
Meta 通过对硬件基础设施的战略投资继续进行人工智能创新,这对于推进人工智能技术至关重要。该公司最近公布了其 24,576 GPU 数据中心规模集群的两次迭代的详细信息,这对于驱动下一代人工智能模型(包括 Llama 3 的开发)发挥了重要作用。
Meta 通过对硬件基础设施的战略投资继续进行人工智能创新,这对于推进人工智能技术至关重要。该公司最近公布了其 24,576 GPU 数据中心规模集群的两次迭代的详细信息,这对于驱动下一代人工智能模型(包括 Llama 3 的开发)发挥了重要作用。这一举措是 Meta 愿景的基础,即生成开放和负责任的构建所有人都可以使用通用人工智能(AGI)。
照片由 META 工程提供
在其持续发展的过程中,Meta 完善了其人工智能研究超级集群 (RSC),最初于 2022 年披露,配备 16,000 个 NVIDIA A100 GPU。 RSC 在推进开放式人工智能研究和促进复杂人工智能模型的创建方面发挥了关键作用,其应用涵盖计算机视觉、自然语言处理 (NLP)、语音识别等多个领域。
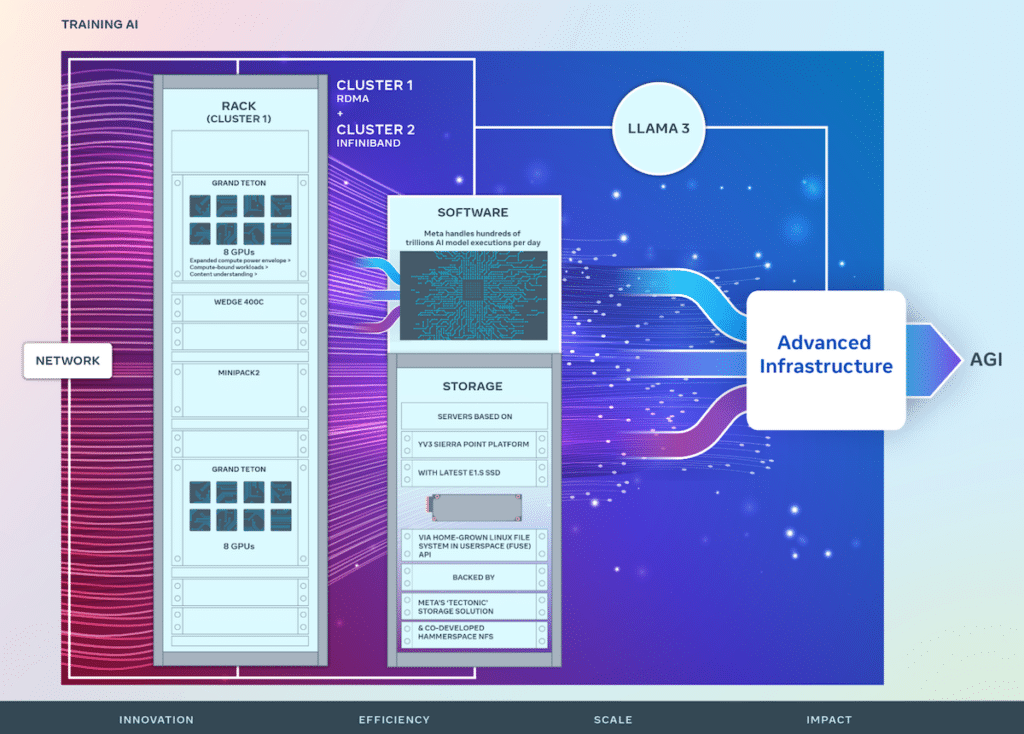
在 RSC 的成功基础上,Meta 的新人工智能集群增强了端到端人工智能系统开发,重点是优化研究人员和开发人员的体验。这些集群集成了 24,576 个 NVIDIA Tensor Core H100 GPU,并利用高性能网络结构来支持比以前更复杂的模型,为 GenAI 产品开发和研究设立了新标准。
Meta 的基础设施非常先进且适应性强,每天处理数百万亿个人工智能模型执行。硬件和网络结构的定制设计可确保人工智能研究人员获得优化的性能,同时保持数据中心的高效运营。
创新的网络解决方案已得到实施,包括一个采用融合以太网 (RoCE) 上的远程直接内存访问 (RDMA) 的集群和另一个采用 NVIDIA Quantum2 InfiniBand 结构的集群,两者都能够实现 400 Gbps 互连。这些技术实现了可扩展性和性能洞察,这对于未来大规模人工智能集群的设计至关重要。

大提顿在 OCP 2022 期间推出
Meta 的 Grand Teton 是一个内部设计的开放式 GPU 硬件平台,为开放计算项目 (OCP) 做出了贡献,并体现了多年的人工智能系统开发经验。它将电源、控制、计算和结构接口合并为一个紧密结合的单元,促进数据中心环境中的快速部署和扩展。
为了解决存储在 AI 训练中经常被忽视但至关重要的作用,Meta 在用户空间 (FUSE) API 中实现了自定义 Linux 文件系统,并由“Tectonic”分布式存储解决方案的优化版本提供支持。该设置与共同开发的 Hammerspace 并行网络文件系统 (NFS) 相结合,提供了一个可扩展的高吞吐量存储解决方案,对于处理多模式 AI 训练作业的海量数据需求至关重要。
Meta 的 YV3 Sierra Point 服务器平台由 Tectonic 和 Hammerspace 解决方案提供支持,凸显了该公司对性能、效率和可扩展性的致力于。这种远见确保存储基础设施能够满足当前的需求并进行扩展,以适应未来人工智能计划不断增长的需求。
随着人工智能系统的复杂性不断增加,Meta 继续在硬件和软件方面进行开源创新,为 OCP 和 PyTorch 做出了重大贡献,从而促进了人工智能研究社区内的协作进步。
这些人工智能训练集群的设计是 Meta 路线图不可或缺的一部分,旨在扩展其基础设施,目标是到 350,000 年底集成 100 个 NVIDIA H2024 GPU。这一轨迹凸显了 Meta 积极主动的基础设施开发方法,旨在满足人工智能的动态需求。未来人工智能的研究和应用。
参与 StorageReview
电子报 | YouTube | 播客 iTunes/Spotify | Instagram | Twitter | TikTok | RSS订阅