
![]() 今天在加利福尼亚州圣何塞举行的 2018 年开放计算项目 (OCP) 上,东芝内存美国公司宣布发布其新的 NVM Express over Fabrics (NVMe-oF) 共享加速存储软件 KumoScale。 这款新软件将帮助公司在数据中心网络上最大限度地利用 NVMe 闪存驱动器,以及定向连接 NVMe 的性能优势。 该公司还与 Portworx 合作,带来业界首个 Kubernetes 与 NVMe-oF 目标的集成。 我们还开始与 Sanmina 的 Newisys 部门一起测试 KumoScale 解决方案,结果非常惊人,我们不想等到审查完成后再分享我们所看到的一些内容。
今天在加利福尼亚州圣何塞举行的 2018 年开放计算项目 (OCP) 上,东芝内存美国公司宣布发布其新的 NVM Express over Fabrics (NVMe-oF) 共享加速存储软件 KumoScale。 这款新软件将帮助公司在数据中心网络上最大限度地利用 NVMe 闪存驱动器,以及定向连接 NVMe 的性能优势。 该公司还与 Portworx 合作,带来业界首个 Kubernetes 与 NVMe-oF 目标的集成。 我们还开始与 Sanmina 的 Newisys 部门一起测试 KumoScale 解决方案,结果非常惊人,我们不想等到审查完成后再分享我们所看到的一些内容。
今天在加利福尼亚州圣何塞举行的 2018 年开放计算项目 (OCP) 上,东芝内存美国公司宣布发布其新的 NVM Express over Fabrics (NVMe-oF) 共享加速存储软件 KumoScale。 这款新软件将帮助公司在数据中心网络上最大限度地利用 NVMe 闪存驱动器,以及定向连接 NVMe 的性能优势。 该公司还与 Portworx 合作,带来业界首个 Kubernetes 与 NVMe-oF 目标的集成。 我们还开始与 Sanmina 的 Newisys 部门一起测试 KumoScale 解决方案,结果非常惊人,我们不想等到审查完成后再分享我们所看到的一些内容。

云建立在直连 SSD 上以提高性能,但许多人发现这缺乏灵活性。 去年东芝推出了NVMe-oF技术,率先拿到 获得 UNH-IOL 认证. 该软件旨在通过管理存储功能解决上述问题,支持创建可立即大规模部署的网络存储节点——通过共享强大的 NVMe SSD 来提高它们的利用率。 KumoScale 可以利用动态编排来实现更高效的计算节点。
该软件的另一个有趣的好处是它能够为 Kubernetes 等容器编排框架启用高性能存储。 Kubernetes 的存储公司,例如 Portworx,可以利用 KumoScale 使容器化的大数据、快速数据和机器学习工作负载更易于管理并提高性能。 据两家公司称,在 KumoScale 的目标命名空间之上运行 Portworx 卷可以使 NVMe 的原始性能在领先的编排框架下得到高效灵活的配置。
TMA 和 Portworx 将于 21 月 20 日至 21 日在圣何塞会议中心的 OCP 展台#AXNUMX 联合展示 KumoScale。
审查预览
我们目前正在审查安装了 KumoScale 软件的 Newisys NSS-1160G-2N 双节点服务器。 Newisys 服务器在一个节点上通过两个 100G Mellanox 卡和 8 个 Toshiba NVMe SSD 提供存储,第二个节点用于管理目的。 负载生成来自单个 Dell PowerEdge R740xd,它通过双 100G Mellanox ConnectX-5 NIC 直接连接到机箱,运行我们的标准 VDbench 配置文件。 对于此预览,我们选择了 4K 和 64K 工作负载进行共享。
测量峰值带宽时,我们看到了超过 13GB/s 的峰值,使用了从存储节点共享的 8 个 NVMe 设备。 如您所见,延迟时间极短,最高不到 450 微秒。
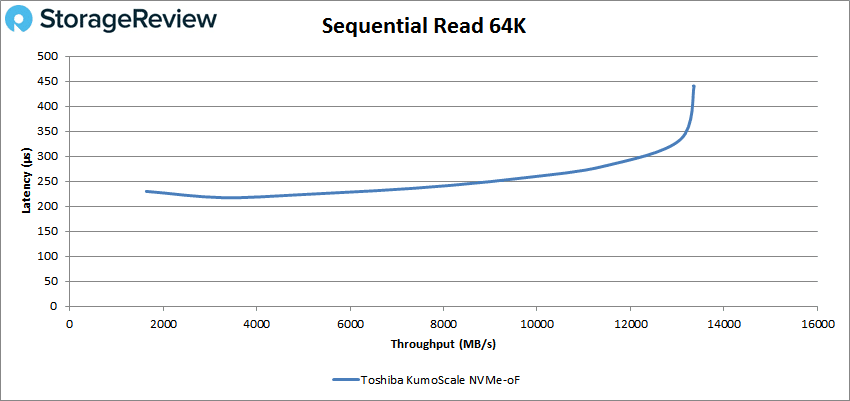
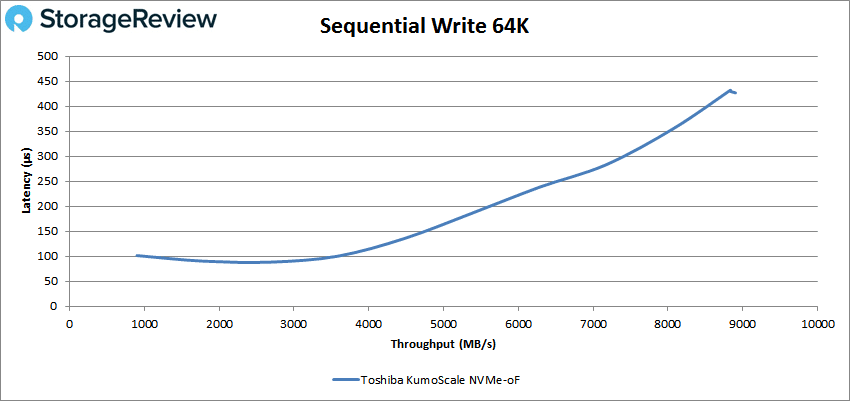
顺序写入性能非常出色,测得的峰值略低于 9GB/s,延迟从未超过 450us。
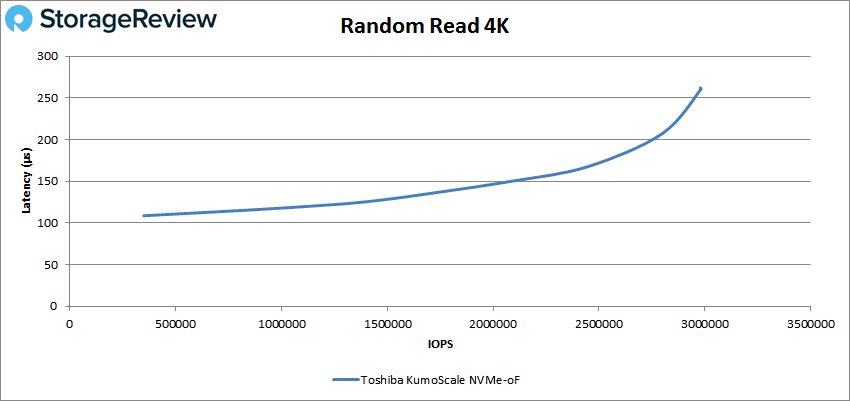
我们 4K 测试中的随机小块性能令人难以置信。 在延迟超过 2us 之前,我们看到了 150M IOPS,在 2.98us 时的峰值为 260M IOPS。
随机小块写入性能也非常出色,低负载延迟低于 50us,最高可达 1M IOPS,然后在 225M IOPS 的峰值下缓慢上升至 1.93us。
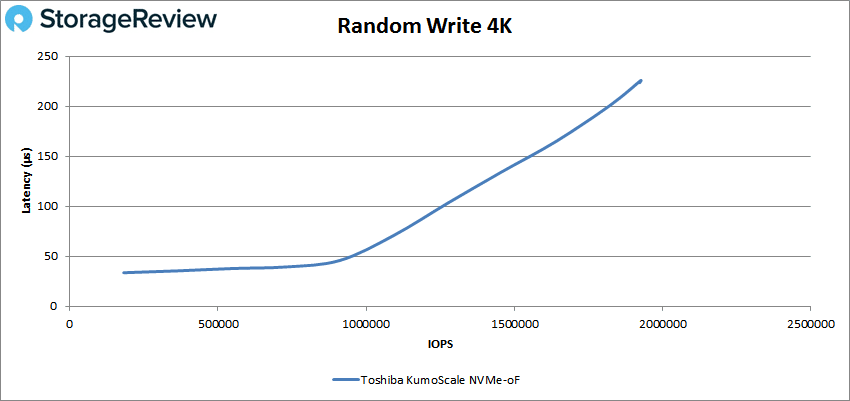
如前所述,这只是初始数据的预览,我们将进行更全面的审查。 然而,延迟数字非常可观,说明 NVMe-oF 在执行良好时的潜力。