

The landscape of graphics processing units (GPUs) has experienced seismic shifts over the past two decades, much more recently with the surge of AI. A significant part of this evolution has been the development of technologies that allow multiple GPUs to work in tandem. NVIDIA, a frontrunner in the GPU space, has been at the forefront of this revolution with two pivotal technologies: Scalable Link Interface (SLI) and NVIDIA NVLink. This article traces the journey from SLI to NVLink, highlighting how NVIDIA continually adapts to ever-changing computing demands.
The Dawn of SLI
NVIDIA introduced SLI in the early 2000s, which was originally developed by 3dfx for the Voodoo2 line of cards, and was NVIDIA’s answer to the growing demand for higher graphical fidelity in video games and consumer applications. At its core, SLI uses a technique known as Alternate Frame Rendering (AFR) to divide the rendering workload across multiple GPUs. Each card would draw every other frame or even a portion of each frame, effectively doubling the graphics horsepower. While revolutionary at the time, SLI had limitations, including higher latency and a lack of flexibility in data sharing among GPUs.
SLI vs. CrossFire: A Rivalry in Multi-GPU Solutions
While NVIDIA’s SLI set the pace for multi-GPU configurations, it wasn’t without competition. AMD’s CrossFire was a direct rival, offering similar capabilities for multi-GPU setups. Like SLI, CrossFire aimed to boost graphical performance through techniques such as Alternate Frame Rendering (AFR) and Split Frame Rendering (SFR).

Image Credit Dallas Moore
However, CrossFire had its own set of advantages and challenges. It was generally more flexible with the combinations of GPUs that could be used, allowing for a mix of different AMD cards. On the downside, CrossFire was often criticized for its software stack, which some users found less reliable and more complex to configure than NVIDIA’s SLI. Despite these differences, both technologies were geared towards the same goal: enhancing gaming and consumer graphical experiences. Their limitations in handling more advanced, data-intensive tasks would eventually pave the way for next-generation solutions like NVLink.
As the 2010s rolled in, the computing landscape began to change dramatically. The rise of artificial intelligence (AI), high-performance computing (HPC), and big data analytics necessitated more robust multi-GPU solutions. It became apparent that SLI, initially designed with gaming and consumer workloads in mind, was insufficient for these computationally intensive tasks. NVIDIA needed a new paradigm.
The Era of Dual-GPU Cards: A Unique Approach to Multi-GPU Computing
While technologies like SLI and CrossFire focused on connecting multiple discrete GPUs, there was another, less common approach to multi-GPU configurations: dual-GPU cards. These specialized graphics cards housed two GPU cores on a single PCB (Printed Circuit Board), effectively acting as an SLI or CrossFire setup on a single card. Cards like the NVIDIA GeForce GTX 690 and the AMD Radeon HD 6990 were popular examples of this approach.
Dual-GPU cards offer several advantages. They saved space by condensing two GPUs into one card slot, making them appealing for small form-factor PCs. They also simplified the setup by eliminating the need for linking separate cards with external connectors. However, these cards were not without their issues. Heat dissipation was a significant problem, often requiring advanced cooling solutions. Power consumption was also high, requiring beefy power supplies to stabilize the system.
Interestingly, dual-GPU cards were a sort of “best-of-both-worlds” solution, combining the raw power of multi-GPU setups with the simplicity of a single card. Yet, they were often seen as a niche product due to their high cost and associated technical challenges. As multi-GPU technologies like NVLink have evolved to offer higher bandwidth and lower latency, the need for dual-GPU cards has diminished. Still, they remain a fascinating chapter in the history of GPU development.
The Tesla line of GPUs from NVIDIA was a cornerstone in enterprise-level computing, particularly in data centers and high-performance computing clusters. While most Tesla GPUs are single-GPU cards designed for maximum performance and efficiency, there have been exceptions like the Tesla K80, which features dual GPUs on a single card. These multi-GPU Tesla cards were optimized for highly parallel computations and were a staple in scientific research, machine learning, and big data analytics. They’re engineered to meet the specific demands of these applications, offering high computational throughput, large memory capacities, and advanced features like Error-Correcting Code (ECC) memory. Although less common than their single-GPU counterparts, these dual-GPU Tesla cards presented a powerful, albeit niche, solution in enterprise computing.
The Advent of NVLink
Enter NVLink, introduced with NVIDIA’s Volta architecture in 2017. This technology was not just an upgrade but a fundamental rethink of how GPUs could be interconnected. NVLink offered significantly higher bandwidth (up to 900 GB/s with the latest versions), lower latency, and a mesh topology that allowed for more intricate and numerous interconnections between GPUs. Moreover, NVLink introduced the concept of unified memory, enabling memory pooling among connected GPUs, a crucial feature for tasks requiring large datasets.
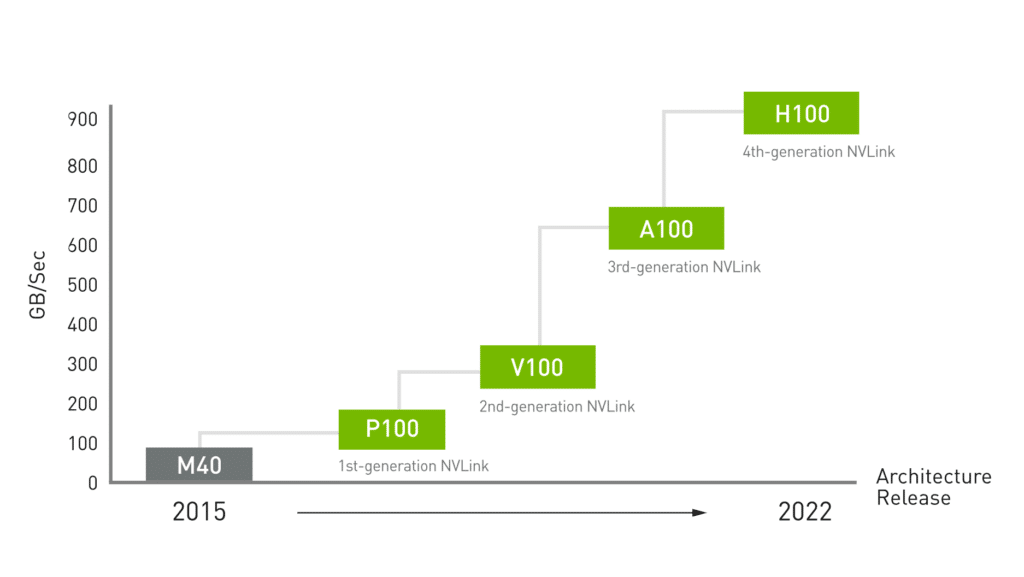
Evolution of NVLink performance
SLI vs. NVLink
At first glance, one might think of NVLink as “SLI on steroids,” but that would be an oversimplification. While both technologies aim to link multiple GPUs, NVLink is designed with a different audience in mind. It is crafted for scientific research, data analysis, and, most notably, AI and machine learning applications. The higher bandwidth, lower latency, and unified memory make NVLink a far more flexible and powerful solution for today’s computational challenges.
Technical Backbone of NVLink
NVLink represents a logical evolution in multi-GPU interconnect technology, not just in terms of speed but also in architectural design. The fabric of NVLink is composed of high-speed data lanes that can transfer data bi-directionally. Unlike traditional bus-based systems, NVLink uses a point-to-point connection, effectively reducing bottlenecks and improving data throughput. The most recent iterations offer bandwidths up to 900 GB/s, a significant enhancement over SLI’s capabilities.

HP Z8 Fury G5 with 4x A6000 GPUs
One of the key features that sets NVLink apart is its ability to support a mesh topology. In contrast to the daisy-chained or hub-and-spoke topologies of older technologies, a mesh setup allows for more versatile and numerous connections between GPUs. This is particularly useful in data center and high-performance computing applications where complex data routes are the norm.
Unified memory is another feature of NVLink. This allows GPUs to share a common memory pool, enabling more efficient data sharing and reducing the need to copy data between GPUs. This is a massive boost for applications like machine learning and big data analytics, where large datasets often exceed the memory capacity of a single GPU.
NVLink also improves upon latency, a crucial factor in any high-performance computing setup. Lower latency ensures quicker data transfer and synchronization between GPUs, leading to more efficient parallel computations. This is achieved through NVLink’s direct memory access (DMA) capabilities, allowing GPUs to read and write directly to each other’s memory without involving the CPU.
The Impact on AI and Machine Learning
Given the increasing importance of AI in modern computing, NVLink’s advantages are not just incremental but transformative. In AI model training and data creation, NVLink enables faster data transfer between GPUs, allowing for more efficient parallel processing. This is especially beneficial when working with large training datasets, a subject that aligns closely with the emerging field of AI model training data creation.
With the growing demands of advanced computing like quantum simulations, real-time analytics, and next-gen AI algorithms, we can expect further enhancements in NVLink’s capabilities. Whether it’s an increase in bandwidth or new features that facilitate even greater cooperation between GPUs, NVLink or its successor will undoubtedly remain central to fulfilling the computational needs of tomorrow.
The transition from SLI to NVLink marks a significant milestone for multi-GPU technologies. It reflects NVIDIA’s commitment to innovation and keen understanding of the changing computational landscape. From gaming to AI, consumer applications to data centers, the roots of NVLink in gaming and SLI illustrate how necessity breeds innovation, driving technology forward in a never-ending cycle of improvement.


 Amazon
Amazon