
 Det finns flera alternativ för förvaring på marknaden idag. De flesta av differentiatorerna där ute involverar olika hastigheter, fler 9:or i tillgänglighet eller varierande GUI-stöd. Sammantaget är arrayerna väldigt lika; de erbjuder bara olika priser och support eller funktioner som är riktade till en viss grupp kunder. DataGravity har kommit in i bilden och erbjuder något som verkligen är annorlunda. DataGravitys fokus ligger inte på hur snabbt data kan lagras eller hämtas, och det är inte heller fokuserat på hur många enheter du får plats i en 2U-formfaktor; åtminstone inte än i alla fall. DataGravity handlar om att kunna förstå din data och att hjälpa kunder att enkelt hitta den, rapportera om den och säkerställa efterlevnad av industri- eller interna policyer.
Det finns flera alternativ för förvaring på marknaden idag. De flesta av differentiatorerna där ute involverar olika hastigheter, fler 9:or i tillgänglighet eller varierande GUI-stöd. Sammantaget är arrayerna väldigt lika; de erbjuder bara olika priser och support eller funktioner som är riktade till en viss grupp kunder. DataGravity har kommit in i bilden och erbjuder något som verkligen är annorlunda. DataGravitys fokus ligger inte på hur snabbt data kan lagras eller hämtas, och det är inte heller fokuserat på hur många enheter du får plats i en 2U-formfaktor; åtminstone inte än i alla fall. DataGravity handlar om att kunna förstå din data och att hjälpa kunder att enkelt hitta den, rapportera om den och säkerställa efterlevnad av industri- eller interna policyer.
Det finns flera alternativ för förvaring på marknaden idag. De flesta av differentiatorerna där ute involverar olika hastigheter, fler 9:or i tillgänglighet eller varierande GUI-stöd. Sammantaget är arrayerna väldigt lika; de erbjuder bara olika priser och support eller funktioner som är riktade till en viss grupp kunder. DataGravity har kommit in i bilden och erbjuder något som verkligen är annorlunda. DataGravitys fokus ligger inte på hur snabbt data kan lagras eller hämtas, och det är inte heller fokuserat på hur många enheter du får plats i en 2U-formfaktor; åtminstone inte än i alla fall. DataGravity handlar om att kunna förstå din data och att hjälpa kunder att enkelt hitta den, rapportera om den och säkerställa efterlevnad av industri- eller interna policyer.

Det är viktigt att förstå nyansen av var DataGravity passar. Inom företaget finns det ofta stora dataanalys- och säkerhetsteam där ute som har i uppdrag att hitta och säkra data, men det är inte den marknad DataGravity går efter. DataGravity riktar sig till mellanklassmarknaden som i de flesta fall har begränsad IT-personal, men samma datautmaningar som stora företag. Varför skulle DataGravity fokusera en så komplicerad process på någon som verkar dåligt rustad att använda den? För som DataGravity-grundaren Paula Long säger, om du kan surfa på nätet kan du använda den här produkten. Automatisering är nyckeln till att lösa dessa problem.
DataGravity Discovery Series-familjen fungerar genom att förstå data i filer. Genom att kunna söka i ett Word-dokument, till exempel för att kontrollera personnummer, erbjuder DataGravity-arrayen omedelbar insyn i de filer som ett företag lagrar. DataGravity kan sedan förstå denna data, rapportera om den och säkerställa att känslig information inte delas med olämpliga parter. Förutom att förstå data som lagras i arrayen, granskas all filåtkomst och användaraktivitet, vilket hjälper företag att uppfylla sina efterlevnads- och säkerhetskrav. Detta är en viktig skillnad för att förstå vad DataGravity är och vad det inte är. DataGravity är mycket fokuserat på detta ostrukturerade dataanvändningsfall, som är en vanlig lekplats för NAS och liknande. Även om de stöder iSCSI, NFS och SMB, är det primära användningsfallet för DataGravity inte vanliga affärsapplikationer som e-post, transaktionsdatabas och sådant. Plattformen kan komma dit så småningom, och kommer förmodligen att göra det, men idag är deras mål extremt väldefinierat.

Data som personnummer, patient-ID, telefonnummer, kreditkortsnummer och liknande är lätta att definiera och förstå. Faktum är att DataGravity stöder många vanliga efterlevnadstaggar direkt. Det är dock inte begränsat till dessa. För organisationer som har unika behov, som många företag gör, erbjuder DataGravity en redigerare som tillåter organisationer att skapa sina egna taggar. Detta säkerställer att användare av plattformen snabbt kan svara på säkerhets-, efterlevnads- och eDiscovery-krav som är specifika för deras bransch. Insynen i lagrad data ger också bättre affärsvärde genom att göra allt sökbart, baserat på åtkomstregler förstås.

DataGravity erbjuder arrayer i flera konfigurationer som utnyttjar nearline hårddiskar för kapacitet och flash som läscache. Enheterna är dubbla kontroller, med varje kontrollenhet "aktiv" och gör ett specifikt jobb som vi kommer att dyka mer in på nedan. DG1100 kommer i 18TB rå diskkapacitet och DG1200 kommer med 36TB rå. DG2200 erbjuder 48TB och DG2400 ger 96TB till bordet. För närvarande är dessa inte utbyggbara, men DataGravity ser tydligt behovet av att ta itu med detta; troligen med expansionshyllor och/eller ett hanteringsgränssnitt som sammanför flera system till en enda hanteringsvy. Vår testning för denna recension är helt inriktad på användbarhet; vi tillbringade två dagar med DataGravity på deras kontor i Nashua, NH och avslutade uppföljningsarbetet på distans. Detta gav oss lite praktisk tid med en DG1100-enhet.
arkitektur
DataGravity har dubbla aktiva aktiva kontroller med en twist. Normalt innebär en aktiv-aktiv dubbelstyrenhet att båda styrenheterna är aktiva med I/O-bearbetning. Men med DataGravity efterliknar arkitekturen aktiv-passiv, med den primära noden som betjänar data och intelligensnoden hanterar dataanalys. DataGravity kallar detta "aktivt-proaktivt". Grundinställningen ser ut så här: flera GB DRAM, batteristödd NVRAM, SSD:er för metadata och cache, och sedan nearline hårddiskar.
Med en inte så obetydlig mängd data som flödar genom DRAM och batteristödd NVRAM, speglar DataGravity skrivningar mellan den primära noden och intelligensnoden som en första order. Detta görs genom en intern PCIe-brygga, som erbjuder hög bandbredd och kommunikation med låg latens. Denna snabblänk utnyttjas i DataGravity-arkitekturen för dess kontinuerliga dataskydd och dataanalys. Data under flygning speglas tills den primära noden kan överföra den till disk. När båda kontrollerna sätts i arbete, utnyttjar Discovery-serien en primär lagringsnod för produktions-I/O, och sätter den typiskt inaktiva sekundära noden att fungera som en intelligensnod. Intelligensnoden utnyttjar metadata och finkorniga skrivningar speglade till denna kontroller för kontinuerligt skydd och datamedveten analysbearbetning.
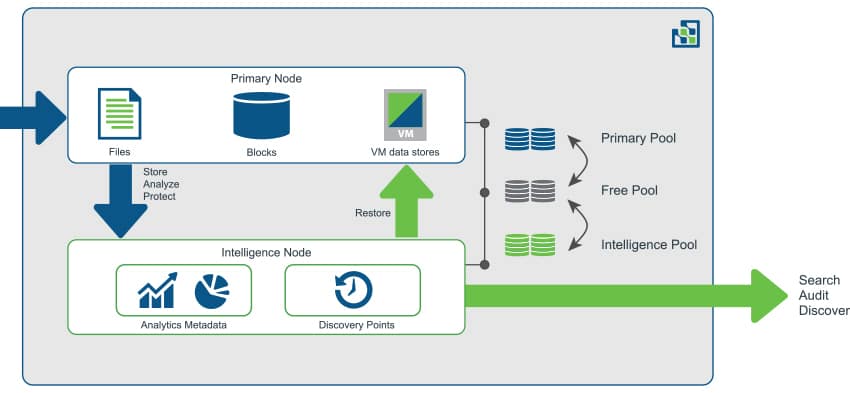
Medan aktiv-aktiv (eller aktiv-proaktiv i det här fallet) har fördelen av att använda det som har betalats för (mot aktiv-passiv där den andra noden sitter vilande tills den primära misslyckas), en fråga som alltid tenderar att dyka upp: Vad händer med prestandan om en nod misslyckas? Om DataGravity behöver två noder för att fungera sin magi och en går förlorad, var lämnar det kunderna? Vid ett nodfel tar den återstående noden över grunderna för produktionen. Användare kommer fortfarande att kunna komma åt och använda filer som de skulle göra i sin normala dagliga verksamhet. Men huvuddelen av analysen avbryts tills den misslyckade noden återställs. Med andra ord, tillgängligheten kvarstår men de metadatacentrerade funktionerna reduceras tills nodåterställning.
användbarhet
DataGravity GUI är HTML 5-baserat och har en mycket enkel och användbar layout. Fliken Hem har bara tre alternativ att välja mellan: Upptäck, Lagring eller System. Längs upp till höger ser vi Global Access Panel, som innehåller ikoner för systemets instrumentpanel och varningar, arbetsyta, profil och onlinehjälp.
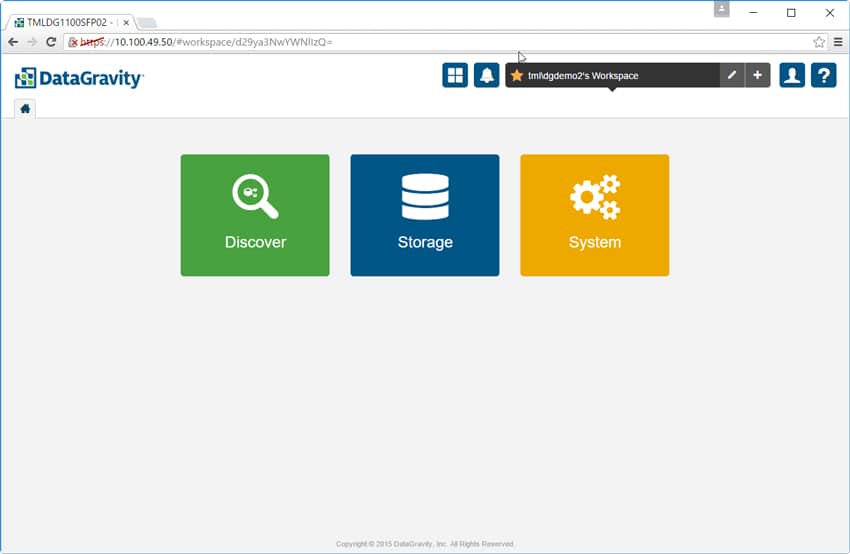
Systemets instrumentpanel ger användarna en snabb blick på statistik som antalet monteringspunkter, totalt antal skyddade filer, pooltilldelning och statistik över dataanvändning.
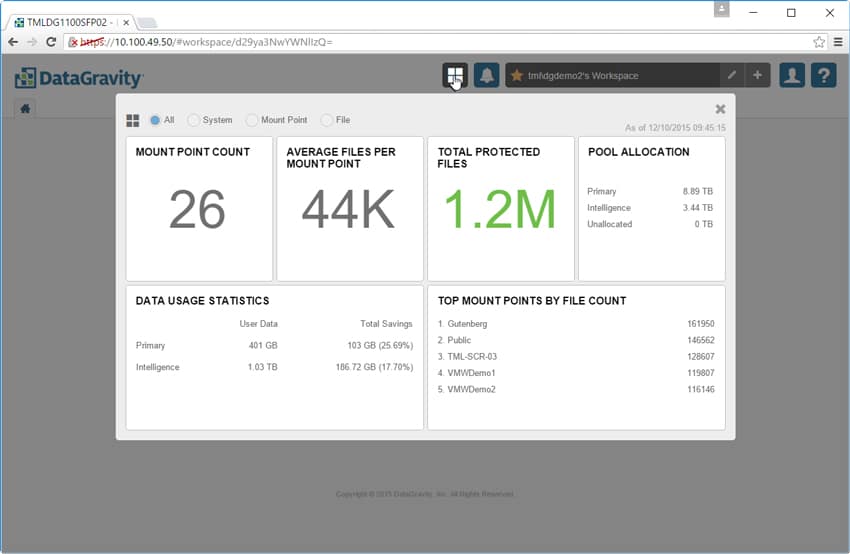
Fliken Systemlarm är som den låter och ger användarna en lista över larm och var de inträffade i systemet.
Till höger om larmfliken finns fliken Arbetsyta. Här kan användare byta namn på eller lägga till arbetsytor. Arbetsytor tillåter användare att konfigurera och hantera sin privata vy av systemet. Användare kan konfigurera flera arbetsytor beroende på deras behov.

Nästa ikon är profilikonen. Genom att klicka på profilikonen har en auktoriserad användare möjlighet att hantera sin profil; e-postprenumerationer för sparade sökningar och kan logga ut ur systemet. Vid inloggning tillhandahåller det grafiska användargränssnittet flera brickor som visar information som användningssammanfattning över tid och senaste aktivitet (var och en uppdelad efter läsningar, uppdateringar, raderingar och i fallet med användning skapar. Det finns också ett ackorddiagram som visar vem varje användare samarbetar med och i vilken egenskap.
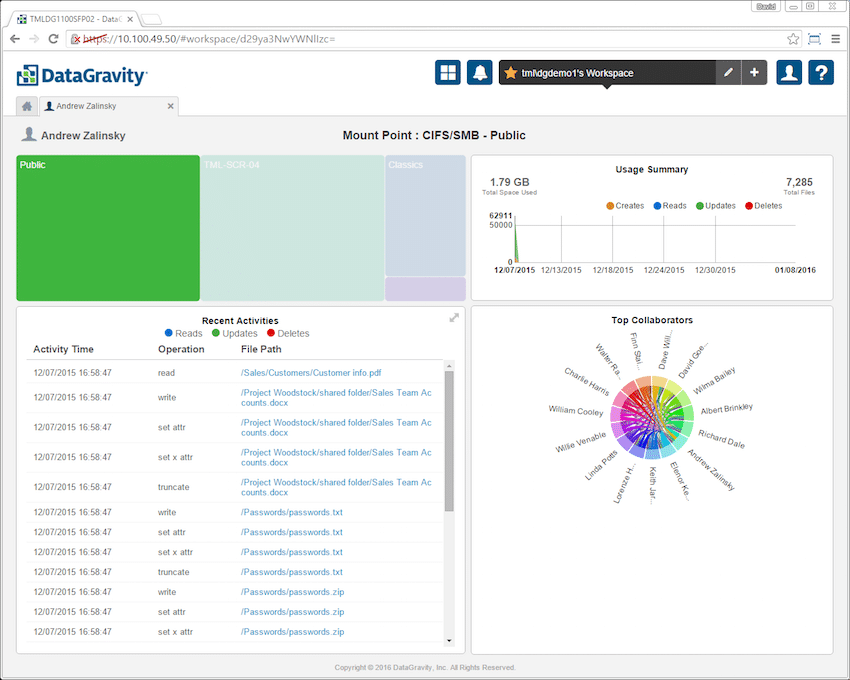
Om du går tillbaka till startfliken är ikonen längst till vänster dataGravitys bröd och smör, fliken Upptäck. Genom att klicka på fliken får användarna alternativ som sökning, trender, filanalys, aktivitetsspårning och innehållsvarningar.
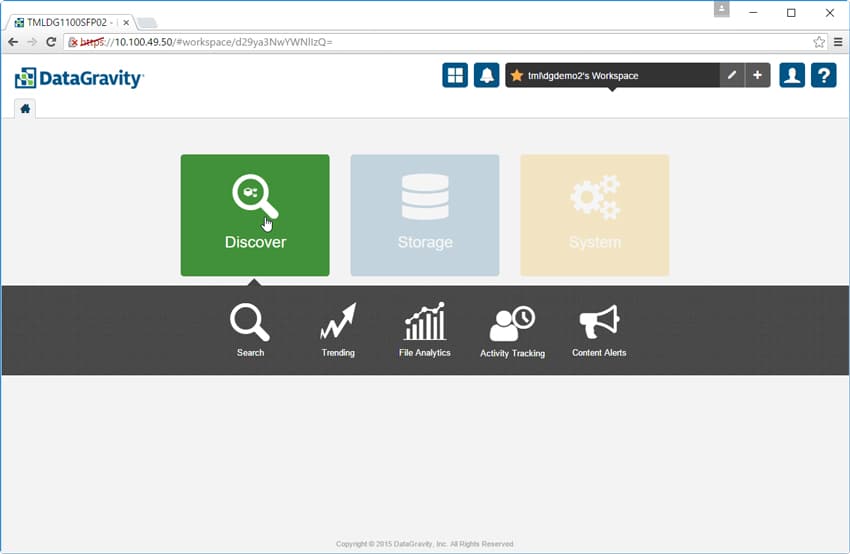
Sök är som det låter. Ett sökfält kommer upp och användarna behöver bara ange nyckelordet eller filnamnet de söker efter. Innan de söker måste användarna välja den monteringspunkt de vill söka i. I bilden nedan är sökningen efter "projekt woodstock". Detta returnerade alla filer i den offentliga monteringspunkten som innehöll dessa termer. Filter till vänster gör det möjligt att skärpa resultatet ytterligare.
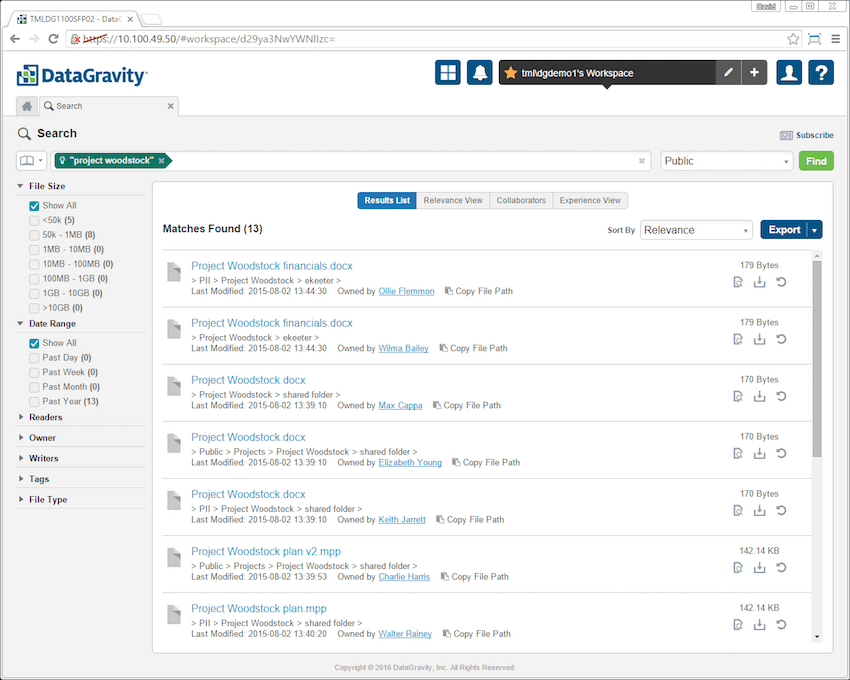
Trender liknar sökning, bara här lägger användare in nyckelordet eller taggen de letar efter och lösningen kommer att ge dem en grafisk representation av datan. Detta gör att företag kan se hur data nås i både live och raderade filer över tid. I skärmlocket nedan angavs kreditkortstaggen (CC) i trend. Resultaten visar hur kreditkortsnummer har trendat över tid i Public Mount Point.
File Analytics är en annan plats där DataGravity skiljer sig från resten av lagringsleverantörerna. Genom denna instrumentpanel kan användare enkelt se filresurser och virtuella maskiner representerade av färgade block på höger sida. Ju större andel, vad gäller kapaciteten som förbrukas, desto större är det färgade blocket. Användare kan också se de 10 bästa användarna efter utrymme som konsumeras i ett stapeldiagram, de flesta aktiva användare (ju mer aktiva användaren desto större namn visas), och vilande data och hur länge data har varit inaktiva grupperade efter 1, 3, 6 , 9 och 12 månaders kategorier.
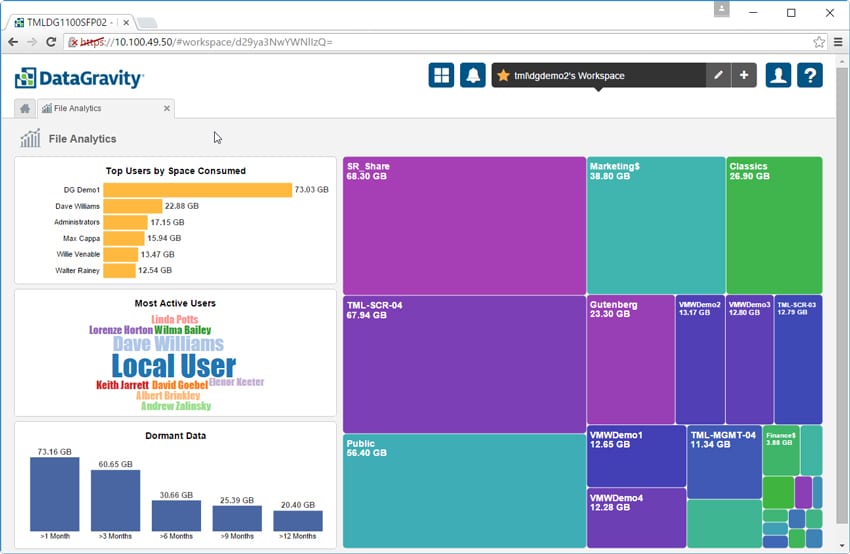
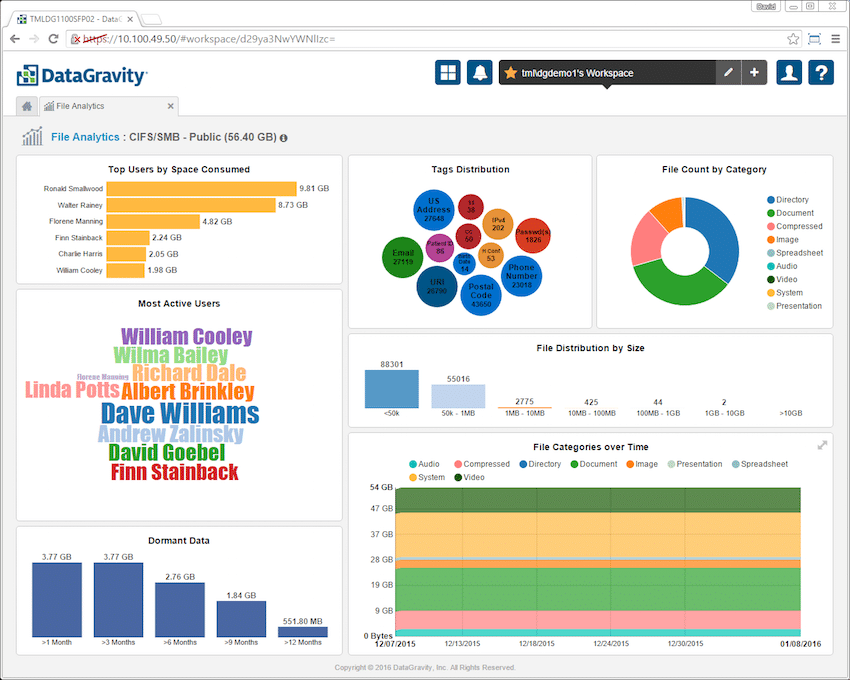
Genom att klicka på en enskild filresurs eller virtuell dator bryter du ner denna information ytterligare. Till vänster finns information om de mest aktiva användarna (mätt med läs-/skriv-/raderingsoperationer) och toppanvändarna efter utrymme inom resursen eller virtuell dator. Det finns också en lista för vilande data. Till höger finns ytterligare fyra brickor: taggardistribution, filantal efter kategori, fildistribution efter storlek och filkategorier över tid. Genom att klicka på varje ruta får du mer detaljer.
Nästa flik i upptäcksavsnittet är aktivitetsspårning. Som namnet antyder kan administratörer och säkerhetsanvändare snabbt se vilken användare som utförde vilken aktivitet under en viss tidsperiod. Administratörer behöver bara välja vilken monteringspunkt som ska sökas och användaren och datumintervallet.
![]()
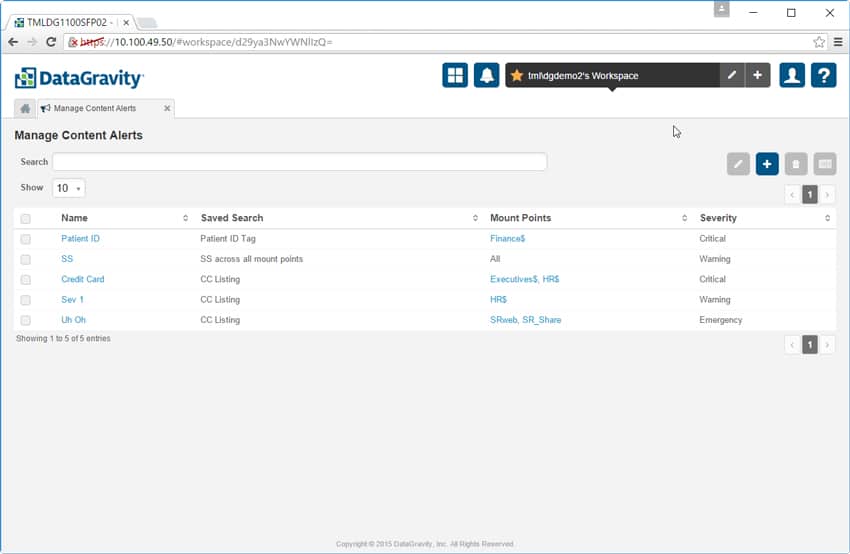
Den sista fliken i Discover-sektionen låter administratörer hantera innehållsvarningar. I exemplet nedan har administratören ställt in varningar som ska meddelas när personnummer eller kreditkortsnummer hittas i öppen text, okrypterade format och på platser där de inte hör hemma. Detta ger företag möjlighet att snabbt hitta och flytta kritisk data som har placerats på osäkra platser.
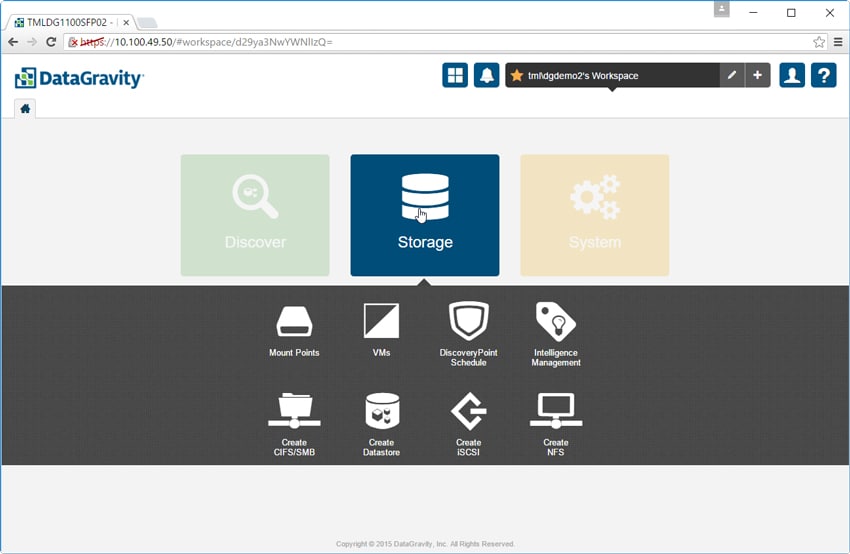
Nästa huvudflik är fliken Lagring. Det finns 8 underflikar här: Montera punkter, virtuella datorer, DiscoveryPoint-schema, Intelligence Management, Skapa CIFS/SMB, Skapa datalager, Skapa iSCSI och Skapa NFS.
Fliken Hantera monteringspunkter låter användare se inställningarna för varje monteringspunkt samt skapa nya. Här kan användare se kapaciteten för varje monteringspunkt (liksom mängden som används), en kort beskrivning av varje, dess skyddspolicy och dess status. Varje ny monteringspunkt som skapas här kan få dessa inställningar justerade efter behov.
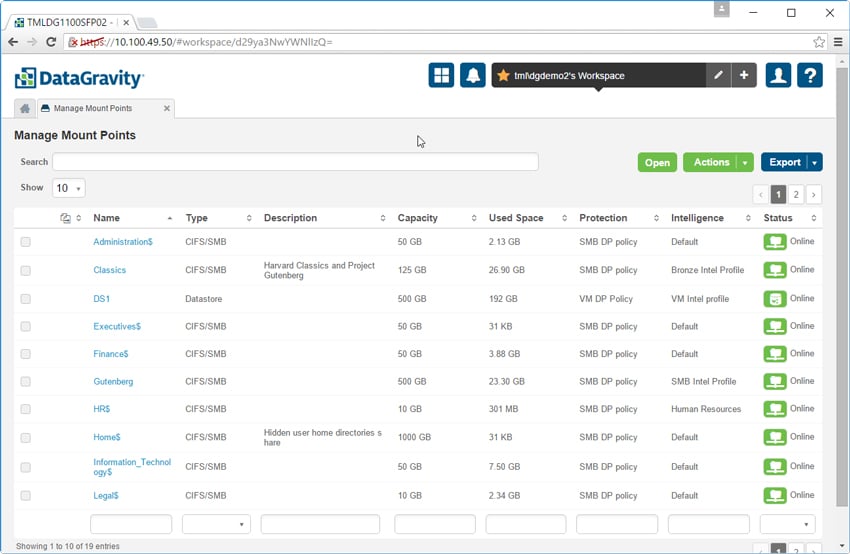
Fliken Hantera virtuella datorer liknar ovanstående. Här är det möjligt att se och konfigurera information om de virtuella datorerna. Den virtuella datorns namn listas liksom dess plats, operativsystem, kapacitet, skyddspolicy, intelligensprofil och om den virtuella datorn är igång eller avstängd. Om du klickar på en virtuell dator får du ytterligare information.
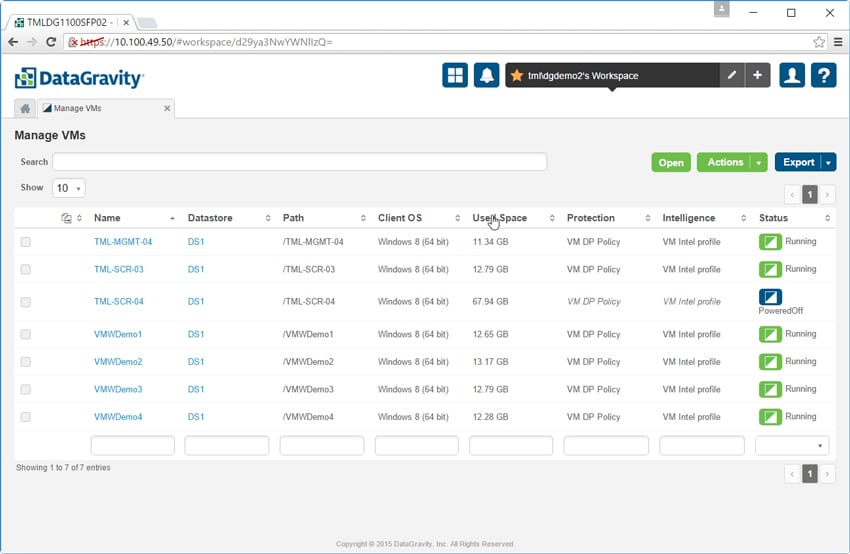
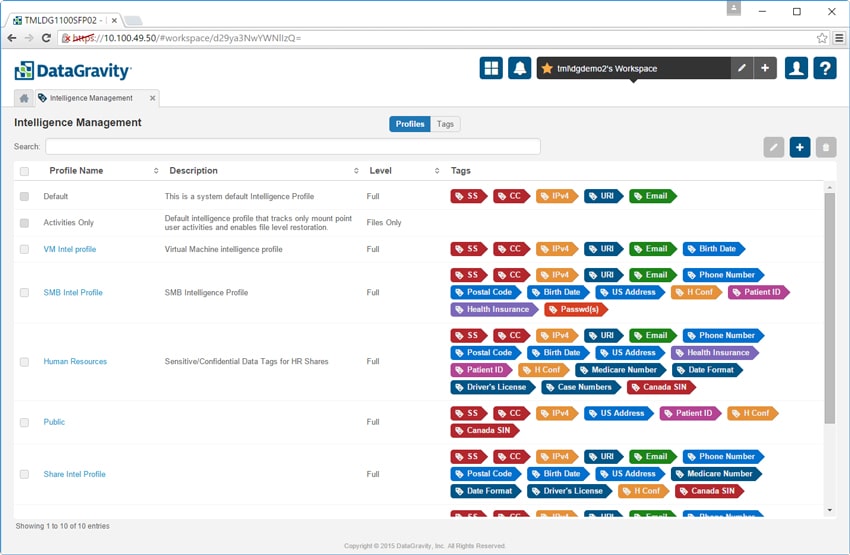
Fliken Intelligence Management låter administratörer konfigurera intelligensprofiler för specifika användningsfall och tillämpa dem på monteringspunkter och virtuella datorer. Knappen Tags låter administratörer definiera mönster eller fraser av innehåll som innehåller känsliga data med hjälp av en inbyggd redigerare för reguljära uttryck.
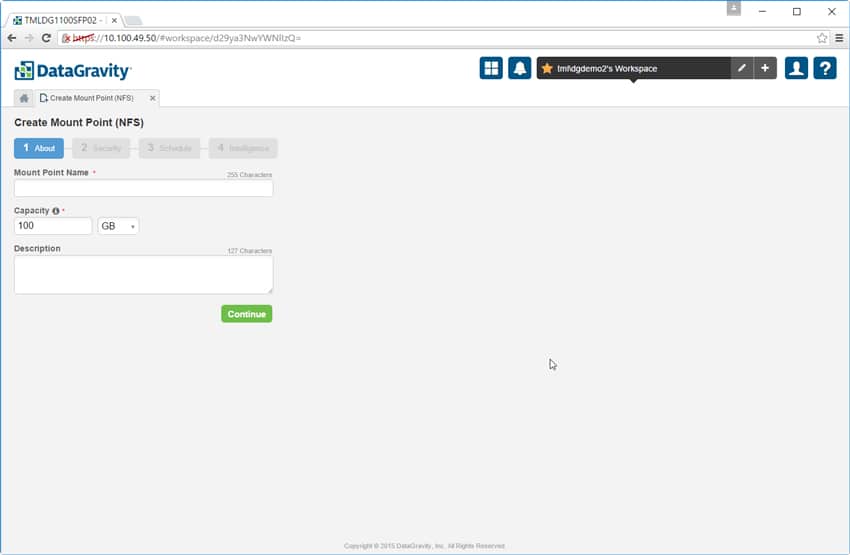
De nästa fyra flikarna handlar alla om att skapa en monteringspunkt och dess åtkomstprotokoll, oavsett om det är CIFS/SMB, VM-medveten NFS DataStore, iSCSI eller NFS (bilden nedan). Administratörer lägger till ett namn för monteringspunkten, lägger till en beskrivning om de vill, väljer kapacitet, ställer in säkerhetspolicy, definierar DiscoveryPoint-schemat och väljer intelligensprofil.
Det sista huvudavsnittet är fliken System. Genom att klicka på den får vi fyra underflikar: Systemhantering, Användaråtkomst, Notifieringspolicyer och VMware-referenser.
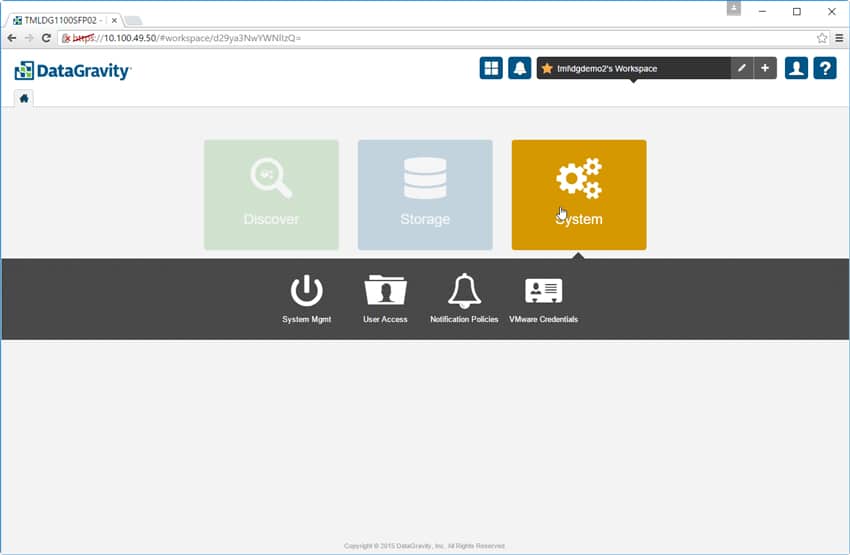
Fliken System Mgmt har flera alternativ, inklusive System Health som ger en bild av det fysiska systemets tillstånd. Till vänster finns en lista över alla komponenter i lösningen. Till höger finns en grafisk representation som ger användaren mer information genom att hålla muspekaren över den.
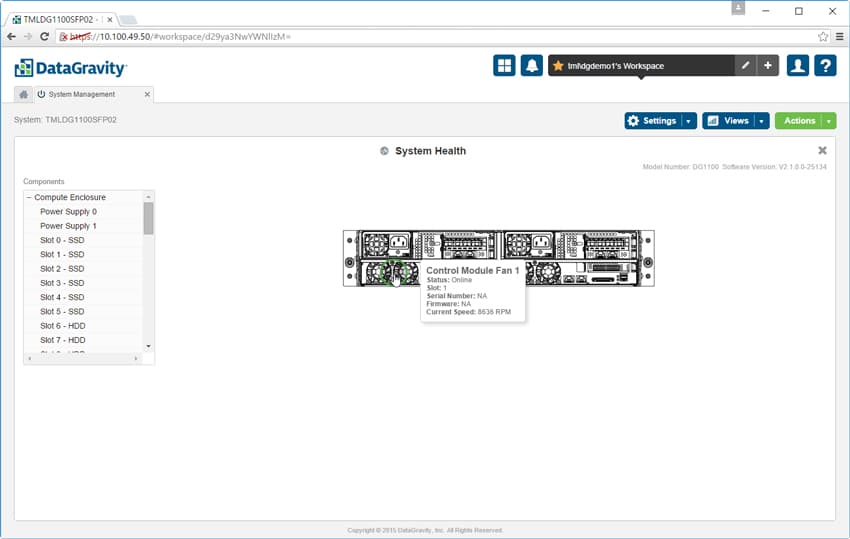
Inom System Mgmt finns också sektionen Storage Pools, som ger en vy av tre olika pooler i DataGravity-systemet: den primära poolen eller poolen som är allokerad för daglig användning, intelligenspoolen och den fria poolen för lagring som har ännu inte tilldelas. Från den här skärmen kan användare ändra storlek på poolerna efter behov.
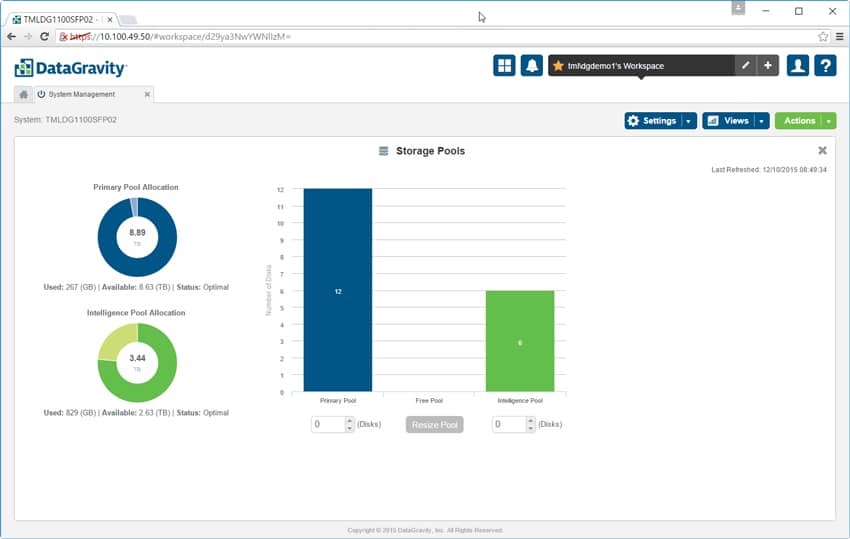
Det finns också ett alternativ för att se systemets prestanda. Prestandavyn visar både läs- och skriv-I/O och ger detaljer som genomströmning i MB/s, IOPS, latens och ködjup. Användare kan titta på prestanda över en tidsperiod eller titta på en realtidsavläsning av prestanda.
Och slutligen under System Mgmt kan administratörer se revisionsloggarna. De kan inte bara se vem som loggat in och vad de sysslat med, loggarna kan filtreras för enklare visningsåtkomst och vidarebefordras till ett annat system för vidare bearbetning.
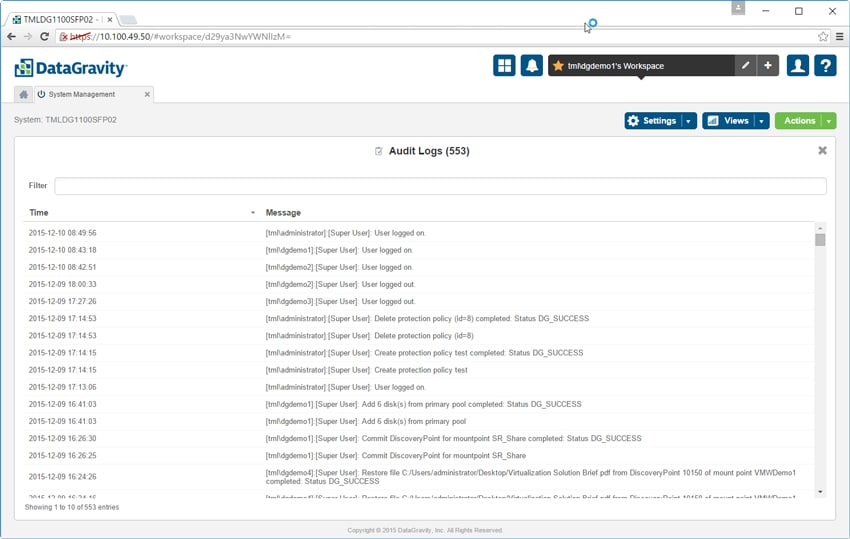
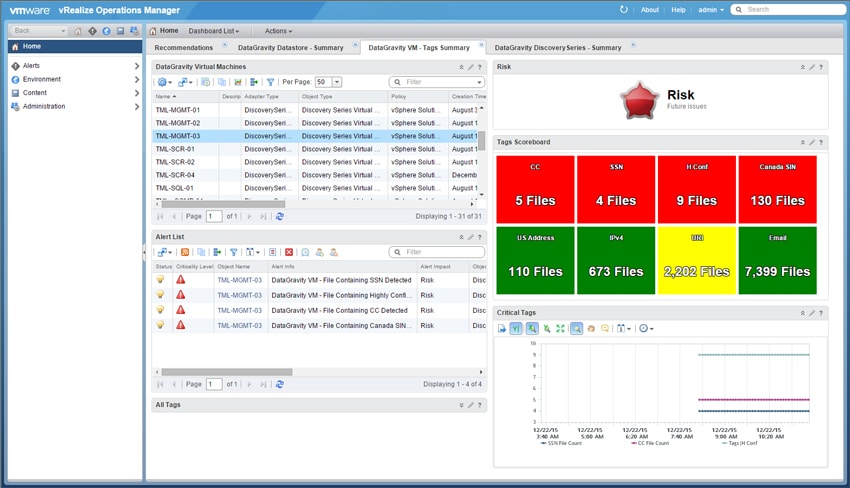
DataGravity integreras också med VMware vRealize Operations Manager (vROPS) för att lägga upp analysen av DataGravity-systemet i den centraliserade konsolen vROPS tillhandahåller. DataGravity har ingen virtuell närvaro i sig, så den här integrationen möjliggör för virtualiseringsadministratören att se in i systemet utan att vara inloggad i DataGravitys användargränssnitt. Även om all information finns, är datavisualiseringar begränsade jämfört med DataGravity GUI.
vROPS-integrationen visar sammanfattningar av Discovery Series, DataStore eller VM. Nedan är en vy av Discovery Series-översiktsinstrumentpanelen som visar systemets övergripande kapacitet och prestanda samt latens för datalagrar och virtuella datorer som är lagrade i systemet med riskpoäng för var och en.
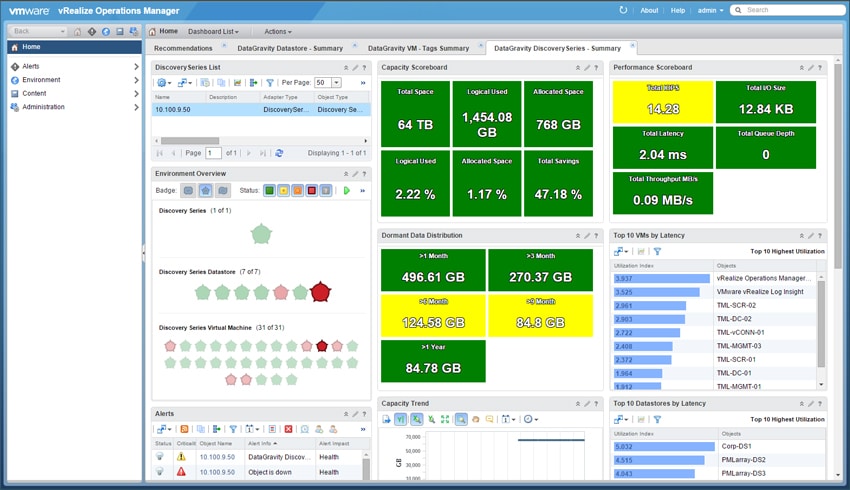
När du tittar på DataGravity Datastore Summary-instrumentpanelen visas liknande mätvärden för DataGravity-datamedvetna, NFS-datalager.
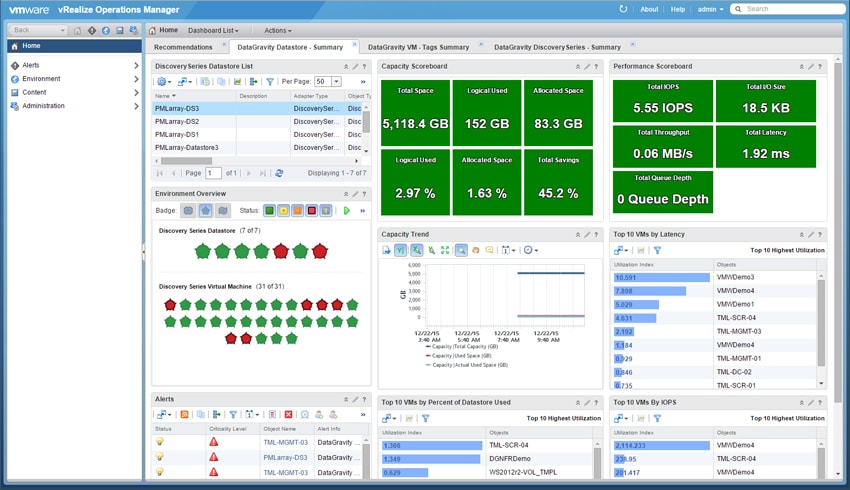
vROPS-integrationen visar också "värmekartor" som visar potentiella problemområden baserat på fördefinierade värden för utrymmesutnyttjande och kritiska intelligenstaggar som finns i virtuella datorer, databutiker och Discovery Series-systemet.
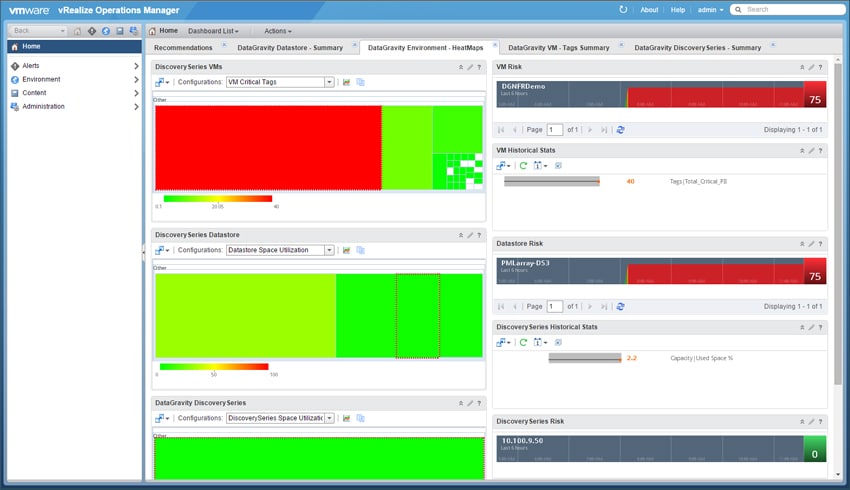
Och virtualiseringsadministratörer kan se vilken data i vilken virtuell dator är i fara. Genom märkningssystemet kan de till och med se mer specifikt vilken typ av data som är i riskzonen.
Slutsats
DataGravitys Discovery Series är en lagringsuppsättning som flyttar fokus bort från ren prestanda och säkerhetskopierings- och återställningsfönster till att vara datamedveten. DataGravity har med andra ord byggt ett system som ger användarna insyn i all sin data genom ett lättanvänt GUI. Det tillåter inte bara användare att se var deras data finns i systemet, det ger dem en djupgående metod för att spåra data, vem som kommer åt dem och om känslig data kan exponeras. DataGravity tillåter användare att tagga de flesta filtyper vilket hjälper till att snabbt hitta och övervaka specifika datafiler. Detta kan inte bara göra ett företags data säkrare genom att hitta problem (oavsett om det är oavsiktligt eller skadligt), det ger också ett företag möjlighet att fullt ut använda all sin lagrade data genom att förstå datalokalitet, åtkomst, lagringsbehov och efterlevnad.
Normalt tittar vi på StorageReview på den underliggande hårdvaran och testar dess prestanda genom en serie riktmärken. När det gäller DataGravity är programvaran det starkaste försäljningsargumentet. Medan företaget erbjuder flera kapaciteter från 18 TB till 96 TB, och de har en kombination av RAM, NVRAM, SSD:er och nearline-hårddiskar i sin lösning, finns den underliggande hårdvaran för att stödja DataGravity-analysplattformen. Naturligtvis finns all hårdvara för att stödja mjukvara, men de flesta leverantörer använder de två parallellt med att leverera klassiska lagringsmöjligheter. DataGravity gör inga påståenden om att vara den högst presterande eller lägsta latensen. DataGravity fokuserar istället på datamedvetenhet och användarvänlighet. På denna punkt utmärker sig företaget klart.
StorageReview-teamet gick på plats för att testa lösningen. Eftersom vårt fokus denna gång låg på användbarhet behövde vi ingen fysisk enhet i vårt labb för att köra våra prestandatester mot. Innan vi anlände tog DataGravity in en stor del av innehållet på vår webbplats i deras array och gav oss data att söka som vi var väl bekanta med. Med bara en grundläggande översikt av systemet kunde vi börja intuitivt använda lösningen för att söka efter nyckelord i olika typer av filer, skapa resurser, omtilldela datapooler, samt se hur vår användning av lösningen spårades.
I slutändan skiljer sig det DataGravity gör exceptionellt från resten av lagringsindustrin. Veteranteamet bestämde sig för att först lösa legitim affärssmärta och använda insyn i lagringsefterlevnad som kroken. Denna betoning på intelligens är grundläggande för vad DataGravity handlar om, vilket skiljer sig mycket från traditionella lagringsköp som är baserade på ett kapacitets- eller genomströmningsbehov. Även om DataGravity-tillvägagångssättet är mycket meningsfullt i reglerade branscher, såg till och med vårt användningsfall för småföretag omedelbara fördelar när vi kunde ha en djupgående bild av till och med en del av vårt utåtriktade innehåll. Kombinera den insikten med samma för användarhemkataloger, delade mappar för arbetsgrupper och resten av affärstillgångarna och fördelarna blir snabbt fler. Det är också väldigt intuitivt att använda, vilket gör DataGravity till en bra passform för små eller överbelastade IT-butiker.
The Bottom Line
DataGravitys Discovery-serie gör det möjligt för företag att fullt ut använda all sin data samtidigt som den håller den säker och handlingsbar via lättanvänt gränssnitt. Tonvikten på analys och synlighet i data är verkligen unik i lagringsindustrin, vilket ger DataGravity en viktig differentieringspunkt i en bransch som ofta saknar kreativitet.
Anmäl dig till StorageReviews nyhetsbrev