
![]() Vandaag heeft Alluxio op de AWS Global Summit de nieuwste versie van zijn data-orkestratietechnologie aangekondigd, Alluxio 2.0. De nieuwste versie komt met nieuwe innovaties voor data-engineers en is gericht op multi-cloud analytics en AI.
Vandaag heeft Alluxio op de AWS Global Summit de nieuwste versie van zijn data-orkestratietechnologie aangekondigd, Alluxio 2.0. De nieuwste versie komt met nieuwe innovaties voor data-engineers en is gericht op multi-cloud analytics en AI.
Vandaag heeft Alluxio op de AWS Global Summit de nieuwste versie van zijn data-orkestratietechnologie aangekondigd, Alluxio 2.0. De nieuwste versie komt met nieuwe innovaties voor data-engineers en is gericht op multi-cloud analytics en AI.
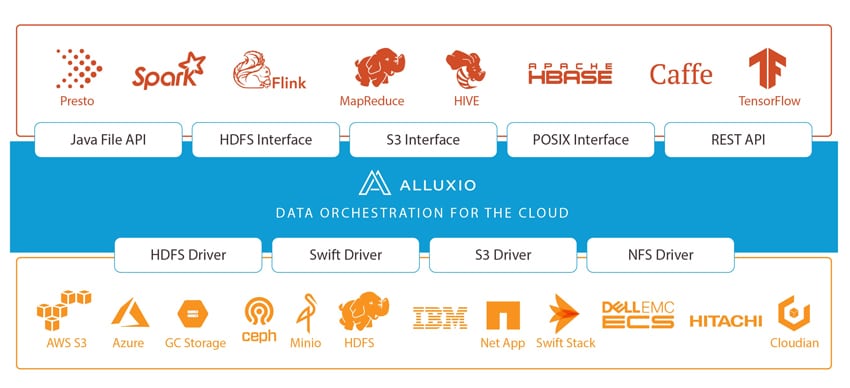
Zoals we aanvankelijk zeiden, stelt Alluxio dat zij 's werelds eerste systeem zijn dat gegevens met geheugensnelheid verenigt. De "geheugensnelheid" zou bedrijven in staat stellen om snel toegang te krijgen tot gegevens via ongelijksoortige opslagsystemen, wat op zijn beurt betekent dat ze hun gegevens efficiënter kunnen beheren, sneller waardevolle inzichten kunnen ontdekken en de acceptatie van de hybride cloud kunnen vergemakkelijken. Momenteel voert Alluxio kritieke workloads uit voor bedrijven zoals Alibaba, Baidu, Barclay's Bank, CERN, ESRI, Huawei, Intel en Juniper.
De wereld verschuift naar cloudgebaseerde rekenintensieve workloads. Deze nieuwe focus betekent dat rekenkracht onafhankelijk van opslag op een elastische manier moet worden geschaald. Hoewel dit vanuit prestatieoogpunt verschillende voordelen heeft, introduceert het potentiële hoofdpijn voor data-engineers. Alluxio probeert dit op te lossen door een abstractielaag toe te voegen die datalokaliteit, datatoegankelijkheid en data-elasticiteit brengt om datasilo's, zones, regio's en zelfs clouds te berekenen.
Functies en mogelijkheden zijn onder meer:
- Innovatie van gegevensorkestratie voor multicloud:
- Beleidsgestuurd gegevensbeheer
- Alluxio 2.0 bevat een nieuwe mogelijkheid waarmee data-engineers gegevensverplaatsing tussen opslagsystemen kunnen automatiseren op basis van vooraf gedefinieerde beleidsregels op een geautomatiseerde en doorlopende basis. Dit betekent dat wanneer gegevens worden gecreëerd en hete, warme, koude gegevens worden beheerd, Alluxio de gelaagdheid van gegevens over een willekeurig aantal opslagsystemen op locatie en in alle clouds kan automatiseren.
- Dataplatformteams kunnen nu de opslagkosten verlagen door automatisch alleen de belangrijkste gegevens in dure opslagsystemen te beheren en andere gegevens naar goedkopere opslagalternatieven te verplaatsen.
- Verbeterd beheer van beleid voor gegevenstoegang: naast fijnmazige beleidsregels op bestandsniveau kunnen gebruikers nu beleid configureren op elk map- en mapniveau om de toegang tot gegevens en de prestaties van werklasten te stroomlijnen. Deze omvatten het definiëren van gedrag voor individuele datasets op verschillende kernfuncties, zoals het schrijven van gegevens of het synchroniseren van gegevens met opslagsystemen onder Alluxio.
- Cross-cloudopslag Efficiënte gegevensverplaatsing via gegevensservice: de nieuwe gegevensservice maakt zeer efficiënte gegevensverplaatsing mogelijk, ook tussen cloudopslagsystemen zoals AWS S3 en Google GCS, waardoor dure bewerkingen op objectopslag naadloos aansluiten op het computerframework.
- Beleidsgestuurd gegevensbeheer
- Compute-geoptimaliseerde gegevenstoegang voor cloudanalyse:
- Compute-gerichte clusterpartitionering: gebruikers kunnen nu een enkele Alluxio partitioneren op basis van elke dimensie, zodat datasets voor elk framework of workload niet worden besmet door de andere. Het meest voorkomende gebruik omvat het partitioneren van het cluster op framework Spark, Presto enz. Bovendien zorgt dit voor lagere kosten voor gegevensoverdracht, waardoor gegevens worden beperkt om binnen een specifieke zone of regio te blijven.
- Integratie met externe gegevensbronnen via REST: gebruikers kunnen nu zelfs gegevens uit webgebaseerde gegevensbronnen binnenhalen om ze in Alluxio te aggregeren om hun analyses uit te voeren. Elke weblocatie met bestanden kan eenvoudig naar Alluxio worden verwezen om naar behoefte te worden opgehaald op basis van de query of modelrun.
- Andere functies zijn onder meer:
- Highly Distributed Data Services – 2.0 introduceert de Alluxio Data Service, een gedistribueerde geclusterde service, die gegevensbewerkingen zoals replicatie, persistentie mogelijk maakt voor hoge prestaties en enorme schaal.
- Adaptieve replicatie voor meer gegevenslokaliteit – Nieuwe functie om een bereik te configureren voor het aantal kopieën van gegevens die zijn opgeslagen in Alluxio en die automatisch worden beheerd.
- Hoge beschikbaarheid met Embedded Journal – Een nieuwe fouttolerantie en hoge beschikbaarheidsmodus voor bestands- en objectmetadata, het embedded journal genaamd, dat het RAFT-consensusalgoritme gebruikt en onafhankelijk is van andere externe opslagsystemen. Dit is met name handig voor het abstraheren van objectopslag.
- Alluxio POSIX API - Alluxio's FUSE-functie maakt een POSIX-compatibele API mogelijk, zodat frameworks zoals Tensorflow, Caffe en andere op Python gebaseerde modellen rechtstreeks toegang hebben tot gegevens van elk opslagsysteem via Alluxio met behulp van traditionele bestandssysteemtoegang.
- Amazon AWS-ondersteuning:
- AWS Elastic Map Reduce (EMR) Service-integratie: naarmate gebruikers overstappen op cloudservices om analytische en AI-workloads in te zetten, worden services zoals AWS EMR steeds vaker gebruikt. Alluxio kan nu naadloos worden opgestart in een AWS EMR-cluster, waardoor het beschikbaar wordt als een datalaag binnen EMR voor Spark-, Presto- en Hive-frameworks. Gebruikers hebben nu een krachtig alternatief voor cachegegevens van S3 of externe gegevens, terwijl ook het aantal gegevenskopieën in EMR wordt verminderd.
Beschikbaarheid
Zowel Alluxio 2.0 Community als Enterprise Edition zijn nu beschikbaar.
Bespreek dit verhaal
Meld u aan voor de StorageReview-nieuwsbrief