
NVIDIA continues to dominate in raw throughput in MLPerf Inference v5.1, but AMD is making steady advances with the MI300, closing the gap in efficiency.
MLPerf Inference v5.1 offers rigorous benchmarks for AI inference across LLMs, vision, and multimodal tasks. Here is the technical analysis on NVIDIA’s Blackwell Ultra results and AMD’s Instinct MI300X/MI325X/MI355X submissions. It includes detailed benchmark data, software optimizations, architectural strategies, and implications for hyperscalers and enterprises.
MLPerf Benchmarking Framework
MLPerf Inference benchmarks serve as the scoreboard for AI accelerators, providing a standardized, apples-to-apples method for measuring performance across image classification, language models, and recommendation systems. For enterprises deploying GPUs at scale, these numbers often guide massive purchasing decisions.
MLPerf Inference is governed by MLCommons and defines Closed vs Open Division rules. Scenarios include:
- Offline: Throughput-centric (batch as many queries as possible).
- Server: Latency-compliant multi-stream inference.
- Interactive: Strict TTFT (Time-to-First-Token) and TPS (tokens per second @ 99th percentile).
The v5.1 workload suite included:
- DeepSeek-R1: A 671B mixture-of-experts model (stress test for reasoning inference).
- Llama-3.1-405B and 8B: Newest LLMs across multiple inference modes.
- Whisper: ASR replacing RNN-T.
- Stable Diffusion XL (SD-XL): Text-to-image generative AI.
- Mixtral, DLRMv2, plus legacy workloads like ResNet-50.
When charts of throughput (tokens/sec or samples/sec) are shown, they typically highlight NVIDIA’s continued dominance in absolute numbers, especially per-GPU. However, AMD’s progress in relative efficiency and scaling smoothness shows they are closing the gap round over round, particularly in server scenarios and multi-node deployments.
NVIDIA Blackwell Ultra Results
Blackwell Ultra systems achieved record throughput across all new workloads. Key enablers:
- NVFP4 precision: custom 4-bit float, accelerating DeepSeek and Llama.
- FP8 KV-cache: memory savings for attention layers.
- Disaggregated serving: split context vs generation stages across 72 GPUs via 1,800 GB/s NVLink.
- Software: CUDA Graphs, TensorRT-LLM, ADP Balance.
The bar chart below, contrasting Hopper vs Blackwell Ultra per-GPU, shows nearly 5× throughput uplift on DeepSeek-R1, validating that fine-grained data formats (NVFP4) and rack-wide bandwidth scale linearly for massive inference workloads. Another figure framed around interactive Llama-405B record-setting results demonstrates how NVIDIA uses NVLink fabric and disaggregated serving to keep latency SLAs while breaking past previous throughput limits. The takeaway: NVIDIA remains the industry pace-setter for sheer raw speed and latency-sensitive workloads.
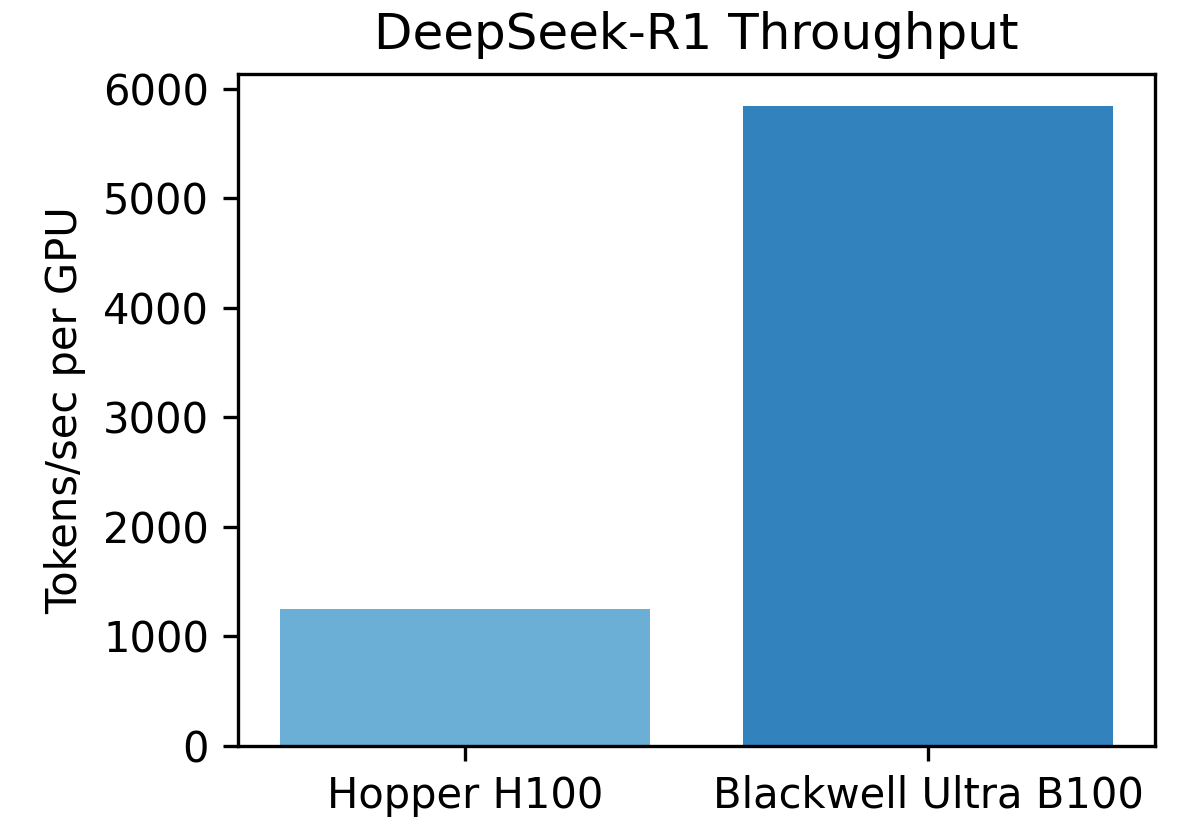
AMD Instinct MI300X/MI325X/MI355X Results
AMD targeted efficiency and flexibility:
- FP4 on MI355X: delivering 2.7× more Llama-2-70B throughput vs MI325X FP8.
- Structured pruning: On Llama-405B, pruning 21–33% reduced FLOPs without impacting accuracy, boosting throughput by ~82–90%.
- Scaling: Smooth linear scaling proven up to 8 nodes; first heterogeneous cluster (4 × MI300X + 2 × MI325X) achieved 94% scaling efficiency.
- ROCm ecosystem reproducibility: Partner submissions consistently within 1–3% of AMD’s own results.
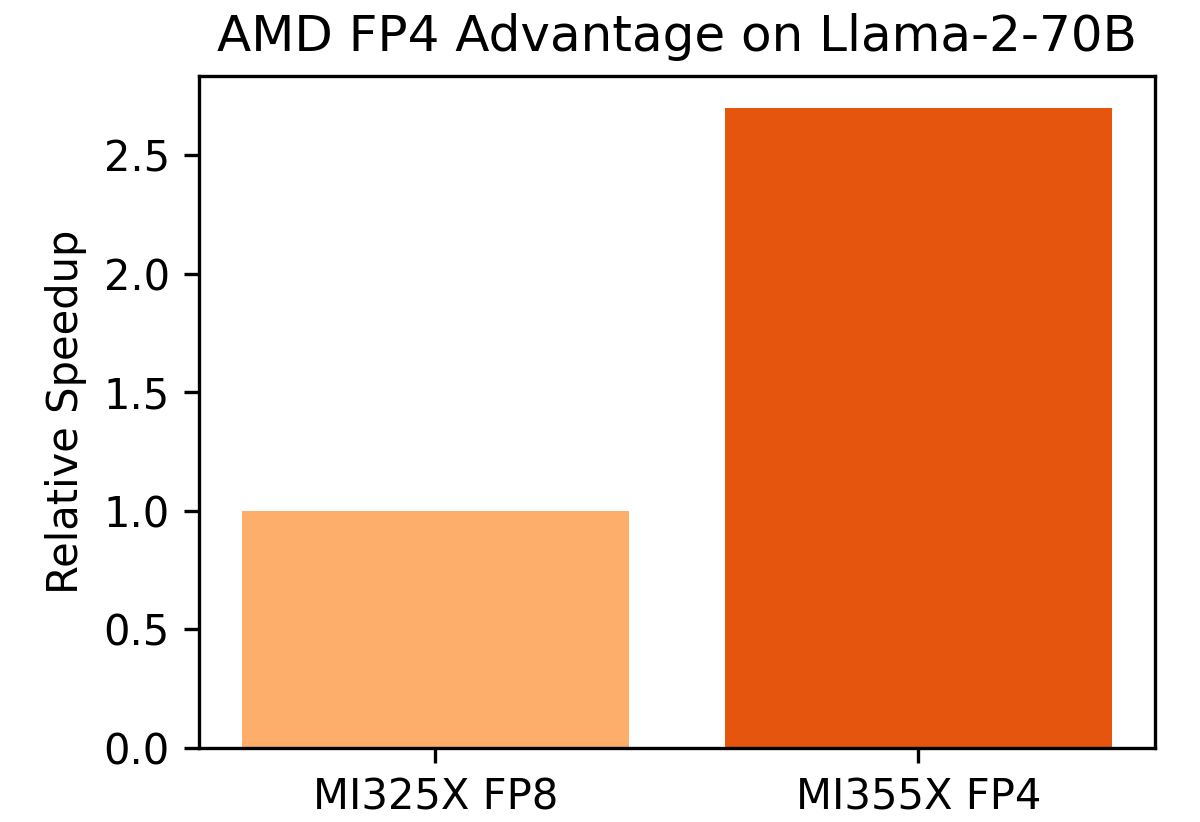
The above chart showing MI325X FP8 vs. MI355X FP4 illustrates breakthrough FP4 benefits, higher tokens/sec with minimal accuracy loss, proving FP4 isn’t experimental but deployment-ready.
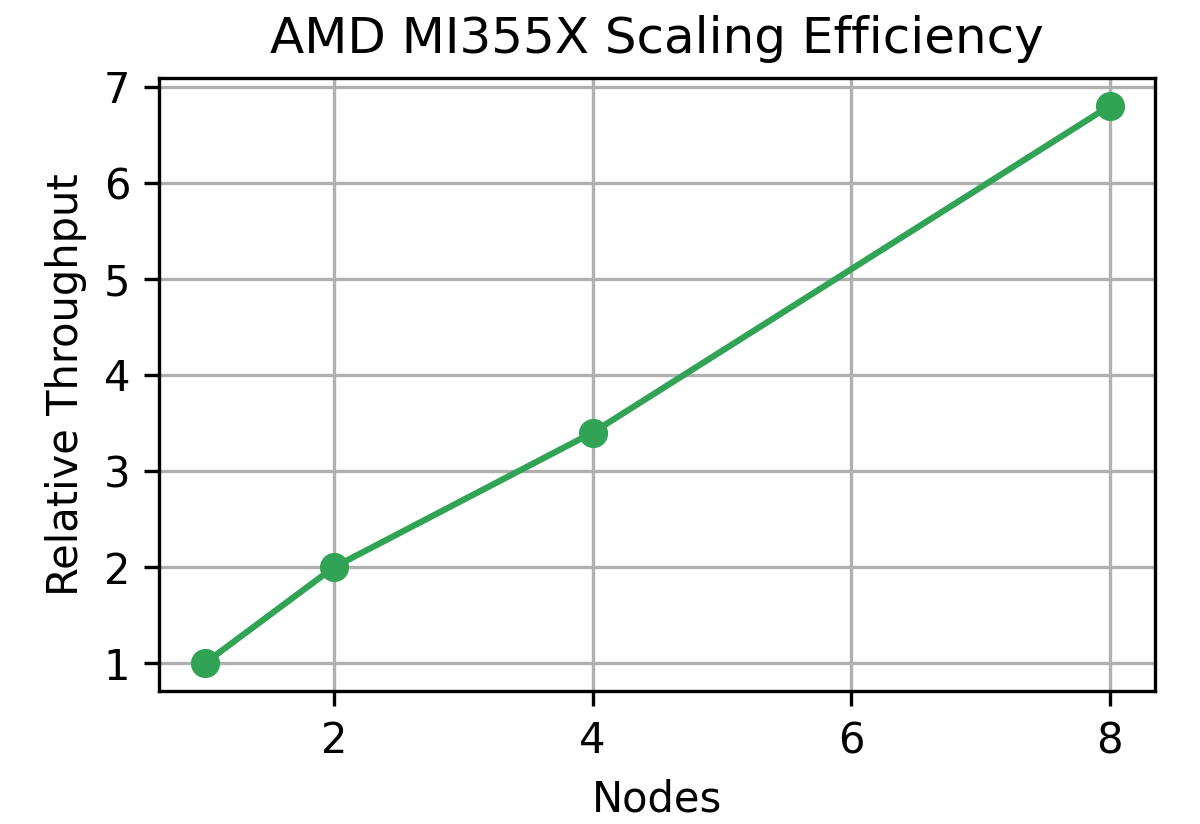
This scaling curve (1 → 8 nodes) chart highlights near-linear scaling, something hyperscalers value since it translates to predictable expansion costs. Meanwhile, the schematic of structured pruning shows AMD’s focus isn’t only on hardware brute force but also on algorithmic efficiency, crucial for real-world inference clusters constrained by power and space.
AMD-NVIDIA Head-to-Head Comparison
|
Metric |
NVIDIA Blackwell Ultra |
AMD MI355X |
Notes |
Winner |
|
Tokens/sec per GPU |
5842 (DeepSeek-R1) |
~2200 (scaled FP4) |
Higher NVIDIA raw perf |
NVIDIA |
|
Memory per GPU |
192GB HBM3e |
288GB HBM3e |
AMD fits 520B model single GPU |
AMD |
|
Precision support |
FP16, FP8, NVFP4 |
FP16, FP8, FP4 |
Both 4-bit lead |
Tie |
|
Scaling Fabric |
72 GPU NVLink |
Linear node scaling to 8 |
Different scale strategies |
Tie |
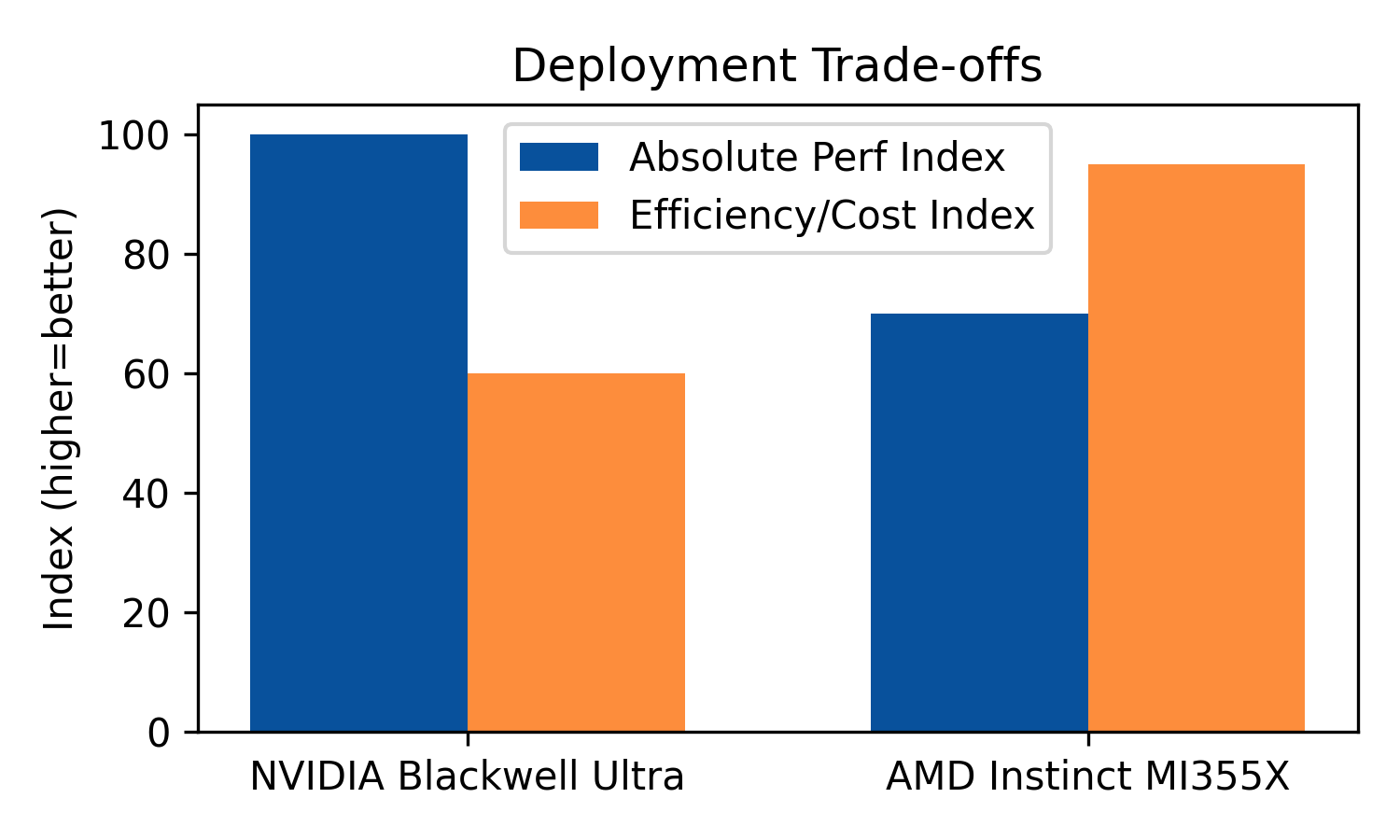
Side-by-side visualizations emphasize the trade-offs.
- NVIDIA dominates per-GPU throughput, making it ideal for AI factories where flop density matters.
- AMD, with larger memory (288GB) and FP4 pruning, shines where cost-per-token and deployment flexibility are paramount.
Industry Implications
- Hyperscalers: NVIDIA remains the tool of choice for AI factories chasing peak performance. AMD’s growing efficiency innovations, however, unlock cost-optimized scaling, appealing for balancing workloads across tiers.
- Cloud Providers: Expect heterogeneous offerings, high-performance NVIDIA tiers vs. cost-efficient AMD Kubernetes pods.
- Enterprises: Structured pruning, FP4, and heterogeneous cluster support allow AMD to deliver 405B+ model inference at lower TCO. NVIDIA innovations (disaggregated serving and Dynamo) remain beneficial for latency-sensitive apps (e.g., real-time LLM chatbots).
- Future Outlook: Expect universal adoption of 4-bit inference as a baseline, broader use of heterogeneous GPU pools, and new system designs including NVIDIA’s Rubin CPX for long sequences and AMD’s ROCm expansion to cover more frameworks.
NVIDIA continues to set the pace in raw throughput, with H200 GPUs leading inference in ResNet-50 and BERT across closed division benchmarks. That said, AMD’s MI300 doesn’t trail far behind, posting competitive numbers in server and offline scenarios while also showing strong gains in power efficiency. The real story here isn’t just that NVIDIA remains on top, but that AMD has significantly closed the gap compared to just one MLPerf round ago. For buyers, this means the days of looking only at green GPUs may be over—ROCm is maturing, and MI300 is viable in real-world inference deployments.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed