
![]() 오늘 AWS Global Summit에서 Alluxio는 데이터 오케스트레이션 기술의 최신 버전인 Alluxio 2.0을 발표했습니다. 최신 버전은 데이터 엔지니어를 위한 새로운 혁신과 함께 제공되며 멀티 클라우드 분석 및 AI를 목표로 합니다.
오늘 AWS Global Summit에서 Alluxio는 데이터 오케스트레이션 기술의 최신 버전인 Alluxio 2.0을 발표했습니다. 최신 버전은 데이터 엔지니어를 위한 새로운 혁신과 함께 제공되며 멀티 클라우드 분석 및 AI를 목표로 합니다.
오늘 AWS Global Summit에서 Alluxio는 데이터 오케스트레이션 기술의 최신 버전인 Alluxio 2.0을 발표했습니다. 최신 버전은 데이터 엔지니어를 위한 새로운 혁신과 함께 제공되며 멀티 클라우드 분석 및 AI를 목표로 합니다.
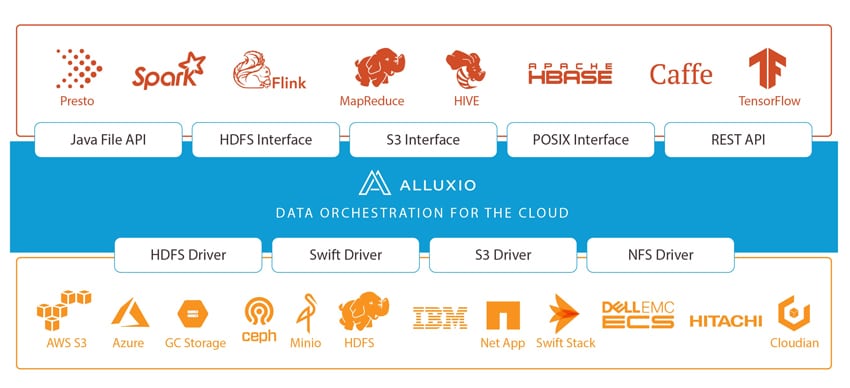
처음에 언급했듯이 Alluxio는 메모리 속도로 데이터를 통합하는 세계 최초의 시스템이라고 말합니다. "메모리 속도"는 기업이 서로 다른 스토리지 시스템에서 데이터에 신속하게 액세스할 수 있도록 하여 데이터를 보다 효율적으로 관리하고 가치 있는 인사이트를 더 빠르게 발견하며 하이브리드 클라우드를 쉽게 채택할 수 있음을 의미합니다. 현재 Alluxio는 Alibaba, Baidu, Barclay's Bank, CERN, ESRI, Huawei, Intel 및 Juniper와 같은 회사의 중요한 워크로드를 실행합니다.
세상은 클라우드 기반 컴퓨팅 집약적 워크로드로 전환하고 있습니다. 이 새로운 초점은 컴퓨팅이 탄력적인 방식으로 스토리지와 독립적으로 확장되어야 함을 의미합니다. 성능 측면에서 여기에는 몇 가지 이점이 있지만 데이터 엔지니어에게는 잠재적인 골칫거리가 됩니다. Alluxio는 데이터 사일로, 구역, 지역 및 심지어 클라우드 전반에 걸쳐 데이터 지역성, 데이터 접근성 및 데이터 탄력성을 컴퓨팅에 제공하는 추상화 계층을 추가하여 이 문제를 해결하는 것을 목표로 합니다.
특징 및 기능은 다음과 같습니다.
- 멀티 클라우드를 위한 데이터 오케스트레이션 혁신:
- 정책 기반 데이터 관리
- Alluxio 2.0에는 데이터 엔지니어가 자동화되고 지속적으로 사전 정의된 정책에 따라 스토리지 시스템 간에 데이터 이동을 자동화할 수 있는 새로운 기능이 포함되어 있습니다. 이는 데이터가 생성되고 핫, 웜, 콜드 데이터가 관리됨에 따라 Alluxio가 온프레미스 및 모든 클라우드에 걸쳐 여러 스토리지 시스템에서 데이터 계층화를 자동화할 수 있음을 의미합니다.
- 이제 데이터 플랫폼 팀은 값비싼 스토리지 시스템에서 가장 중요한 데이터만 자동으로 관리하고 다른 데이터는 저렴한 스토리지 대안으로 이동하여 스토리지 비용을 절감할 수 있습니다.
- 향상된 데이터 액세스 정책 관리: 파일 수준의 세분화된 정책 외에도 이제 사용자는 모든 디렉터리 및 폴더 수준에서 정책을 구성하여 데이터 액세스와 워크로드 성능을 합리화할 수 있습니다. 여기에는 데이터 쓰기 또는 Alluxio에서 스토리지 시스템과 데이터 동기화와 같은 다양한 핵심 기능에 대한 개별 데이터 세트의 동작 정의가 포함됩니다.
- 데이터 서비스를 통한 클라우드 스토리지 간 효율적인 데이터 이동: 새로운 데이터 서비스는 AWS S3 및 Google GCS와 같은 클라우드 저장소 전반을 포함하여 매우 효율적인 데이터 이동을 허용하여 객체 스토리지에서 비용이 많이 드는 작업을 컴퓨팅 프레임워크에 매끄럽게 만듭니다.
- 정책 기반 데이터 관리
- 클라우드 분석을 위한 컴퓨팅 최적화 데이터 액세스:
- 컴퓨팅 중심 클러스터 파티셔닝: 사용자는 이제 모든 차원을 기반으로 단일 Alluxio를 파티셔닝할 수 있으므로 각 프레임워크 또는 워크로드의 데이터 세트가 서로 오염되지 않습니다. 가장 일반적인 용도에는 프레임워크 Spark, Presto 등으로 클러스터를 분할하는 것이 포함됩니다. 또한 이를 통해 데이터 전송 비용을 줄이고 데이터를 특정 영역 또는 지역 내에 유지하도록 제한할 수 있습니다.
- REST를 통한 외부 데이터 소스와의 통합: 이제 사용자는 웹 기반 데이터 소스에서도 데이터를 가져와 Alluxio에서 집계하여 분석을 수행할 수 있습니다. 파일이 있는 모든 웹 위치는 쿼리 또는 모델 실행을 기반으로 필요에 따라 가져올 Alluxio를 가리키도록 단순화할 수 있습니다.
- 기타 기능은 다음과 같습니다.
- 고도로 분산된 데이터 서비스 – 2.0은 복제, 지속성과 같은 데이터 작업을 통해 고성능 및 대규모 확장이 가능한 분산 클러스터형 서비스인 Alluxio 데이터 서비스를 도입합니다.
- 증가된 데이터 지역성을 위한 적응형 복제 - 자동으로 관리되는 Alluxio에 저장된 데이터 사본 수의 범위를 구성하는 새로운 기능입니다.
- 포함된 저널의 고가용성 – RAFT 합의 알고리즘을 사용하고 다른 외부 스토리지 시스템과 독립적인 포함된 저널이라고 하는 파일 및 개체 메타데이터에 대한 새로운 내결함성 및 고가용성 모드입니다. 이것은 객체 스토리지를 추상화하는 데 특히 유용합니다.
- Alluxio POSIX API – Alluxio의 FUSE 기능은 Tensorflow, Caffe 및 기타 Python 기반 모델과 같은 프레임워크가 기존 파일 시스템 액세스를 사용하여 Alluxio를 통해 모든 스토리지 시스템의 데이터에 직접 액세스할 수 있도록 POSIX 호환 API를 지원합니다.
- 아마존 AWS 지원:
- AWS EMR(Elastic Map Reduce) 서비스 통합: 사용자가 클라우드 서비스로 이동하여 분석 및 AI 워크로드를 배포함에 따라 AWS EMR과 같은 서비스의 사용이 증가하고 있습니다. Alluxio는 이제 AWS EMR 클러스터로 원활하게 부트스트랩되어 Spark, Presto 및 Hive 프레임워크용 EMR 내에서 데이터 계층으로 사용할 수 있습니다. 이제 사용자는 EMR에서 유지 관리되는 데이터 사본을 줄이면서 S3 또는 원격 데이터의 캐시 데이터에 대한 고성능 대안을 갖게 되었습니다.
유효성
이제 Alluxio 2.0 Community 및 Enterprise Edition을 모두 사용할 수 있습니다.
이 이야기에 대해 토론하기