
La piattaforma di memoria token PEAK:AIO utilizza il riutilizzo di KVCache e CXL per offrire inferenza più rapida, finestre di contesto più ampie e scalabilità della memoria compatibile con l'intelligenza artificiale.
PEAK:AIO ha introdotto una soluzione innovativa progettata per unificare l'accelerazione KVCache con l'espansione della memoria GPU, rispondendo alle esigenze di carichi di lavoro di intelligenza artificiale su larga scala. Questa nuova piattaforma risponde alle esigenze di inferenza, sistemi agenti e creazione di modelli, in un momento in cui le applicazioni di intelligenza artificiale si evolvono da prompt statici a flussi di contesto dinamici e agenti di lunga durata. Il cambiamento nella complessità dei carichi di lavoro di intelligenza artificiale richiede una corrispondente evoluzione dell'infrastruttura e PICCO:AIOL'ultima proposta di è progettata per affrontare queste sfide a testa alta.
Eyal Lemberger, co-fondatore e Chief AI Strategist di PEAK:AIO, sottolinea la necessità critica di trattare la cronologia dei token come memoria anziché come storage tradizionale. Sottolinea che i moderni modelli di intelligenza artificiale possono richiedere oltre 500 GB di memoria per istanza e che la scalabilità della memoria deve tenere il passo con i progressi del computing. Lemberger osserva che, con la crescita e la complessità dei modelli transformer, gli approcci legacy, come l'ammodernamento degli stack di storage o l'estensione eccessiva di NVMe, non sono più sufficienti. La nuova piattaforma di memoria token 1U di PEAK:AIO è progettata appositamente per operazioni incentrate sulla memoria, non per l'archiviazione di file, segnando un netto distacco dalle architetture convenzionali.
Architettura incentrata sui token per l'intelligenza artificiale scalabile
La piattaforma PEAK:AIO è la prima a implementare un'architettura incentrata sui token che sfrutta la memoria CXL, Gen5 NVMe e GPUDirect RDMA per offrire una velocità di elaborazione sostenuta fino a 150 GB/sec con una latenza inferiore a 5 microsecondi.
La piattaforma supporta il riutilizzo di KVCache su sessioni, modelli e nodi, consentendo un utilizzo più efficiente della memoria e un cambio di contesto più rapido. Consente inoltre l'espansione della finestra di contesto, fondamentale per mantenere cronologie LLM più lunghe e supportare interazioni IA più complesse. Scaricando la memoria GPU tramite un vero e proprio tiering CXL, la soluzione riduce la saturazione della memoria GPU, un collo di bottiglia comune nelle distribuzioni IA su larga scala. L'accesso a bassissima latenza viene ottenuto utilizzando RDMA su NVMe-oF, garantendo che la memoria token sia disponibile a velocità di classe memoria.
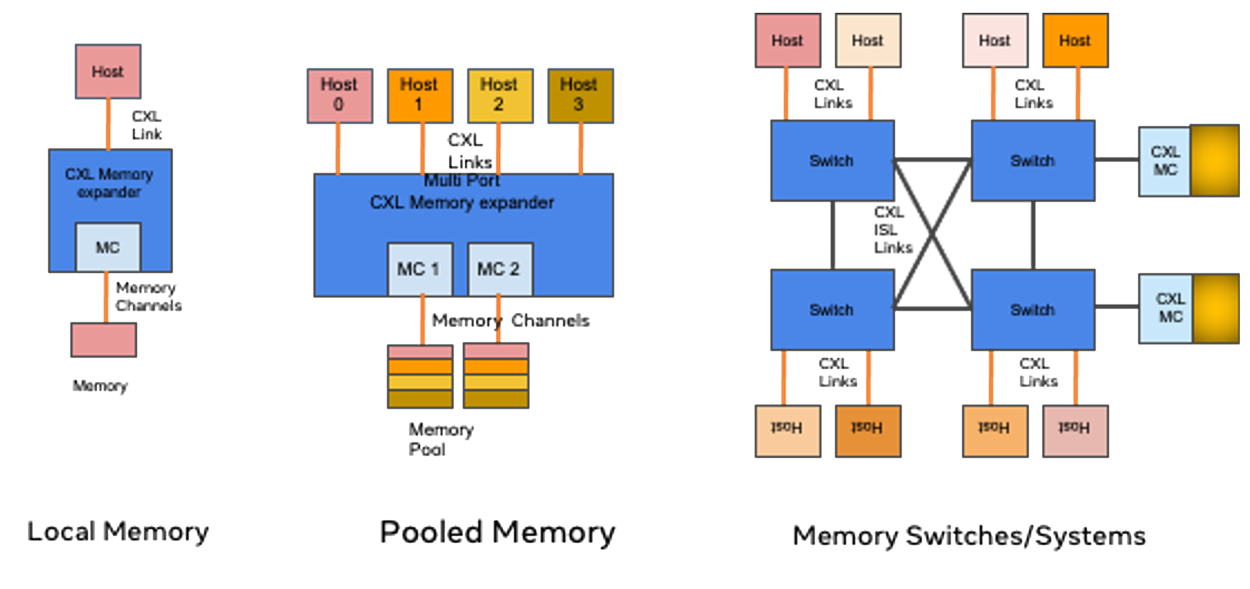
A differenza delle tradizionali soluzioni di storage basate su NVMe, l'architettura di PEAK:AIO è progettata per funzionare come una vera e propria infrastruttura di memoria. Ciò consente ai team di memorizzare nella cache la cronologia dei token, le mappe di attenzione e i dati in streaming con la velocità e l'efficienza della RAM, anziché trattarli come file. La piattaforma si allinea perfettamente con i modelli di riutilizzo e recupero della memoria KVCache di NVIDIA, offrendo un'integrazione perfetta per i team che lavorano con TensorRT-LLM o Triton. Questa compatibilità con i plug-in accelera l'inferenza e riduce il sovraccarico di integrazione, offrendo un significativo vantaggio in termini di prestazioni.
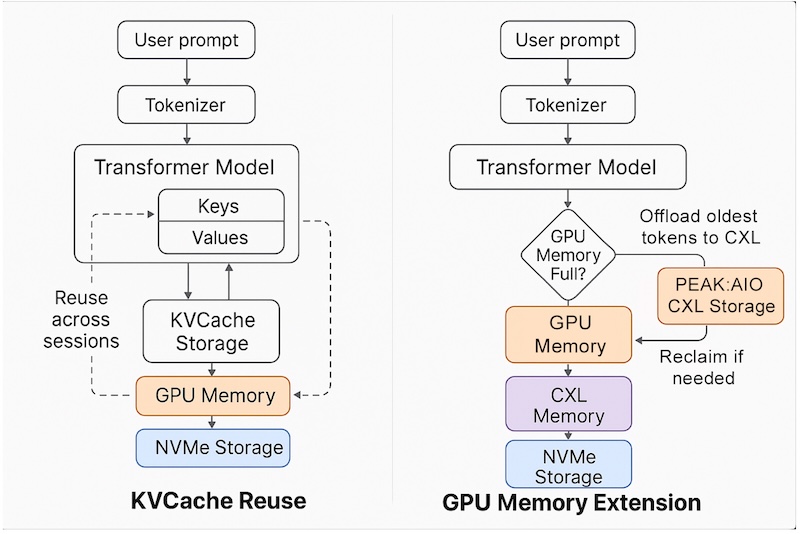
Lemberger sottolinea che, mentre altri fornitori tentano di adattare i file system affinché si comportino come memoria, PEAK:AIO ha sviluppato un'infrastruttura che opera intrinsecamente come memoria. Questa distinzione è cruciale per l'intelligenza artificiale moderna, dove la priorità è l'accesso rapido e di classe memoria a ogni token, non solo all'archiviazione dei file.
Mark Klarzynski, co-fondatore e Chief Strategy Officer di PEAK:AIO, sottolinea l'utilizzo della tecnologia CXL come un elemento chiave di differenziazione. Descrive la piattaforma come una vera e propria struttura di memoria per l'intelligenza artificiale, a differenza dei concorrenti che impilano dispositivi NVMe. Klarzynski sottolinea che questa innovazione è essenziale per offrire reali capacità di memoria su larga scala e supportare la prossima generazione di carichi di lavoro di intelligenza artificiale.
La soluzione è completamente software-defined e funziona su server standard, rendendola accessibile e scalabile per diversi ambienti aziendali e cloud. PEAK:AIO prevede che la piattaforma entri in produzione entro il terzo trimestre, posizionandosi come una tecnologia rivoluzionaria per team di vendita, ingegneri e dirigenti che desiderano rendere la propria infrastruttura di intelligenza artificiale a prova di futuro.
Interagisci con StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS feed