

The HPE ProLiant Compute DL380a Gen12 targets mainstream enterprise AI teams that want density without altering their rack configurations. This 4U, air-cooled chassis drops in cleanly, supports up to eight double-wide GPUs, and offers PCIe Gen5 throughout. It can be configured with dual Intel Xeon 6 CPUs, each with up to 144 cores, 4TB of DDR5 across 32 DIMMs, and sixteen E3.S NVMe bays for high throughput and capacity. The goal is straightforward: to achieve production-grade inference and focused fine-tuning at scale without venturing into liquid-cooled territory.

For accelerators, HPE validates a broad stack that spans NVIDIA H200 NVL, H100 NVL, L40S, L20, L4, and RTX PRO 6000 Blackwell Server Edition, with PSU options that support higher-draw components. For this review, we are focusing on the RTX PRO 6000 Server, which hits a practical sweet spot for enterprise AI. Each card brings 96GB of ECC GDDR7, PCIe Gen5 x16, FP4-capable Tensor cores, and a 600W envelope that works in air-cooled racks. Our rig shipped with four cards, which is a sensible starting point for high-throughput inference and targeted fine-tuning, with headroom to scale.

HPE rounds out the platform with the operational pieces that matter. iLO 7 handles out-of-band setup, health, and power control, anchored by the Silicon Root of Trust—a secure enclave for firmware integrity—support for 4096-bit RSA, and a detachable DC-MHS iLO module that strengthens supply chain verification. The server also ties into HPE’s Private Cloud AI framework for multi-team governance and repeatable deployments at fleet scale.
HPE ProLiant Compute DL380a Gen12 – Technical Specifications
| Category | Specification |
|---|---|
| Processor type | HPE ProLiant Compute DL380a Gen12 |
| Processor family | 6th Generation Intel® Xeon® Scalable Processors |
| Processor cores available | 64 to 144 cores, depending on the processor |
| Processor count | 2 |
| Processor speed | Up to 2.4 GHz, depending on the processor |
| Maximum memory | 4 TB RDIMM (2 TB per processor) |
| Memory slots | 32 DIMM slots |
| Memory type | HPE DDR5 Smart Memory |
| Memory protection | RAS: Advanced ECC, online spare, mirroring, combined channel (lockstep) functionality, HPE Fast Fault Tolerant Memory (ADDDC) |
| Drive support | SFF NVMe and EDSFF |
| Security | Optional locking bezel, intrusion detection, and embedded HPE TPM 2.0 |
| Infrastructure management | HPE iLO Standard with Intelligent Provisioning (embedded), HPE OneView Standard (requires download) • Optional: HPE iLO Advanced and HPE OneView Advanced (licenses required) |
| Power supply | Up to 8 M-CRPS. Single 1+1 redundancy for system board. Dual 2+1 redundancy for GPUs. |
| Expansion slots | 6 |
| System fans | 4 dual-rotor and 8 single-rotor hot-plug fans included |
| Form factor | 4U rack |
| Warranty | 3/3/3: Server Warranty |
HPE ProLiant DL380a Gen12 Design and Build
The HPE ProLiant Compute DL380a Gen12 is a 4U, dual-socket rack server designed for high-performance, scalable deployments. Measuring 6.88 x 17.63 x 31.60 in, it combines dense CPU and GPU compute power with efficient air cooling for reliable operation under heavy workloads.
Weighing between 82.7 lbs and 137.8 lbs, depending on configuration, the chassis supports high-capacity components, redundant power, and easy front access for serviceability. Its design emphasizes performance, expandability, and robust thermal management, making it suited for enterprise and data center environments.
 Moving into storage, the HPE ProLiant DL380a Gen12 offers 4- and 8-bay configurations in either SFF or EDSFF formats. Our review unit came configured with the HPE DL380a Gen12 NS204i-u Front Cage Kit, supporting two NVMe M.2 hot-pluggable boot devices. The chassis also included eight 2.5-inch bays, populated with two HPE-branded U.3 SSDs with a capacity of 15.36 TB. HPE offers several front-bay options, enabling flexible scalability for diverse deployment needs.
Moving into storage, the HPE ProLiant DL380a Gen12 offers 4- and 8-bay configurations in either SFF or EDSFF formats. Our review unit came configured with the HPE DL380a Gen12 NS204i-u Front Cage Kit, supporting two NVMe M.2 hot-pluggable boot devices. The chassis also included eight 2.5-inch bays, populated with two HPE-branded U.3 SSDs with a capacity of 15.36 TB. HPE offers several front-bay options, enabling flexible scalability for diverse deployment needs.

The unit can be transported using two handles on each side, meaning it requires at least two people to safely rack and install. It utilizes a 2U rail kit with telescoping rails, allowing for smooth installation and in-rack serviceability without requiring full rack removal.
 On the rear of the HPE ProLiant DL380a Gen12, you’ll find a well-organized layout focused on airflow, expandability, and serviceability. The system supports up to eight MCRPS power supplies (1-8) with an integrated air ventilation wall, maintaining optimal cooling under load. Expansion is extensive, featuring multiple PCIe Gen5 x16 slots (slots 1-6) that accommodate both default and optional captive risers, as well as OCP slots A and B for flexible network adapter configurations.
On the rear of the HPE ProLiant DL380a Gen12, you’ll find a well-organized layout focused on airflow, expandability, and serviceability. The system supports up to eight MCRPS power supplies (1-8) with an integrated air ventilation wall, maintaining optimal cooling under load. Expansion is extensive, featuring multiple PCIe Gen5 x16 slots (slots 1-6) that accommodate both default and optional captive risers, as well as OCP slots A and B for flexible network adapter configurations.
Connectivity includes a dedicated iLO network port, several USB 3.2 Gen 1 ports, and a VGA port for local management. It’s worth noting that Slot 1 is available only when the HPE DL380a Gen12 4EDSFF Direct Cable for NVD (P74716-B21) is installed and cannot be used with SFF NVMe drives, while Slot 4 is not supported in configurations with 4 or 8 DW GPUs.

Power for the HPE ProLiant DL380a Gen12 is provided through modular M-CRPS Titanium Hot Plug Power Supply Kits, with supported options including the 1500W (P67244-B21), 2400W (P67252-B21), and 3200W (P67248-B21) models. The system supports up to eight PSUs, allowing for N+1 redundancy to ensure continuous operation even in the event of a power module failure. Depending on the GPU configuration, power requirements and distribution can vary. Our review unit came equipped with five 2400W M-CRPS power supplies, providing sufficient capacity to support the system’s four 600W TDP GPUs while maintaining reliable redundancy.
 Looking top-down inside the HPE ProLiant DL380a Gen12, it’s clear that HPE engineered this chassis with a GPU-first thermal strategy, positioning the GPUs at the front of the system to receive direct, unobstructed airflow. The cooling system features four hot-plug fan assemblies, each built with one dual-rotor 92x56mm fan and two single-rotor 40x28mm fans. The smaller fans focus airflow over the CPU and memory modules, ensuring efficient thermal management for lower components. In comparison, the larger dual-rotor fans are specifically designed to drive high-volume airflow directly across the GPU array. This balanced design ensures optimal cooling for both compute and accelerator components, even under sustained high-power workloads.
Looking top-down inside the HPE ProLiant DL380a Gen12, it’s clear that HPE engineered this chassis with a GPU-first thermal strategy, positioning the GPUs at the front of the system to receive direct, unobstructed airflow. The cooling system features four hot-plug fan assemblies, each built with one dual-rotor 92x56mm fan and two single-rotor 40x28mm fans. The smaller fans focus airflow over the CPU and memory modules, ensuring efficient thermal management for lower components. In comparison, the larger dual-rotor fans are specifically designed to drive high-volume airflow directly across the GPU array. This balanced design ensures optimal cooling for both compute and accelerator components, even under sustained high-power workloads.

Upon examining the GPU configuration, our unit was prewired for four PCIe 5.0 GPUs, each installed cleanly within the front GPU cage. The system was configured with NVIDIA RTX PRO 6000 GPUs (Blackwell Server Edition, 96GB), part of NVIDIA’s new professional lineup optimized for AI, rendering, and compute workloads. Depending on the build, the DL380a Gen12 can support 4 or 8 dual-width GPUs or up to 16 single-width accelerators, offering flexibility for a wide range of enterprise and AI deployments.
Supported GPUs for this platform include:
- NVIDIA RTX PRO 6000 Server Edition (96GB)
- NVIDIA H200 NVL (141GB)
- NVIDIA H100 NVL (94GB)
- NVIDIA L40S (48GB)
- NVIDIA L20 (48GB)
- NVIDIA L4 (24GB)
This flexible GPU layout, paired with high-bandwidth PCIe Gen5 lanes, ensures the DL380a Gen12 is ready for both dense inference tasks and large-scale AI training environments. Moving further back inside the chassis, with the cooling shroud installed, we can see HPE’s thoughtful engineering approach to airflow management. The shroud features a precisely molded baffle design that directs air efficiently across the CPUs, memory modules, and VRMs, ensuring even cooling throughout the system.
 Looking at the CPU coolers, HPE designed the DL380a Gen12 with thermal balance in mind. Each Xeon 6 processor is fitted with a tall, high-density heatsink, engineered to handle the CPU’s own thermal output and the additional heat generated by the GPUs positioned toward the front of the chassis. This design ensures consistent cooling performance even under heavy mixed workloads, where GPU exhaust can raise ambient temperatures around the CPU zone. When high-wattage GPUs are populated, the combination of taller heatsinks and HPE’s front-to-rear airflow design provides the necessary surface area and cooling efficiency to manage the additional thermal load effectively.
Looking at the CPU coolers, HPE designed the DL380a Gen12 with thermal balance in mind. Each Xeon 6 processor is fitted with a tall, high-density heatsink, engineered to handle the CPU’s own thermal output and the additional heat generated by the GPUs positioned toward the front of the chassis. This design ensures consistent cooling performance even under heavy mixed workloads, where GPU exhaust can raise ambient temperatures around the CPU zone. When high-wattage GPUs are populated, the combination of taller heatsinks and HPE’s front-to-rear airflow design provides the necessary surface area and cooling efficiency to manage the additional thermal load effectively.

ILO 7 Overview
As mentioned, the system includes a dedicated iLO port that provides out-of-band management capabilities for complete server control and monitoring. This box comes with the new HPE iLO 7 interface, providing administrators with access to a refreshed interface and enhanced functionality, integrated with HPE Compute Ops Management for streamlined configuration, monitoring, and lifecycle management. Below is the new HPE iLO 7 login screen from our sample system.
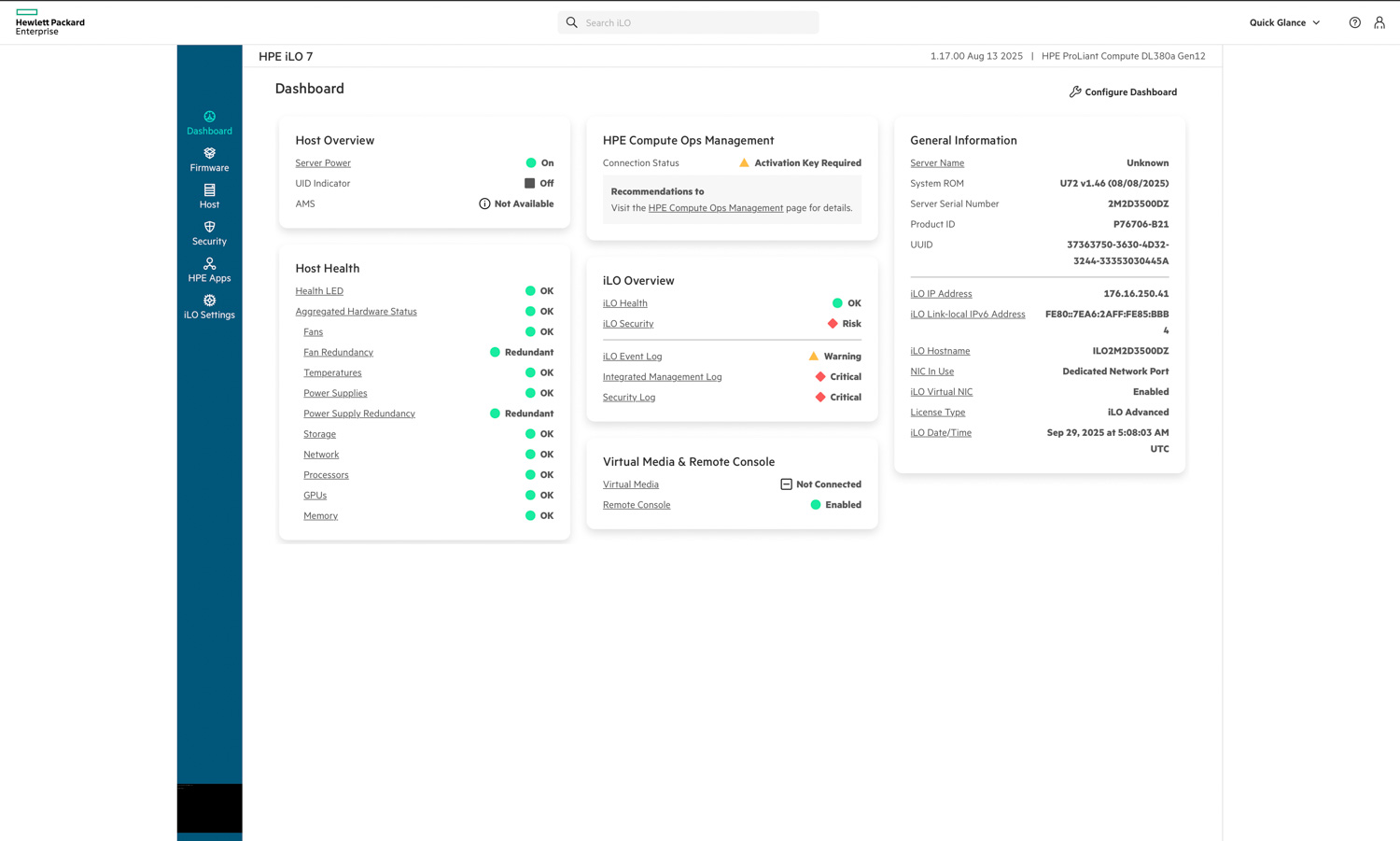
Starting with the dashboard, we can see that HPE iLO 7 presents a modernized interface that immediately highlights system status and key health indicators. The main panel provides an overview of host power state, health, and connection status with HPE Compute Ops Management. On the right, general system information such as the iLO IP address, hostname, and license type is displayed for quick reference.
The dashboard consolidates essential metrics—such as fan redundancy, power supply health, and temperature readings—into a clear, color-coded layout, making it easy to assess server conditions at a glance. Virtual media and remote console access are also accessible directly from the main page, streamlining common remote management tasks without additional navigation.
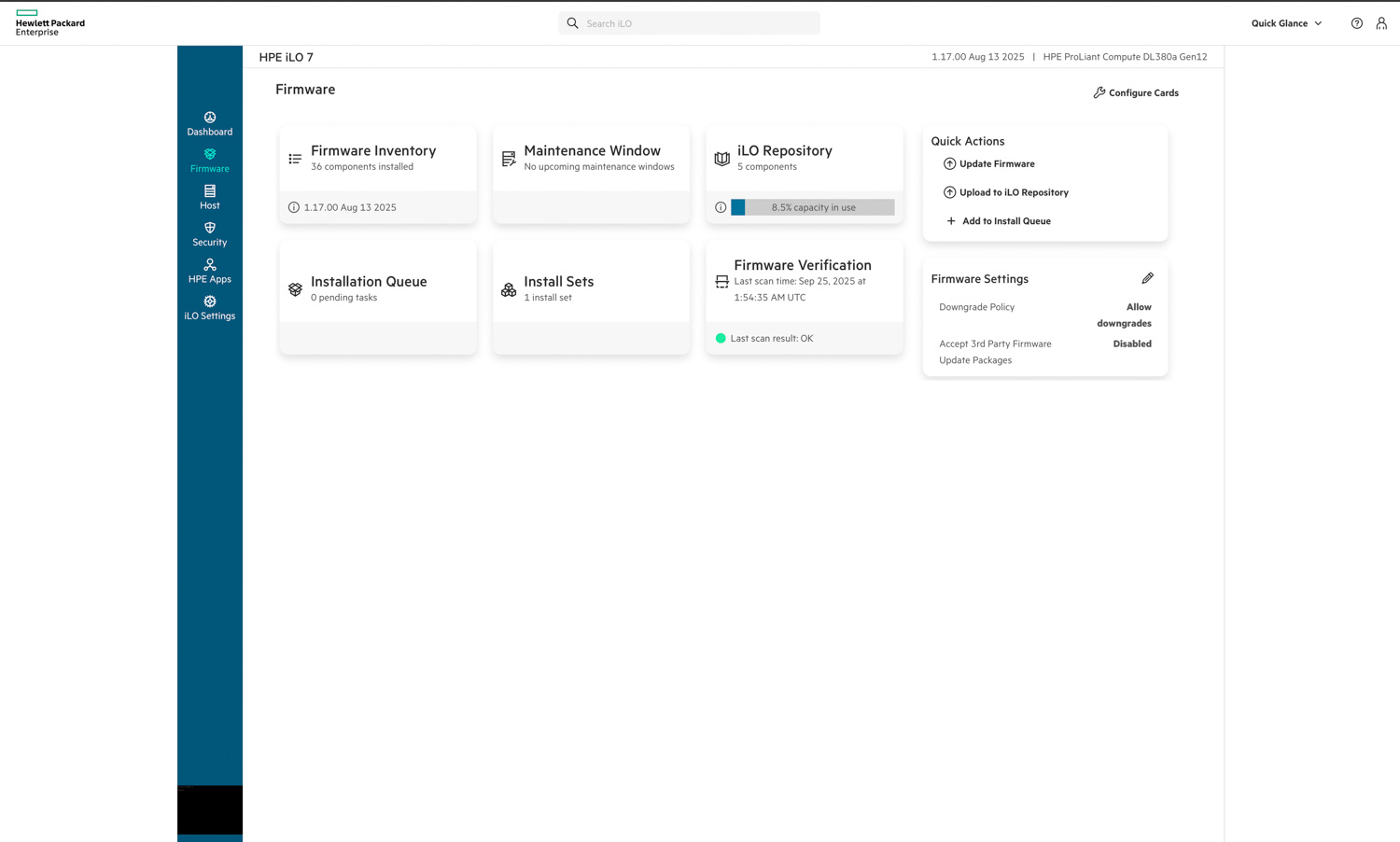
In the Firmware tab, HPE iLO 7 provides a clear and organized view of all components and update management tasks. The interface lists the firmware inventory, active installation queues, and verification results in a card-based layout that’s easy to navigate. Administrators can quickly initiate updates, upload packages to the iLO repository, or create install sets for batch deployment.
Firmware verification and repository management are built directly into this view, allowing users to confirm integrity and maintain version consistency across components. The Quick Actions menu on the right streamlines essential tasks, such as updating firmware or uploading new files. The Firmware Settings card provides control over downgrade policies and the acceptance of third-party packages.
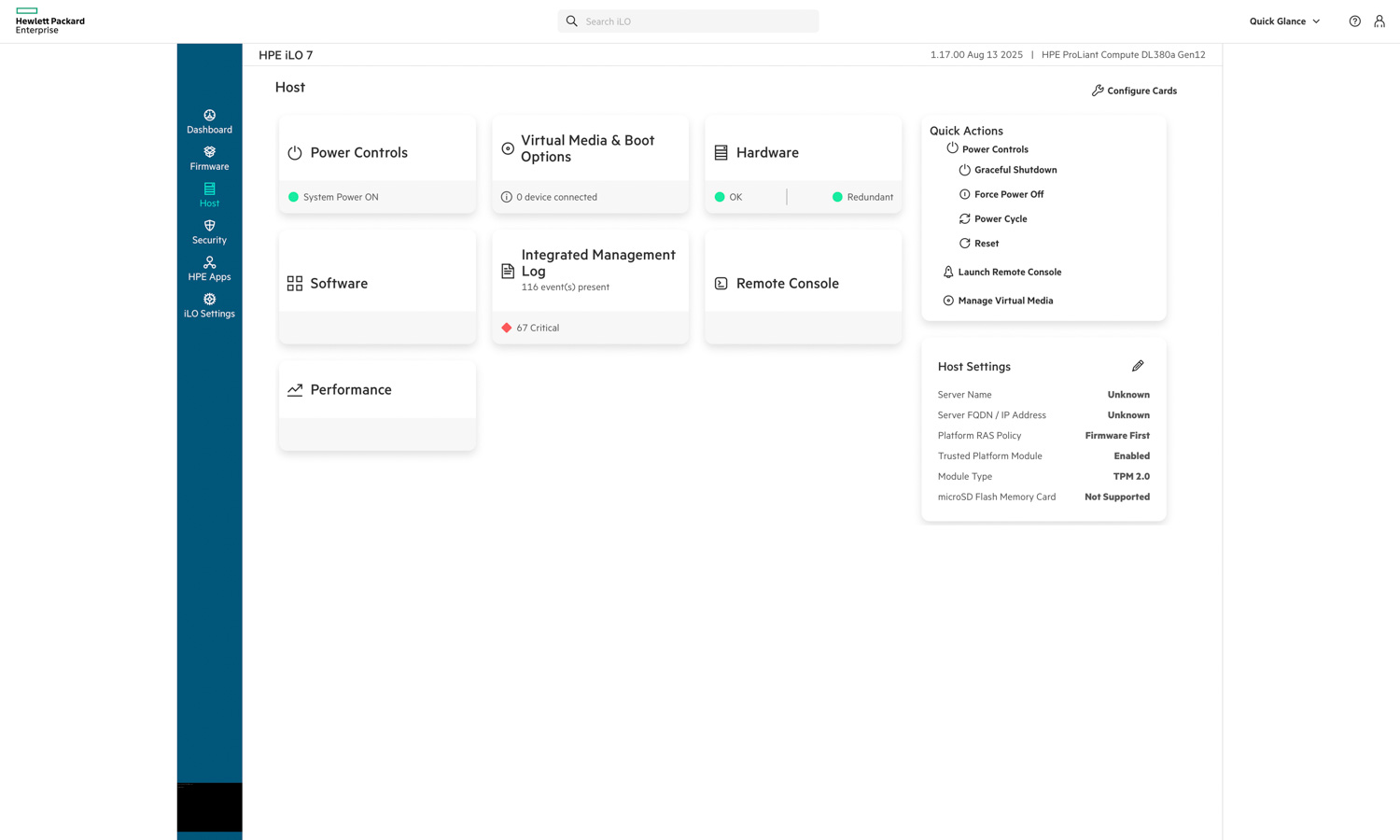
In the Host section, HPE iLO 7 provides quick access to critical server management functions, including power controls, virtual media, hardware health, and system performance. Administrators can view real-time hardware redundancy status, access the integrated management log, or launch the remote console directly from this interface. The layout also includes quick actions such as graceful shutdown, power cycling, and reset functions, enabling full remote control of the system without physical access.
The right-hand panel displays host settings, including TPM status, platform policy configuration, and hardware module information. Overall, this section highlights iLO 7’s role as a centralized control hub, allowing administrators to securely manage power, monitor events, and maintain operational oversight in a single view.
 From the Host > Hardware view, we can see the GPUs installed in the system. As noted, the unit is equipped with four NVIDIA RTX PRO 6000 Blackwell GPUs, each reported as enabled and operating normally. iLO 7 provides detailed hardware information, including model numbers, part numbers, and serial numbers, allowing administrators to verify component health at a glance.
From the Host > Hardware view, we can see the GPUs installed in the system. As noted, the unit is equipped with four NVIDIA RTX PRO 6000 Blackwell GPUs, each reported as enabled and operating normally. iLO 7 provides detailed hardware information, including model numbers, part numbers, and serial numbers, allowing administrators to verify component health at a glance.
In the Security tab, HPE iLO 7 consolidates all key controls related to system protection and access management. The overview panel provides a high-level view of the overall security state, highlighting risk levels, configuration locks, and certificate status. From here, administrators can manage encryption settings, authentication methods, and TLS certificates, as well as configure secure erase and remote key management.
The interface clearly indicates areas that require attention, such as self-signed certificates or unconfigured key management, while still confirming secure operation where applicable. Security logs, user management policies, and access controls are easily accessible, providing administrators with a comprehensive view of the system’s security posture directly from the iLO environment.
Under the HPE Apps tab, iLO 7 provides access to integrated tools that enhance server deployment and lifecycle management. From this view, administrators can launch Intelligent Provisioning, a built-in utility designed to simplify operating system installation, firmware updates, and system configuration without the need for external media.
The iLO Settings tab consolidates all configuration and administrative options for managing the iLO interface. From here, administrators can control user access, network port configurations, authentication methods, and logging behavior. The menu also includes options for troubleshooting, policy enforcement, license management, and time synchronization.
Quick actions, such as backing up or restoring the iLO configuration and performing a reset, are conveniently available on the right, helping to streamline maintenance tasks. The layout mirrors the rest of iLO 7’s modern, card-based interface, providing a clean, organized way to manage security, connectivity, and operational parameters from a single centralized location.
Performance Testing
To evaluate the real-world capabilities of the DL380a Gen12, we conducted a comprehensive set of performance tests that covered both AI inference and general compute workloads. These include vLLM online serving benchmarks for large language models (LLMs) and Phoronix Test Suite benchmarks to measure CPU throughput, memory bandwidth, web-serving efficiency, and cryptographic performance.
System Configuration
- CPU: 2 x Intel Xeon 6527P CPU
- Memory: 16 x HPE 64GB 2Rx4 PC5-3400B-R Smart Kit
- GPU: 4 x NVIDIA RTX PRO 6000 (96GB)
- Storage: 2 x 15.63TB PM1733a U.3

vLLM Online Serving – LLM Inference Performance
vLLM is the most popular high-throughput inference and serving engine for LLMs. The vLLM online serving benchmark is a performance evaluation tool that measures the real-world serving capabilities of this inference engine under concurrent requests. It simulates production workloads by sending requests to a running vLLM server with configurable parameters, including request rate, input/output lengths, and the number of concurrent clients. The benchmark measures key metrics, including throughput (tok/s), time to first token, and time per output token, helping users understand how vLLM performs under different load conditions.
We tested the inference performance across three representative models spanning different scales and quantization approaches, evaluating how the HPE ProLiant DL380a Gen12’s four NVIDIA RTX PRO 6000 GPUs handle production inference workloads.
Dense Model Performance
Dense models represent the conventional LLM architecture, where all parameters and activations are engaged during inference. We evaluated two dense model configurations: Llama-2-70b-chat-hf and Llama-3.2-90B-Vision-Instruct.
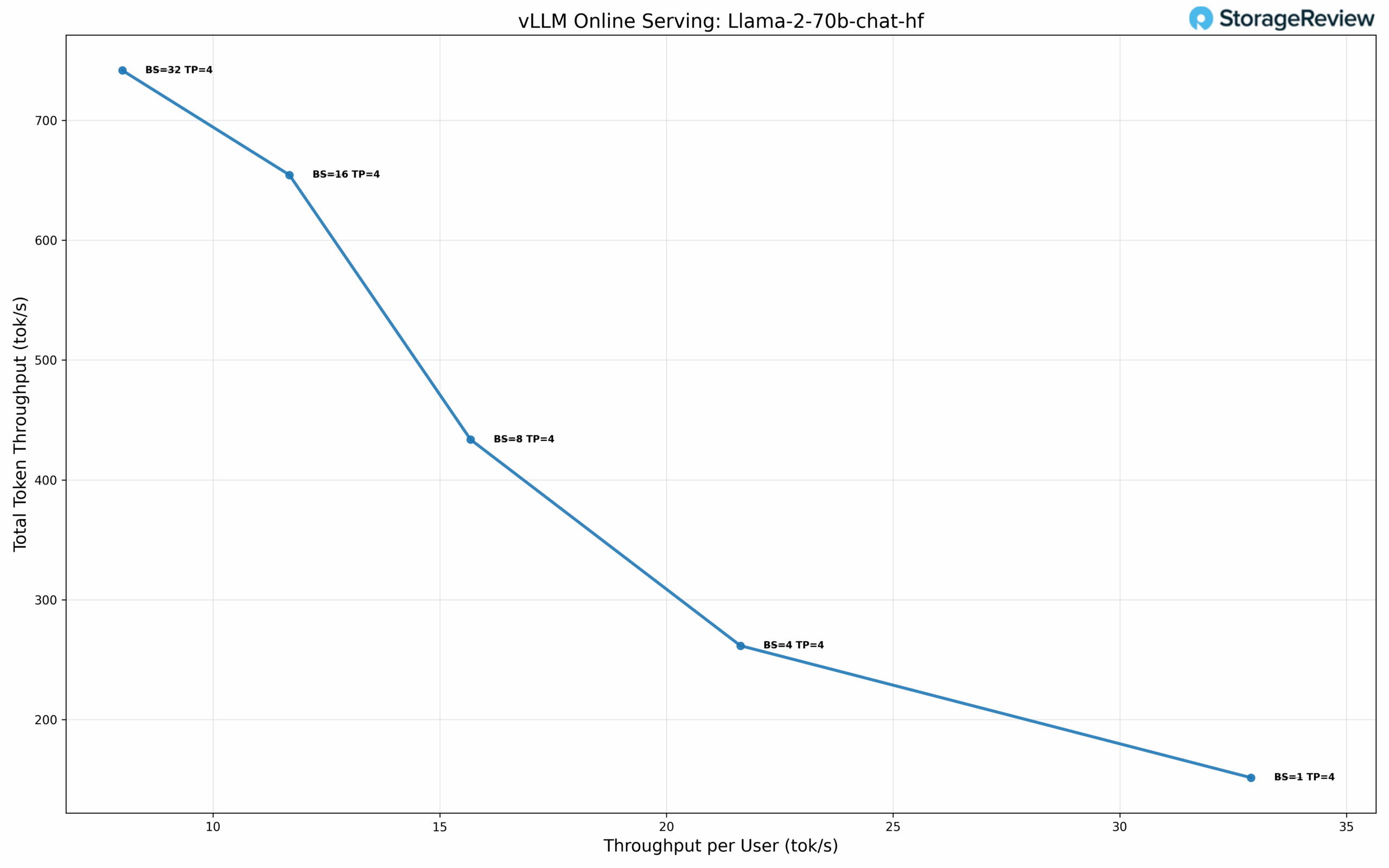
Llama-2-70B-Chat Performance
At single-user concurrency (BS=1) with TP=4, the model achieves 32.89 tok/s per user with a TPOT of 30.18 ms. At BS=8, performance reaches 15.68 tok/s per user with 433.62 tok/s total throughput and 35.98 ms TPOT. Scaling to BS=32, total throughput reaches 741.62 tok/s while maintaining 8.00 tok/s per user with 43.44 ms TPOT.
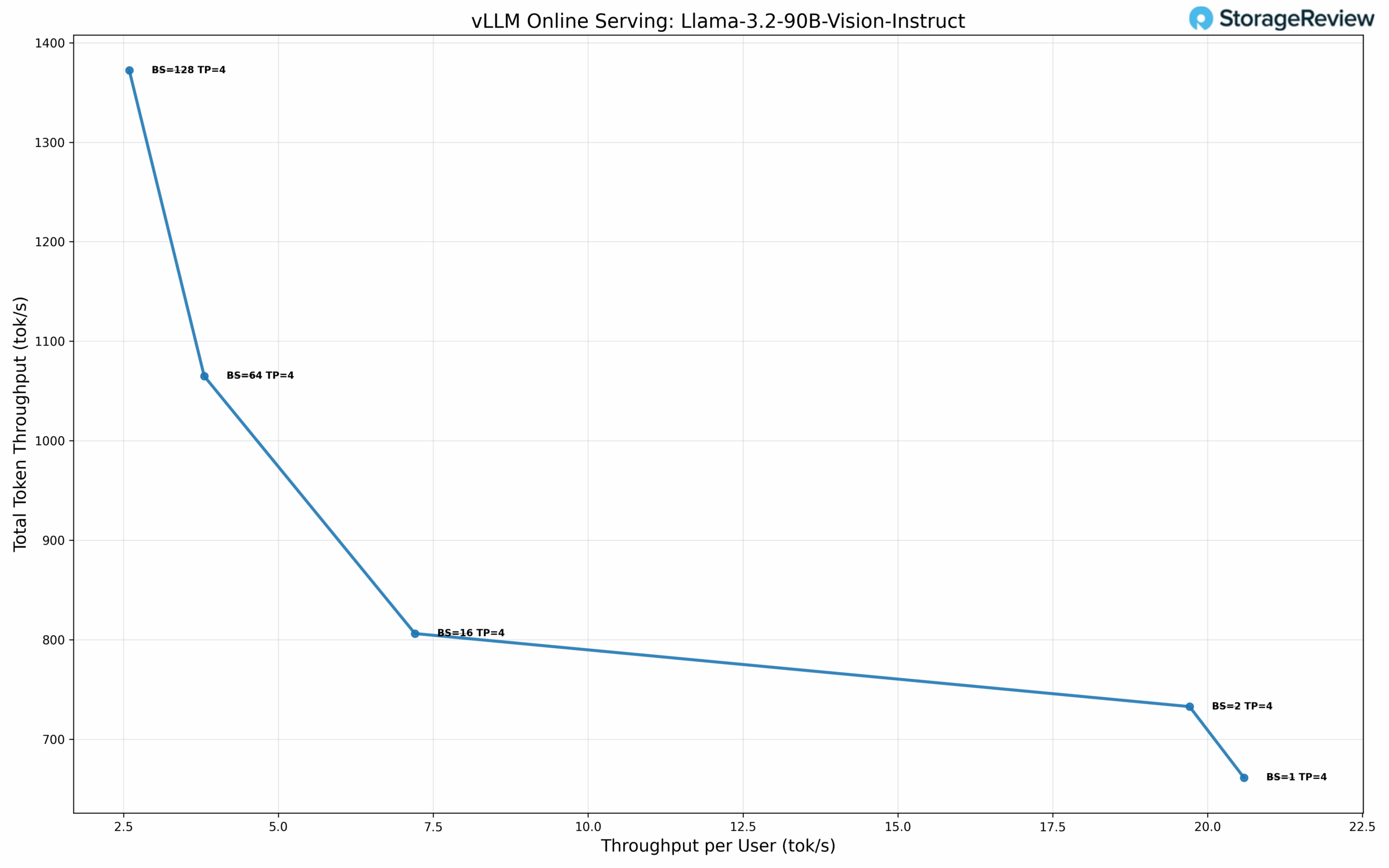
Llama-3.2-90B-Vision-Instruct Performance
At BS=1 with TP=4, the model delivers 20.59 tok/s per user with 38.27 ms TPOT. At BS=16, performance scales to 7.20 tok/s per user with 806.14 tok/s total throughput and 54.98 ms TPOT. Maximum total throughput of 1372.21 tok/s is achieved at BS=128, delivering 2.59 tok/s per user with 122.75 ms TPOT.
Microscaling Datatype Performance
Microscaling represents an advanced quantization approach that applies fine-grained scaling factors to small blocks of weights rather than uniform quantization across large parameter groups. NVIDIA’s NVFP4 format implements this technique through a blocked floating-point representation where each microscale block of 8-32 values shares a common exponent as a scaling factor. This granular approach preserves numerical precision while achieving 4-bit representation, maintaining the dynamic range critical for transformer architectures. The format integrates with NVIDIA’s Tensor Core architecture on the RTX PRO 6000, enabling efficient mixed-precision computation with on-the-fly decompression during matrix operations.
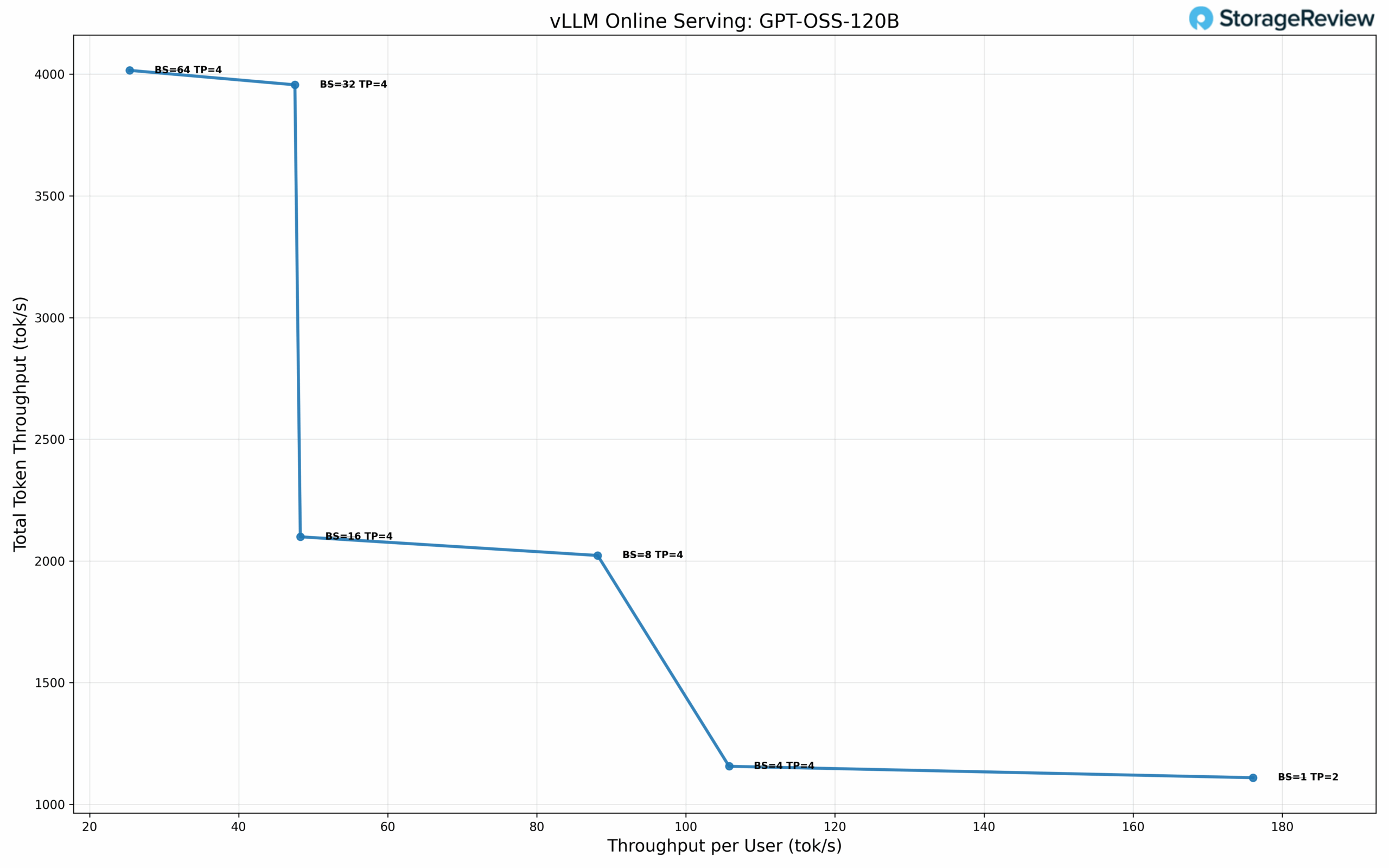
GPT-OSS-120B Performance
We evaluated OpenAI’s GPT-OSS-120B model using NVFP4 quantization. At single-user concurrency with TP=2, the model achieves 176.09 tok/s per user with 5.46 ms TPOT, the lowest latency in our test suite. At BS=4 with TP=4, performance reaches 105.79 tok/s per user while delivering 1155.94 tok/s total throughput with 7.79 ms TPOT. At BS=32 with TP=4, throughput scales to 47.54 tok/s per user and 3956.44 tok/s total with 13.86 ms TPOT. Maximum total throughput of 4015.77 tok/s is achieved at BS=64, delivering 25.38 tok/s per user with 14.78 ms TPOT.
Phoronix Benchmarks
Phoronix Test Suite is an open-source, automated benchmarking platform that supports over 450 test profiles and 100+ test suites via OpenBenchmarking.org. It handles everything from installing dependencies to running tests and collecting results, making it ideal for performance comparisons, hardware validation, and continuous integration. We will focus on the following tests: Stream, 7-Zip, Linux kernel build, Apache, and OpenSSL tests.
Stream Memory Bandwidth
In the Stream benchmark, which measures raw memory throughput, the HPE DL380a Gen12 achieved an impressive 542 GB/s, demonstrating the platform’s ability to sustain high data transfer rates under continuous load. This level of bandwidth makes the system particularly effective for workloads such as data modeling, simulation, and AI inference, where large datasets must move rapidly between memory and compute resources
7-Zip Compression
The 7-Zip compression test measured 305 k MIPs, highlighting the system’s strong multithreaded efficiency for compute-intensive compression and decompression operations. These results make the DL380a Gen12 well-suited for environments involving frequent data packaging, archival tasks, or backup workflows that rely on consistent, repeatable CPU performance.
Kernel Compile
When compiling a full Linux kernel (allmodconfig), the DL380a Gen12 completed the task in 316 seconds. This benchmark reflects the system’s ability to handle parallelized, code-heavy workloads with ease. Faster compile performance translates directly to shorter build times and improved iteration speed for developers working in large-scale software or CI/CD environments.
Apache Web Server
In web-serving performance, the DL380a Gen12 sustained 94,348 requests per second in the Apache benchmark. This result demonstrates balanced I/O handling and strong cache efficiency, providing the throughput and responsiveness needed for enterprise web applications, virtualization front ends, or internal service hosting.
OpenSSL Verification
Cryptographic performance was equally strong, with the DL380a Gen12 verifying 803 billion operations per second in OpenSSL. This showcases the system’s ability to manage encryption, authentication, and secure communications workloads at scale.
| Phoronix Benchmarks | HPE ProLiant DL380a Gen 12 (2x Intel Xeon 6527P) |
| Stream | 542,720.7 MB/s |
| 7-ZIP | 304,907 MIP/s |
| Kernel Compile (allmod) | 316.166 Seconds |
| Apache (requests per second) | 94,347.52 R/s |
| OpenSSL | 803,597,895,087 Verify/s |
Conclusion
The HPE ProLiant DL380a Gen12 stands out as one of the most practical and well-balanced AI servers designed for the mainstream enterprise AI market. Its 4U air-cooled design delivers serious compute density with dual Xeon 6 CPUs, support for up to 8 double-wide or 16 single-width GPUs, and 16 E3.S NVMe bays, all while maintaining reliability and straightforward serviceability. HPE’s engineering approach to airflow and thermal balance ensures consistent performance under heavy workloads, demonstrating that advanced AI acceleration can still thrive in traditional air-cooled environments.
The inclusion of iLO 7 provides a significant improvement in manageability, a huge advantage for tier-1 server vendors like HPE. The modernized interface, integration with HPE Compute Ops Management, and detailed hardware telemetry make remote administration intuitive and efficient. Each section, Dashboard, Firmware, Host, Security, Apps, and Settings, reflects HPE’s shift toward a cleaner, more cloud-integrated experience without sacrificing the on-prem control that enterprise teams depend on.

In performance testing, the server delivered excellent results. The four RTX PRO 6000 GPUs achieved impressive throughput across both dense and microscaled LLM models, with vLLM serving performance that rivals liquid-cooled systems. CPU benchmarks from Phoronix further highlight its balance, with over 540 GB/s of memory bandwidth, 94k RPS in Apache, and more than 800 billion OpenSSL verifications per second, showing strength across both AI and general-purpose compute.
HPE’s design goal is clear: to deliver high-density, production-ready AI performance using air cooling that fits within existing rack and power infrastructures. For data center teams seeking reliable, secure, and easily managed compute in an air-cooled form factor, the DL380a Gen12 is a capable, forward-looking solution for the growing mainstream AI market.


 Amazon
Amazon