

AI Infra Summit highlights MLPerf Inference results from AMD and NVIDIA, as well as NVIDIA’s 2026 Vera Rubin roadmap, specifically Rubin CPX.
At the AI Infra Summit 2025, NVIDIA showcased momentum on two fronts: impressive new MLPerf Inference results from its Blackwell Ultra systems and, more significantly, a detailed roadmap for the 2026 Vera Rubin generation, including Rubin CPX, a new class of GPU purpose-built for massive-context inference.
Blackwell Ultra Sets New Performance Baselines
NVIDIA’s GB300 NVL72 rack-scale systems have already achieved remarkable performance in MLPerf Inference v5.1, showcasing the architectural maturity of the Blackwell Ultra platform even as software continues to unlock its full potential. This power is clearly exhibited on the Llama 2 70B benchmark, where the platform delivered an impressive 12,934 tokens per second per GPU in offline scenarios. The performance in the online serving test was nearly identical at 12,701 tokens per second, speaking towards the architecture’s exceptional efficiency across different workloads.
The platform’s readiness for real-world applications was further demonstrated in the newly introduced interactive category, which imposes substantially stricter latency constraints, including sub-500ms time-to-first-token requirements and a 33 tokens-per-second-per-user threshold. Even under these aggressive quality-of-service demands, Blackwell Ultra maintained high throughput, delivering 7,856 tokens per second per GPU. On the DeepSeek-R1 reasoning benchmark, the platform established another definitive baseline at 5,842 tokens per second per GPU.
Ultimately, these results indicate that the hardware’s capabilities surpass those of the current software stack. There is significant performance headroom yet to be unlocked as frameworks like TensorRT-LLM and NVIDIA Dynamo evolve to fully exploit Blackwell Ultra’s architectural advantages, such as its enhanced NVFP4 compute paths and the massive 288GB HBM3e capacity per GPU.
Accelerating Innovation Cadence: The Vera Rubin Platform
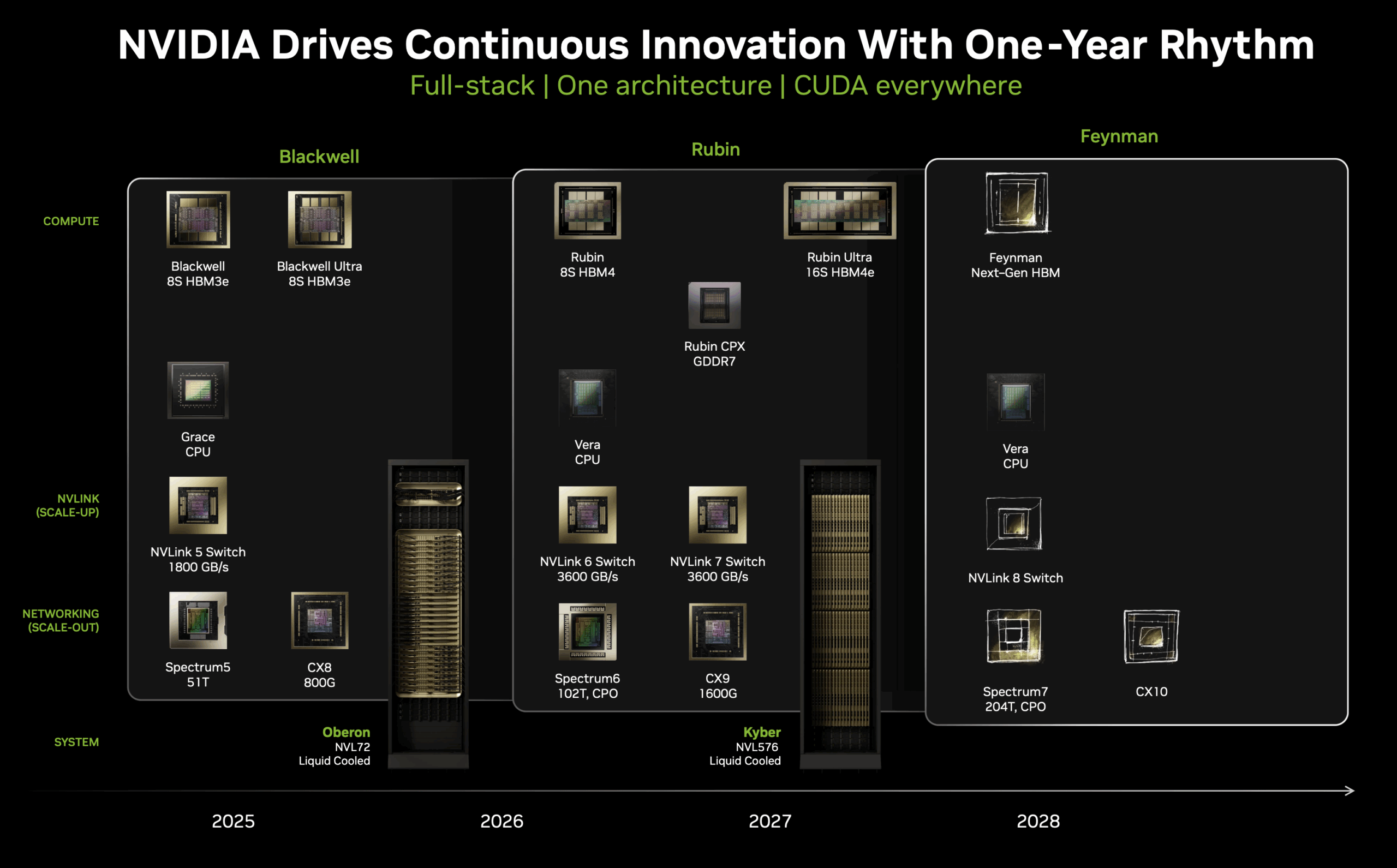
NVIDIA has adopted an annual architecture refresh cycle as a strategic response to the exponential growth in AI computational demands. Adhering to this aggressive timeline, NVIDIA revealed that the Vera Rubin generation is already taped out and slated for enterprise deployment in the second half of 2026.
The Vera Rubin architecture introduces a comprehensive platform refresh centered on the integration of new Vera CPUs and Rubin GPUs. The Vera CPU represents a significant evolution from the Grace “>last three generations of NVIDIA systems. The Vera CPUs feature 88 ARM cores supporting 176 threads. These processors also double the chip-to-chip (C2C) link bandwidth to 1,800 GB/s, enabling a faster link between the CPU, GPU, and their shared memory resources.

At the interconnect layer, the sixth-generation NVLink delivers 3,600 GB/s of bidirectional bandwidth, doubling the bandwidth of the current 5th-generation NVLink switches. This enhanced connectivity becomes particularly critical as models continue to scale beyond the memory capacity of individual devices, requiring sophisticated parallel execution strategies that demand minimal communication latency and maximum throughput between nodes.
Complementing the NVLink advancement, the Spectrum-6 switch, incorporating co-packaged optics (CPO) technology, achieves 102 TB/s of switching capacity. The integration of optical components directly into the switch package eliminates traditional electrical-to-optical conversion bottlenecks, reducing latency while dramatically improving power efficiency—critical considerations as AI factories scale toward gigawatt power consumption levels.

The VR NVL144 systems will still utilize the proven Oberon rack platform that currently underpins Grace Hopper, Grace Blackwell, and Grace Blackwell Ultra deployments.
Architectural Nomenclature Evolution: From Packages to Dies
NVIDIA is shifting its naming convention from a package-based to a die-based count. While this change might be controversial, it is a forward-looking move that will provide greater clarity, especially with the anticipated launch of Rubin Ultra GPUs in late 2026, which are expected to feature four reticle-sized dies.

With the Rubin generation, NVIDIA is adopting a die-count nomenclature that directly reflects the available computational resources. The NVL144 designation explicitly references 144 GPU dies while maintaining the 72-package physical configuration and provides a more precise measure of computational capacity. This is similar to the current generation GB200 and GB300 NVL72 systems, which contain 72 GPU packages, each housing two GPU dies, for a total of 144 computational dies.
Addressing the Context Processing Challenge
The announcement of Rubin CPX, planned for availability in late 2026, is NVIDIA’s architectural response to one of the most pressing challenges in LLM inference: the fundamental mismatch between computational patterns during different phases of token generation. To understand this innovation, we need to look into the distinctive characteristics of LLM inference workloads and the limitations of current homogeneous GPU architectures in addressing these varied computational demands.
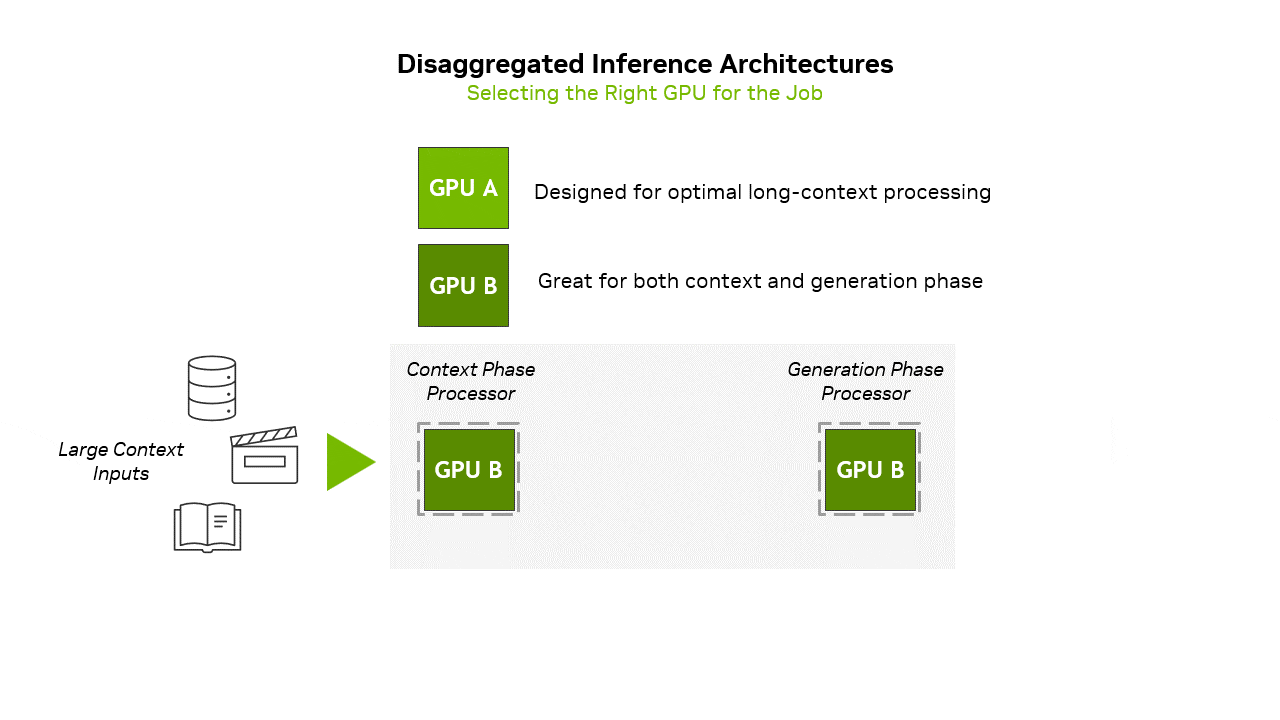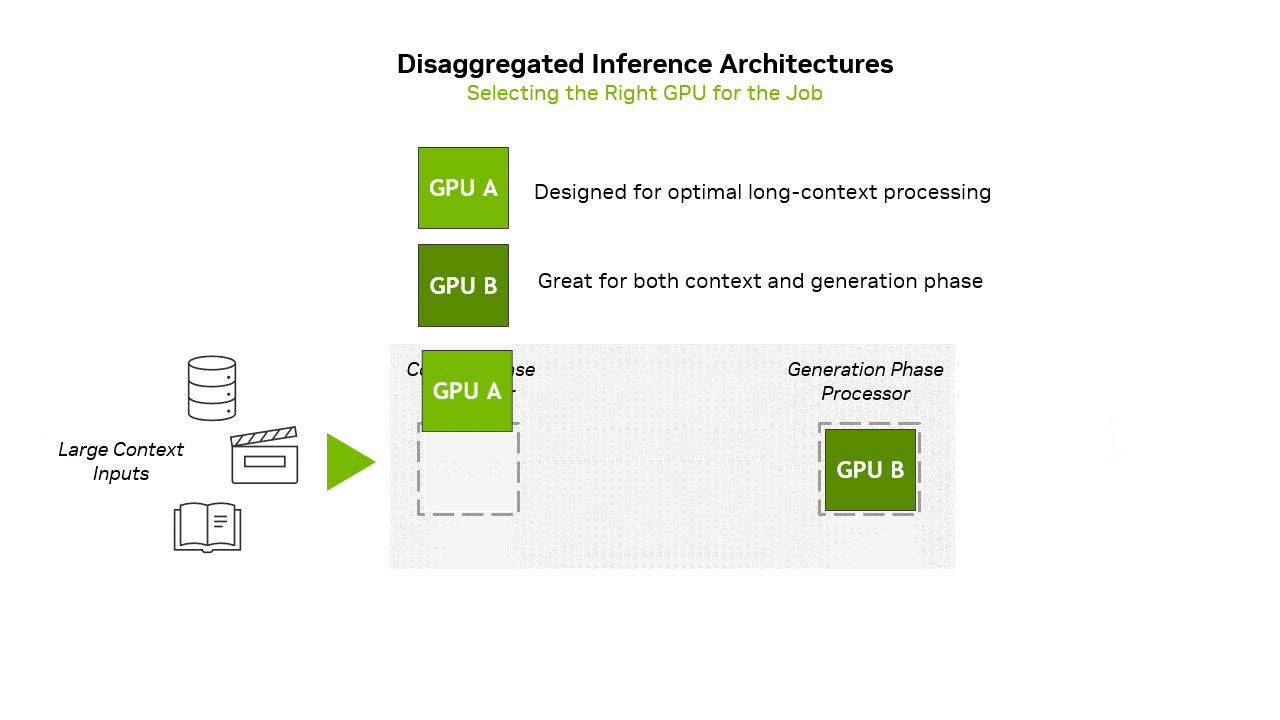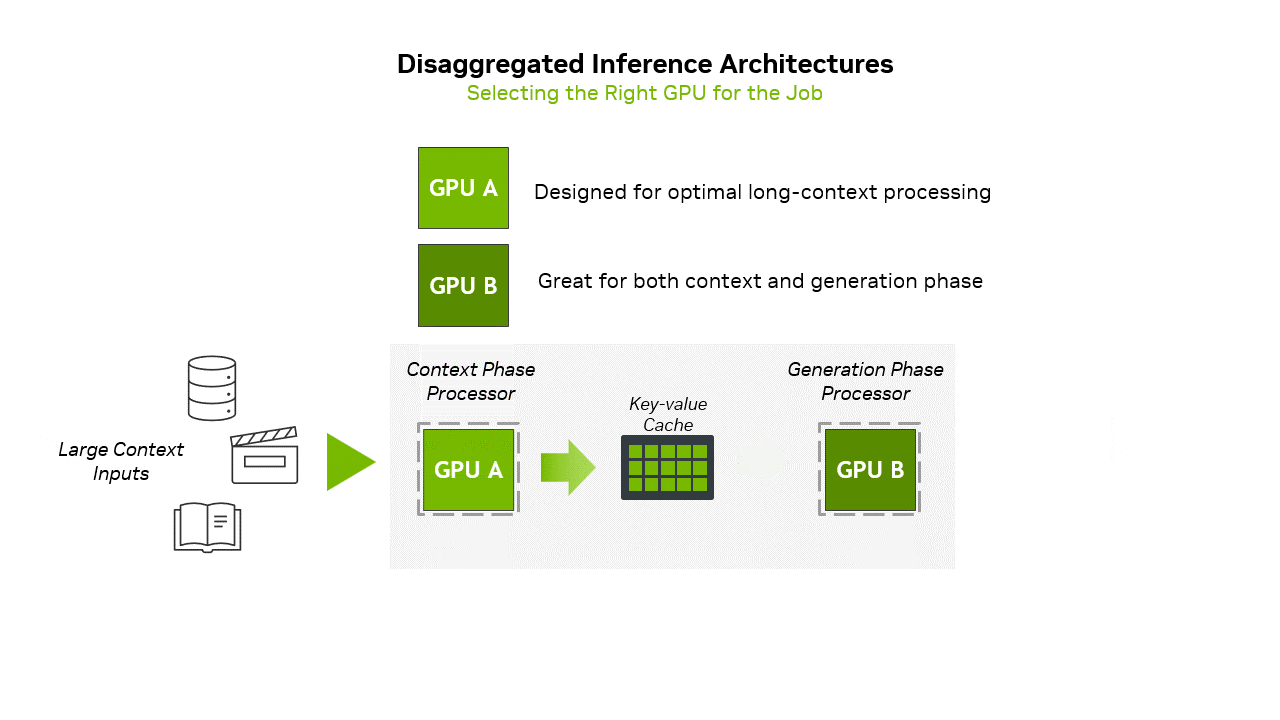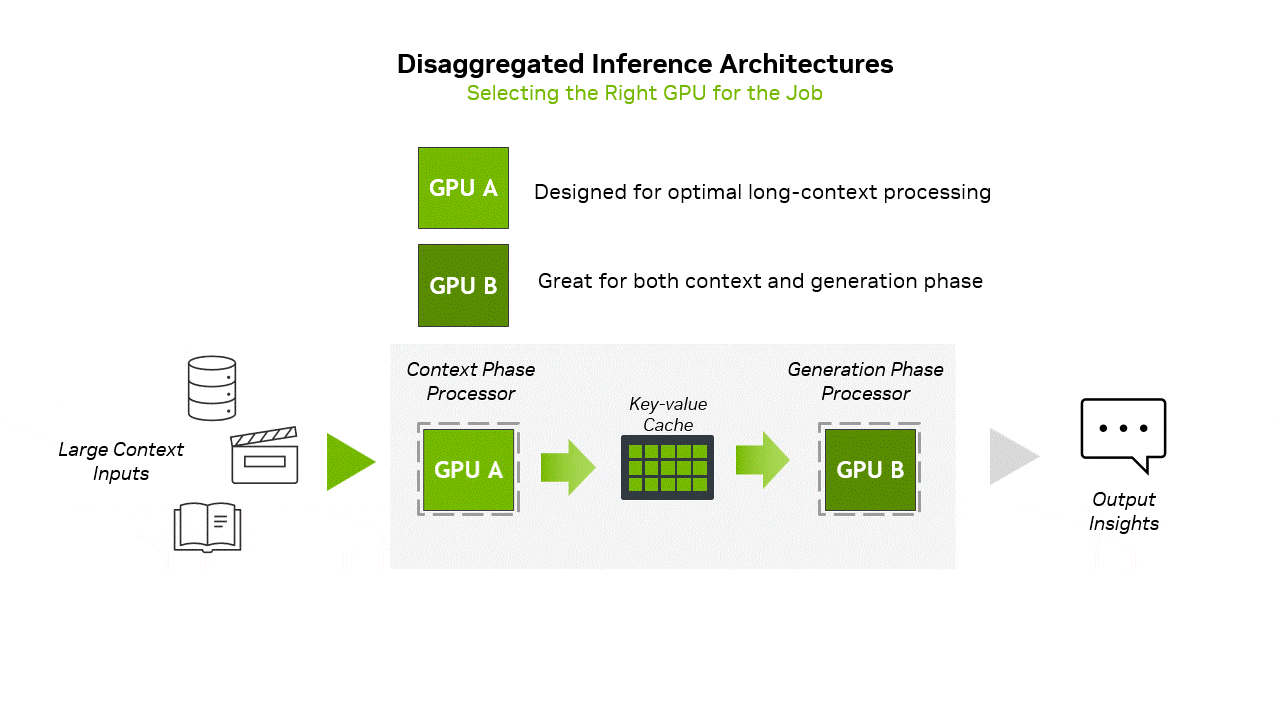
Large language model inference operates through two fundamentally different computational phases that place dramatically different demands on hardware resources. The prefill stage processes the initial input prompt, computing the Key and Value matrices for subsequent generation. This phase is compute-intensive and efficiently utilizes the massive floating-point throughput of modern GPUs.
The decode stage presents an entirely different computational challenge. During decode, the model generates output tokens auto-regressively, producing one token at a time by attending to the previous context. Each new token requires the attention mechanism to process the entire sequence history, computing its relationship to all previous tokens. This creates a unique computational pattern where memory bandwidth, rather than compute throughput, becomes the primary bottleneck. The KV cache, which stores the intermediate representations needed to maintain context, becomes the dominant consumer of memory.
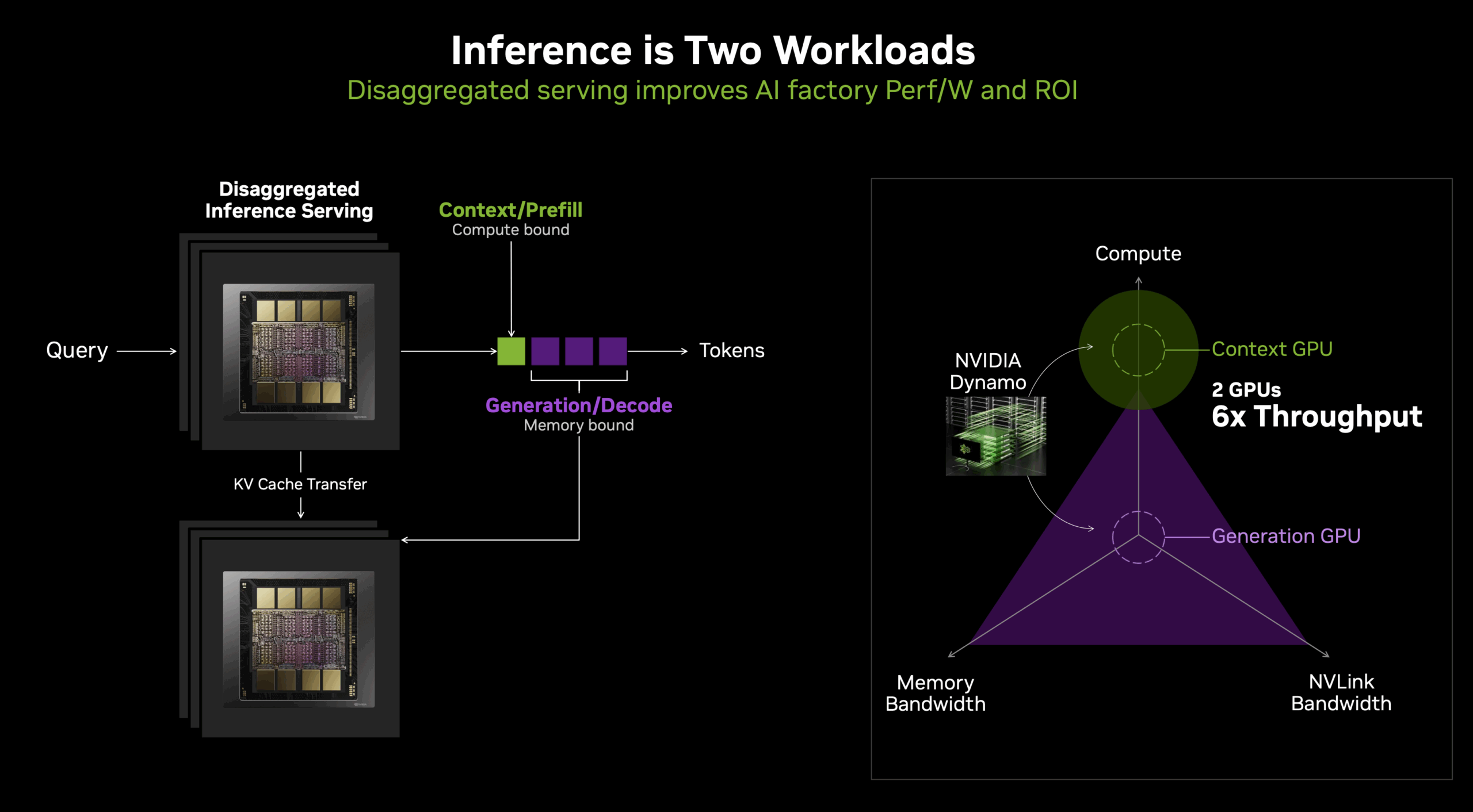
The scaling characteristics of the KV cache present particular challenges in production environments. For a model like Llama 3.1 405B processing extended contexts, the KV cache can easily consume tens of gigabytes per sequence. In batch inference scenarios, which are essential for achieving high throughput in production, the aggregate KV cache size frequently exceeds that of the model weights themselves. With the large batch sizes possible in large-scale NVL72 deployments, the KV cache can reach multiple terabytes in size. While this data must remain accessible with reasonable latency, not all KV cache accesses require the extreme bandwidth of HBM memory. Many attention operations exhibit access patterns amenable to hierarchical memory architectures.
Rubin CPX: Purpose-Built Architecture for Context Processing
Rubin CPX addresses these architectural mismatches through a purpose-built design for long-context LLM inference. The architecture centers on 128GB of GDDR7 memory, providing a large and cost-effective memory pool for KV cache operations. GDDR7’s bandwidth characteristics, although lower than those of HBM4, are sufficient for the majority of attention operations, particularly when combined with intelligent caching strategies.

Integration with the broader Vera Rubin platform in the VR NVL144 CPX rack occurs via PCIe links through the ConnectX-9 NICs and switch chips, facilitating hybrid execution models where compute-intensive operations occur on traditional GPUs. Memory-intensive context management migrates to CPX processors.
Flexible Deployment Architectures and Configuration Options

The Vera Rubin platform’s modular architecture enables deployment flexibility, enabling organizations to optimize configurations for specific workload characteristics. The standard VR NVL144 rack configuration features Vera Rubin GPUs with eight ConnectX-9 NICs, providing a balanced architecture suitable for diverse AI workloads. This configuration delivers 3.6 ExaFLOPS of NVFP4 compute, a 3.3x improvement over the current GB300 NVL72 systems, alongside 1.4 PB/s of HBM4 bandwidth (2.5x the current generation) and 75 TB of HBM4 memory capacity (2x the current generation).
For organizations optimizing for inference and long-context RL post-training, the ultra-dense VR NVL144 CPX compute tray is available. Each tray incorporates four VR GPU packages, each containing eight GPU dies, thereby maintaining the computational density of the standard configuration, while also adding eight Rubin CPX GPUs. The eight ConnectX-9 NIC/switch chips ensure the seamless data flow essential for distributed inference.

The modular nature of the architecture enables exceptionally flexible deployment strategies. Organizations can initially deploy standard VR NVL144 racks and subsequently augment them with dedicated Rubin CPX racks as their context processing requirements grow. This approach enables infrastructure to evolve in tandem with model capabilities, thereby avoiding over-provisioning.

The complete VR NVL144 CPX configuration establishes a new baseline for computational power. The system delivers 8 ExaFLOPS of NVFP4 compute, a 7.5x improvement over current-generation GB300 NVL72 systems. This massive computational capacity is combined with 1.7 PB/s of aggregate memory bandwidth, leveraging both HBM4 and GDDR7 to achieve three times the memory throughput of current systems. The total memory capacity reaches 100TB, providing 2.5x the memory resources of current-generation platforms.
NVIDIA is targeting end-of-2026 availability. This will enable new categories of AI applications and make million-token context windows practical for production, allowing AI systems to process entire codebases or lengthy documents in a single pass. These innovations also enable organizations to support larger batch sizes, lowering the cost of inference and creating a more favorable OPEX calculation.
Gigawatt-Scale Infrastructure Blueprint
Beyond individual system innovations, NVIDIA also unveiled reference architectures for gigawatt-scale AI factories. Developed in collaboration with infrastructure partners including Jacobs, Schneider Electric, Siemens Energy, and Vertiv, these blueprints address the complete infrastructure stack, from power generation to computational delivery. The reference designs acknowledge that next-generation AI deployments require holistic optimization that extends far beyond the computational components themselves.
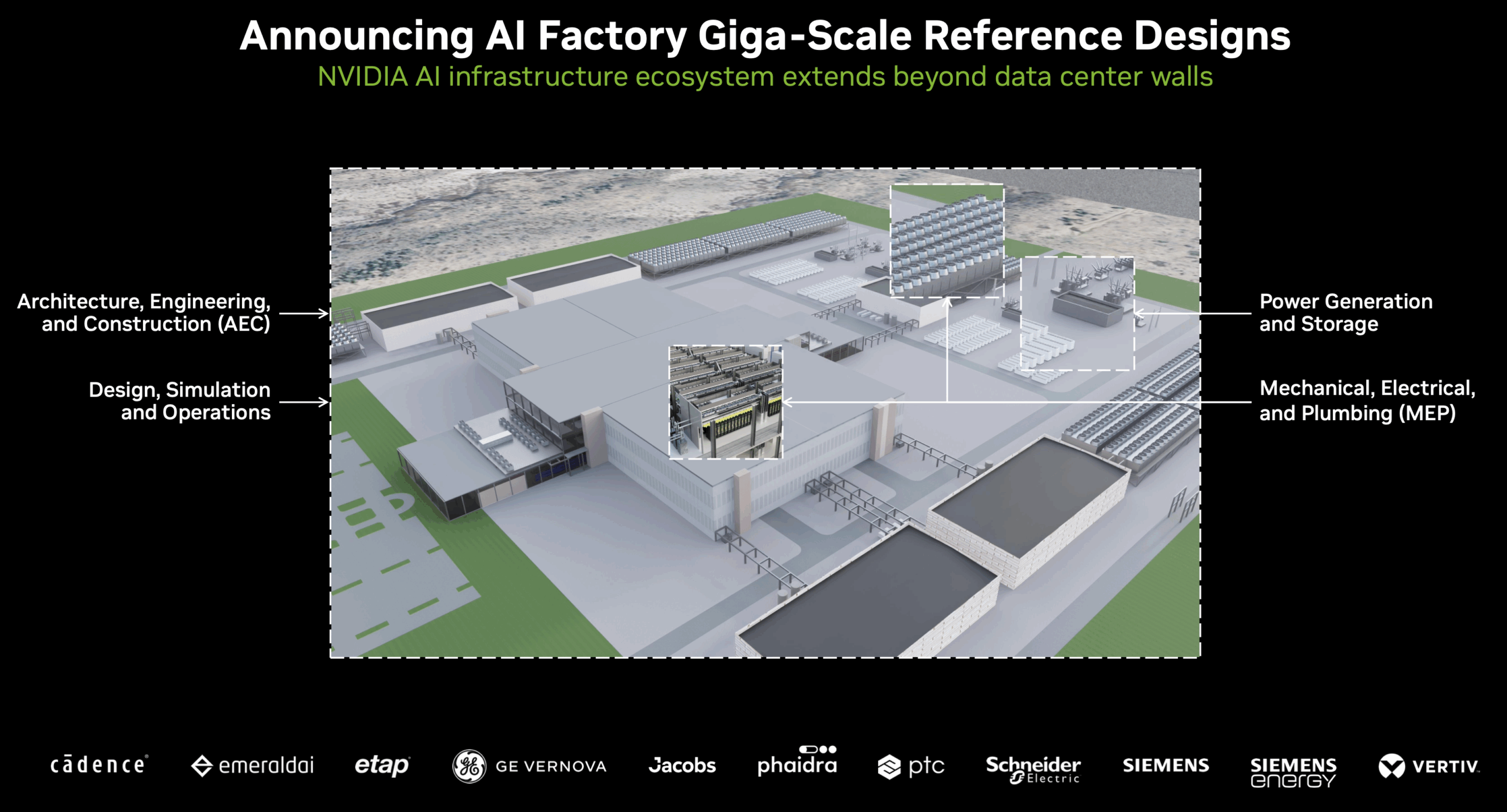
These architectural blueprints utilize NVIDIA Omniverse digital twins to facilitate comprehensive facility simulation before physical deployment. Organizations can model power distribution, cooling systems, and computational workloads in unified simulations, identifying and addressing bottlenecks before committing to physical infrastructure.
Conclusion
NVIDIA continues to lead the AI infrastructure space with a forward-thinking, developer-centric approach that directly addresses the pain points faced by organizations and AI labs. The transition from general-purpose acceleration to workload-specific architectures, exemplified by Rubin CPX’s targeted approach to context processing, indicates that future AI systems will increasingly comprise heterogeneous computational resources optimized for every phase of AI workflows. This architectural evolution demands that organizations planning multi-year AI infrastructure investments consider not just raw computational throughput but also the alignment between hardware capabilities and evolving model architectures.
The accelerated innovation cadence, from Blackwell Ultra through Vera Rubin to Rubin CPX within a compressed timeline, is truly impressive. Such a rapid pace requires organizations to design systems capable of integrating new architectural paradigms as they emerge, avoiding the lock-in that characterized previous generations of data center infrastructure. To address this challenge, NVIDIA’s AI Factory reference designs and Omniverse digital twins provide the essential blueprints and simulation tools for future-proofing these critical investments. As AI models continue their trajectory toward trillion-parameter scales and million-token contexts, the architectural innovations unveiled at the AI Infrastructure Summit provide the essential foundation for this future of computation. They establish the frameworks and technologies that will define enterprise AI capabilities throughout the decade.
Articles Referenced: Nvidia GTC25 News
All Slides and Images are sourced from Nvidia
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed