
Heute gab das Unternehmen auf der NetApp Insight bekannt, dass es mit dem virtualisierenden KI-Infrastrukturunternehmen Run:AI zusammenarbeitet, um schnellere KI-Experimente bei voller GPU-Auslastung zu ermöglichen. Die beiden Unternehmen werden die KI beschleunigen, indem sie viele Experimente parallel durchführen, schnell auf Daten zugreifen und unbegrenzte Rechenressourcen nutzen. Das Ziel ist das Beste aus allen Welten: schnellere Experimente bei gleichzeitiger Nutzung aller Ressourcen.
Heute gab das Unternehmen auf der NetApp Insight bekannt, dass es mit dem virtualisierenden KI-Infrastrukturunternehmen Run:AI zusammenarbeitet, um schnellere KI-Experimente bei voller GPU-Auslastung zu ermöglichen. Die beiden Unternehmen werden die KI beschleunigen, indem sie viele Experimente parallel durchführen, schnell auf Daten zugreifen und unbegrenzte Rechenressourcen nutzen. Das Ziel ist das Beste aus allen Welten: schnellere Experimente bei gleichzeitiger Nutzung aller Ressourcen.
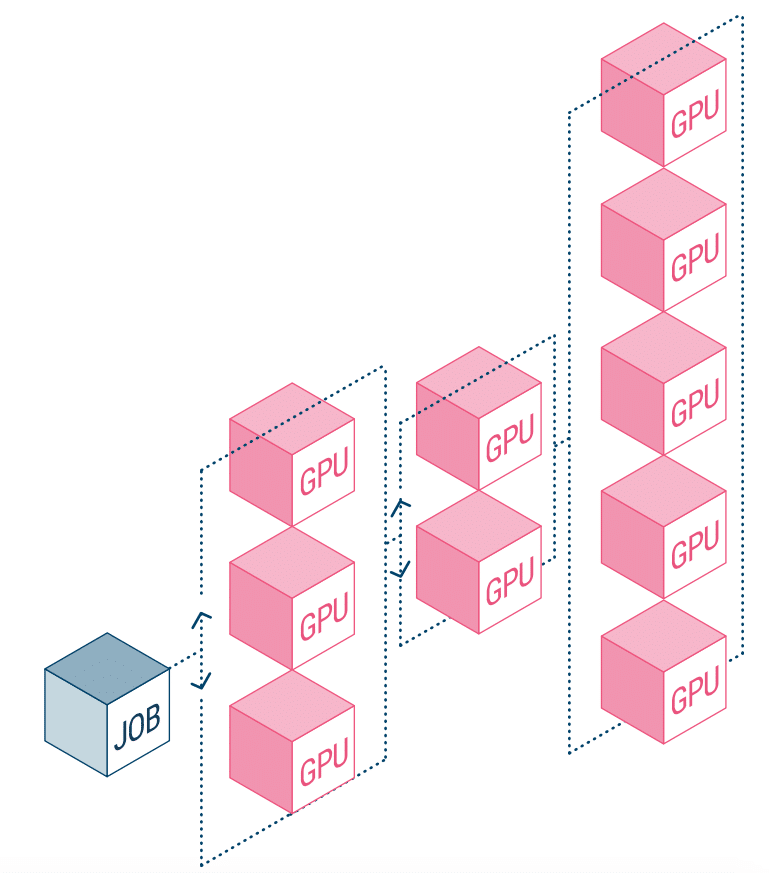
Geschwindigkeit ist zu einem entscheidenden Aspekt der meisten modernen Workloads geworden. Das Experimentieren mit KI hängt jedoch etwas enger mit der Geschwindigkeit zusammen, denn je schneller das Experimentieren, desto besser sind die erfolgreichen Geschäftsergebnisse. Obwohl dies kein Geheimnis ist, leiden KI-Projekte unter Prozessen, die sie weniger effizient machen, vor allem durch die Kombination aus Datenverarbeitungszeit und veralteten Speicherlösungen. Weitere Probleme, die die Anzahl der durchgeführten Experimente einschränken können, sind Probleme bei der Workload-Orchestrierung und der statischen Zuweisung von GPU-Rechenressourcen.
NetApp AI und Run:AI arbeiten zusammen, um die oben genannten Probleme anzugehen. Dies bedeutet eine Vereinfachung der Orchestrierung von KI-Workloads und eine Optimierung des Prozesses sowohl der Datenpipelines als auch der Maschinenplanung für Deep Learning (DL). Das Unternehmen gibt an, dass Kunden mit der bewährten Architektur von NetApp ONTAP AI KI und DL besser umsetzen können, indem sie ihre Datenpipeline vereinfachen, beschleunigen und integrieren. Auf der Run:AI-Seite fügt die Orchestrierung von KI-Workloads eine proprietäre Kubernetes-basierte Planungs- und Ressourcennutzungsplattform hinzu, um Forschern bei der Verwaltung und Optimierung der GPU-Auslastung zu helfen. Die kombinierte Technologie ermöglicht die parallele Ausführung mehrerer Experimente auf verschiedenen Rechenknoten mit schnellem Zugriff auf viele Datensätze im zentralen Speicher.
Run:AI hat die weltweit erste Orchestrierungs- und Virtualisierungsplattform für die KI-Infrastruktur entwickelt. Sie abstrahieren die Arbeitslast von der Hardware und erstellen gemeinsame Pools von GPU-Ressourcen, die dynamisch bereitgestellt werden können. Durch die Ausführung auf den Speichersystemen von NetApp können sich Forscher auf ihre Arbeit konzentrieren, ohne sich über Engpässe Gedanken machen zu müssen.
Beteiligen Sie sich an StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | Facebook | RSS Feed