

NVIDIA has introduced Helix Parallelism, a new method developed for its Blackwell GPU architecture aimed at improving real-time AI performance with very large datasets. The technique addresses the growing need for LLMs to process multi-million-token contexts. NVIDIA demonstrates this approach can increase processing speeds by up to 32 times over conventional methods, enabling more complex and responsive AI applications.
The Million-Token Challenge: Why AI Needed a New Approach
The frontier of AI has moved beyond simple queries to complex, long-term reasoning. Advanced applications exceedingly require a vast context to be effective. AI assistant that remembers months of conversations, a legal tool that analyzes gigabytes of case law in one go, or a coding partner that understands an entire repository. These tasks require processing millions of tokens.
However, scaling to this level exposes two fundamental bottlenecks.
- The KV Cache Bottleneck: During autoregressive token generation, models calculate attention to previously generated tokens to avoid a quadratic scaling factor. To achieve this, previously generated tokens are cached, a process known as KV cache. With multi-million-token contexts, this cache becomes enormous, saturating the GPU’s memory bandwidth and dramatically slowing down response times.
- The FFN Weight Bottleneck: For every new token a model generates, it must load massive Feed-Forward Network (FFN) weights from memory. In interactive, low-latency applications, this constant loading process becomes a primary source of delay.
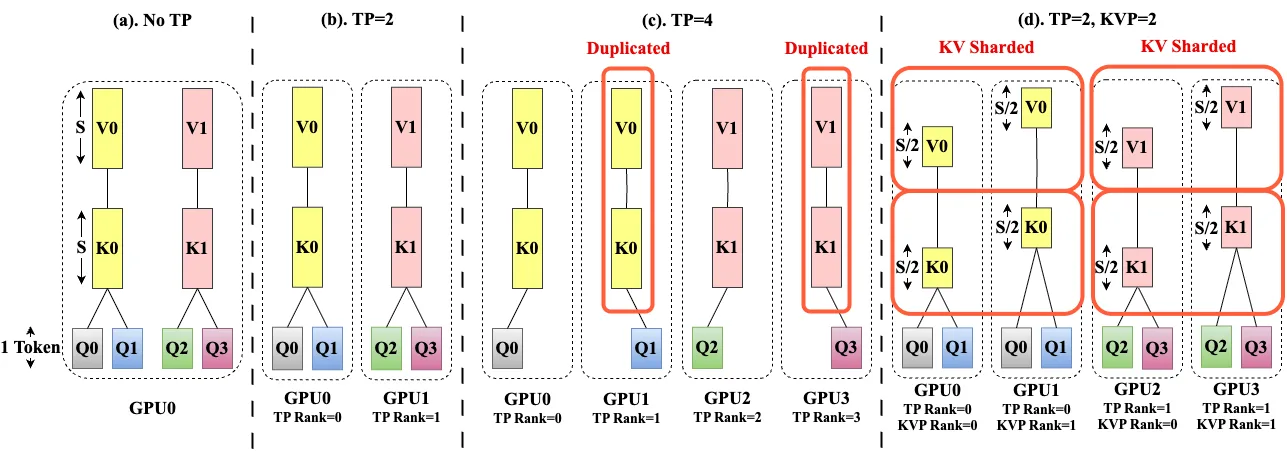
Currently, we rely on methods like Tensor Parallelism, which splits a model’s tensors and therefore memory required and computational work across multiple GPUs. While effective for some tasks, its benefits decrease with newer attention mechanisms. In attention mechanisms like GQA (Grouped Query Attention) or MLA (Multi-Latent Attention), to reduce the memory usage, multiple query heads share a smaller set of KV heads. However, when the Tensor Parallelism size exceeds the number of KV heads, it necessitates KV head duplication due to the significant latency introduced by cross-GPU communication at every step. This duplication negates some benefits of Tensor Parallelism.
Helix Parallelism
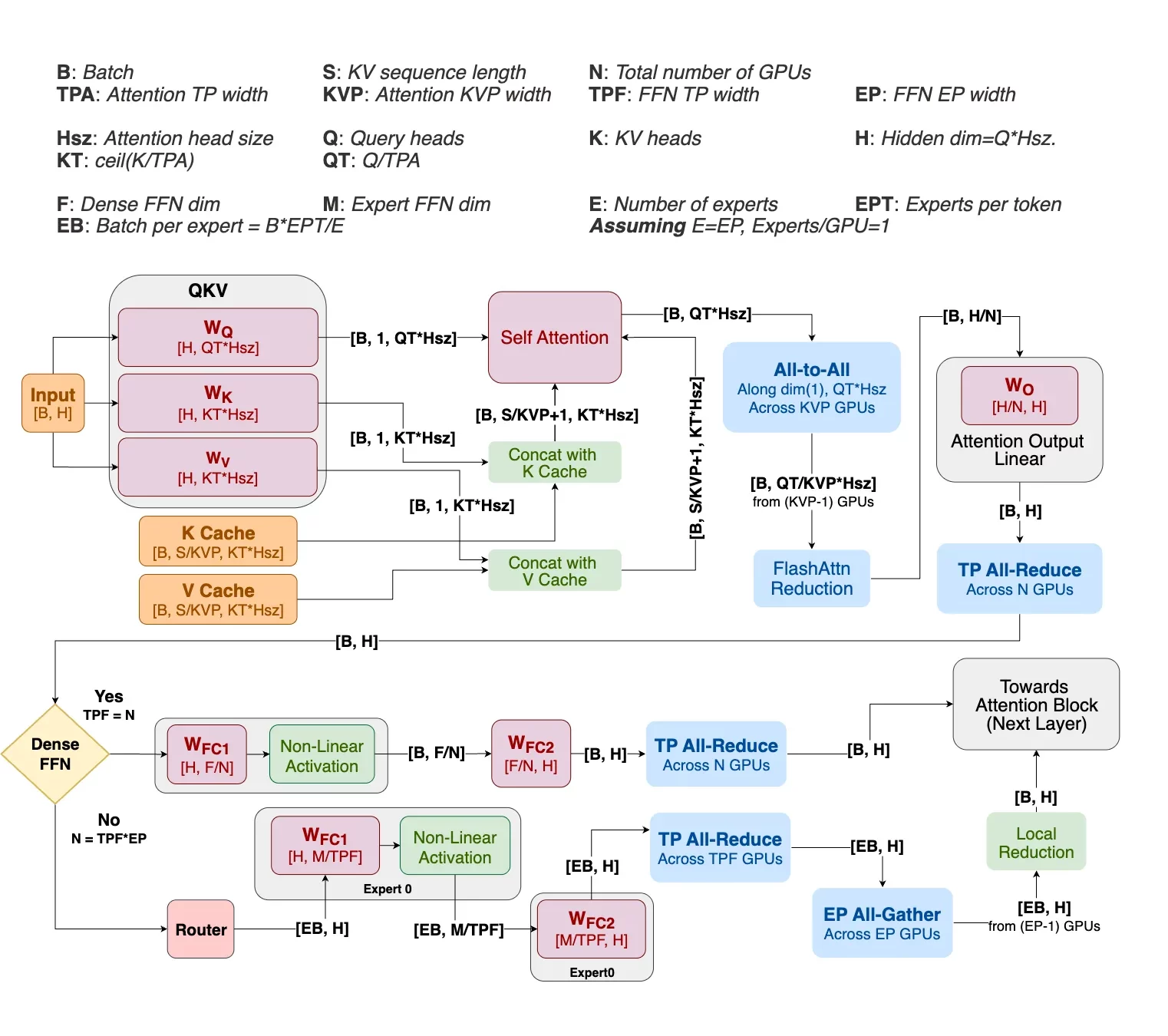
To solve this puzzle, NVIDIA’s Helix Parallelism introduces a hybrid strategy that treats the two bottlenecks as separate problems to be solved in a seamless, temporal pipeline. Instead of using a single parallelism method for the entire process, Helix dynamically reconfigures the same pool of GPUs to use the optimal strategy for each stage of computation.
The process can be broken down into two main phases for each layer of the model.
Phase 1: The Attention Phase (Tackling the KV Cache)
Helix directly addresses the KV cache bottleneck by combining two forms of parallelism. First, it applies KV Parallelism, which shards the KV cache itself across multiple GPUs along the sequence dimension. This means each GPU only holds a piece of the total context, reducing the memory burden.
Simultaneously, it uses Tensor Parallelism to split the attention heads, ensuring the number of splits does not exceed the number of KV heads. This combination avoids the cache duplication that plagues traditional Tensor Parallelism. The result is a 2D grid of GPUs that can efficiently compute attention on a massive context without any one GPU being overwhelmed. Communication between these GPUs is handled by a single, efficient all-to-all exchange whose cost is independent of the context length, making it highly scalable.
Phase 2: The FFN Phase (Tackling the FFN Weights)
The all-to-all communication at the end of the attention phase also partitions the output data across the GPUs. This means the data is already perfectly arranged for the FFN computation to begin immediately.
The same pool of GPUs is reprovisioned into a large Tensor Parallelism group. Because the data is pre-partitioned, each GPU can perform a local matrix multiplication using its shard of the massive FFN weights. This initial computation happens in parallel with no cross-GPU communication, maximizing speed. Only after this local compute step do the GPUs participate in an efficient all-reduce communication to combine their partial results into the final output.
A final piece of the puzzle is how Helix manages the KV cache as it grows. As the model generates new tokens, they must be appended to the cache. A naive approach could create a memory hotspot by writing all new tokens to a single GPU. Helix prevents this with a clever round-robin update system. For example, the first block of new tokens might go to GPU 0, the following block to GPU 1, and so on. This staggered approach ensures that memory usage grows uniformly across all GPUs in the KV Parallelism group, maintaining balanced performance and consistent throughput regardless of the context size.
A New Performance Frontier on Blackwell
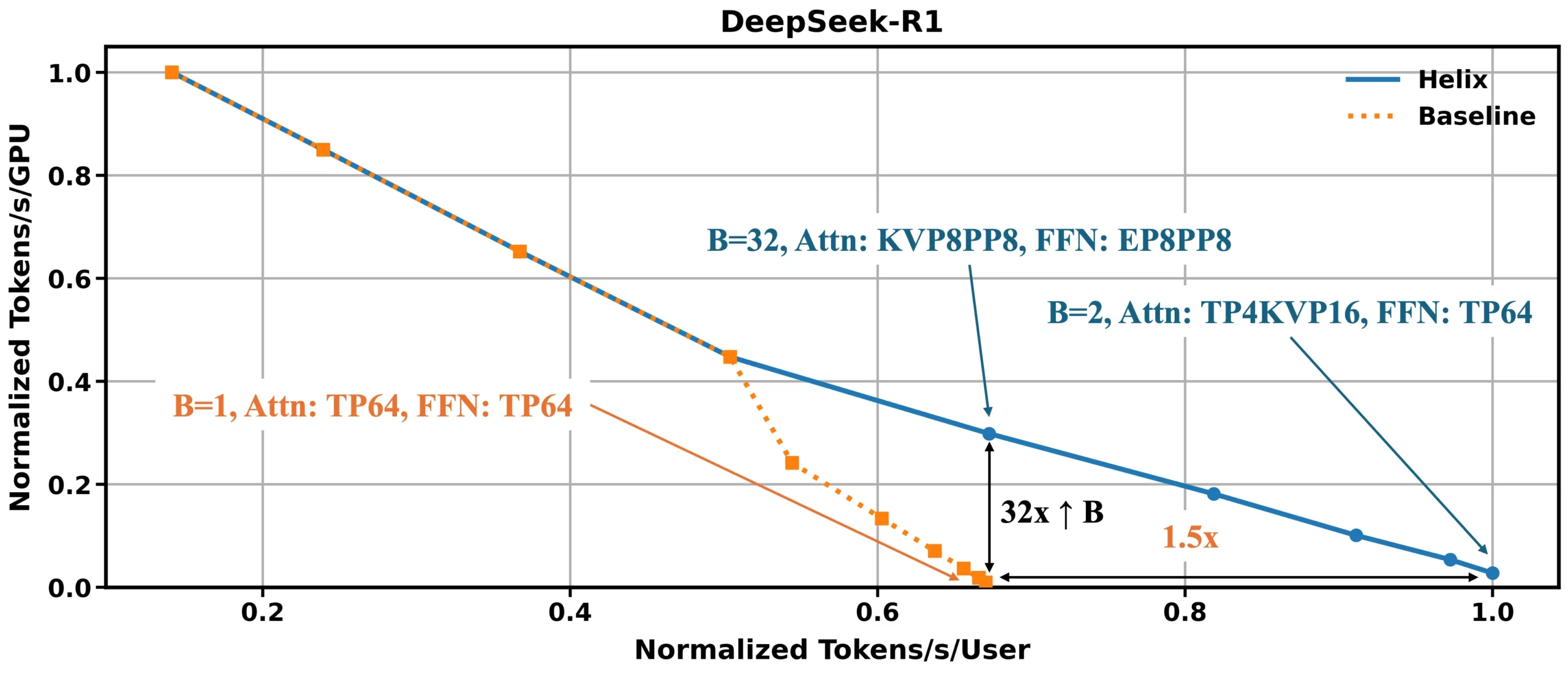
Helix sets a new performance benchmark for long-context LLM decoding. The results are based on an exhaustive simulation on the Blackwell NVL72 using DeepSeek R1 671B parameter model (FP4) with a hypothetical one-million-token context, systematically varying partitioning strategies and batch sizes to find the best throughput-latency tradeoffs. For applications requiring massive scalability, such as serving many users simultaneously, Helix can improve the number of concurrent users by up to 32x for a given latency budget. For low-concurrency settings where single-user responsiveness is critical, the technique can improve user interactivity by up to 1.5x by reducing the minimum achievable token-to-token latency. These gains are made possible by sharding both the KV cache and FFN weights across all available devices, which dramatically reduces DRAM pressure and improves compute efficiency.
For a deeper technical dive into the methodology and simulation results, here’s the link for the full report.


 Amazon
Amazon