
![]() 오늘 Pivotal Software Inc.는 Pivotal Big Data Suite의 주요 업데이트를 발표했습니다. 새로운 업데이트에는 Pivotal HD Apache Hadoop 배포에 대한 업그레이드가 포함되며 Pivotal은 Pivotal Greenplum Database를 포함한 분석 솔루션의 성능이 최대 100배 향상되었다고 주장합니다. 새로운 업그레이드는 고객이 모바일, 클라우드, 소셜 및 사물 인터넷으로 인해 급증하는 데이터 세트를 관리하고 전례 없는 속도, 규모 및 유연성으로 이러한 데이터 세트에서 가장 복잡한 쿼리를 처리할 수 있도록 지원하는 것을 목표로 합니다.
오늘 Pivotal Software Inc.는 Pivotal Big Data Suite의 주요 업데이트를 발표했습니다. 새로운 업데이트에는 Pivotal HD Apache Hadoop 배포에 대한 업그레이드가 포함되며 Pivotal은 Pivotal Greenplum Database를 포함한 분석 솔루션의 성능이 최대 100배 향상되었다고 주장합니다. 새로운 업그레이드는 고객이 모바일, 클라우드, 소셜 및 사물 인터넷으로 인해 급증하는 데이터 세트를 관리하고 전례 없는 속도, 규모 및 유연성으로 이러한 데이터 세트에서 가장 복잡한 쿼리를 처리할 수 있도록 지원하는 것을 목표로 합니다.
오늘 Pivotal Software Inc.는 Pivotal Big Data Suite의 주요 업데이트를 발표했습니다. 새로운 업데이트에는 Pivotal HD Apache Hadoop 배포에 대한 업그레이드가 포함되며 Pivotal은 Pivotal Greenplum Database를 포함한 분석 솔루션의 성능이 최대 100배 향상되었다고 주장합니다. 새로운 업그레이드는 고객이 모바일, 클라우드, 소셜 및 사물 인터넷으로 인해 급증하는 데이터 세트를 관리하고 전례 없는 속도, 규모 및 유연성으로 이러한 데이터 세트에서 가장 복잡한 쿼리를 처리할 수 있도록 지원하는 것을 목표로 합니다.
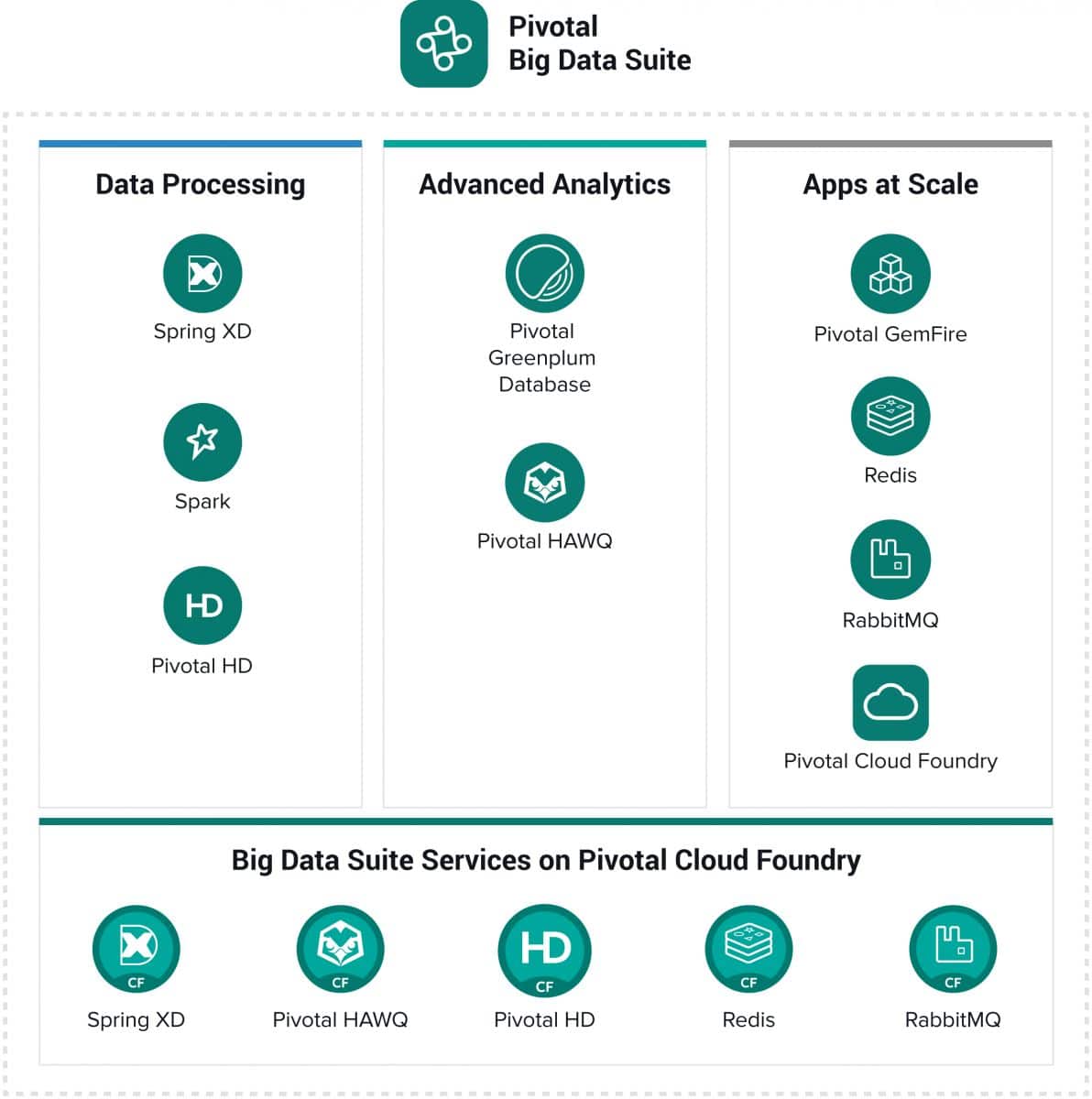
현대 기업은 빅 데이터, 민첩한 방법론 및 클라우드 네이티브 애플리케이션을 마스터할 수 있어야 합니다. 여기에서 Pivotal Big Data Suite가 등장합니다. 구독 모델을 기반으로 하고 오픈 소스 소프트웨어에 고정된 Big Data Suite는 데이터 아키텍처에 대한 새로운 접근 방식과 기존 접근 방식을 확장하고 지원하도록 설계되었습니다. 고객은 단일 제품군에서 더 나은 통찰력을 얻기 위해 필요한 모든 데이터 처리, 분석 및 애플리케이션 기능을 얻습니다. Pivotal Big Data Suite는 개방적이고 민첩하며 클라우드에서 읽을 수 있으며 해당 구성 요소는 상용 하드웨어, 사전 인증된 어플라이언스, 가상화 및 프라이빗 클라우드 인스턴스, 퍼블릭 클라우드에 배포할 수 있습니다.
새로운 업데이트 중 하나는 빅 데이터를 위한 고급 비용 기반 쿼리 최적화 프로그램인 새로운 Pivotal Query Optimizer입니다. 새로운 옵티마이저는 Pivotal Greenplum Database와 Pivotal HAWQ 모두에서 성능 향상을 주도하고 있습니다. 또 다른 업데이트는 Open Data Platform 코어를 기반으로 하는 Pivotal HD의 첫 번째 버전이며 Apache Spark를 비롯한 Apache Hadoop 구성 요소에 대한 주요 업데이트를 포함합니다. 이를 통해 고객은 Hadoop 스택에서 더 나은 안정성, 관리, 보안, 모니터링 및 데이터 처리 기능을 제공하고 더 많은 비즈니스 크리티컬 워크로드를 Hadoop으로 오프로드하여 정책 및 규정을 준수하면서 비용을 절감할 수 있습니다.
새로운 혜택은 다음과 같습니다.
- Pivotal Greenplum 데이터베이스 및 Pivotal HAWQ
- 빅 데이터를 위한 가장 진보된 비용 기반 쿼리 옵티마이저인 대폭 향상된 Pivotal Query Optimizer로 성능이 크게 향상되었습니다.
- 많은 수의 다양한 워크로드를 고성능으로 처리할 수 있는 기능을 통해 대규모 팀이 여러 분석 사용 사례에서 동시에 작업할 수 있습니다.
- 성능 저하 없이 대규모 데이터 볼륨을 처리할 수 있습니다.
- 향상된 데이터 구조 및 데이터 관리 기능
- 중추 HD
- 이제 Apache Hadoop 2.6 및 Apache Ambari로 구성된 표준화된 개방형 데이터 플랫폼 코어를 기반으로 합니다.
- 기본 조정 및 워크플로 오케스트레이션(Apache Zookeeper™ 및 Apache Oozie)과 함께 스크립팅 및 쿼리(Apache Pig 및 Apache Hive), 비관계형 데이터베이스(Apache HBase)를 위한 기존 Hadoop 구성 요소를 업데이트합니다.
- Apache Spark 코어 및 기계 학습 라이브러리를 추가합니다.
- 보안(Apache Ranger(인큐베이팅), Apache Knox), 모니터링(Apache Ambari 외에 Nagios, Ganglia) 및 데이터 처리(Apache Tez)를 위해 추가 Hadoop 구성 요소를 추가합니다.
유효성
새로운 기능을 지금 사용할 수 있습니다.