
I åratal har automatiserad lagringsnivå varit en viktig lösning för företag som vill hantera sitt datacenter på ett effektivt sätt samtidigt som de minskar den totala ägandekostnaden (TCO). Strategin är enkel: använd algoritmer och policyer för automatisk nivåindelning och behåll aktiv data på primär lagring samtidigt som inaktiv data flyttas till billiga lagringskategorier. Under de senaste åren har Cloud Tiering vuxit fram som en robust, kostnadseffektiv lösning som hanterar förflyttning av inaktiv data till lågkostnadsobjektlagring i molnet. Med ThinkSystem DM-serien gör Lenovo det möjligt för företag att hantera data och molnalternativ med en intelligent lagringslösning. Denna molnstrategi hanterar framgångsrikt kapacitet, smidighet och säkerhet i hybrid-molnmiljöer, utan att kompromissa med hanterbarhet, säkerhet eller prestanda.
I åratal har automatiserad lagringsnivå varit en viktig lösning för företag som vill hantera sitt datacenter på ett effektivt sätt samtidigt som de minskar den totala ägandekostnaden (TCO). Strategin är enkel: använd algoritmer och policyer för automatisk nivåindelning och behåll aktiv data på primär lagring samtidigt som inaktiv data flyttas till billiga lagringskategorier. Under de senaste åren har Cloud Tiering vuxit fram som en robust, kostnadseffektiv lösning som hanterar förflyttning av inaktiv data till lågkostnadsobjektlagring i molnet. Med ThinkSystem DM-serien gör Lenovo det möjligt för företag att hantera data och molnalternativ med en intelligent lagringslösning. Denna molnstrategi hanterar framgångsrikt kapacitet, smidighet och säkerhet i hybrid-molnmiljöer, utan att kompromissa med hanterbarhet, säkerhet eller prestanda.

Den här artikeln diskuterar hur Lenovo ThinkSystem Storage Solutions och DM-serien erbjuder en heltäckande datacenterstrategi, från on-prem till molnet. Först kommer vi att beröra några grundläggande begrepp om datalagring, molnnivå och nya utmaningar för lagringshantering. Vi ska titta på Lenovos ekosystem för datahantering, och hur företaget sticker ut på lagringsmarknaden med DM-serien. Vi kommer också att ta en närmare titt på ONTAP-programvaran och FabricPools policyer för lagringsnivåer. Och slutligen, från vårt labb, kommer vi att visa Lenovos molnnivålösnings konfiguration och validering.
I en traditionell datacentermodell, när ett företag växer, börjar det samla in kritisk data och filer i sina lokaler. Men dessa data blir så småningom gamla och nås sällan, vilket tillägnar sig värdefull prestanda och kapacitet från den primära och sekundära lagringen, vilket påverkar kritiska arbetsbelastningar. Att arkivera dessa data tidigare var en praktisk lösning för företag; Men genom att göra detta är informationen inte omedelbart tillgänglig om den plötsligt skulle behövas.
Det här problemet har skapat medvetenhet bland IT-organisationer att överväga lagringsnivåer med olika kapacitets-, kostnads- och prestandaegenskaper. De måste också erkänna och vara beredda att möta kraven på datatillväxt över flera och molnmiljöer. Cloud Tiering är svaret, och det måste övervägas i moderna lagringsarkitekturer. Annars kommer ett växande datafotavtryck att överväldiga investeringen företaget gjort i högpresterande primär lagring i sitt datacenter.
Molnet som lagringsnivå
När mer avancerad teknik blir tillgänglig kan befintliga lagringsnivåer omvandlas efter behov, och ytterligare kan läggas till för att diversifiera den skiktade lagringsarkitekturen ytterligare. Molnet har öppnat nya möjligheter för IT-organisationer, vilket möjliggör lagringslösningar från offentliga molnleverantörer som en ytterligare (lägre) nivå. Om det designas och utförs väl kommer molnet att vara en utmärkt och billigare lösning än en lägre lokal nivå.
I primära lagringsnivåer som använder flash för extremt hög prestanda kan cirka 50 % av kall data allokeras till molnet. Snapshot-kopior och ostrukturerad data utgör ofta denna kategori, inklusive verksamhetskritiska appar. I sekundära nivåer kan kalla data som sitter i lagringen vara upp till 90 % från säkerhetskopior. All denna värdefulla, men bara ibland åtkomliga, data kunde också flyttas till molnet. Populära molnleverantörer och tjänster som är redo att skikta inaktiv data inkluderar Azure Blob-lagring, AWS S3 och Google Cloud Storage.
Liksom lokal automatisk lagringsnivå kan vi skapa policyer och regler för att administrera data för molnet. Villkoren tillåter oss att överföra filer direkt från lokala till det offentliga molnet. Policyer tillämpas på flera sätt. Till exempel kan data flyttas baserat på filens filtillägg, från mönster som ingår i filens namn, eller hur ofta filen nås inom en viss period. Det här sista alternativet är förmodligen det bästa scenariot, där lagringsfiler och block ges temperaturvärden, taggar nyskrivna data som heta och inaktiva som kalla. Genom att implementera en uppsättning policyer för lagringsnivåer kan kall data snabbt flyttas till molnet genom att köra regler på begäran eller enligt schema.
Nya utmaningar för lagringshantering
De största utmaningarna som observeras på marknaden idag kring hybrid-molndatahantering består av volym och variation, datahastighet och dataintegritet.
Datavolymerna växer i nästan exponentiell takt. IT-organisationer måste få grepp om inte bara datatillväxt, utan datatillväxt och hantering i flera miljöer. Volymen och variationen av data som genereras fortsätter att vara överväldigande. Utan kapaciteten att lagra, kategorisera och bearbeta denna data i en hybrid-molnlösning går organisationer miste om kritiska insikter om sina kunder och verksamhet. Dessutom förutspås det att datavolymerna kommer att expandera 10x till 2025 (cirka 163ZB), drivet av IoT och edge-teknologi. Om data är den mest värdefulla tillgången måste den behandlas med omsorg och måste kunna ge insikter till fokuserade beslut, samtidigt som den tillåter en blick in i framtiden. Dessutom är det avgörande för kundernas köpbeslut att hitta mer effektiva sätt att bearbeta denna data för att omvandla den till ett värde.
IT-hoten utvecklas också – och att hålla infrastrukturen säker är en pågående kamp. En bra säkerhetsstrategi är att bygga en solid grund baserad på att veta exakt när, var och hur data lagras. Den här typen av strategi hjälper företag att undvika de stigande kostnaderna i samband med dataintrång, såväl som ny skadlig programvara, katastrofer och regleringar som utgör betydande risker för verksamheten. Datasäkerhet är av absolut betydelse för företag, oavsett om det gäller att skydda mot dataförlust eller säkerställa dataintegritet. Det är här Lenovo täcker alla alternativ och försäkrar att deras kunders data alltid kommer att vara skyddade.
Lenovo ThinkSystem Storage Solutions
Att förutse ny utveckling är också utmanande, liksom att hålla sig à jour med den bästa lagrings- och molnstrategin. Men industrin har redan gjort en enorm investering i forskningsekosystem och plattformar som levererar värde och möjligheter för företaget. Lenovo har tagit nästa strategiska steg för lagringsindustrin och skräddarsytt sin lösning för att möta de största utmaningarna inom datahantering. Detta smarta drag från Lenovo syftar till att tillhandahålla den ultimata lösningen till sina kunder och erbjuder en unik blandning av produkter och tjänster för att göra det möjligt för företag att på bästa sätt använda hybridmolnet.
Lenovo är ett av de unika teknikföretagen på marknaden som tillhandahåller en end-to-end datacenterlösning genom Lenovo Data Center Group (DCG). Dessutom tillhandahåller Lenovo end-to-end säkerhet och programvaruhantering med sitt Intelligent Device Group (IDG) ekosystem. Med dessa erbjudanden och Lenovos ThinkSystem DM-serie kan företag förbättra sin infrastruktur och hantera all arbetsbelastning som körs i deras miljöer.
ThinkSystem DM-serien är Lenovos flaggskeppslagringslösning som erbjuder en mångsidig datahanteringssvit för strukturerad och ostrukturerad data. Det sträcker sig från ingångsutrymmet till ett högt mellanregister och kan tillhandahålla datarika funktioner som inbyggd datareduktion, dataskydd och datasäkerhet. Var och en av DM-serierna kan leverera integrerad hybridmolnkapacitet för offentliga molnleverantörslösningar. Samtidigt bygger Lenovo ut sina end-to-end NVMe-erbjudanden med sina nyligen släppt DM7100F-serien, och planerar senare i år att utöka utbudet av end-to-end NVMe till fler arbetsbelastningar på nybörjarnivå för kunder för att skapa ett infrastrukturomfattande företags-NVMe-tyg.
FabricPools
DM Series Data Management Suite förenar datahantering över flash, disk och moln för att förenkla lagringsmiljöer. Denna omfattande programvara är enkel att använda och mycket flexibel, utformad för effektiv lagring och har robusta datahanteringsfunktioner samt sömlös molnintegrering. Sammantaget syftar DM-serien till att förenkla driftsättning och hantering av data och öka företagsapplikationer; dvs den är framtidsredo för datainfrastrukturer.
Vid sidan av den inbyggda datahanteringskapaciteten finns FabricPool Cloud Tiering-teknik. Det möjliggör automatisk nivåindelning av data till lågkostnadsnivåer för S3-objektlagring, placerade antingen på plats eller i det offentliga molnet. Till skillnad från lösningar för manuell nivåsättning automatiserar FabricPool nivåindelningen av data för att sänka kostnaden för lagring. Aktiv data finns kvar på högpresterande enheter, och inaktiva data är anpassade till objektlagring samtidigt som DM-seriens funktionalitet och dataeffektivitet bevaras.
FabricPool stöder ett brett utbud av offentliga molnleverantörer och deras lagringstjänster. Dessa inkluderar Amazon S3, Alibaba Cloud Object Storage Service, Microsoft Azure Blob Storage, Google Cloud Storage, IBM Cloud Object Storage och privata moln. Kunder kommer också att dra nytta av att behålla de inbyggda datareduktionsfunktionerna när de flyttar data till och från molnet. Detta sparar transportkostnader när data behöver flyttas tillbaka från molnet. Dessutom skyddar inbyggd datakryptering båda data när de flyttar till molnet och fortsätter en gång i molnet. Detta säkerställer att det inte finns några sårbarheter under hela molnnivåprocessen.
FabricPool-policyer
FabricPool har två primära användningsfall: återta kapacitet på primär lagring eller krympa det sekundära lagringsutrymmet. Vårt fokus i den här artikeln ligger på möjligheten att återta kapacitet på den primära lagringen. Det finns tre olika och unika policyer för primär lagringsmolnnivå: automatisk nivå, endast ögonblicksbilder och all-tiering.
Att underhålla sällan åtkomliga data associerade med produktivitetsprogramvara, slutförda projekt och gamla datauppsättningar på primärlagring är en ineffektiv användning av högpresterande flashlagring. Att koppla dessa data till ett objektlager är ett enkelt sätt att återta befintlig flashkapacitet och minska mängden nödvändig kapacitet framåt. Policyn för automatisk nivådelning flyttar alla kalla block i volymen till molnnivån. Om de läses av slumpmässiga läsningar blir kalla datablock på molnnivån varma och överförs till den lokala nivån. Om de läses av sekventiella läsningar som de som är kopplade till index- och antivirusgenomsökningar, förblir kalla datablock på molnnivån kalla och skrivs inte till den lokala nivån.
Snapshot-kopior kan ofta förbruka mer än 10 % av en typisk lagringsmiljö. Även om de är nödvändiga för dataskydd och katastrofåterställning, används dessa punkt-i-tid-kopior sällan och är en ineffektiv användning av högpresterande flash. Snapshot-Only Tiering Policy för FabricPool är ett enkelt sätt att återta lagringsutrymme på flash-lagring. Under vår testning var Snapshot-Only policyn som användes för att testa molnnivåoperationer. Cold Snapshot-block i volymen som inte delas med det aktiva filsystemet flyttas till molnnivån. Om de läses blir kalla datablock på molnnivån varma och överförs till den lokala nivån.
En av de vanligaste användningsområdena för FabricPool är att flytta hela datavolymer till moln. Slutförda projekt, äldre rapporter eller historiska poster är idealiska kandidater för att kopplas till lågkostnadsobjektlagring. Att flytta hela volymer görs genom att ställa in All Tiering Policy på en volym. Denna policy används främst med sekundära data- och dataskyddsvolymer. Ändå kan den också användas för att gruppera all data i läs/skrivvolymer.
Data i volymer som använder All Tiering-policyn märks omedelbart som kalla och skiktade till molnet så snart som möjligt. Det finns ingen väntan på att ett minsta antal dagar ska passera innan data görs kall och skiktad. Om de läses förblir kalla datablock på molnnivån kalla och skrivs inte tillbaka till den lokala nivån.
Ett fjärde alternativ för nivåindelning är också tillgängligt med Lenovo och heter det passande namnet 'Ingen'. Med den här policyn är ingen data uppdelad, vilket gör att allt kan underhållas i flash. Ett bra exempel på dess användning är ögonblicksbilder i DevOps-miljöer, där tidigare tidpunkt-kopior används ofta.
Lenovo Storage Cloud Tiering-konfiguration
För att testa funktionerna och några av Lenovos lagringslösningsfunktioner för molnet, satte vi upp en DM7000F-modell i vårt labb.
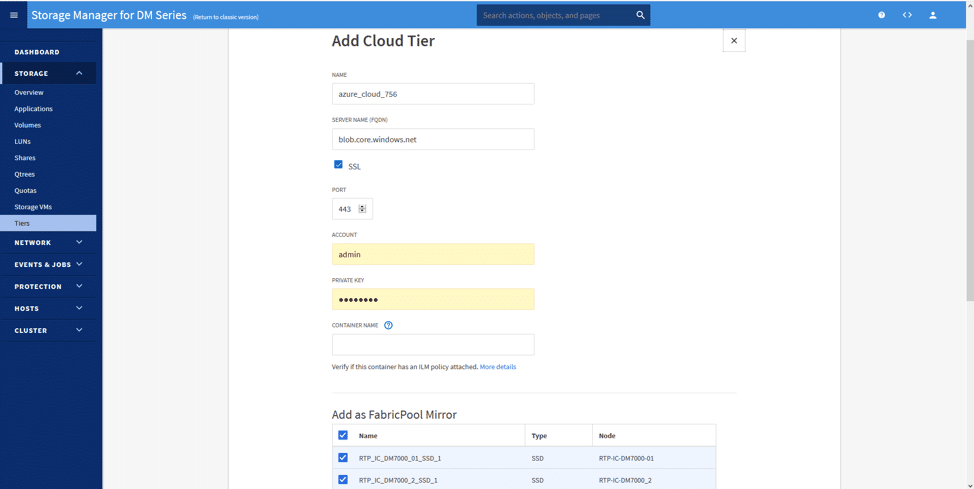
Först skapade vi en lagringsbehållare med Azure Blob Storage, vår molnlösning för detta test. Återigen är det bra att notera det breda utbudet av alternativ som finns tillgängliga från Lenovo som inkluderar Alibaba Cloud, Amazon S3, Google Cloud, IBM Cloud och andra. Under testet var syftet att använda Microsoft Azure Blob Storage för molnet som molnnivå för FabricPool. När vi var klara med installationen av molnlagring var det dags att logga in på DM7000:s GUI-gränssnitt.
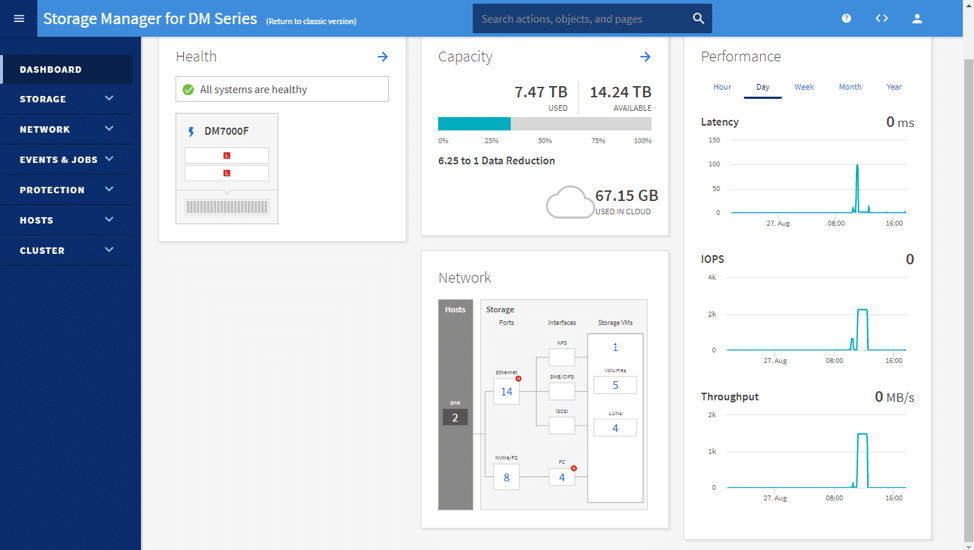
När du har loggat in visas standardsidan för Dashboard. Instrumentpanelen visar hälso-, kapacitets-, prestanda- och nätverksinformation för arrayen i fråga.
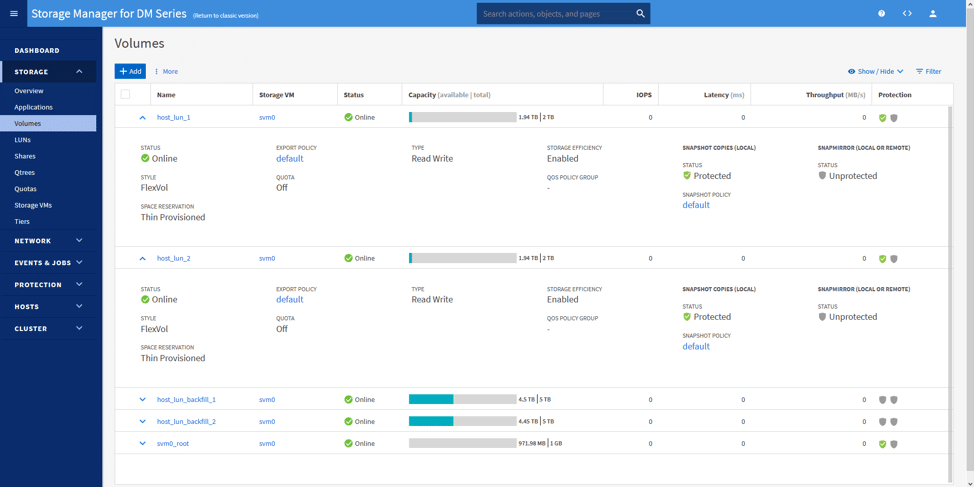
Vi skapade sedan två volymer (en per kontroller) och två virtuella datorer (en för varje volym). Planen var att låta dessa virtuella datorer köra och sedan låta dem sitta sysslolösa ett tag. Bilden nedan visar de använda volymerna: host_lun_1 och host_lun_2.
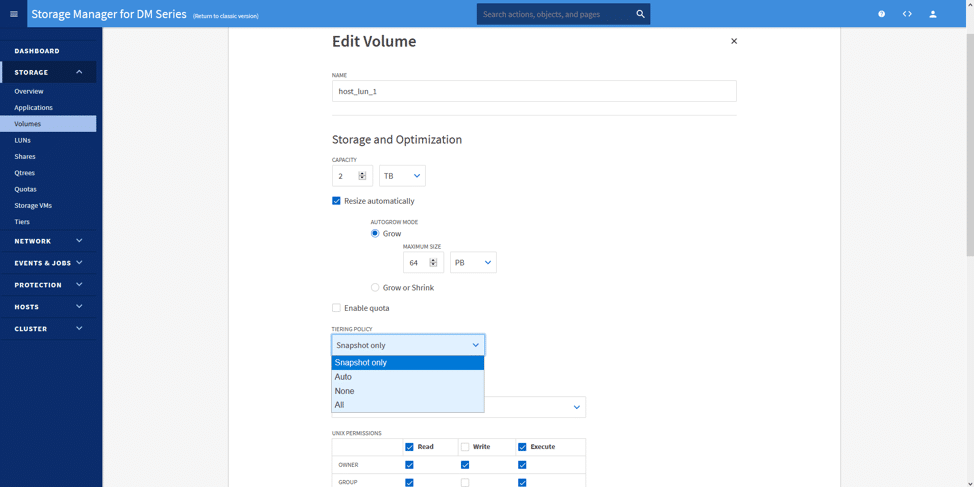
När vi redigerar eller skapar volymen kan vi välja önskad nivåpolicy. Här valde vi endast Snapshot. Genom att välja denna nivåstyrningspolicy flyttas våra data (sedda som kalla efter varje ögonblicksbild) till Azure Blob Storage som skapats på ett bakgrundsintervall. Intervallet körs på sin egen tid och förutsäger när arbetsbelastningen kommer att påverkas minst.
På sidan Nivåer kan vi lägga till vår molnnivå från de offentliga molnen. Här har vi kopplat Azure Blob Storage-resursen och kopplat den till de två lokala lagringsnivåerna. Under bilden nedan kan du se två resurser kopplade till Azure.
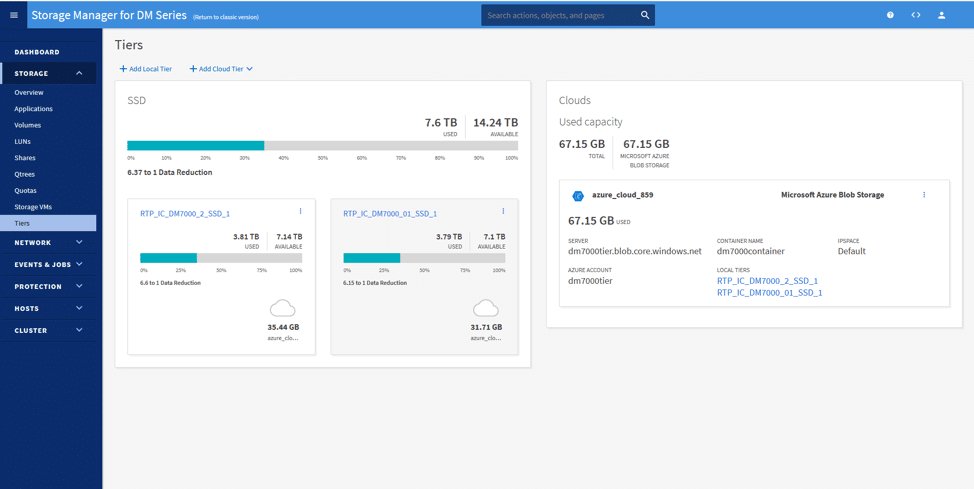
Konfigurationen är enkel; genom att klicka på Lägg till molnnivå och välja vårt önskade moln (Azure, i det här scenariot) kunde vi omedelbart ställa in molnnivån.
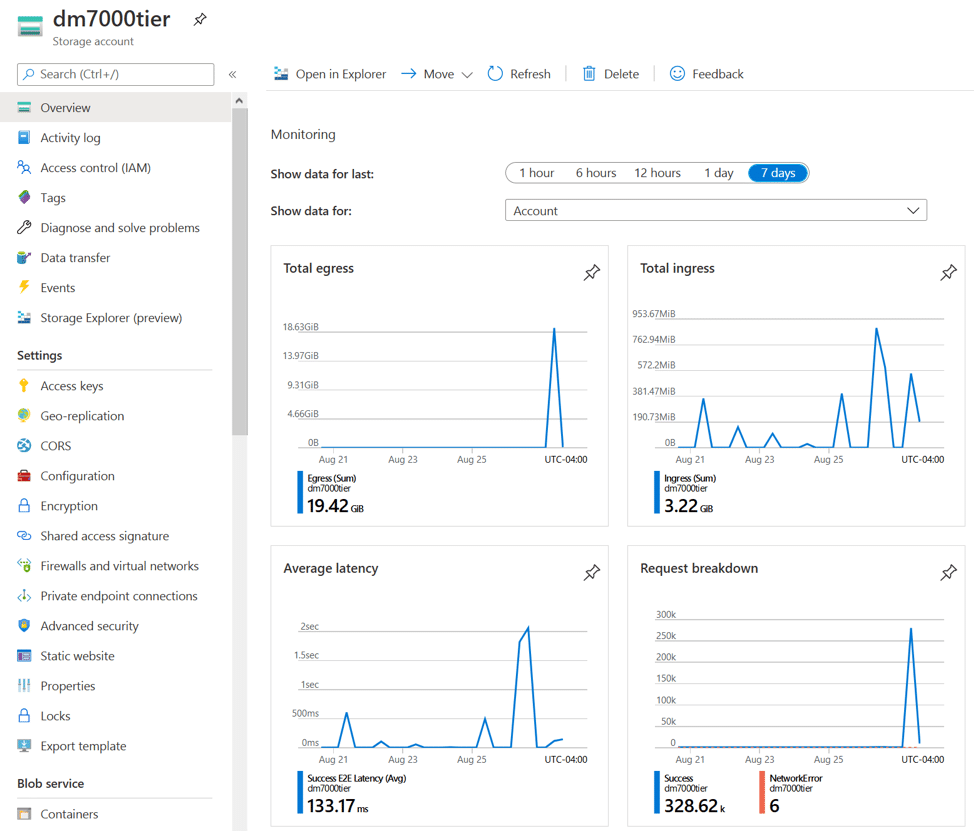
Slutligen, från vår instrumentpanel för Azure Storage-konton, ville vi visa både data som går in i Azure (ingång) och data som flyttas ut (utgående). De små topparna som visas varje dag är nya ögonblicksbilder av data som överförs till Azure. Å andra sidan visar utgående spikar utgående data, vilket illustrerar en ögonblicksbildsåterställning från en volym för att rulla tillbaka.
Avslutande tankar
I allmänhet är molnet och hanteringen av data ett brett ämne under utveckling bland företag. Lenovo vill tillhandahålla lösningar som gör kunderna redo för förändrade behov, vare sig det är i datacentret eller via hybrid-molnmiljöer. Vi på StorageReview är ganska imponerade av Lenovos inställning till deras lagringsarrayer. Genom den här utvärderingen upplevde vi hur nivåindelning av data till molnet fungerar från Storage Manager för DM-serien, och hur värdefull flashkapacitet återvinns eller utökas till molnet. Viktigt är att DM7000F-lagringssystemet ger denna flexibilitet utan att göra några ändringar i infrastrukturen. Dessutom är funktionen lätt att implementera.
Med stöd av DCG och IDG ser vi Lenovo i en stark position på datalagringsmarknaden. Deras lagringslösningar gör det möjligt för kunder att köpa det de behöver idag samtidigt som de utnyttjar molnet för att möta framtidens datatillväxtkrav. Nettoresultatet är att Lenovos molnnivåer kommer att minska kostnaderna och göra det möjligt för företag att ha den flexibilitet de önskar när de överväger en investering i lagring.
Lenovo ThinkSystem DM Series Storage Arrays
Den här rapporten är sponsrad av Lenovo. Alla åsikter och åsikter som uttrycks i denna rapport är baserade på vår opartiska syn på produkten/de produkter som övervägs.