
為了驗證 DRAM 在 AI 系統中的優勢,我們使用八個金士頓 KSM56R46BD4PMI-64HAI DDR5 記憶體模組進行了一系列測試。
系統 DRAM 在 AI 中發揮重要作用,特別是在 CPU 推理中。隨著人工智慧應用變得越來越複雜,對更快、更有效率的記憶體解決方案的需求變得越來越重要。我們想要了解系統 DRAM 在 AI 中的重要性,重點放在 CPU 推理以及利用多個記憶體通道的重要作用。

Kingston KSM56R46BD4PMI-64HAI DDR5
系統 DRAM 在 AI 中的重要性
系統 DRAM 是人工智慧系統中資料的中央樞紐。資料被暫時儲存以便CPU快速訪問,從而實現快速資料處理。
這在人工智慧應用中尤其重要,因為快速有效地處理大型資料集不僅是一種優勢,而且是必要的。以下是系統 DRAM 在增強 AI 功能方面的多方面作用的詳細介紹:
- 速度和效率:人工智慧演算法,尤其是推理演算法,需要高速記憶體來處理大量資料。系統 DRAM 提供了這種速度,減少了延遲並提高了整體系統效能。
- 容量:現代人工智慧應用需要大記憶體容量。高容量 DRAM 確保可以在記憶體中處理更大的資料集,從而避免從儲存裝置獲取資料的過程變慢。
- 可靠性:在人工智慧中,資料完整性至關重要。系統 DRAM 具有糾錯功能,可確保最大限度地減少資料損壞,這對於精確度至關重要的應用至關重要。
- 可擴展性:隨著人工智慧模型變得越來越複雜,擴展記憶體資源的能力變得極為重要。系統 DRAM 提供必要的可擴展性,以滿足不斷發展的人工智慧應用及其不斷升級的數據需求日益增長的需求。
- 頻寬:系統 DRAM 更高的頻寬可實現更快的資料傳輸速率,從而更快地存取資料。這對於訓練複雜的神經網路和管理大規模資料處理任務特別有益。
CPU 推理與 DRAM
在人工智慧中,CPU 推理(使用經過訓練的模型進行預測或決策的過程)和 DRAM 的作用是顯著影響人工智慧應用程式的效率和速度的關鍵組件。由於需要快速存取和處理大型資料集,此階段需要佔用大量記憶體。由於所涉及資料的複雜性和大小,它對系統記憶體的要求特別高。

DRAM 透過多項關鍵增強功能在優化 AI 操作的 CPU 推理方面發揮關鍵作用。首先,它提供了實現高資料吞吐量所需的頻寬,這對於CPU推理中的快速資料處理和決策至關重要。吞吐量的增加直接轉化為複雜任務中更快的效能。
此外,透過將資料儲存在靠近 CPU 的位置,系統 DRAM 顯著減少了存取資料的時間,從而最大限度地減少了整體推理延遲。這種接近對於維持快速反應的系統至關重要。最後,隨著資料處理速度的加快和存取時間的縮短,CPU 推理任務所需的整體功耗也顯著降低。這將帶來更節能的運營,並確保為人工智慧應用提供更永續和成本效益的環境。
多個記憶體通道的作用
系統記憶體架構是定義人工智慧應用效能的重要元素。利用多個記憶體通道就像拓寬高速公路一樣——它可以同時促進更大的資料流量,從而顯著提高整體系統效能。以下是如何利用多個管道來優化人工智慧操作:
- 增加頻寬:多個通道增加記憶體頻寬。這對於人工智慧應用至關重要,因為它們可以同時處理和分析更多數據,從而縮短推理時間。
- 並行處理:透過多個通道,可以並行處理數據,顯著加快涉及大型數據集的人工智慧運算速度。
- 減少瓶頸:多個記憶體通道有助於減少系統瓶頸。分配記憶體負載使每個通道能夠更有效地運行,從而增強整體系統效能。
測試數據
為了驗證 DRAM 在 AI 系統(特別是 CPU 推理)中的優勢,我們使用八個金士頓 KSM56R46BD4PMI-64HAI DDR5 記憶體模組在不同的通道配置中進行了一系列測試。

| KSM48R40BD4TMM-64HMR 64GB 2Rx4 8G x 80 位元 PC5-4800 CL40 寄存 EC8 288 針 DIMM | KSM56R46BD4PMI-64HAI 64GB 2Rx4 8G x 80 位元 PC5-5600 CL46 寄存式 EC8 288 針 DIMM | |
| 傳輸速度 | 4800 MT/s | 5600 MT/s |
| 中文(國際直撥) | 40週期 | 46週期 |
| 行週期時間 (tRCmin) | 48ns(分鐘) | 48ns(分鐘) |
| 刷新到活動/刷新命令時間 (tRFCmin) | 295ns(分鐘) | 295ns(分鐘) |
| 行活動時間 | 32ns(分鐘) | 32ns(分鐘) |
| 行預充電時間 | 16ns(分鐘) | 16ns(分鐘) |
| UL 等級 | 94 伏 – 0 | 94 伏 – 0 |
| 工作溫度 | 0℃至+95℃ | 0℃至+95℃ |
| 儲藏溫度 | -55 C至+ 100 C. | -55 C至+ 100 C. |
為了建立基線,我們啟動了集中的 CPU 基準測試和 Geekbench 測試,衡量 CPU 的獨立功能。為了對整個系統(包括記憶體和儲存)施加嚴格壓力,我們選擇了 y-cruncher,因為它具有嚴格的要求。這種方法使我們能夠評估整個系統在極端條件下的凝聚力和耐久性,從而提供整體性能和穩定性的清晰畫面。
最終,這些結果將提供有關係統 DRAM 和記憶體通道數量如何直接影響人工智慧應用中的運算速度、效率和整體系統效能的具體數據。
Geekbench 6
首先是 Geekbench 6,衡量整體系統效能的跨平台基準。您可以在以下位置找到與任何您想要的系統的比較 Geekbench 瀏覽器. 分數越高越好。
| Geekbench 6 | 金士頓DDR5 2通道 |
金士頓DDR5 4通道 |
金士頓DDR5 8通道 |
| CPU 基準測試: 單核 |
2,083 | 2,233 | 2,317 |
| CPU 基準測試: 多核 |
14,404 | 18,561 | 19,752 |
在比較 6、5 和 2 頻道設定時,金士頓 DDR4 的 Geekbench 8 結果顯示出一系列變化。在單核測試中,分數小幅但穩定地從兩個通道的 2,083 增加到八個通道的 2,317,這表明隨著通道數量的增加,各個核心操作的效率和吞吐量有所提高。然而,最顯著的效能提升是在多核心測試中,分數從兩個通道的 14,404 躍升至八通道的 19,752。
y 粉碎機
y-cruncher 是一個多線程且可擴展的程序,可以將 Pi 和其他數學常數計算到數萬億位。 自 2009 年推出以來,y-cruncher 已成為超頻玩家和硬體愛好者流行的基準測試和壓力測試應用程式。 在這個測試中越快越好。
| y 粉碎機 (總計算時間) |
金士頓DDR5 2通道 |
金士頓DDR5 4通道 |
金士頓DDR5 8通道 |
| 十億位 | 18.117秒 | 10.856秒 | 7.552秒 |
| 十億位 | 51.412秒 | 31.861 秒 | 20.981 秒 |
| 十億位 | 110.728秒 | 64.609 秒 | 46.304 秒 |
| 十億位 | 240.666秒 | 138.402 秒 | 103.216 秒 |
| 25 億位數字 | 693.835秒 | 396.997 秒 | 不適用 |
2、4 和 8 個通道的 y-cruncher 基準測試表明,隨著通道數量的增加,計算速度得到了明顯且一致的改進。對於計算 1 億位元 Pi,總計算時間從兩個通道的 18.117 秒顯著減少到八通道的 7.552 秒。
這種計算時間減少的趨勢在所有測試的尺度上持續存在,當從 25 個通道變為 693.835 個通道時,計算 396.997 億位數字的時間從 2 秒減少到 4 秒。
3DMark – CPU 設定文件
3DMark 中的 CPU 設定檔測試專門測量處理器在一系列執行緒數下的效能,詳細了解 DDR5 RAM 通道的不同配置如何影響 CPU 工作負載處理和效率。此測試有助於了解使用各種 DDR5 RAM 通道設定時記憶體密集型操作和多執行緒應用程式的效能細微差別。
| 3DMark – CPU 設定檔 – 分數 | |||
| 線程數 | 金士頓DDR5 2通道 |
金士頓DDR5 4通道 |
金士頓DDR5 8通道 |
| 最大線程數 | 15,822 | 15,547 | 15,457 |
| 16個線程 | 10,632 | 9,515 | 10,367 |
| 8個線程 | 4,957 | 6,019 | 5,053 |
| 4個線程 | 3,165 | 3,366 | 3,323 |
| 2個線程 | 1,726 | 1,765 | 1,781 |
| 螺紋1 | 907 | 911 | 884 |
金士頓 DDR3 RAM 的 5DMark CPU 設定檔分數顯示了一個有些複雜的情況,表明最佳通道數可能會根據執行緒數和特定工作負載而變化。
在最大線程數下,兩個通道的分數最高 (15,822),而通道數越多,分數略有下降,這表明額外的通道不會為高度並行任務帶來好處。然而,在 4 個執行緒中,6,019 個通道配置得分最高 (4),這表明附加通道可以改善中階並行性的處理。在線程數較低(2、1 和 XNUMX 線程)的所有通道配置中,分數相似。
這些結果表明,雖然更多通道可以使某些多執行緒操作受益,但其影響因任務性質和系統架構而異。也就是說,對於每個用例來說,更多並不總是更好。
DRAM 通道對 AI 推理的影響
所有測試均在 Intel Xeon w9-3475X CPU 上進行,並透過 UL 實驗室 Procyon 基準測試利用 Intel OpenVINO API。

UL Procyon AI 推理基準測試配備了一系列來自頂級供應商的 AI 推理引擎,可滿足廣泛的硬體設定和要求。基準分數提供了設備上推理性能的便捷且標準化的摘要。這使我們能夠在現實情況下比較和對比各種硬體設置,而無需內部解決方案。
FP32 上的結果在誤差範圍內,但當您轉向 INT 時,查看細粒度分數而不是總體分數,事情會變得有趣。
數字越大總分越好,數字越小時間越好。
首先是 FP32 Precision
| FP 32 | ||
| 精密 | 8通道 | 2通道 |
| 總體得分 | 629 | 630 |
| MobileNet V3 平均推理時間 | 0.81 | 0.77 |
| ResNet 50 平均推理時間 | 1.96 | 1.82 |
| Inception V4 平均推理時間 | 6.93 | 7.31 |
| DeepLab V3 平均推理時間 | 6.27 | 6.17 |
| YOLO V3 平均推理時間 | 12.99 | 13.99 |
| REAL-ESRGAN 平均推理時間 | 280.59 | 282.45 |
接下來是 FP16 Precision
| FP 16 | ||
| 精密 | 8通道 | 2通道 |
| 總體得分 | 645 | 603 |
| MobileNet V3 平均推理時間 | 0.81 | 0.76 |
| ResNet 50 平均推理時間 | 1.91 | 1.94 |
| Inception V4 平均推理時間 | 7.11 | 7.27 |
| DeepLab V3 平均推理時間 | 6.27 | 7.13 |
| YOLO V3 平均推理時間 | 12.93 | 15.01 |
| REAL-ESRGAN 平均推理時間 | 242.24 | 280.91 |
最後是INT
| INT | ||
| 精密 | 8通道 | 2通道 |
| 總體得分 | 1,033 | 1004 |
| MobileNet V3 平均推理時間 | 0.71 | 0.73 |
| ResNet 50 平均推理時間 | 1.48 | 1.48 |
| Inception V4 平均推理時間 | 4.42 | 4.47 |
| DeepLab V3 平均推理時間 | 4.33 | 4.99 |
| YOLO V3 平均推理時間 | 5.15 | 5.12 |
| REAL-ESRGAN 平均推理時間 | 122.40 | 123.57 |
DRAM 吞吐量和延遲
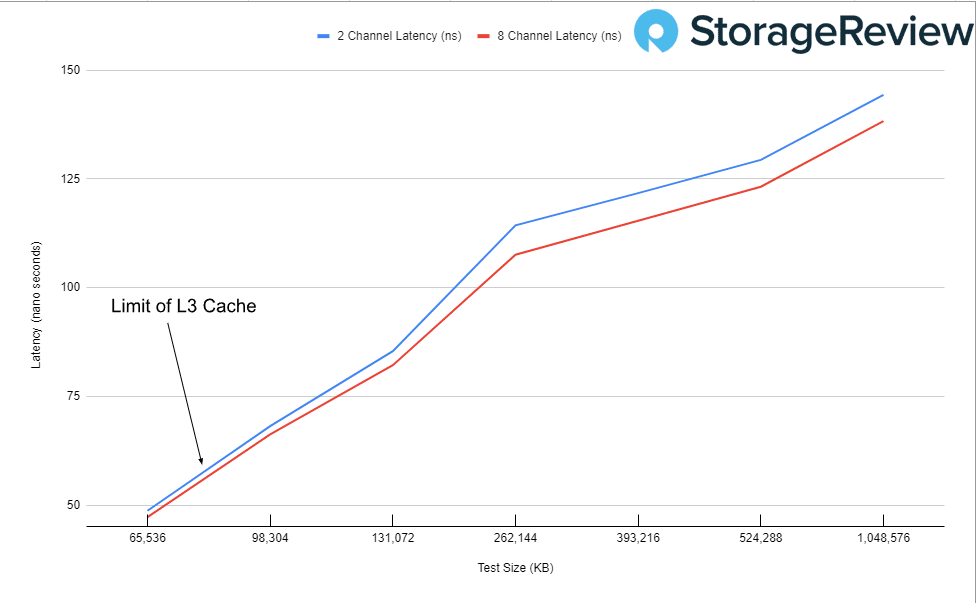
首先,查看 2 通道和 8 通道 DRAM 配置的延遲。我們分析了整個 CPU 和內存,但我們唯一關注的是從 CPU 緩存到 DRAM 的過渡。由於我們的 Xeon W9-3475X CPU 只有 82.50MB 的 L3 緩存,因此我們在過渡開始時就拿出了圖表。
| 測試大小 (KB) | 2 頻道頻寬 |
8 頻道延遲 (ns)
|
| 65,536 | 48.70080 | 47.24411 |
| 98,304 | 68.16823 | 66.25920 |
| 131,072 | 85.38640 | 82.16685 |
| 262,144 | 114.32570 | 107.57450 |
| 393,216 | 121.74860 | 115.40340 |
| 524,288 | 129.38970 | 123.22100 |
| 1,048,576 | 144.32880 | 138.28380 |
在這裡,我們可以看到添加更多通道可以小幅改善延遲。
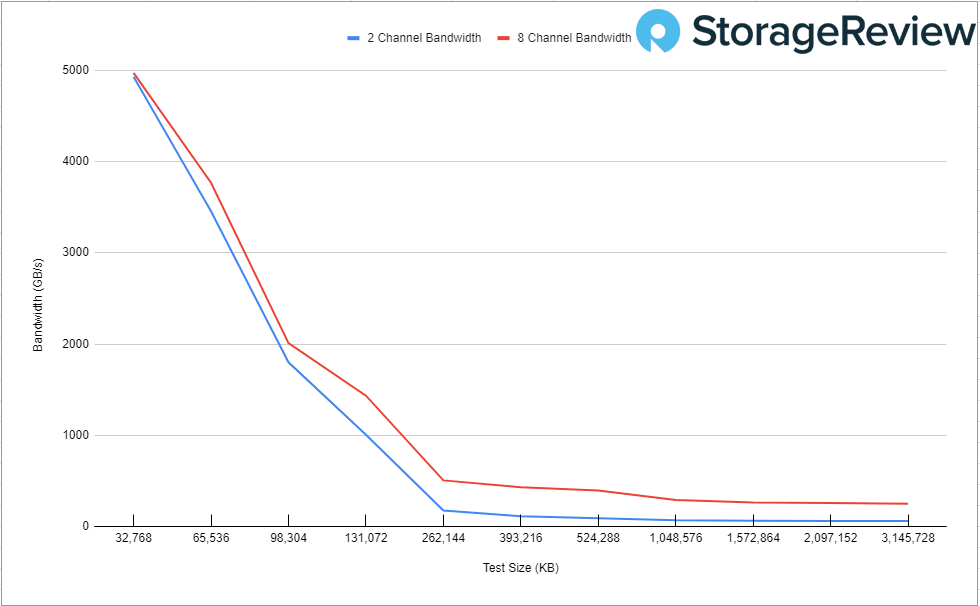
繼續討論 AVX512 指令的頻寬,我們可以看到 2 通道和 8 通道之間的頻寬有顯著差異。這裡的 Delta 是 2 到 8 個通道之間的性能影響。
| 測試大小 (KB) AVX512 | 2通道頻寬(GB/s) | 8通道頻寬(GB/s) | 增量(GB/s 差異) |
| 65,536 | 3,455.28 | 3,767.91 | -312.63 |
| 98,304 | 1,801.88 | 2,011.83 | -209.95 |
| 131,072 | 1,009.21 | 1,436.50 | -427.28 |
| 262,144 | 178.52 | 508.65 | -330.13 |
| 393,216 | 114.76 | 433.91 | -319.15 |
| 524,288 | 94.81 | 396.90 | -302.09 |
| 1,048,576 | 71.12 | 293.26 | -222.13 |
| 1,572,864 | 66.98 | 267.44 | -200.46 |
| 2,097,152 | 65.08 | 262.50 | -197.42 |
| 3,145,728 | 63.63 | 253.12 | -189.50 |
結論
綜上所述,系統 DRAM 是 AI 系統架構的基石,尤其是在 CPU 推理方面。它提供高速、可靠和大容量記憶體的能力是不可或缺的。此外,利用多個記憶體通道可以透過增加頻寬、實現並行處理和最小化瓶頸來顯著提高人工智慧應用程式的效能。隨著人工智慧的不斷發展,優化系統 DRAM 仍將是確保最高水準的效能和效率的關鍵焦點。

由 Jordan Ranous 提示的 AI 生成圖像
此外,測試數據強化了這個概念,展現了增強型記憶體配置的實際好處。隨著我們突破人工智慧和資料處理的界限,系統記憶體的策略增強對於支援下一代人工智慧創新和實際應用至關重要。
參與 StorageReview
電子報 | YouTube | 播客 iTunes/Spotify | Instagram | Twitter | 的TikTok | RSS訂閱