
NVIDIA declares the data center is now the computer, delivering that message during Stanford’s Hot Chips conference.
NVIDIA presents at Stanford’s Hot Chips conference with a clear message: the data center is the computer, and its performance limit is determined more by the interconnecting fabric than by raw FLOPS. Throughout five sessions, NVIDIA will show how Spectrum-XGS Ethernet, fifth-generation NVLink with NVLink Fusion, CPO-powered photonic switches, and the new DGX Spark desktop supercomputer work together. This integration aims to turn tens of thousands of GPUs into a single, revenue-generating AI factory.

A Three-Layer Fabric for AI Factories
Modern LLMs are implicitly distributed applications. They stream trillions of parameters across GPUs, synchronize gradient updates at microsecond cadence, and must return a first token to a user in less than a heartbeat. That workload drives a hierarchy of interconnects:
- Scale-up within a rack so GPUs function like cores on a single, large processor.
- Scale-out across racks so the cluster operates as a unified system.
- Scale across entire data centers for geo-redundancy, capacity sharing, and compliance with regulations.
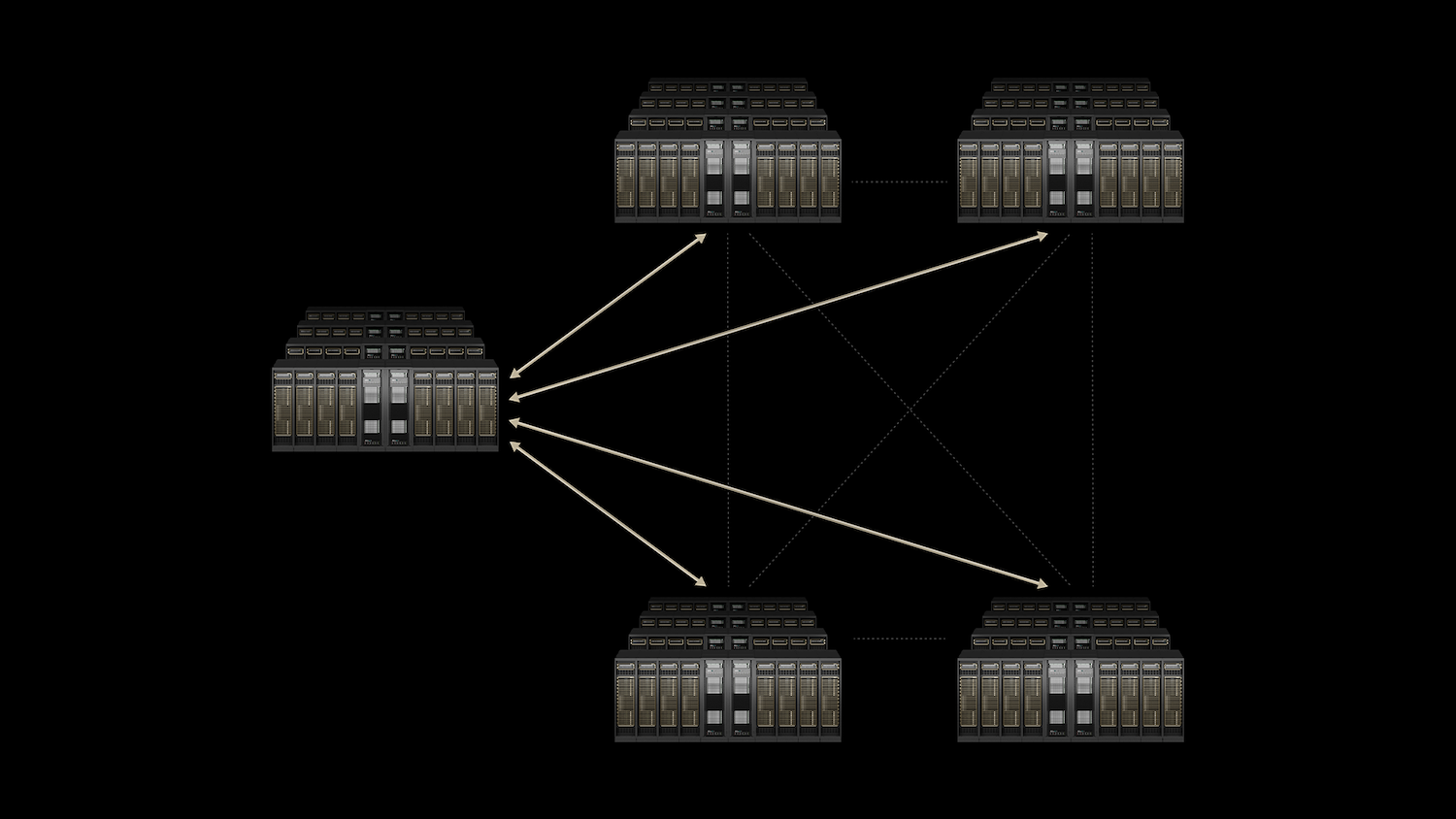
NVIDIA’s answer is a vertically integrated stack. NVLink and NVLink Switch own the scale-up domain; Quantum InfiniBand and Spectrum-X own scale-out; the new Spectrum-XGS Ethernet extends lossless, AI-tuned networking across data centers. Co-Packaged Optics (CPO) reduces the power and density limits that million-GPU clusters would otherwise hit.
Spectrum-XGS Ethernet
Traditional Ethernet technology was primarily designed to handle best-effort traffic, which means it worked well for simple, single-server communications. However, as we move into a world increasingly reliant on AI, we find ourselves facing new challenges.
With the rise of AI collectives and multi-tenant inference systems, the requirements for network performance have evolved significantly. These modern applications demand a level of reliability and speed that traditional Ethernet simply can’t provide.
Specifically, they require zero jitter, meaning no variability in latency, which is crucial for real-time processing. Additionally, deterministic latency ensures that responses are predictable and consistent, which is vital for applications that rely on immediate feedback. Finally, near-line-rate throughput is essential to handle the high volume of data being processed during microbursty loads, where data traffic can spike unexpectedly.

Spectrum-X is a solution that operates seamlessly within a data center, while Spectrum-XGS takes this innovation to the next level by extending its capabilities across multiple data centers. It integrates advanced Spectrum-6 or -4 ASIC-based switches with super-fast 800-Gb/s SuperNICs, specifically the BlueField-3 or ConnectX-8 variants. These technologies work together to efficiently manage congestion and reorder packets, ensuring smooth data flow.
What sets this system apart is its intelligent telemetry that collects data from every port and feeds it into in-switch congestion-control logic, enabling real-time traffic reshaping. In production clusters, this results in remarkable performance, maintaining throughput above 95 percent of theoretical capacity at a staggering 32k GPU scale. In contrast, traditional 800 G Ethernet struggles, only achieving about 60 percent throughput when facing collective collisions.
Moreover, Spectrum-XGS guarantees standards compliance, making SONiC and Cumulus Linux integral components of its ecosystem. This means that cloud and enterprise operators can retain their existing automation stacks while benefiting from the superior determinism typically associated with InfiniBand. The enhancements lead to higher GPU utilization and reduced latency, translating into more tokens per watt and tighter service level objectives. Additionally, it empowers operators to onboard new tenants onto the same fleet without experiencing performance dips, making it a game-changer in the industry.
NVLink and NVLink Fusion: The Rack as One Giant GPU
Fifth-generation NVLink delivers an impressive 1.8TB/s of point-to-point bandwidth and an impressive 130TB/s of aggregate bandwidth within an NVL72 rack. This enhanced connectivity allows every GPU to communicate directly with every other GPU in just a single hop, effectively turning the entire rack into a coherent memory domain. Thanks to the NVIDIA Collective Communications Library (NCCL), which has now been fine-tuned over ten years, application developers can effortlessly achieve near-wire rates without needing to write custom communication code for different topologies.
Moreover, the recent announcement of NVLink Fusion opens exciting possibilities for hyperscalers. This innovation enables custom CPUs or XPUs to seamlessly integrate NVLink SERDES or chiplets via UCIe for accelerators, or NVLink-C2C for CPUs, allowing these components to be directly placed onto the NVLink fabric. A significant advantage of Fusion is its modular MGX rack specification, which comes with a fully qualified supply chain. This means that the same vendors currently supplying NVL72 racks can also deliver Fusion racks, significantly reducing time-to-market for companies looking to implement this technology.

When it comes to inference economics, the influence of NVLink is evident on the traditional throughput-per-watt versus latency Pareto frontier. By transitioning from a PCIe mesh to an NVLink Switch node, both throughput and latency improve, and further advancements can be achieved by upgrading to the NVLink rack. This translates into processing more user queries per kilowatt-hour while also lowering the amortized capital expenditure per token generated, making NVLink a powerful tool for enhancing operational efficiency.
Fifth-generation NVLink delivers 1.8 TB/s of point-to-point bandwidth and 130 TB/s of aggregate bandwidth inside an NVL72 rack. With NVLink Switch, every GPU sees every other in a single hop, making the full rack a coherent memory domain. Collective operations run through NCCL, a library now in its tenth year of production, tuned for every imaginable topology and automatically topology-aware. So application developers need no custom comms code to achieve near-wire rates.
Co-Packaged Optics (CPO): Breaking the Power Wall at 800 Gb/s and Beyond
Traditional pluggable-module switches have been the networking standard for some time now. However, the inefficiencies inherent in these systems are becoming increasingly apparent. When data exits the ASIC, it travels along lengthy PCB traces and passes through several connectors before reaching a DSP-heavy optical module. This journey results in significant losses, often up to 22dB in the electrical domain, and consumes a staggering 30W per port just to recover the signal. As we push towards higher data rates, such as 200G PAM4 today and an ambitious 1.6 T in the near future, the limitations of this architecture become clear, leading to explosive power budgets and constraints on faceplate density.

Enter NVIDIA’s innovative solutions: Quantum-X Photonics for InfiniBand and Spectrum-X Photonics for Ethernet. By integrating the optical engines directly onto the switch package, they drastically reduce the electrical path length. This not only minimizes loss to around 4 dB but also cuts the port power consumption down to approximately 9 W—an impressive improvement.
Next week, we’ll see the launch of two cutting-edge liquid-cooled chassis: the 128-port model, boasting a whopping 102.4 Tb/s throughput, and the 512-port model, which pushes this boundary even further to 409.6 Tb/s. The latter model features an integrated fiber shuffle, ensuring that every port connects seamlessly to the correct fiber bundle without the need for cumbersome manual patching. Initial field data is promising, indicating a remarkable 3.5 times better power efficiency and about 10 times greater mean-time-between-failure when compared to traditional pluggables. Additionally, the bring-up window per cluster is 1.3 times faster, streamlining deployment.

While these advanced solutions won’t be available until 2026, design-ins are already underway. This is crucial for operators planning gigawatt-class facilities or governments considering million-GPU national labs. NVIDIA’s CPO (Coherent Photonics Optics) technology clearly defines a path to staying within power envelopes and avoiding the dreaded optics maintenance nightmare, paving the way for a more efficient and powerful future in high-performance networking.
DGX Spark and the System: From Desktop Prototype to Rack-Scale Production
Not every workload starts at hyperscale. DGX Spark, powered by the new GB10 Superchip, compresses Blackwell Tensor Cores, NVFP4 (4-bit floating point) inference, and all CUDA-X libraries into a deskside chassis. Developers train, fine-tune, and RAG-compose locally, then lift-and-shift identical containers onto GB200 or GB300 NVL72 racks when workloads mature.

That continuum lets enterprises pilot agentic AI, robotics perception, or multi-modal generative tasks without blocking on cluster slots. For the field, Spark is a Trojan horse: place one in a customer lab, let their researchers see 4-bit inference speed-ups firsthand, and expansions follow.
The Software Multiplier: TensorRT-LLM, Dynamo, and NIM Microservices
Hardware interconnects set ceilings; software determines how close real workloads get. NVIDIA will demo TensorRT-LLM running the 120-billion-parameter GPT-OSS model in NVFP4, hitting four times the interactivity of stock TorchServe on long contexts. On GB200 racks, DeepSeek-R1 at 671 B sees 2.5× higher throughput per GPU with Dynamo’s disaggregated pipeline scheduler, without raising cost per query. All of this arrives as NIM microservices—containerized endpoints that drop into Kubernetes clusters or on-prem bare-metal stacks alike.
Open source underpins the stack. RAPIDS accelerates ETL end-to-end on GPUs; CUTLASS templates enable custom high-performance kernels; NeMo and BioNeMo extend PyTorch for frontier LLM and protein-folding training while staying 100 percent OSS. The message to buyers wary of lock-in: NVIDIA is “open where it matters, optimized where it counts.”
Competitive and Commercial Implications
NVIDIA has carved out a unique position in the tech landscape through its vertically integrated approach, particularly in contrast to merchant-silicon switch vendors and disaggregated accelerator startups. This strategy allows NVIDIA to offer not merely individual components but comprehensive solutions that encompass a reference architecture. This architecture is supported by a proven supply chain, a clearly defined two-year roadmap, and a high-level API surface known as NIM, which simplifies the complexity of wiring for developers.
For hyperscalers, NVIDIA’s offerings are compelling due to their emphasis on deterministic Service Level Agreements (SLAs) and minimal operational risk. By implementing NVLink racks, these organizations can achieve premium inference capabilities, which are essential for applications requiring rapid data processing. Additionally, the Spectrum-X technology facilitates capacity scale-out, enabling hyperscalers to expand their infrastructure seamlessly. The introduction of Spectrum-XGS allows for the federation of regions, thereby enhancing the efficiency of resource allocation across geographically distributed data centers. This integration supports the operation of standard Ethernet control planes, ensuring compatibility and ease of management within existing infrastructure.
For enterprises, the appeal of NVIDIA’s technology lies in its ability to maximize revenue per rack. The Spectrum-X system, for instance, significantly enhances the effectiveness of GPU cycles—reportedly by up to 35 percent. This means that businesses can achieve greater output, whether in the form of tokens, images, or automated actions, without increasing capital expenditures. Consequently, companies can derive more value from their existing investments, aligning with contemporary needs for efficiency and cost-effectiveness in a competitive market.
The Bottom Line
The narrative surrounding Hot Chips signifies a notable shift in the landscape of computing technology, particularly in relation to artificial intelligence (AI). It emphasizes that networking is now regarded as a fundamental accelerator in computing, comparable in significance to advancements like tensor cores.
Technologies such as NVLink are pivotal as they transform a rack of servers into a cohesive logical chip, enhancing performance and efficiency. Spectrum-X plays a crucial role in facilitating sub-millisecond collectives across extensive networks, while Spectrum-XGS extends this high-performance fabric on a global scale. Additionally, CPO is designed to ensure that power and density requirements are future-proofed, catering to the evolving demands of AI applications. DGX Spark, on the other hand, is instrumental in fostering the adoption of these technologies, encouraging enterprises to embrace innovative solutions.
Collectively, these advancements have the potential to shift the economic dynamics of both inference and training processes. This is particularly relevant as businesses are currently at a crossroads, weighing their options between building new infrastructure, renting existing solutions, or delaying investments in large-scale AI capabilities. NVIDIA’s position is unequivocal: organizations should invest in building their own infrastructure, but with an emphasis on a networking framework that is meticulously designed—from the copper spine to the photonic switch—to support the forthcoming era dominated by AI-driven factories.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed