
PEAK:AIO 令牌記憶體平台使用 KVCache 重複使用和 CXL 來提供更快的推理、更大的上下文視窗和 AI 就緒記憶體擴充。
PEAK:AIO 推出了一種創新解決方案,旨在將 KVCache 加速與 GPU 記憶體擴充統一起來,滿足大規模 AI 工作負載的需求。隨著人工智慧應用程式從靜態提示轉向動態上下文流和長期運行的代理,這個新平台滿足了推理、代理系統和模型創建的需求。人工智慧工作負載複雜性的轉變需要基礎設施的相應改進, 峰值:AIO的最新產品旨在迎接這些挑戰。
PEAK:AIO 聯合創始人兼首席人工智慧策略師 Eyal Lemberger 強調將代幣歷史視為記憶而非傳統儲存的迫切需求。他指出,現代人工智慧模型每個實例可能需要超過 500GB 的內存,並且內存擴展必須跟上計算技術的進步。 Lemberger 指出,隨著變壓器模型的成長和變得更加複雜,改造儲存堆疊或過度擴展 NVMe 等傳統方法已不再足夠。 PEAK:AIO 的新型 1U 令牌記憶體平台專為以記憶體為中心的操作而非檔案儲存而設計,這與傳統架構有著顯著的不同。
以代幣為中心的可擴展人工智慧架構
PEAK:AIO 平台是第一個實現以令牌為中心的架構的平台,該架構利用 CXL 記憶體、Gen5 NVMe 和 GPUDirect RDMA 來提供高達 150 GB/秒的持續吞吐量和低於 5 微秒的延遲。
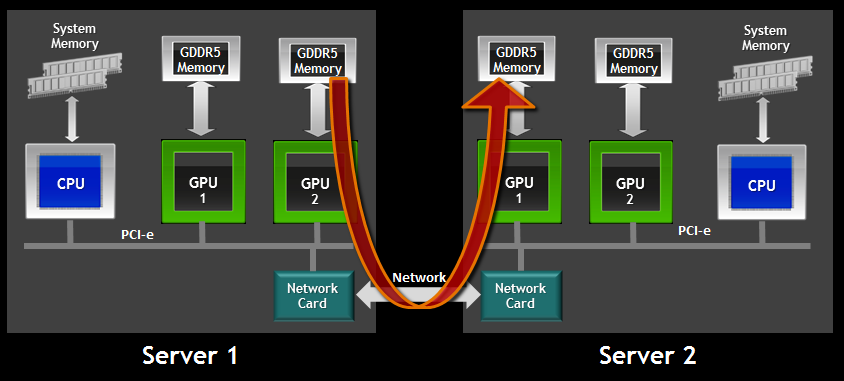
該平台支援跨會話、模型和節點重複使用 KVCache,從而實現更有效率的記憶體利用和更快的上下文切換。它還支援上下文視窗擴展,這對於維持更長的 LLM 歷史和支援更複雜的 AI 互動至關重要。透過真正的 CXL 分層卸載 GPU 內存,該解決方案緩解了 GPU 內存飽和問題,這是大規模 AI 部署中常見的瓶頸。使用 NVMe-oF 上的 RDMA 實現超低延遲訪問,確保令牌記憶體以記憶體級速度可用。
與傳統的基於 NVMe 的儲存解決方案不同,PEAK:AIO 的架構旨在充當真正的記憶體基礎架構。這使得團隊能夠以 RAM 的速度和效率快取令牌歷史記錄、注意力圖和流數據,而不是將這些元素視為文件。該平台完全符合 NVIDIA 的 KVCache 重用和記憶體回收模型,為使用 TensorRT-LLM 或 Triton 的團隊提供無縫整合。這種插件相容性加速了推理並減少了整合開銷,從而帶來了顯著的效能優勢。
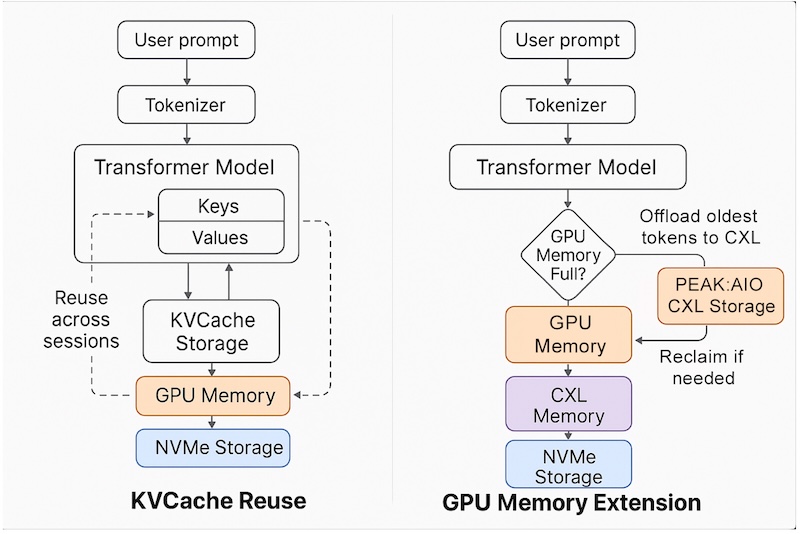
Lemberger 強調,雖然其他供應商試圖使檔案系統像記憶體一樣運行,但 PEAK:AIO 已經開發出本質上像記憶體一樣運行的基礎設施。這種區別對於現代人工智慧來說至關重要,因為現代人工智慧的首要任務是快速、內存級地存取每個令牌,而不僅僅是文件儲存。
PEAK:AIO 聯合創辦人兼首席策略長 Mark Klarzynski 強調使用 CXL 技術作為關鍵的差異化因素。他將該平台描述為 AI 的真正記憶體結構,與堆疊 NVMe 設備的競爭對手不同。 Klarzynski 指出,這項創新對於大規模提供真正的記憶體功能和支援下一代 AI 工作負載至關重要。
該解決方案完全由軟體定義,可在現成的伺服器上運行,使其可供各種企業和雲端環境存取和擴展。 PEAK:AIO 預計該平台將於第三季投入生產,將其定位為面向技術銷售、工程團隊和高階主管的變革性技術,以期為其 AI 基礎設施提供面向未來的保障。
參與 StorageReview
電子報 | YouTube | 播客 iTunes/Spotify | Instagram | Twitter | 的TikTok | RSS訂閱