

Qumulo File System is Qumulo’s unique software-defined distributed file system that spans the data center, private and public cloud. Its software is built for the hybrid cloud, allowing it to run on pre-configured and pre-qualified industry standard hardware platforms, as well as natively across multiple public clouds. In our lab, we had the opportunity to study at Qumulo’s software and some of its most significant capabilities. In this particular review, we take a look at Qumulo’s file system and its graphical user interface (GUI).
To innovate, organizations depend on modern storage, data infrastructure, legacy and cloud-based applications and services, and cloud storage, as well as unstructured data management and platforms. However, unstructured data is becoming a pain in the neck for companies wanting to migrate to the cloud or leverage a hybrid-cloud model, as this kind of data creates a new data silo; in most cloud platforms available. The IT department faces this consequence that, more often than not, it is overwhelmed to manage workloads in two different file systems: the one on their premises and one in the cloud.

Nonetheless, the real problem is not cloud platforms nor unstructured data platforms. We are still using legacy file storage that is not proper for making the transition to the cloud. As Qumulo highlights, IT has changed, but file storage hasn’t. The last successful file storage architectures were created more than 15 years ago before the cloud boomed. In contrast, modern file storage should be cloud-ready: unify all unstructured data types, scale to billions of files, span multiple data centers, and the cloud itself. Also, provide visibility and automation with real-time analytics and API driven control.
Qumulo: a Cloud-Ready File System
Identifying itself as a different type of storage company, Qumulo claims to have the first file system to address hybrid cloud workloads and to provide cloud-native file data services. With this software, the company targets unstructured data platforms and powers applications and microservices for builders and developers. The Qumulo file system software is available in the public, private, and hybrid cloud.

Layers of Qumulo’s software include:
- Platforms. Current hardware platforms include HPE and Fujitsu, and public clouds AWS and GCP. Qumulo also recently announced the ability to Shift data from file to object in order to leverage cloud-native applications and services that leverage object data.
- The operating system. Based on standard Ubuntu Linux.
- Scalable Block Store (SBS). The foundation of Qumulo. Enables scale, portability, protection, and performance.
- The File System. It enables scalable file counts and high-performance file operations. Also, it provides real-time insight into performance and capacity.
- Data Services. Protect, secure, and manage data in the Qumulo platform using the enterprise-grade tools. This layer consists of five capabilities: snapshots, replication, quotas, audit, and role-based access control (RBAC).
- Management and Programmability. Enable to build integrated solutions with the Qumulo platform, and administrators to automate and manage their data services.
- Data Access and Authentication. Enable access to data using standard applications and operating systems while ensuring enterprise-grade security. This layer supports enterprise access protocols, including NFS, SMB, and FTP.
Our focus here is the file system, which is based on the concept of organizing data in logical structures and enabling workloads with massive file counts. The file system uses a distributed architecture that presents a single namespace. Used platforms are shared-nothing clusters of independent nodes, each node providing capacity and performance. And, individual nodes consistently coordinate with each other, making it possible for any client to connect to any node and read and write in the namespace. This structure is very interesting; its purposed for creators to collaborate on data sets as they move through the data lifecycle. It also provides real-time insight into performance and capacity utilization, even when systems scale to petabytes and billions of files.
The Qumulo File System organizes data into directories and presents data to SMB and NFS clients with the ability to share data across protocols, giving multiple different users and application types access to the same data. The file system has unique properties where it stands out: the use of B-trees and a built in real-time data analytics engine.
With the use of B-trees structure, Qumulo can scale to billions of files without experiencing problems prevalent in other systems. B-trees are particularly well-suited for systems that read and write large numbers of data blocks because they are “shallow” data structures that minimize the amount of I/O required for each operation as the number of data increases. These structures are ideal for file systems and extensive database indexes.
Another critical part of the Qumulo File System is the data-aware capability with a real-time analytics engine. Data awareness means multi-dimensional visibility into the storage system, providing powerful insights about systems content, activity, users, and more. With Qumulo’s real-time analytics, storage administrators can quickly monitor storage usage and performance, including throughput and latency. This visibility empowers organizations to gain control over their unstructured data, and reduce overall operational and capital costs, by proactively managing current needs as well as better predicting future storage requirements. The Qumulo web-UI, as reviewed in the section below, brings this visibility to the next system management level.
With its software architecture and its particular file system, Qumulo allows organizations to achieve business goals that were previously impossible in the on-prem data center alone. One of the advantages of Qumulo is to run its file system on-premises and then run the exact same software in the cloud. The company is well-known as a scale-out file storage provider. Now, using the elasticity of the cloud and the scale of both cloud compute and cloud storage infrastructure, coupled with Qumulo’s software makes it very powerful to move data back and forth, and easily scale-out or scale-up the data center. For instance, companies could take their on-prem apps as it is, moving it up into the cloud, and it just works. And if a user has file data that they want to leverage with cloud services such as machine learning or AI, Qumulo’s Shift functionality will copy the data to a cloud object store to gain access to cloud-native application innovation.
As organizations move these workloads to the cloud, they also want to comprehend how their data is performing. The same experience that Qumulo’s analytics offers for hardware platforms is found in the cloud, offering a full hybrid-cloud experience. Either if companies run the software into a physical appliance or into the cloud, the software is the same, including the same GUI and capabilities.
For more details on features and capabilities, we encourage you to visit the technical documentation on Qumulo’s website.
Qumulo Performance
Performance Configuration
The configuration of the Qumulo nodes in our 5-node cluster included dual 25GbE ports in LACP with four 480GB SATA SSDs and twelve 6TB SATA HDDs each. For our storage tests we provisioned a single NFS namespace to our eight Dell EMC PowerEdge R740xd servers each with a single 25G port assigned to the vSwitch connecting to the NFS share. We then used our 16 CentOS LoadGens in VMware, each with twin 125GB vDisks allocated, giving us a total of a 4TB footprint on the cluster.
When it comes to benchmarking storage arrays, application testing is best, and synthetic testing comes in second place. While not a perfect representation of actual workloads, synthetic tests do help to baseline storage devices with a repeatability factor that makes it easy to do apples-to-apples comparison between competing solutions. These workloads offer a range of different testing profiles ranging from “four corners” tests, common database transfer size tests, as well as trace captures from different VDI environments. All of these tests leverage the common vdBench workload generator, with a scripting engine to automate and capture results over a large compute testing cluster. This allows us to repeat the same workloads across a wide range of storage devices, including flash arrays and individual storage devices.
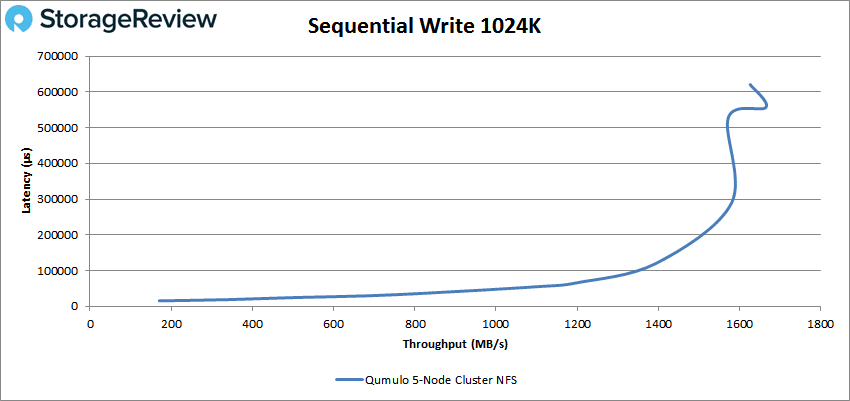
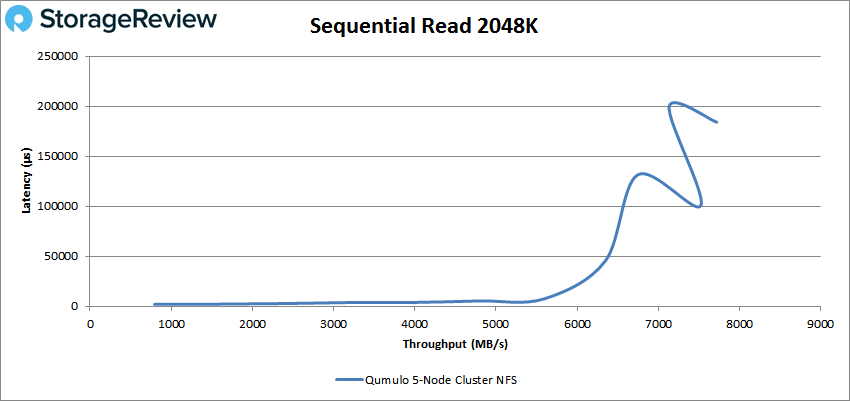
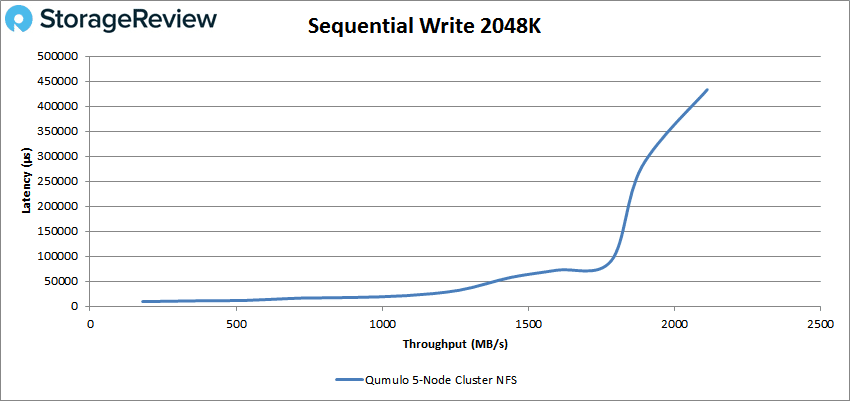
With the Qumulo storage array being optimized for large-block transfers, our tests focused on 64K, 1024K and 2048K sequential transfers.
Profiles:
- 64K Sequential Read: 100% Read, 32 threads, 0-120% iorate
- 64K Sequential Write: 100% Write, 32 threads, 0-120% iorate
- 1024K Sequential Read: 100% Read, 32 threads, 0-120% iorate
- 1024K Sequential Write: 100% Write, 32 threads, 0-120% iorate
- 2048K Sequential Read: 100% Read, 32 threads, 0-120% iorate
- 2048K Sequential Write: 100% Write, 32 threads, 0-120% iorate
First up is our 64K sequential benchmark 74,619 IOPS or 4.66GB/s at a latency of 11.3ms.
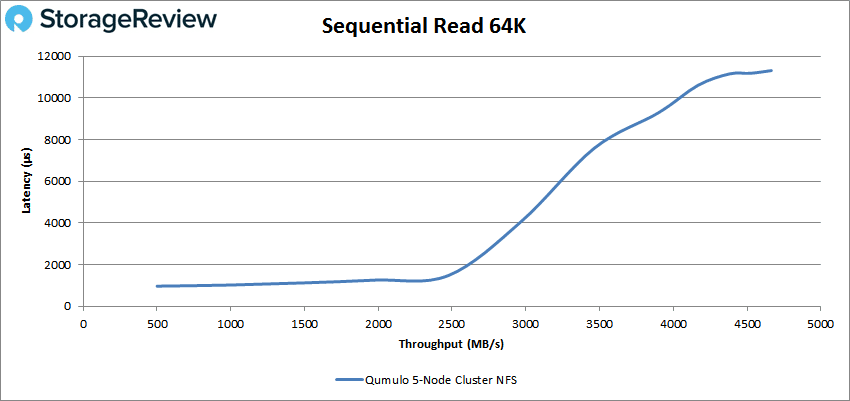
64K write saw a peak performance of about 9K IOPS or 555MB/s at a latency of 110ms.
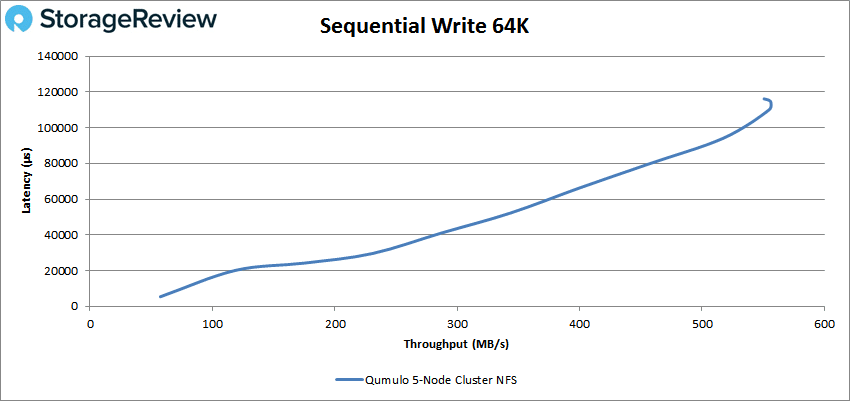
Next we move onto our 1024K tests. For read we saw a peak performance of 7,128 IOPS or 7.13GB/s at a latency of 108ms.
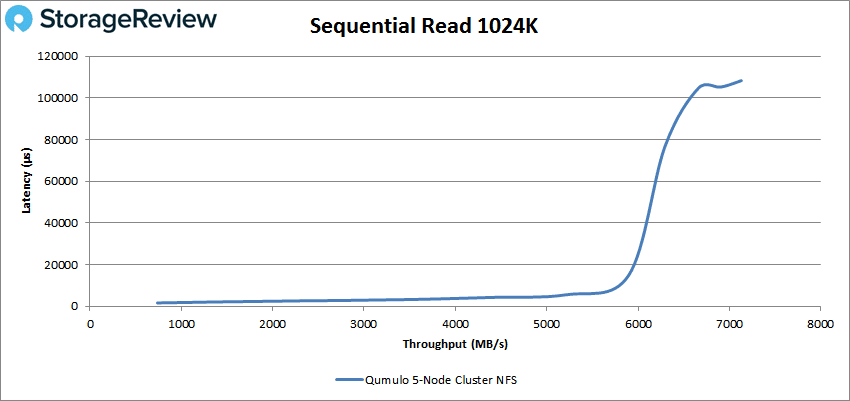
1024K write saw a peak of roughly 1,670 IOPS or 1.6GB/s at a latency of 557ms before dropping off some.
Our final sequential benchmarks are our 2048K. In read performance we saw a peak of 3,858 IOPS or 7.7GB/s at a latency of 184ms.
Finally, in our 2048K write we saw a peak of 1,055 IOPS or 2.1GB/s at a latency of 433ms.
Qumulo Web UI Overview
In the following section, we overview Qumulo’s web user interface and some of its key configurations. The company offers this web-based UI for administrators to deploy, manage, and monitor data center and cloud environments.
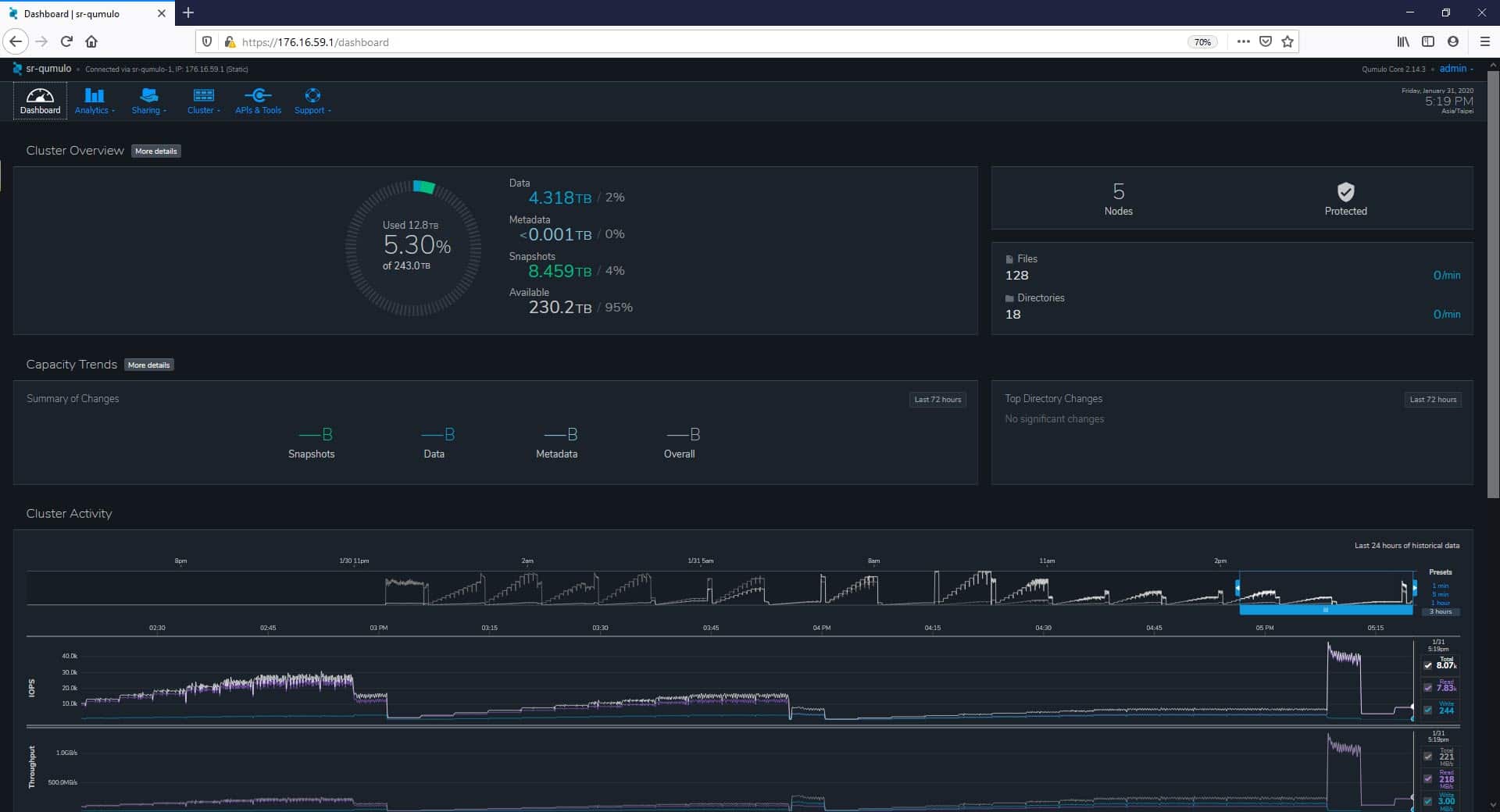
After logging in to the cluster as admin, we are brought directly to the Dashboard page. At this point, we immediately realize the unique and modern-looking Web UI proposed by Qumulo. This web UI consists of an intuitive menu well organized in tabs; we see it on the top left of the screen, which quickly includes all the categories needed to deploy, manage, and monitor our infrastructure. The main menu consists of the Dashboard, Analytics, Sharing, Cluster, API’s & Tools, and Support tabs. Pointing on these tabs, the UI displays a drop-down list to access to all the different pages that the UI offers. On the top-right corner, users can see the current software version, the time (based on the web browser’s client local time), and the current logged user.
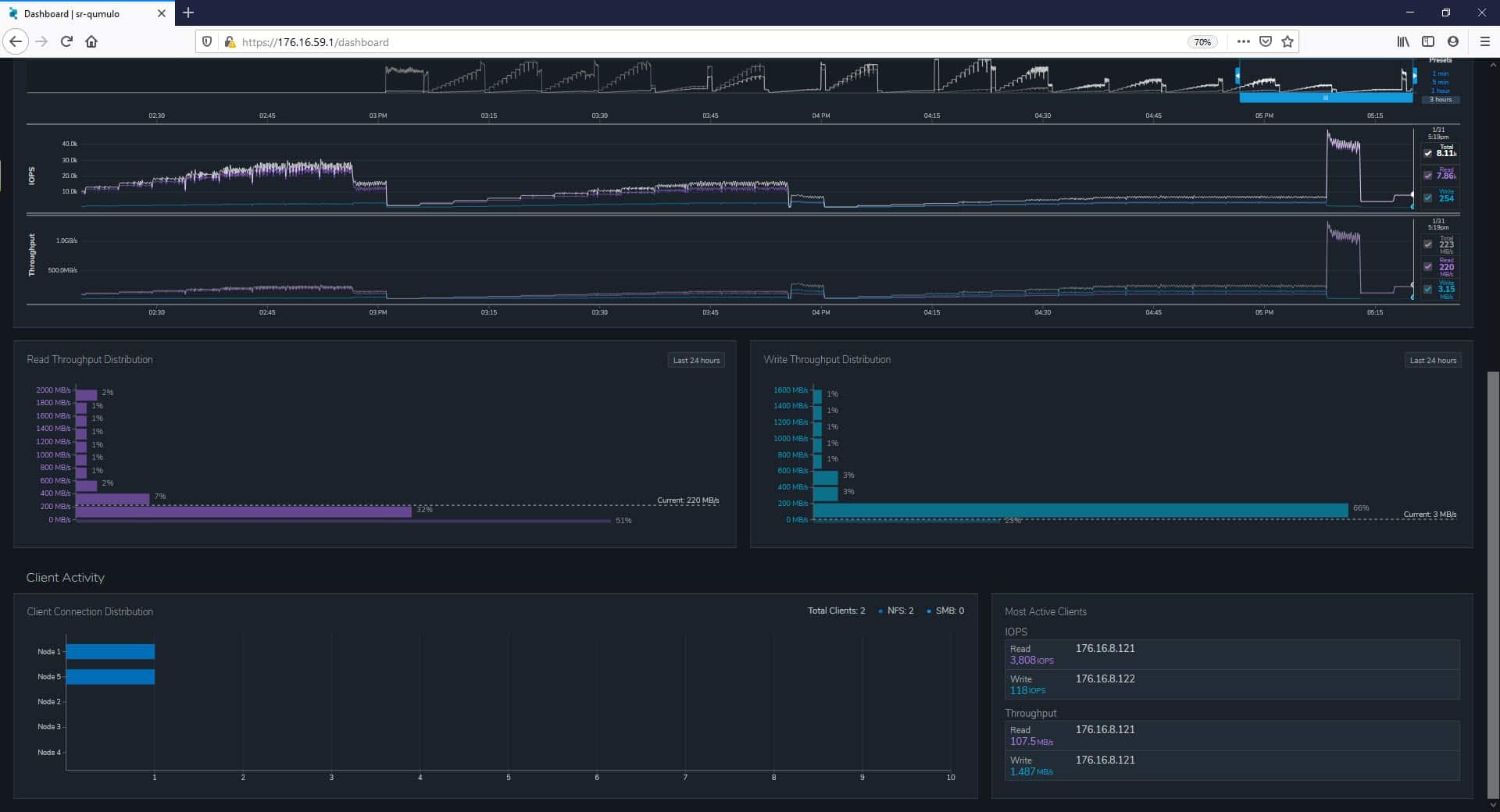
Still, on the Dashboard page, we notice an attractive UI layout that facilitates the monitoring of infrastructures, and where we can observe different critical areas like Cluster Overview, Capacity Trends, Client Activity, and in real-time, Cluster Activity.
One concept that we particularly liked about the UI, in the Dashboard area, is the dynamic interaction with all its elements. For example, under Cluster Activity, one can easily drag to move, expand, or narrow the desired information activity that we want to monitor, within 24 hours. Here we also have some presets with periods of 1 min, 5 min, 1 hour, and the default, 3 hours. The metrics (IOPS and Throughput) will adjust accordingly to the peak data.
Scrolling-down on the Dashboard page, we find the Client Activity area.
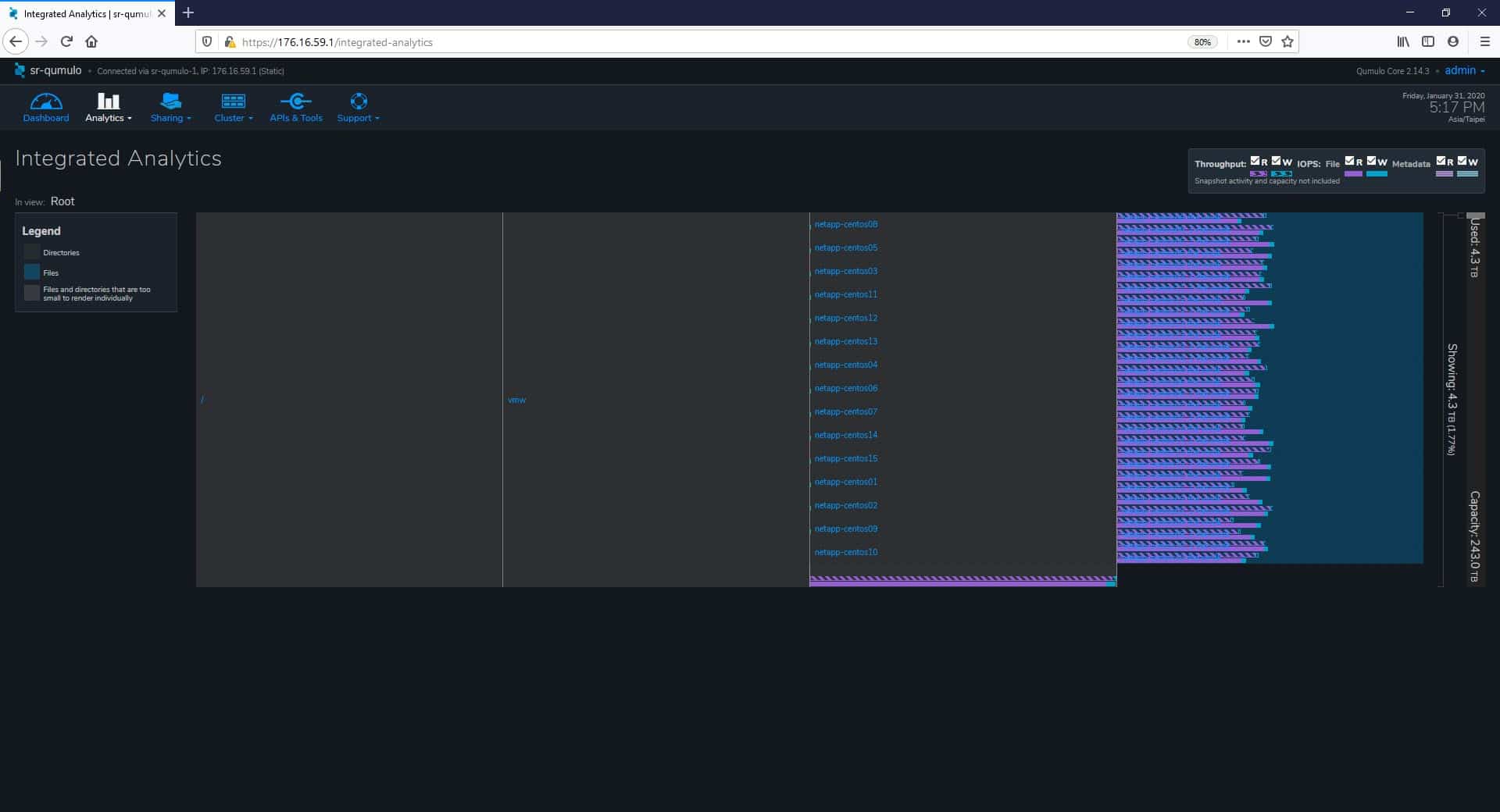
Now, we move straight to the area where Qumulo stands out, the analytics. As mentioned previously, Qumulo allows administrators to manage the data and users in real-time. Under Analytics > Integrated Analytics, we can see the information pane to the left populated with the clients that are using the most resources of the system, and with the directories and files are actively being read and written. This information is shown after clicking on a specific directory or subdirectory.
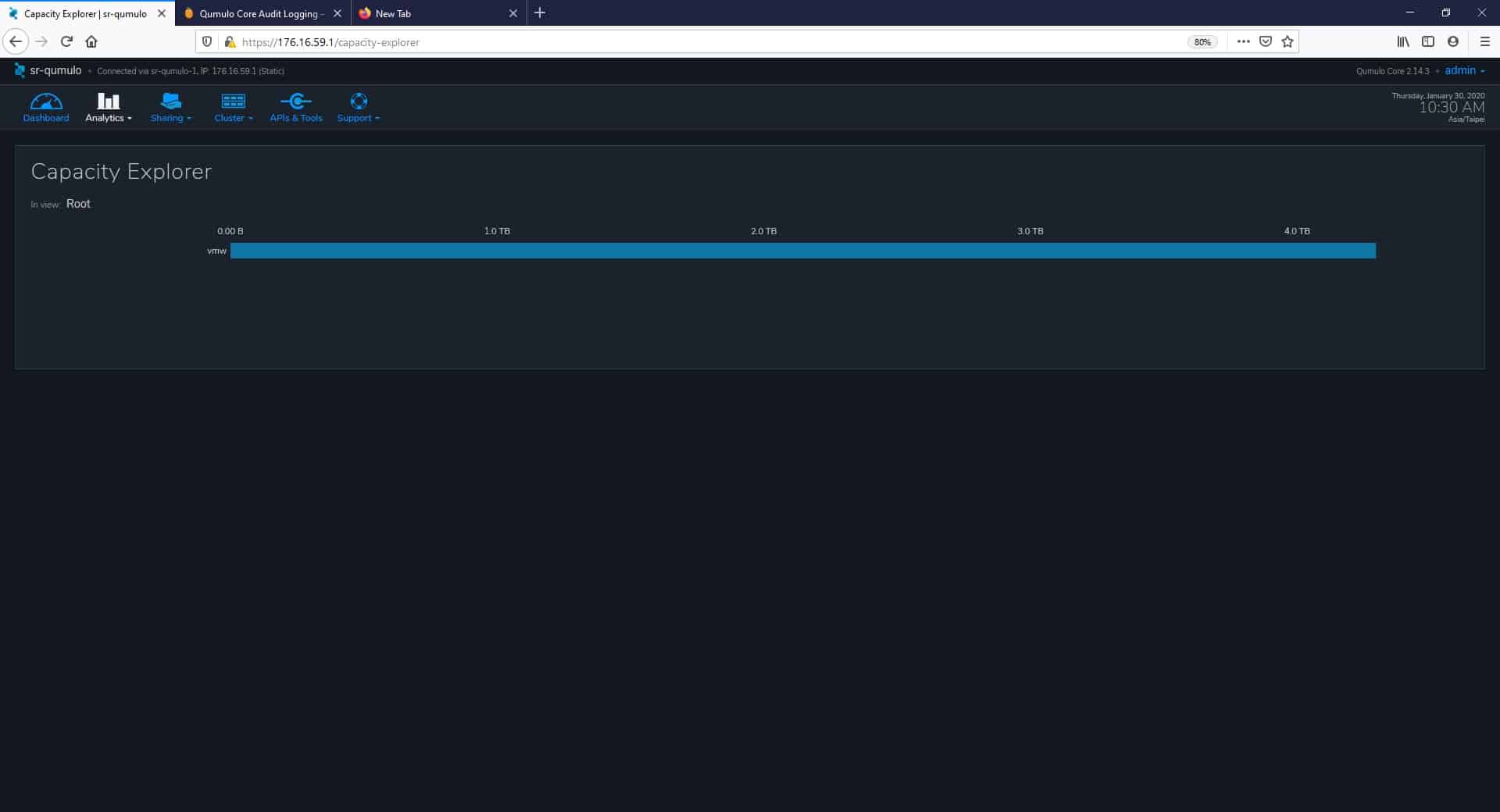
Moving to the Capacity Explorer page, still under the Analytics tab, we can see how the capacity is distributed on the system. First, we have a general overview of the directory’s capacity, listed from largest to smallest.
By clicking on a directory, we can dig down and explore each of them in a more detailed perspective. As an example, the image below shows the subdirectories contained in the directory named “vmw.”
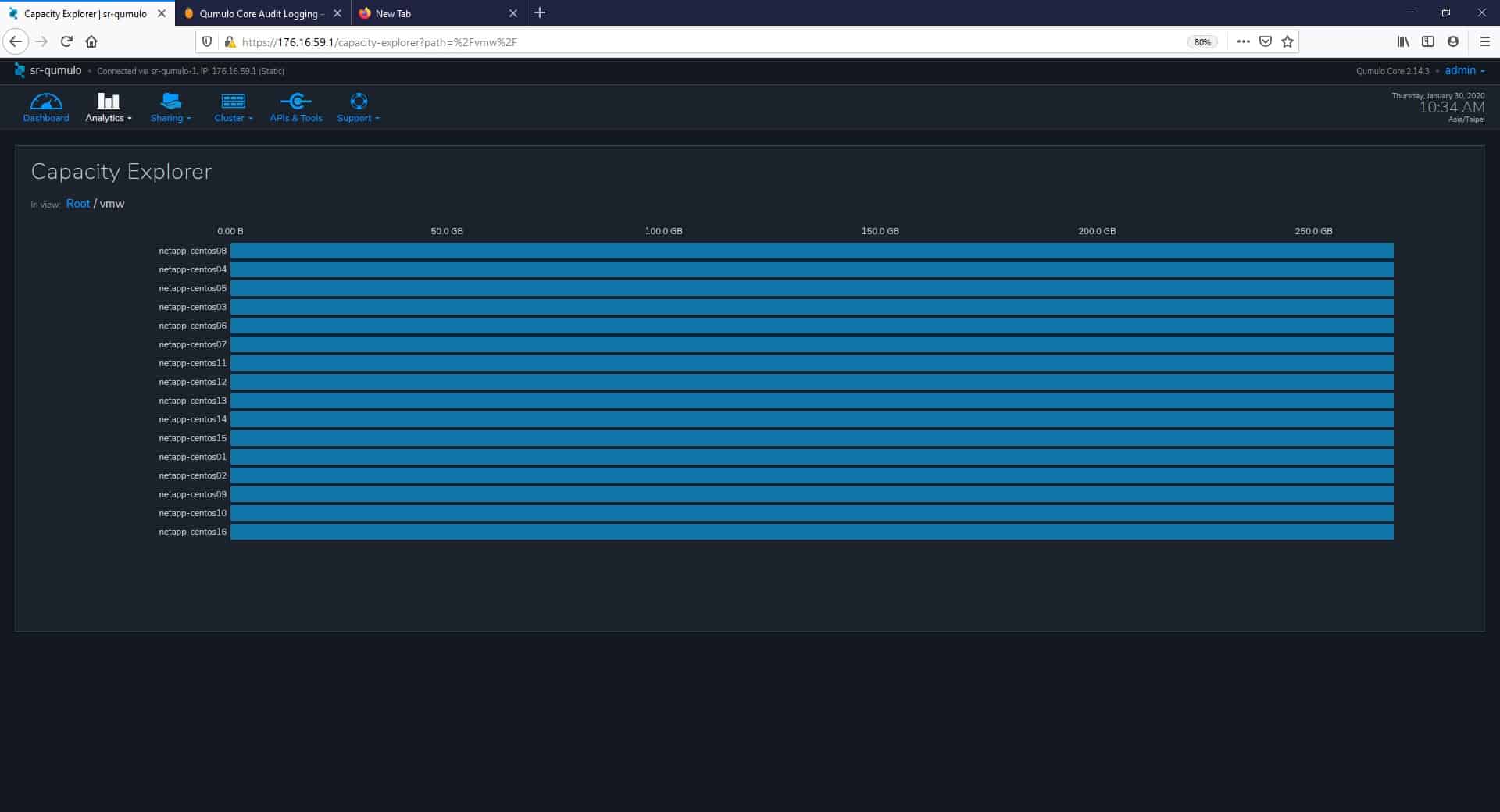
And if we continue clicking on the subdirectories, we can eventually reach details at the file level. This time, we clicked on the subdirectory named “netapp-centos01”.
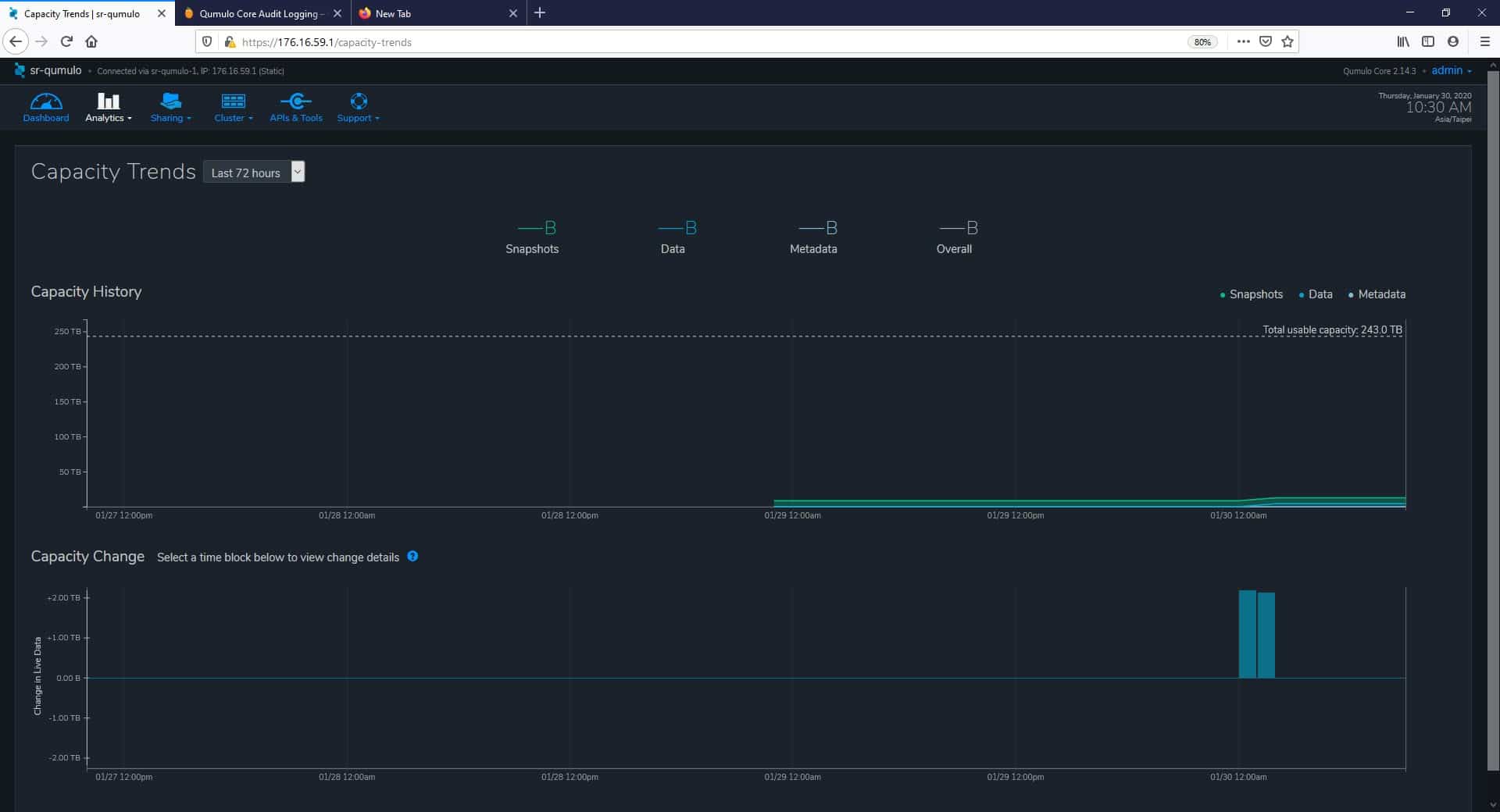
The next page under analytics is Capacity Trends. From here, we can get all the details needed to monitor and manage the capacity usage overtime of the cluster. The two main areas here are Capacity History and Capacity Change. These capacities include metadata, data, and snapshots (excluded only in Capacity Change). History and changes of the capacity can be quickly filtered by time frames of the last 72 hours, last 30 days, or las 52 weeks. These are great options that help storage admins to visualize and manage the cluster for scale and to explore significant capacity changing events.
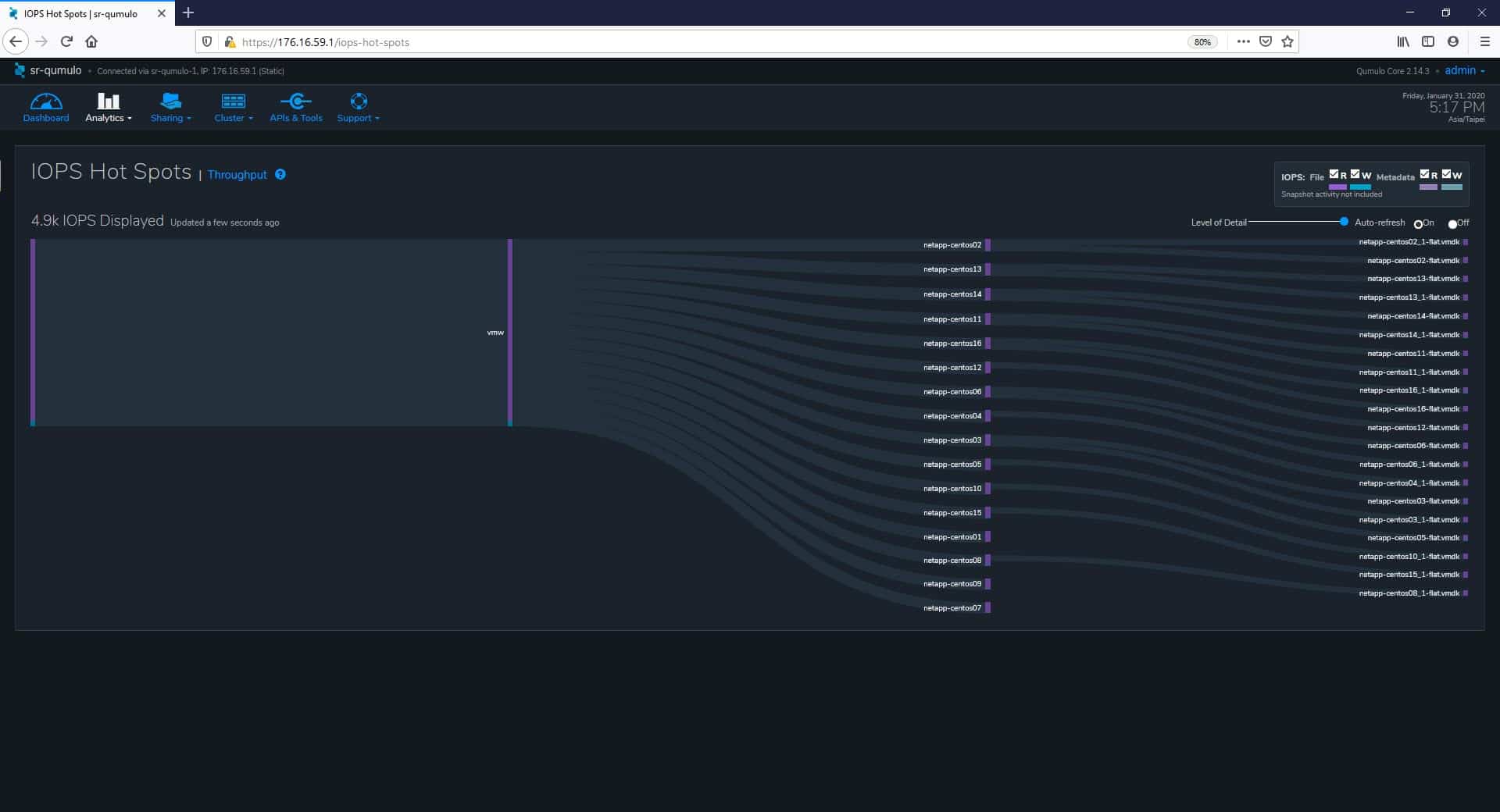
The next section that we explored under the Analytics tab is Activity, where we can find Throughput Hot Spots, IOPS Hot Spots, Clients, and Paths. The IOPS Hot Spots page lets us identify the input/output per second hotspots in our storage system. The graph shows the most active directories in terms of read/write operations for files and metadata. The level of detail of these data can be adjusted using the slider on the top-right of the graph. A great option to pause the display is also available, from the Auto-refresh radio button.
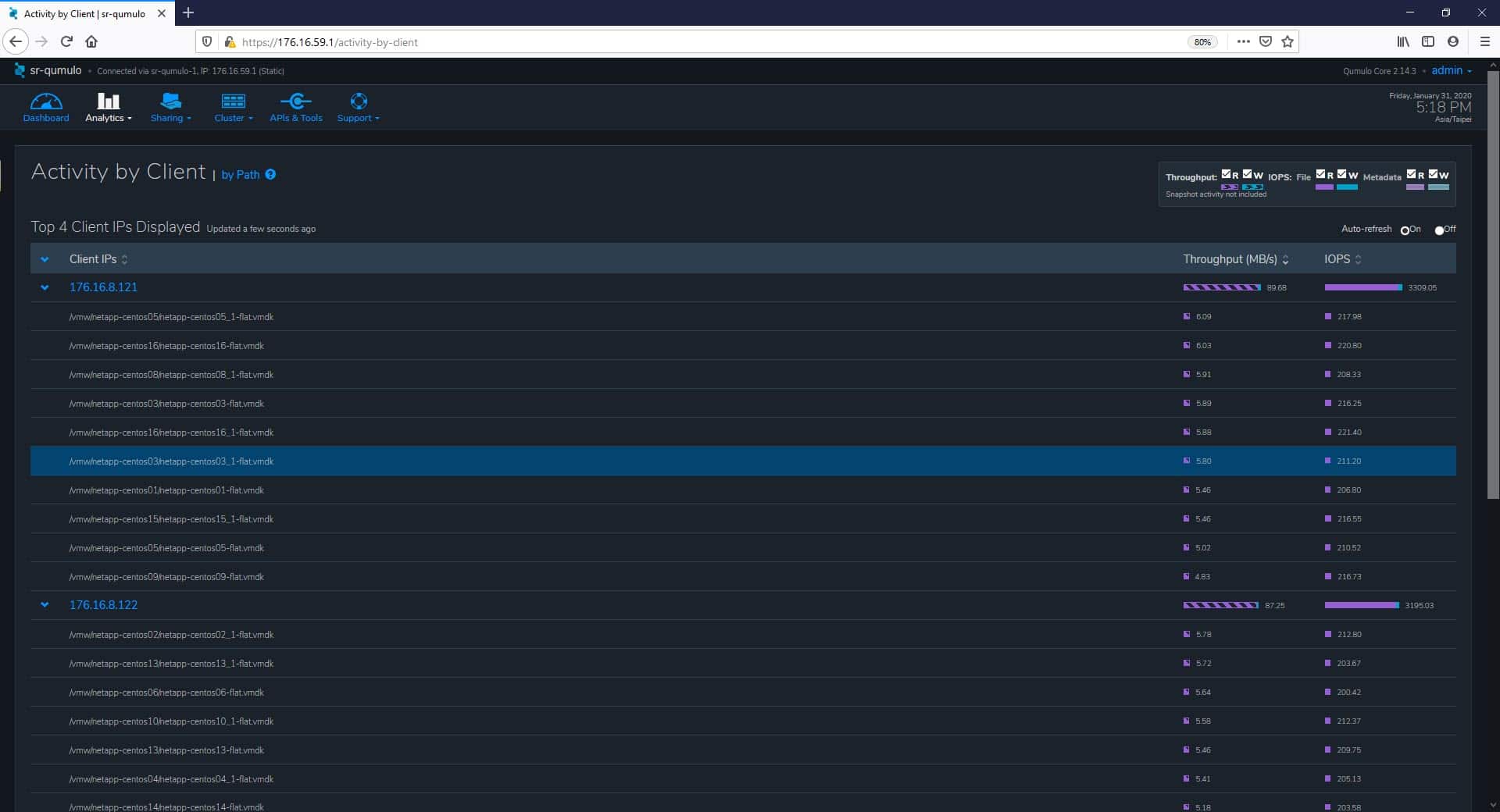
We can also monitor activity by Client. The analytics lets us see which clients are most active in terms of throughput and IOPS.
And also, we cloud monitor activity by Path.
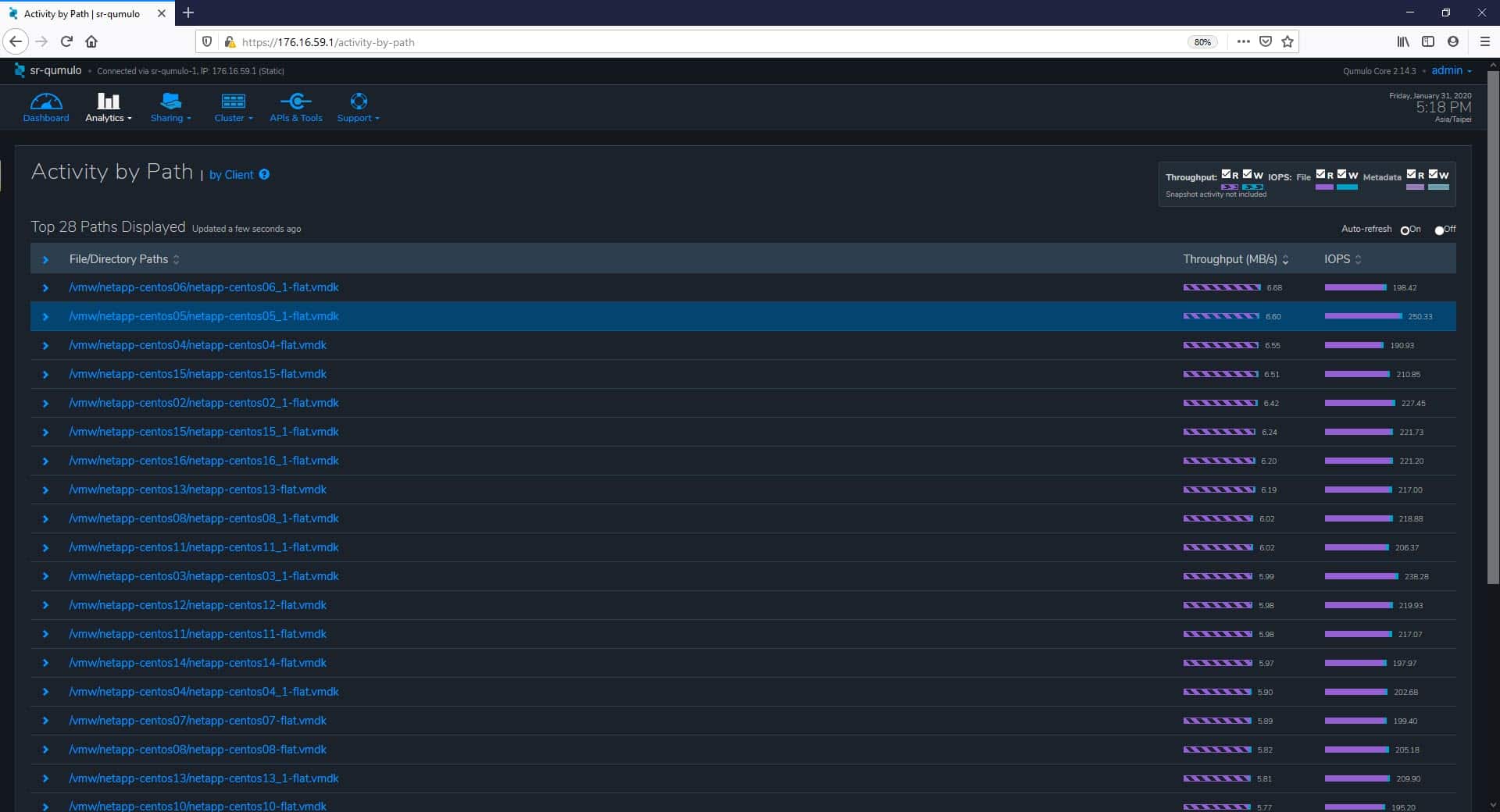
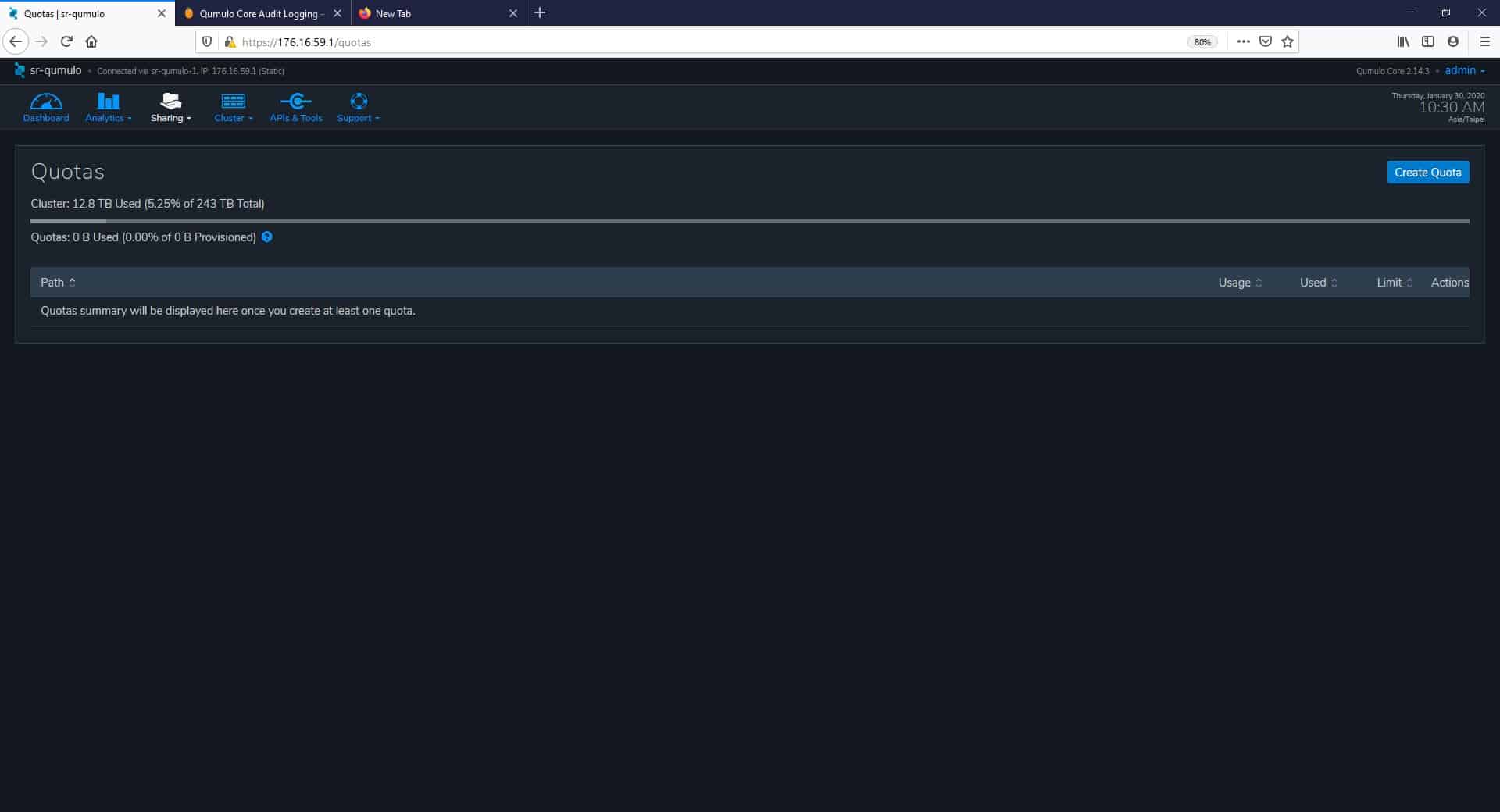
The next tab in the main menu is Sharing, and here, the first page we analyze is Quotas. Qumulo enables real-time capacity quotas, letting admins specify how much capacity a given directory is allowed to use for files. From this page, we can create, edit, or delete Quotas.
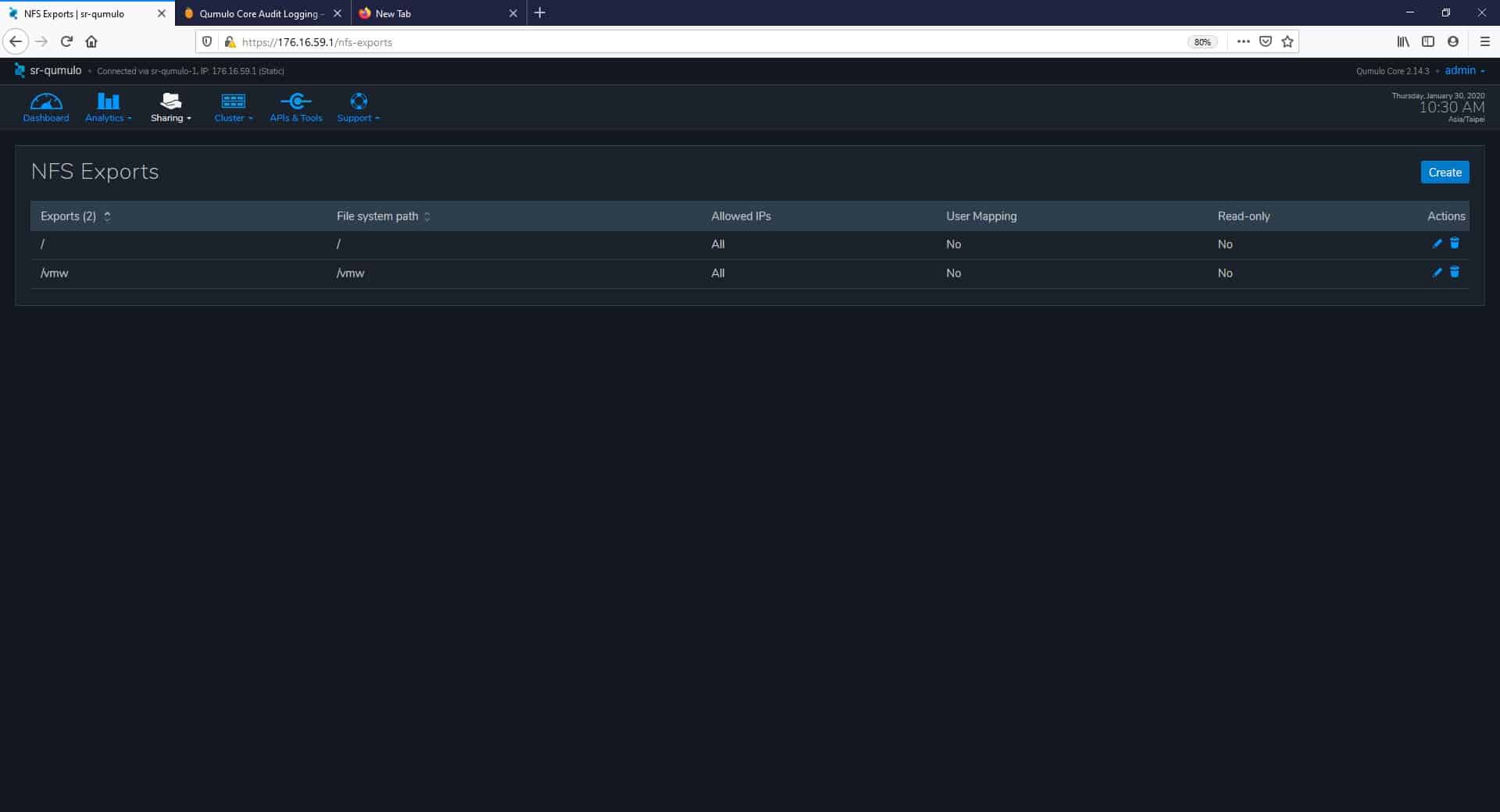
The next two pages are NFS Exports and SMB Shares that allow clients to share data stored in a particular directory. Under NFS Exports, for instance, we can create new exports, as well as edit and delete them.
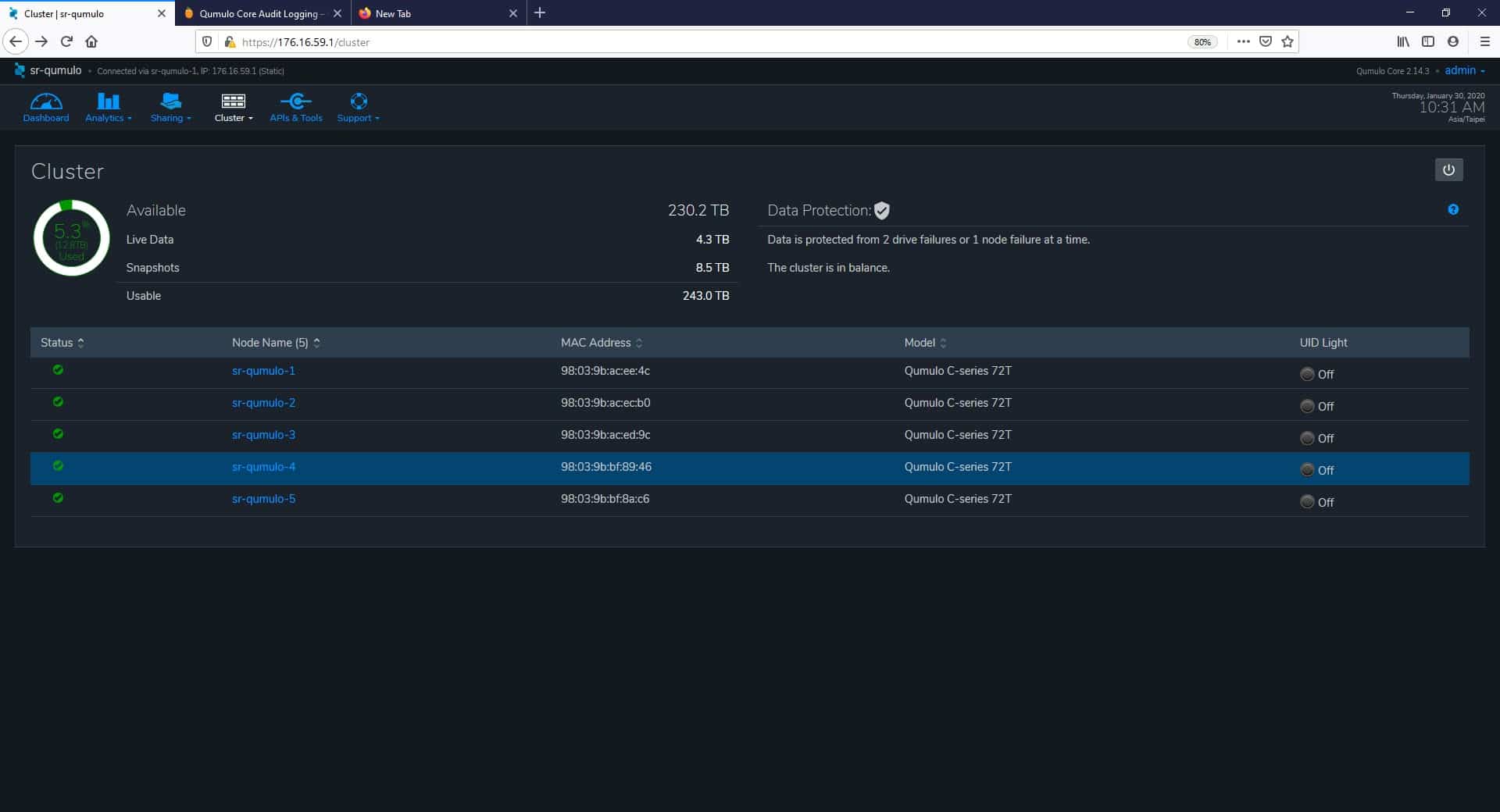
Next up in the main menu is Cluster. Under the Cluster menu, we find various configurations and options related to the cluster and the system in general. On the first page, Overview, we have vital capacity information on our cluster and its nodes.
By clicking on one of the nodes, we can drill down into more specific hardware details. As an example, we click on the “sr-qumulo-1” node to discover relevant network information and drives health status.
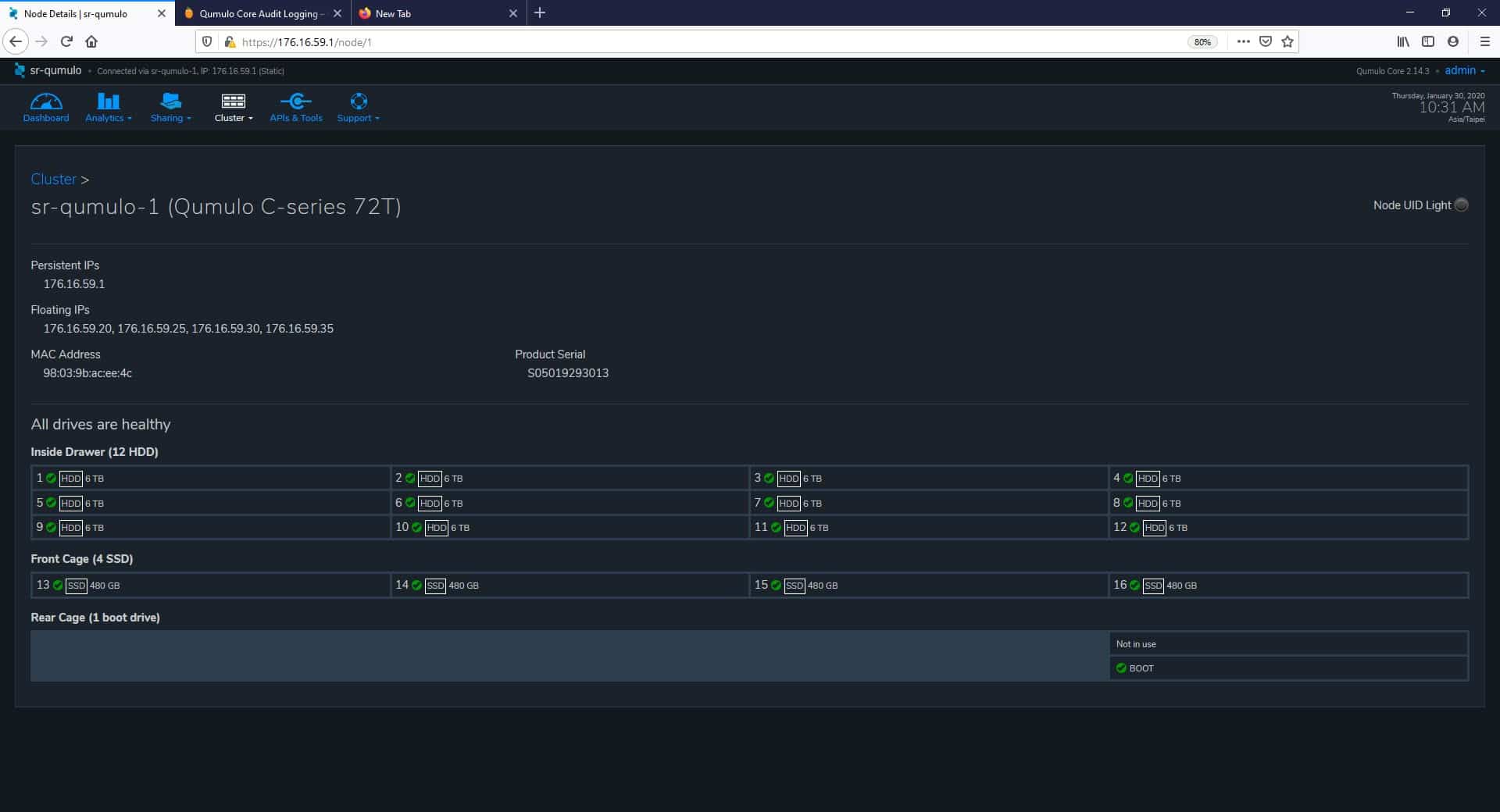
Under the Cluster menu, we also find critical storage features such as Snapshots and Replication. And more options, including network configuration, renaming the cluster, add a new host to the cluster, and more. Also, setting up the FTP and SMB protocols. Finally, on this menu, we can manage authentication and authorization. The image below shows the Local Users & Groups page as an example.
From the APIs & Tools tab, we can access the Qumulo Core page directly in the UI. Here, we could download python client library wrappers and CLI for the Qumulo Core REST API.
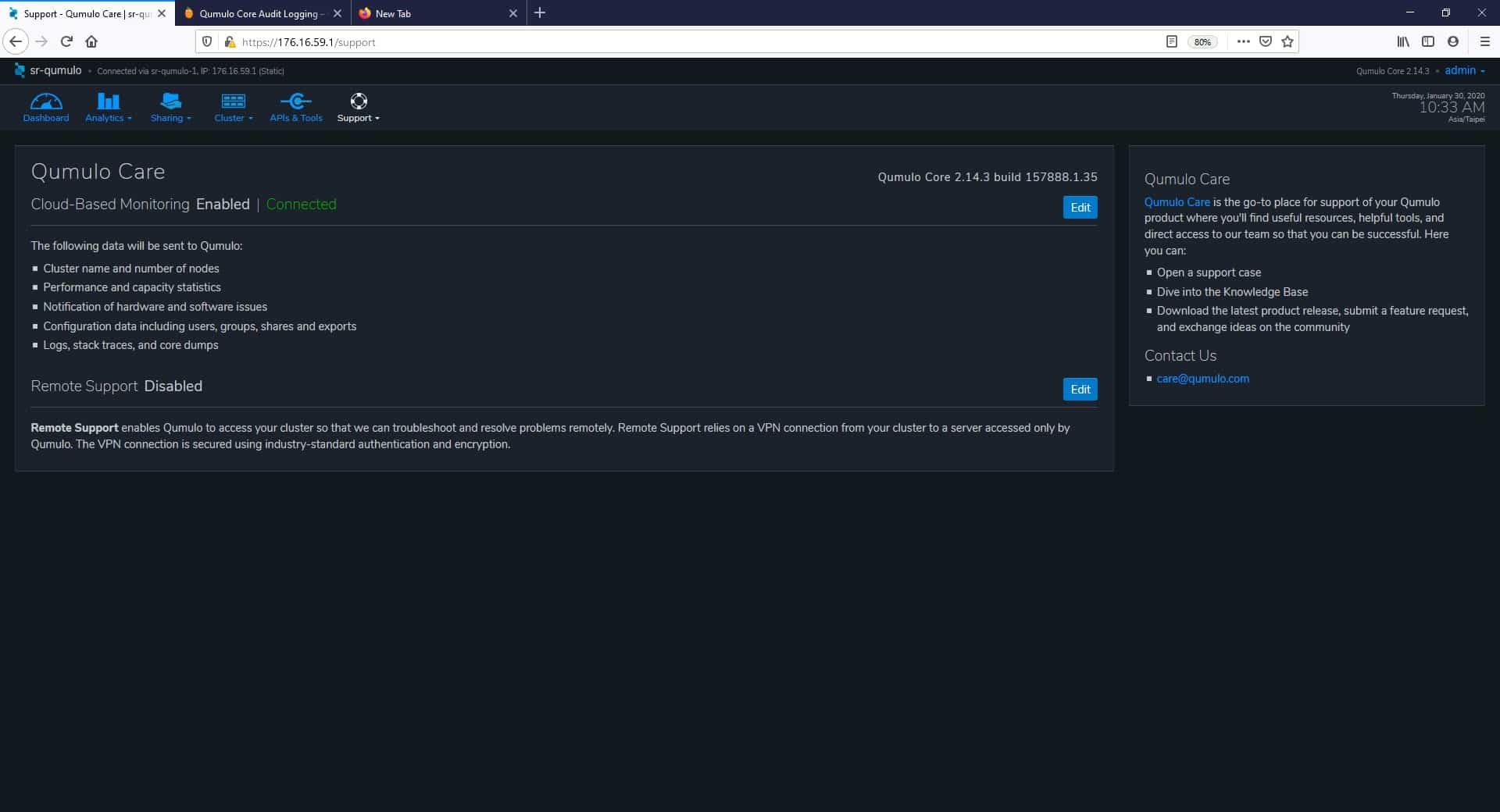
The last tab in the menu is Support, and the first page we found here is Qumulo Care, a cloud-based monitoring service that we can enable to send data to Qumulo. In this way, the Qumulo team could troubleshoot better and speed up any cluster related issue.
Finally, on the menu, we have the Software Upgrade page.
Conclusion
To innovate, organizations depend on unstructured data platforms and data-aware storage, that are poorly served by available solutions. In this review, we studied Qumulo File System, developed to offer unstructured data across all environments. Qumulo is among the pioneers of data-aware storage and cloud file data services, with its unique software-defined solution for the hybrid cloud.
In the last section of this article, we took a look at Qumulo’s Web-UI. In the past, we’ve been overviewing graphical user interfaces (GUI) of some of the most popular server and storage appliances, and this time, we were thrilled to overview Qumulo’s fresh GUI. At first glance, we become aware of this GUI’s elegant design, the excellent user experience, and how straightforward it is with admin’s day-to-day managing operations.
Overall, Qumulo’s software provides its customers with an exceptional set of capabilities, monitoring, and planning tools. The software simplifies the journey to the cloud. It supports data movement with lift-and-shift cloud migration while providing powerful real-time analytics to detect and get immediate insight into what is happening with our valuable data.


 Amazon
Amazon