

AI infrastructures are notoriously resource-intensive, and enterprises consistently grapple with the challenge of optimizing GPU utilization. Dell Technologies, through its AI Factory platform, is tackling this challenge by integrating NVIDIA’s recently acquired orchestration solution, Run:ai. In a recent Dell blog, the company highlighted how Run:ai maximizes resource utilization and accelerates AI outcomes, transforming the way enterprises deploy and manage GPU resources at scale.

Dell NVL72 Cluster
What Exactly is Run:ai?
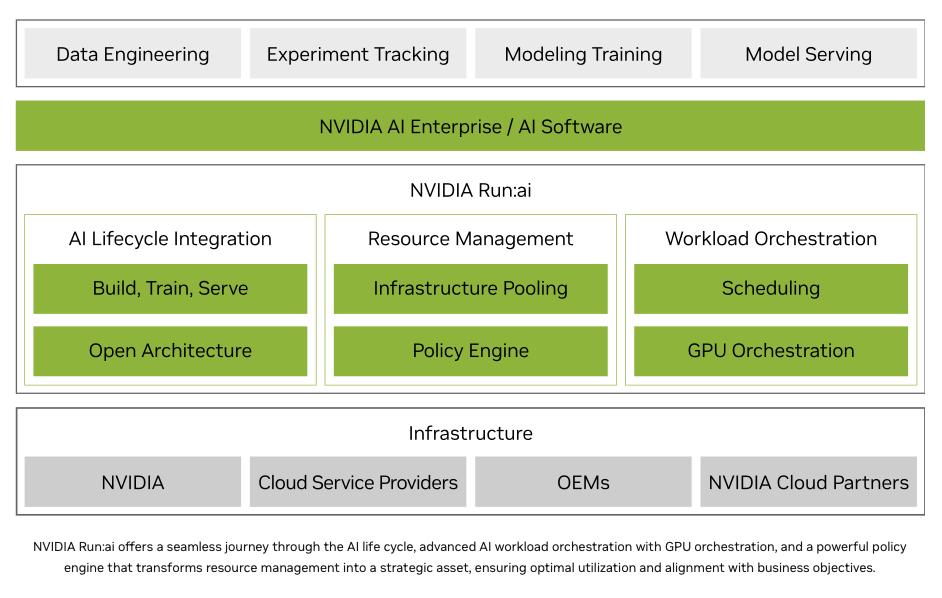
Run:ai is an orchestration platform built on Kubernetes, designed specifically for GPU-centric workloads. Founded in 2018, Run:ai gained traction by addressing a pervasive industry challenge: inefficient use of GPUs. Traditionally, GPUs assigned to AI workloads often sit idle or underutilized. Run:ai solves this by dynamically pooling and intelligently scheduling GPU resources, enabling fractional GPU allocation, efficient multi-GPU deployments, and seamless management across hybrid, cloud, and on-premises environments.
Recognizing the potential of Run:ai to dramatically reshape AI infrastructure, NVIDIA completed its acquisition of the company in December 2024 for approximately $700 million. Interestingly, NVIDIA has committed to eventually open-sourcing Run:ai, signaling its intention to foster broad ecosystem adoption beyond its hardware platforms. This move is anticipated further to accelerate innovation and industry-wide efficiency across the board.
For those seeking a deeper technical perspective on resource management, NVIDIA’s documentation details how Run:ai is essential for orchestrating workloads on GB200 NVL72 systems. The doc highlights a critical gap: Kubernetes does not natively recognize NVIDIA’s MNNVL architecture, which makes managing and scheduling workloads across these high-performance domains more complex. Run:ai abstracts this complexity away by automatically detecting NVLink domains and simplifying the submission of distributed workloads. This ensures that pods are correctly placed on nodes with NVLink interconnects, eliminating the need for deep hardware knowledge or manual configuration for each job. These capabilities demonstrate how the platform streamlines operations in dense training environments, enabling organizations to fully leverage the power of advanced hardware configurations, such as the GB200 NVL72.
Why This Matters for the Enterprise
For organizations running GPU-intensive workloads, particularly those involving generative AI and large language models, GPU underutilization represents a substantial risk: waste of investment. Run:ai directly addresses these inefficiencies, with NVIDIA reporting that organizations leveraging the platform can see GPU utilization improvements by up to five times.
This level of optimization not only enhances ROI but also fundamentally reshapes operational efficiency. Teams previously constrained by limited resources and complex scheduling processes now have the tools to deploy more models concurrently, scale rapidly, and experiment more aggressively, all without additional capital expenditure on hardware. While these methodologies are common in large HPC deployments, the level of efficiency required for maximizing GPU utilization is less common in the enterprise.
Broad Industry Momentum
Several major infrastructure providers are embracing the platform, signaling growing momentum across the enterprise IT landscape.
Dell continues to expand its AI Factory framework, with NVIDIA technologies at its core, including Run:ai. Dell’s use of Run:ai illustrates how enterprises can move from siloed, manual resource allocation to more dynamic, automated scheduling that drives higher efficiency across multi-tenant environments.
HPE offers Run:ai as part of its GreenLake Marketplace, integrating it with the Ezmeral platform to enable advanced GPU scheduling, fractional allocation, and hybrid infrastructure orchestration. This allows customers to deploy and manage AI workloads with greater precision and scalability.
Cisco integrates Run:ai with its UCS X-Series servers and Intersight cloud operations platform. Their solution highlights quota management, fractional GPU sharing, and real-time monitoring to support large-scale AI deployments on-premises.

We’ve highlighted just a few of the Run:ai partners. NVIDIA has an extensive list of logos as seen above. Across the board, leading OEMs and cloud platform providers are aligning with Run:ai as they seek to deliver more innovative and efficient AI infrastructure solutions.


 Amazon
Amazon