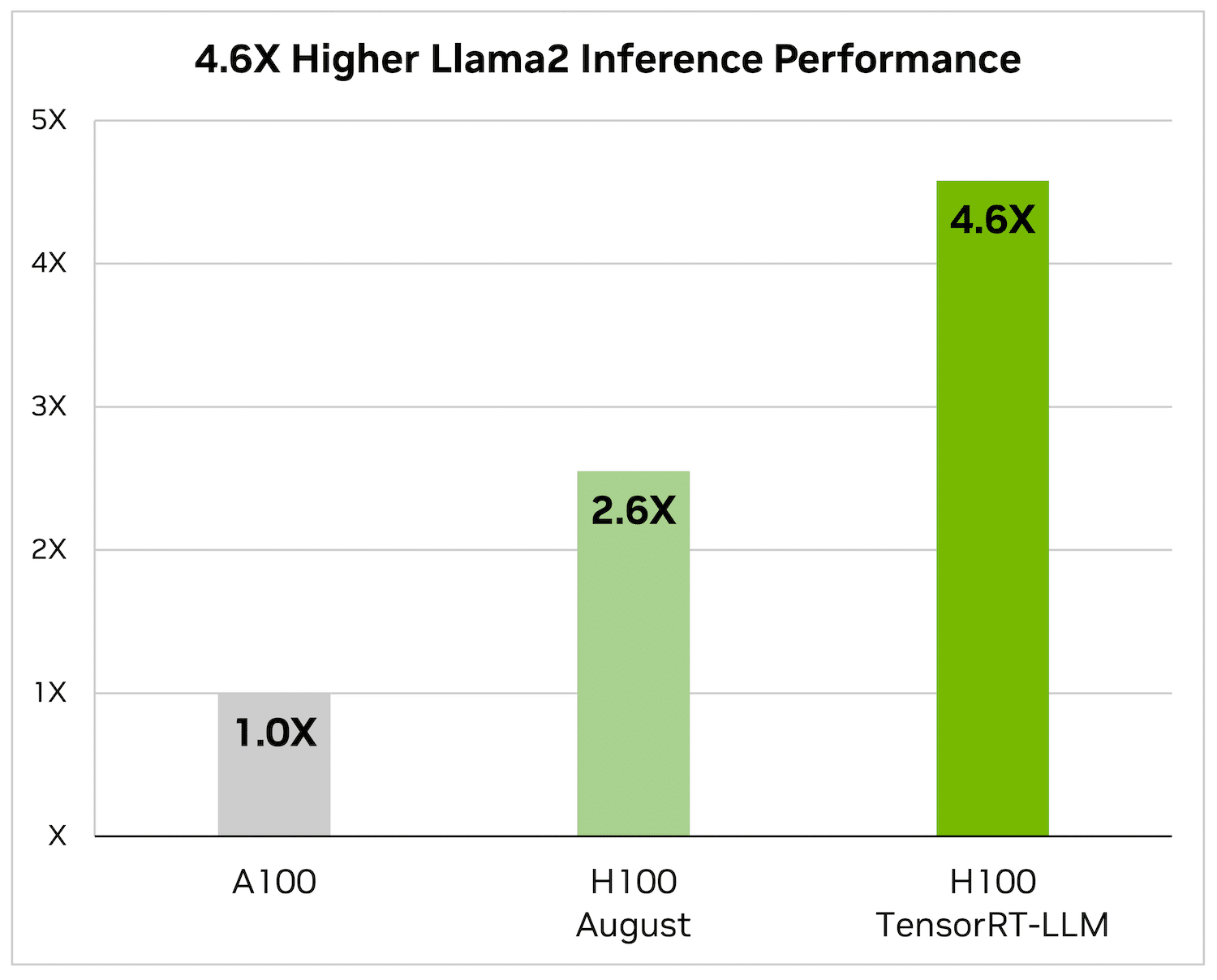
På Llama 2 – en populär språkmodell som nyligen släpptes av Meta och används flitigt av organisationer som vill införliva generativ AI – kan TensorRT-LLM accelerera slutledningsprestanda med 4.6x jämfört med A100 GPU:er.
LLM Ecosystem Innovation utvecklas snabbt
Ekosystemet Large Language Model (LLM) utvecklas snabbt, vilket ger upphov till olika modellarkitekturer med utökade möjligheter. Några av de största och mest avancerade LLM:erna, som Metas 70-miljarder-parameter Llama 2, kräver flera GPU:er för att ge realtidssvar. Tidigare involverade optimering av LLM-inferens för toppprestanda komplexa uppgifter som att manuellt dela upp AI-modeller och koordinera GPU-exekveringen.
TensorRT-LLM förenklar denna process genom att använda tensorparallellism, en form av modellparallellism som fördelar viktmatriser över enheter. Detta tillvägagångssätt möjliggör effektiv utskalning av slutledningar över flera GPU:er sammankopplade via NVLink och flera servrar utan ingripande av utvecklare eller modelländringar.
När nya LLM:er och modellarkitekturer dyker upp kan utvecklare optimera sina modeller med de senaste NVIDIA AI-kärnorna som finns tillgängliga i TensorRT-LLM, som inkluderar banbrytande implementeringar som FlashAttention och maskerad uppmärksamhet med flera huvuden.
Dessutom inkluderar TensorRT-LLM föroptimerade versioner av allmänt använda LLM, såsom Meta Llama 2, OpenAI GPT-2, GPT-3, Falcon, Mosaic MPT, BLOOM och andra. Dessa kan enkelt implementeras med hjälp av det användarvänliga TensorRT-LLM Python API, vilket ger utvecklare möjlighet att skapa skräddarsydda LLM:er skräddarsydda för olika branscher.
För att hantera den dynamiska naturen hos LLM-arbetsbelastningar introducerar TensorRT-LLM batchning under flygning, vilket optimerar schemaläggningen av förfrågningar. Denna teknik förbättrar GPU-användningen och nästan fördubblar genomströmningen på verkliga LLM-förfrågningar, vilket minskar den totala ägandekostnaden (TCO).

Dell XE9680 GPU-block
Dessutom använder TensorRT-LLM kvantiseringstekniker för att representera modellvikter och aktiveringar med lägre precision (t.ex. FP8). Detta minskar minnesförbrukningen, vilket gör att större modeller kan köras effektivt på samma hårdvara samtidigt som minnesrelaterad overhead minimeras under körning.
LLM-ekosystemet går snabbt framåt och erbjuder större möjligheter och tillämpningar inom olika branscher. TensorRT-LLM effektiviserar LLM-inferens, förbättrar prestanda och TCO. Det ger utvecklare möjlighet att optimera modeller enkelt och effektivt. För att få tillgång till TensorRT-LLM kan utvecklare och forskare delta i programmet för tidig åtkomst via NVIDIA NeMo-ramverket eller GitHub, förutsatt att de är registrerade i NVIDIA Developer Program med en organisations e-postadress.
Utgående Tankar
Vi har länge noterat i The Lab att det finns overhead tillgängliga som underutnyttjas av mjukvarustacken, och TensorRT-LLM gör det klart att förnyat fokus på optimeringar och inte bara innovation kan vara extremt värdefullt. När vi fortsätter att experimentera lokalt med olika ramverk och banbrytande teknologi, planerar vi att oberoende testa och validera dessa vinster från de förbättrade biblioteks- och SDK-versionerna.
NVIDIA spenderar helt klart utvecklingstid och resurser för att pressa ut varenda droppe prestanda ur sin hårdvara, ytterligare befästa sin position som branschledare och fortsätta sina bidrag till samhället och demokratisering av AI genom att behålla verktygens öppen källkod. .
Engagera dig med StorageReview
Nyhetsbrev | Youtube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | Rssflöde