
HPE는 ProLiant 서버, Private Cloud AI, Alletra SDK, RTX PRO 6000 Blackwell GPU에 대한 OpsRamp 지원으로 AI 인프라를 업데이트합니다.
HPE는 NVIDIA AI 컴퓨팅 by HPE 포트폴리오 전반에 걸쳐 다양한 업데이트를 출시했습니다. 이러한 개선 사항은 데이터 수집 및 학습부터 실시간 추론 및 운영 관리에 이르기까지 AI 개발의 전체 라이프사이클을 더욱 효과적으로 지원하도록 설계되었습니다. HPE는 엔터프라이즈 인프라 내 AI의 전체 라이프사이클에 집중하고 있습니다. 최신 업데이트는 HPE 프라이빗 클라우드 AI의 새로운 기능을 시작으로 유연성, 확장성, 그리고 개발자 지원에 중점을 두고 있습니다.
HPE Private Cloud AI의 새로운 기능은 개발자 마찰을 줄이는 것을 목표로 합니다.
NVIDIA와 협력하여 개발한 풀스택 솔루션인 HPE Private Cloud AI에 핵심 업데이트가 적용되었습니다. 이 플랫폼을 통해 기업은 온프레미스 또는 하이브리드 환경에서 생성적 AI(GenAI) 및 에이전트 워크로드를 실행할 수 있으며, 이제 NVIDIA AI Enterprise의 기능 브랜치 모델 업데이트를 지원합니다.
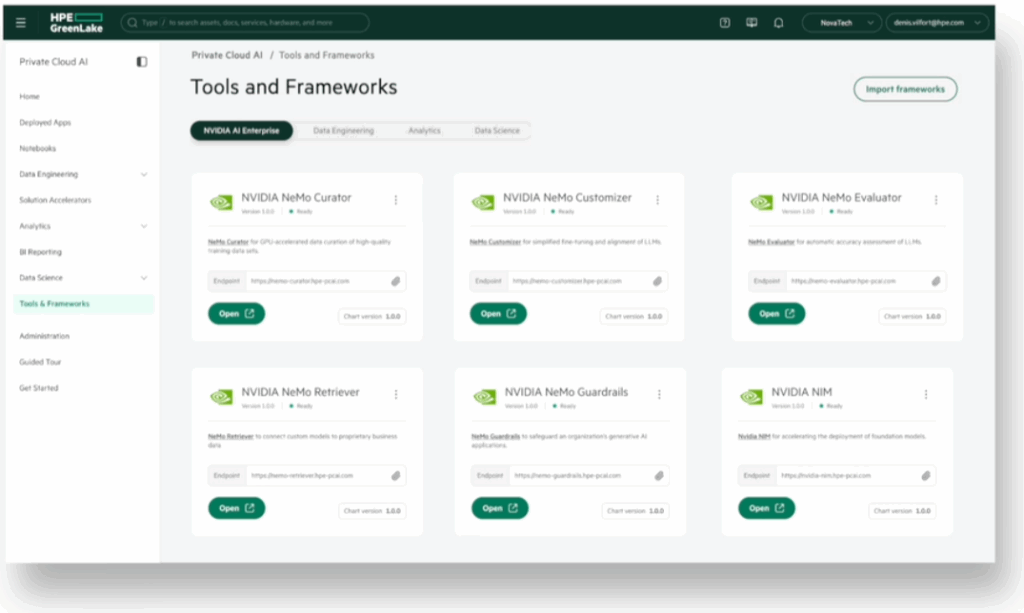
즉, 개발자는 안정적인 운영 모델에 영향을 주지 않고 새로운 AI 프레임워크, 마이크로서비스 및 SDK를 테스트할 수 있습니다. 이는 현대 소프트웨어 개발에서 흔히 사용되는 방식을 반영한 접근 방식입니다. 엔터프라이즈급 AI에 필요한 견고성을 유지하면서도 더욱 안전한 실험 환경을 제공합니다.
HPE 프라이빗 클라우드 AI는 NVIDIA Enterprise AI Factory 검증 설계도 지원합니다. 이러한 협력을 통해 기업은 NVIDIA의 검증된 레퍼런스 설계를 활용하여 AI 솔루션을 구축하는 더욱 명확한 방향을 확보하고, 안정적이고 일관된 확장을 더욱 쉽게 수행할 수 있습니다.
Alletra Storage용 새로운 SDK로 Agentic AI의 데이터 워크플로 간소화
HPE는 또한 NVIDIA AI 데이터 플랫폼과 호환되도록 설계된 Alletra Storage MP X10000 시스템용 새로운 소프트웨어 개발 키트(SDK)를 출시했습니다. 이 SDK를 통해 기업은 데이터 인프라를 NVIDIA AI 도구에 더욱 쉽게 연결할 수 있습니다.

주요 목표는 AI 프로젝트에 사용하기 전에 정리 및 정리가 필요한 비정형 데이터(예: 문서, 이미지, 비디오)를 관리하는 것입니다. SDK는 유용한 정보로 데이터 태그 지정, 빠른 검색을 위한 데이터 정리, AI 모델 학습 및 추론을 위한 데이터 준비 등의 작업을 지원합니다.
또한 RDMA(Remote Direct Memory Access) 기술을 사용하여 스토리지와 GPU 간 데이터 전송 속도를 높여 대규모 AI 워크로드를 처리할 때 성능을 향상시키는 데 도움이 됩니다.
또한 Alletra X10000의 모듈형 설계는 기업이 스토리지와 성능을 개별적으로 확장하여 특정 프로젝트 요구 사항에 따라 설정을 조정할 수 있도록 지원합니다. HPE와 NVIDIA는 이러한 도구를 결합하여 온프레미스 시스템부터 클라우드 기반 환경까지 기업이 데이터에 더욱 효율적으로 액세스하고 처리할 수 있는 방법을 제공하고자 합니다.
HPE 서버, AI 벤치마크에서 1위 차지
HPE의 ProLiant Compute DL380a Gen12 서버는 최근 10가지 MLPerf Inference: Datacenter v5.0 벤치마크에서 최고 순위를 기록했습니다. 이 테스트는 언어 작업을 위한 GPT-J, 대규모 생성 AI를 위한 Llama2-70B, 이미지 분류를 위한 ResNet50, 객체 감지를 위한 RetinaNet 등 다양하고 까다로운 AI 모델의 성능을 평가했습니다. 이처럼 뛰어난 벤치마크 성능은 고성능 NVIDIA H100 NVL, H200 NVL, L40S GPU를 포함한 서버의 현재 구성을 반영합니다.

HPE ProLiant 컴퓨팅 DL380a Gen12
이러한 추진력을 바탕으로 HPE는 10월 6000일부터 최대 4개의 NVIDIA RTX PRO XNUMX Blackwell Server Edition GPU를 사용한 구성을 제공하여 서버 성능을 확장할 계획입니다. 이를 통해 멀티모달 추론, 시뮬레이션 기반 AI(물리적 AI라고도 함), 모델 미세 조정, 고급 디자인 또는 미디어 워크플로와 같은 엔터프라이즈 AI 애플리케이션에 대한 서버의 적합성이 더욱 향상될 것으로 예상됩니다.
DL380a Gen12는 고부하 워크로드를 처리하기 위해 기존 공랭식과 직접 액체 냉각(DLC)의 두 가지 냉각 옵션을 제공합니다. DLC 구성은 HPE의 오랜 열 관리 전문성을 활용하여 지속적인 컴퓨팅 집약적 운영 시 시스템 안정성과 성능을 유지하는 데 도움을 줍니다.
이 서버에는 실리콘 루트 오브 트러스트(Silicon Root of Trust)를 활용한 하드웨어 수준의 보안 보호 기능을 통합한 HPE의 iLO(Integrated Lights Out) 7 관리 엔진이 포함되어 있습니다. 양자 이후 암호화를 지원하도록 설계된 최초의 서버 플랫폼 중 하나이며, 암호화 보안을 위한 고급 인증인 FIPS 140-3 레벨 3 표준을 충족합니다.
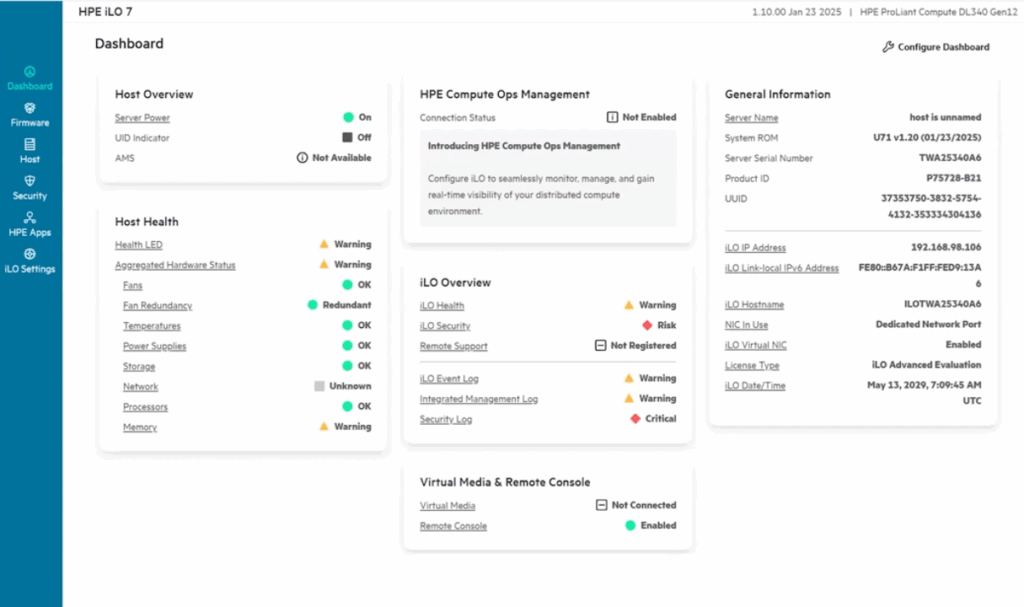
관리 측면에서 HPE Compute Ops Management는 시스템 상태를 추적하고 잠재적인 문제를 조기에 표시하며 AI 기반 분석을 통해 에너지 사용에 대한 통찰력을 제공하는 자동화된 수명 주기 도구를 제공합니다.
DL380a 외에도 HPE는 서버 라인업 전반에 걸쳐 강력한 성능을 입증했습니다. 듀얼 소켓 NVIDIA GH384 NVL12 GPU를 탑재한 ProLiant Compute DL200 Gen2는 Llama5.0-2B 및 Mixtral-70x8B와 같은 대형 모델을 포함하여 MLPerf v7 테스트 670개에서 8위를 차지했습니다. 한편, NVIDIA H200 SXM GPU 30개를 탑재한 HPE Cray XD50은 대규모 언어 모델과 비전 기반 AI 작업을 포함한 XNUMX개 벤치마크 시나리오에서 XNUMX위를 차지했습니다. HPE 시스템은 XNUMX개 이상의 테스트 범주에서 XNUMX위를 차지하며 AI 인프라 기능에 대한 제XNUMX자 검증을 제공했습니다.
OpsRamp, 인프라 관찰을 위한 새로운 GPU 클래스로 확장
운영 측면에서 HPE는 곧 출시될 NVIDIA RTX PRO 6000 Blackwell GPU를 사용하는 환경을 관리하기 위해 OpsRamp 소프트웨어에 대한 지원을 확대하고 있습니다. 이 확장을 통해 IT 팀은 GPU 사용률, 열 부하, 메모리 사용량, 전력 소모량 등 AI 인프라에 대한 가시성을 확보할 수 있습니다.
이 소프트웨어는 하이브리드 AI 환경에 풀스택 가시성을 제공하고, 팀이 과거 추세를 기반으로 능동적으로 대응을 자동화하고, 작업 스케줄링을 최적화하고, 리소스 할당을 관리할 수 있도록 지원합니다. 기업의 AI 투자가 증가함에 따라, 이러한 가시성 및 최적화 도구는 안정적이고 비용 효율적인 AI 배포를 운영하는 데 중요해지고 있습니다.
유효성
기능 브랜치 지원 HPE 프라이빗 클라우드 AI의 NVIDIA AI Enterprise 여름까지 예상됩니다. HPE Alletra Storage MP X10000의 SDKNVIDIA 가속 인프라에 대한 직접 메모리 액세스 지원을 포함하여 2025년 여름에 출시될 예정입니다. HPE ProLiant Compute DL380a Gen12 서버NVIDIA RTX PRO 6000 Blackwell Server Edition GPU로 구성된 이 제품은 4년 2025월 XNUMX일부터 주문 가능합니다. HPE의 OpsRamp 소프트웨어 RTX PRO 6000 출시에 맞춰 관리 및 최적화를 지원하기 위해 제공될 예정입니다.
이러한 업데이트를 통해 HPE는 AI 인프라 포트폴리오를 더욱 강화하기 위한 조치를 취하고 있으며, 운영을 지나치게 복잡하게 만들지 않으면서도 광범위한 AI 워크로드를 지원할 수 있는 확장 가능하고 관리하기 쉬운 환경을 만드는 데 중점을 두고 있는 것으로 보입니다.
StorageReview에 참여
뉴스레터 | 유튜브 | 팟캐스트 iTunes/스포티 파이 | 인스타그램 | 트위터 | 틱톡 서비스 | RSS 피드