
Pliops XDP LightningAI boosts LLM inference by offloading KV cache, enabling faster, scalable AI with NVIDIA Dynamo integration.
Pliops stands at the forefront of data acceleration, specializing in hardware and software solutions engineered to optimize and supercharge data-intensive workloads within cloud and enterprise data centers. Pliops Extreme Data Processor (XDP) is built to improve the performance and efficiency of modern data infrastructure by managing data flow between applications and storage, eliminating bottlenecks and reducing latency. The XDP is exceptionally well-suited for demanding environments requiring high throughput and minimal latency, such as those underpinning AI, complex databases, advanced analytics, and expansive large-scale storage systems.

As AI increasingly becomes a cornerstone of business operations and innovation, the demands on data center infrastructure have escalated exponentially, particularly for AI inference workloads. These workloads necessitate the rapid and efficient processing of vast volumes of data, placing immense strain on existing compute and storage resources. Organizations are grappling with mounting challenges in deploying scalable, cost-effective, and power-efficient infrastructure capable of consistently meeting stringent performance SLAs.
Pliops XDP LightningAI addresses these pressing challenges head-on. This innovative solution introduces a universal storage acceleration engine designed to seamlessly integrate with leading server platforms, such as Dell PowerEdge systems, and work in concert with advanced inference solutions like NVIDIA Dynamo, promising efficient AI operations.
Why KV Caching Is Critical for Scalable LLM Inference
The Mechanics and Importance of KV Caching
At the heart of optimizing transformer-based Large Language Models lies KV caching, a foundational technique that mitigates computational redundancies during autoregressive inference. In transformer architectures, generating each new token requires calculating attention between the current token’s query and the keys and values of all preceding tokens.
Without an effective caching mechanism, this process would redundantly recompute these keys and values for every token in the sequence at each generation step. This results in a computational complexity of O(n²), or quadratic complexity, for a sequence of length n. KV caching circumvents this by storing previous tokens’ computed key and value matrices directly in GPU memory; the model can reuse these precomputed tensors for subsequent steps. This reuse dramatically reduces the computational complexity to O(n) after the initial token processing, significantly accelerating inference speeds.
This gain in efficiency is paramount for real-time AI applications such as interactive chatbots, instantaneous translation services, and dynamic code generation, where latency is a critical factor directly impacting user experience and application viability.
GPU Memory Constraints: The Hidden Bottleneck
While KV caching substantially improves inference speed, it introduces pressure on GPU memory resources. The size of the KV cache grows linearly with both the sequence length (context window) and the batch size (number of concurrent requests).

In multi-tenant cloud environments or enterprise systems serving hundreds, if not thousands, of concurrent requests, this memory consumption can rapidly exhaust even the most high-end GPU infrastructure. This exhaustion forces difficult trade-offs: reduce batch sizes (lowering throughput), shorten context lengths, or invest in more GPUs (increasing CapEx).
Furthermore, a common practice among inference providers is not to persist KV Caches between user turns or messages. This means that the quadratic computation complexity for previously computed tokens is incurred anew for every subsequent interaction, negating some potential efficiency gains.
NVIDIA Dynamo: Rethinking LLM Inference at Scale

What is NVIDIA Dynamo?
NVIDIA Dynamo, a recently released and transformative open-source framework, is engineered to address the intricate challenges of distributed and disaggregated LLM inference serving. Supporting various backends, including PyTorch, SGLang, TensorRT-LLM, and vLLM, Dynamo is designed explicitly for seamlessly scaling inference operations from single-GPU deployments to thousand-GPU clusters. It introduces significant architectural innovations to combat KV cache-induced memory constraints while optimizing for maximum throughput and minimal latency.
Disaggregated Serving Architecture
A core innovation within NVIDIA Dynamo is its disaggregated serving approach. This architecture strategically decouples the computationally intensive prefill phase from the memory-bound decode phase (generating subsequent tokens). By intelligently allocating these distinct phases to separate specialized GPU pools, Dynamo enables independent optimization of each, leading to more efficient resource utilization and overall improved performance.
KV Cache Advancements
NVIDIA Dynamo also incorporates sophisticated KV Cache management capabilities. Its KV Cache-Aware Smart Router tracks the state and location of KV cache data across the entire GPU fleet. This allows it to intelligently route incoming inference requests to GPUs with relevant cache entries, minimizing costly recomputation and data transfer overhead.
Furthermore, the Dynamo Distributed KV Cache Manager directly addresses memory capacity limitations by implementing tiered offloading. This feature allows less frequently accessed or lower-priority KV cache blocks to be moved from expensive, fast HBM to more cost-effective storage solutions, such as shared CPU memory, local SSDs, or networked object storage. This hierarchical storage approach enables organizations to manage and store significantly larger volumes of KV cache data at a fraction of the cost, enhancing inference performance and economic efficiency.
It is important to clarify that, as of today, the KV cache offloading capabilities described above are part of Dynamo’s future roadmap and are not yet available in the open-source release. As such, current open-source Dynamo deployments do not support KV cache offload to tiered storage. This means that, in practice, Dynamo’s performance is still constrained by the available GPU memory.
Pliops XDP LightningAI: Solving KV Cache at Scale
Enter Pliops XDP LightningAI, which establishes an ultra-fast, scalable, petabyte-tier memory layer strategically positioned below the GPU’s HBM. This addresses organizations’ critical trade-offs between batch size, context length, model complexity, and escalating hardware costs. The Pliops solution combines its cutting-edge XDP-PRO ASIC and its KVIO Store. It enables GPU servers to efficiently offload vast quantities of KV cache data to cost-effective NVMe SSD storage, all while maintaining exceptionally low, sub-millisecond access latencies.

In practical deployments, leveraging Pliops XDP LightningAI for KV cache offloading results in virtually no discernible difference in TTFT (Time-To-First-Token) compared to scenarios where the entire KV cache is retained within the scarce and expensive HBM. This allows organizations to dramatically expand their effective memory capacity for KV caching without compromising on the critical low-latency performance demanded by real-time AI applications.

Seamless Integration Through Standards-Based Design
An advantage of Pliops XDP LightningAI is its use of open standards, ensuring effortless adoption. The solution’s NVMe-oF-native architecture guarantees broad compatibility with existing GPU server ecosystems, requiring no hardware modifications to the servers for deployment. It utilizes standard NVMe-oF over RDMA for high-speed, low-latency cache synchronization across GPU clusters. This leverages existing data center networking infrastructure, simplifying deployment and reducing integration friction.

Pliops achieves this with a cohesive solution built from two complementary technologies: XDP LightningAI and FusIOnX. While these components work together as part of the overall architecture, they serve distinct roles. The Pliops XDP LightningAI solution is architected around a dedicated hardware appliance featuring a PCIe add-in card powered by a custom XDP ASIC and an array of SSDs.
FusIOnX, on the other hand, is the complementary software platform that orchestrates and manages the intelligent use of XDP LightningAI hardware. It is a disaggregated KV-cache offloading system that eliminates redundant computation by storing and reusing previously computed KV-caches. FusIOnX provides the intelligence to identify, store, and efficiently retrieve context data that would otherwise require recomputation, thus accelerating LLM inference. The software stack offers multiple configurations tailored to different deployment scenarios, including a vLLM production stack with smart routing across multiple GPU nodes and integration with frameworks like Dynamo and SGLang.
Pliops LightningAI FusIOnX Architecture
The system architecture is built upon initiator nodes, which house the GPUs, and LightningAI target nodes, responsible for offloading the KV cache to high-performance storage. These nodes communicate over a high-speed network utilizing the NVMe-oF protocol using either DPUs’ standard NICs.

Diving deeper into the data flow, the Nvidia Dynamo worker interacts with the FusIOnX Client SDK within the application container on the GPU server. This SDK then facilitates communication via NVMe-oF through DPUs or standard NICs to the XDP LightningAI storage server hosting the FusIOnX KV Store and a Pliops XDP Pro1 acceleration card.
LightningAI Meets NVIDIA Dynamo: Performance Benchmarks
The FusIOnX-Dynamo integration benchmarks reveal impressive performance gains across multiple configurations. Tests were conducted using the Meta-Llama-3.1-70B-Instruct-FP8-dynamic model running with tensor parallelism of 2 (TP2).
Test Configuration
- Initiator (GPU Server): Dell PowerEdge XE9680 server, configured with:
- GPUs: 8 x NVIDIA H100 SXM, each with 80GB of HBM3
- DRAM: 2TB
- CPUs: Dual-socket Intel Xeon Platinum 8568Y+ processors
- Networking: 2 x NVIDIA ConnectX-7 adapters (400Gbps)
- Target (Pliops Storage Server): A Dell PowerEdge R860 node, configured with:
- DRAM: 512GB
- CPUs: Quad-socket Intel Xeon Gold 6418H processors
- Pliops Acceleration: 1 x Pliops XDP Pro1 card
- Storage: 24 x Samsung PM1733a 3.84TB NVMe SSDs, providing a substantial raw capacity for KV cache offload
- Networking: 1 x NVIDIA ConnectX-7 HHHL Adapter card (400GbE, Single-port OSFP, PCIe 5.0 x16)
- Network Interconnect: These two servers are connected via NVIDIA SN5600 Spectrum-X 800Gbps Ethernet switch, ensuring high-bandwidth and low-latency communication for NVMe-oF traffic.

Key metrics measured:
- Time-to-First-Token (TTFT): How quickly users start seeing generated content
- Time-per-Output-Token (TPOT): Time between generated tokens
- Requests-per-Second (RPS): System throughput
- Tokens-per-Second (TPS): Generation speed
The benchmarks simulated multi-turn conversations with average prompt lengths of 2,200 tokens and 100-230 output tokens per turn, with conversations spanning 2-28 turns.
Dynamo Single-Worker Performance
| Configuration | TTFT (ms) | TPOT (ms) | #clients | RPS |
|---|---|---|---|---|
| vLLM | 310 | 33 | 8 | 1.35 |
| Pliops FusIOnX | 111 | 30 | 16 | 3.03 |
| Gain | 2.79x | – | 2x | 2.24x |
Dynamo Two-Worker Performance
| Configuration | TTFT (ms) | TPOT (ms) | #clients | RPS |
|---|---|---|---|---|
| vLLM | 557 | 40 | 26 | 3.49 |
| vLLM 1P1D | 753 | 36 | 26 | 3.76 |
| Pliops FusIOnX | 166 | 38 | 56 | 8.43 |
| Gain | 3.3–4.5x | – | 2.15x | 2.24–2.4x |
Dynamo Four-Worker Performance
| Configuration | TTFT (ms) | TPOT (ms) | #clients | RPS |
|---|---|---|---|---|
| vLLM | 1192 | 41 | 60 | 7.32 |
| vLLM 2P2D | 719 | 39 | 60 | 7.99 |
| Pliops FusIOnX | 329 | 40 | 148 | 20.7 |
| Gain | 2.2–3.6x | – | 2.46x | 2.6–2.8x |
At the typical 40ms TPOT SLO (representing approximately 25 TPS/user), FusIOnX demonstrates 2.8x higher efficiency than vanilla Dynamo and 2.24x better efficiency than Dynamo’s prefill-decode disaggregated setup in terms of RPS/GPU. And at a less strict TPOT SLO, e.g., 60ms (~17 TPS/user), the efficiency grows to over 3x.

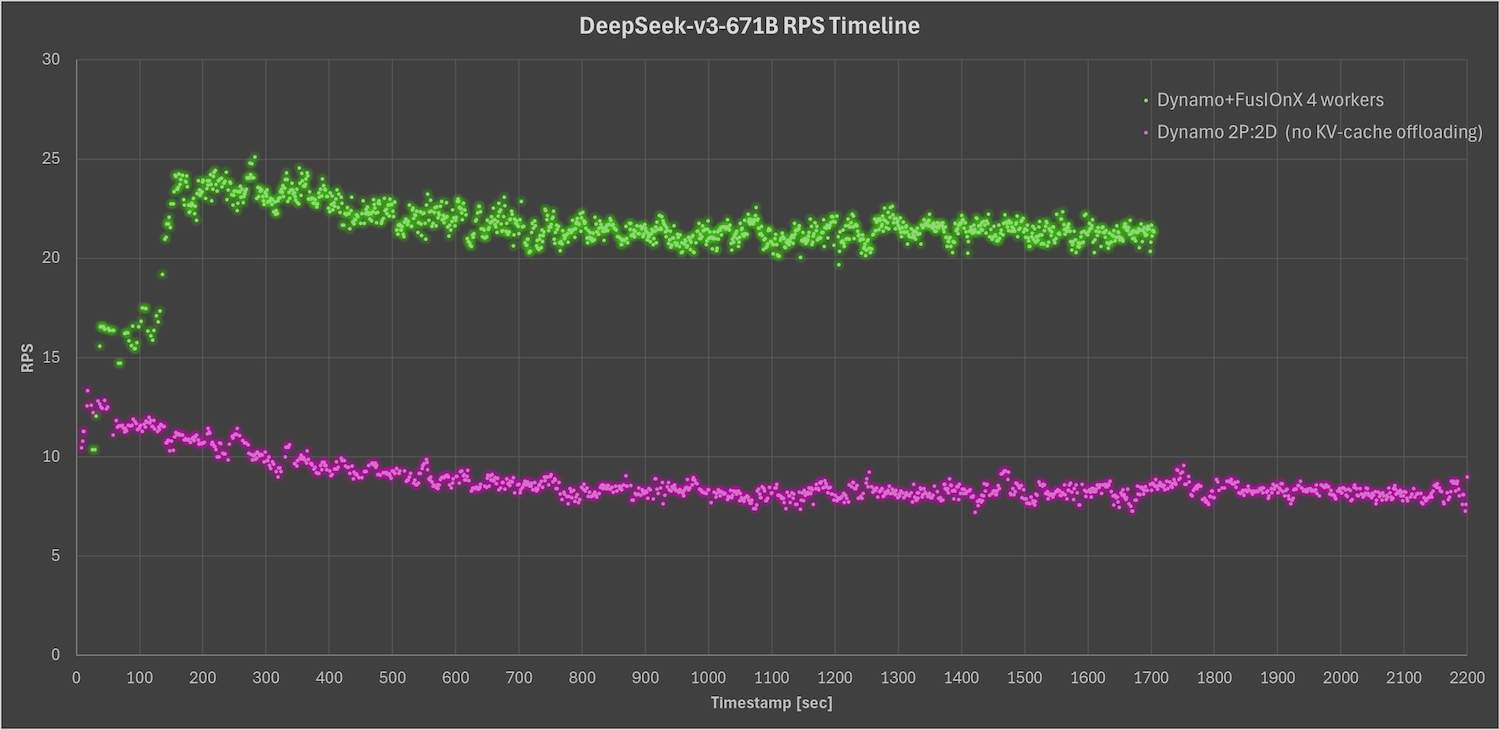
In addition, the following graph visualizes the average RPS gain achieved by Pliops compared to vanilla Dynamo across the four-worker configuration, measured over the duration of the experiment. Throughout the test window, Pliops maintained more than a 2x improvement over Dynamo, showcasing the solution’s ability to sustain high performance under realistic, production-like load conditions. This sustained throughput gain directly translates to greater user concurrency and improved service responsiveness, validating the effectiveness of KV cache offloading at scale.
Quantifying the Advantage: Real-World Benefits of KV Cache Offload
So what does this mean for businesses and the broader AI ecosystem? The dramatically reduced Time-To-First-Token (TTFT) translates directly into a significantly improved user experience, with faster, more responsive interactions. This is particularly critical for interactive applications like chatbots, virtual assistants, and real-time coding copilots, where latency can make or break usability.
Beyond individual user experience, the ability to handle two to three times more concurrent users while strictly maintaining Service-Level Objectives (SLOs) means organizations can serve a substantially larger customer base using their existing hardware infrastructure. This enhanced capacity is crucial for cloud-based inference deployments, where scaling to meet fluctuating demand is paramount.
Furthermore, the virtually unlimited storage capacity for KV caches, facilitated by Pliops XDP LightningAI, enables support for much longer context windows and a higher density of concurrent users than traditional HBM-only approaches can sustain. This capability is no longer confined to just the largest AI research labs. Inference providers of all sizes can now leverage Pliops’ solution to implement sophisticated KV caching mechanisms, similar to those employed by major AI companies like OpenAI, Anthropic, and Google.

Additionally, these providers can reduce overall power consumption by eliminating redundant computation and optimizing memory usage, contributing to more sustainable AI infrastructure. Ultimately, these efficiencies can be passed along to end-users through more competitively priced AI services, simultaneously allowing providers to maximize the utilization and return on their hardware investments with minimal additional capital expenditure.
What This Means for AI Infrastructure
Pliops XDP LightningAI, with its FusIOnX architecture, represents a significant advancement in LLM inference optimization. Addressing the critical bottleneck of KV cache management through intelligent offloading to cost-effective storage delivers substantial performance improvements across all key metrics.
The solution’s seamless integration with NVIDIA Dynamo and vLLM immediately applies to various deployment scenarios. Whether used with Dynamo’s sophisticated distributed serving capabilities or directly with vLLM, organizations can expect significant gains in throughput, latency, and cost efficiency.

As LLMs increase in size and capability and their applications become increasingly mission-critical, solutions like Pliops XDP LightningAI will be an essential tool for organizations seeking to build scalable, efficient, and cost-effective AI infrastructure.
Conclusion
Pliops XDP LightningAI, augmented by the FusIOnX architecture, delivers a leap in LLM inference efficiency by solving the persistent KV cache bottleneck. Through intelligent offloading of KV cache data to high-performance, cost-effective storage, Pliops enables organizations to dramatically expand context windows, support more concurrent users, and maintain strict latency SLOs without additional GPU investment. The seamless integration with frameworks like NVIDIA Dynamo and vLLM ensures broad applicability across modern AI serving stacks.
As LLMs grow in complexity and enterprise adoption accelerates, decoupling memory scaling from expensive GPU resources will be critical. Pliops XDP LightningAI is an enabler for next-generation AI infrastructure, empowering providers to deliver faster, more scalable, and cost-efficient AI services at scale. For organizations seeking to future-proof their AI deployments and maximize hardware ROI, Pliops offers a compelling, production-ready solution to one of the most pressing challenges in large-scale inference today.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed