

The L40S fills a critical gap in the data center GPU ecosystem. While compute-focused AI training GPUs like the Nvidia H100 prioritize raw performance but omit graphics acceleration entirely, traditional professional visualization cards typically lack the AI computational capabilities demanded by modern inference workloads and emerging AI-driven graphics applications. This positioning makes it particularly valuable for synthetic data generation, multimodal AI development, and Omniverse applications where both compute and graphics performance are essential.

NVIDIA L40S Specifications
| Specification | L40 | L40S | H100 80G PCIe |
| GPU Architecture | Ada Lovelace | Ada Lovelace | Hopper |
| GPU Die | AD102 | AD102 | GH100 |
| CUDA Cores | 18,176 | 18,176 | 14,592 |
| Tensor Cores | 568 (4th Gen) | 568 (4th Gen) | 456 |
| RT Cores | 142 (3rd Gen) | 142 (3rd Gen) | – |
| GPU Memory | 48GB GDDR6 with ECC | 48GB GDDR6 with ECC | 80GB HBM2e |
| Memory Bandwidth | 864 GB/s | 864 GB/s | 2 TB/s |
| Memory Interface | 384-bit | 384-bit | 5120-bit |
| Max Power Consumption | 300W | 350W | 350W |
| Form Factor | 4.4″ H x 10.5″ L: Dual Slot | 4.4″ H x 10.5″ L: Dual Slot | 4.4″ H x 10.5″ L: Dual Slot |
| Thermal Solution | Passive | Passive | Passive |
| Display Connectors | 4x DisplayPort 1.4a | 4x DisplayPort 1.4a | – |
| PCIe Interface | Gen4 x16 | Gen4 x16 | Gen5 x16 |
| Power Connector | 16-pin | 16-pin | 16-pin |
| vGPU Support | Yes | Yes | No |
| Multi-Instance GPU (MiG) | No | No | Yes |
| NVLink Support | No | No | No |
Performance Specifications
| Metric | L40 Performance | L40S Performance | H100 Performance |
| FP32 Performance | 90.5 TFLOPS | 91.6 TFLOPS | 51.2 TFLOPS |
| TF32 Tensor Core | 362.1 TFLOPS | 366 TFLOPS | 756 TFLOPS |
| FP16 Tensor Core | 724 TFLOPS | 733 TFLOPS | 1513 TFLOPS |
| FP8 Tensor Core | 1,448 TFLOPS | 1,466 TFLOPS | 3026 TFLOPS |
| Peak INT8 Tensor TOPS | 1,448 TFLOPS | 1,466 TFLOPS | 3026 TOPS |
| RT Core Performance | 209 TFLOPS | 212 TFLOPS | – |
(Performance numbers are with sparsity)
NVIDIA L40S vs. H100
A detailed look at the specifications reveals the distinct design philosophies behind the NVIDIA L40S and H100. The L40S is built on the Ada Lovelace architecture, using the same AD102 die found in NVIDIA’s high-end workstation graphics cards. This heritage gives it a massive count of 18,176 CUDA cores, leading to great single-precision FP32 performance, which is a cornerstone of traditional graphics rendering and scientific computing. In contrast, the H100’s Hopper architecture and GH100 die are purpose-built for AI and HPC workloads over all else.
The most telling differentiator is the core configuration. The L40S includes 142 third-generation RT Cores and 568 fourth-generation Tensor Cores. The RT Cores are specialized hardware for accelerating ray tracing, a feature entirely absent from the H100, making the L40S uniquely capable of photorealistic rendering. While the H100 has fewer Tensor Cores, they are faster and more advanced, optimized for new AI data formats like FP8, giving it a commanding lead in raw AI performance.
This trade-off is also evident in the memory subsystems. The H100 utilizes 80GB of high-cost HBM2e memory, delivering a staggering 2 TB/s of bandwidth. This is essential for keeping the SMs fed during large-scale AI model training and inference. The L40S employs a more conventional 48GB of GDDR6 memory, providing 864 GB/s of bandwidth. While less than half that of the H100, this is still a substantial amount, perfectly adequate for loading large 3D scenes, high-resolution textures, and sizeable AI models for inference.
Finally, the feature set outlines their intended roles. The L40S includes four DisplayPort 1.4a outputs and robust vGPU support, making it ideal for virtualized workstations, render farms, and cloud gaming deployments. The H100, lacking any display outputs or vGPU capabilities, instead offers Multi-Instance GPU (MiG) technology, which allows it to be partitioned into multiple smaller, isolated GPU instances to serve multiple compute-intensive workloads simultaneously. The shared dual-slot, passive thermal design and 350W power envelope of the L40S and PCIe H100 allow for deployment flexibility in a wide range of industry-standard servers.
When comparing the L40S to NVIDIA’s flagship H100, the differences in their intended roles become clear. The H100 is the undisputed leader in raw AI training performance of that generation of GPUs, but this comparison only tells part of the story. It’s worth noting that the L40 is also part of NVIDIA’s lineup, with a lower 300W TDP compared to the L40S’s 350W power envelope, offering similar capabilities at reduced power consumption.

The H100 we’re examining here is the original 80GB PCIe version with HBM2e memory. NVIDIA has since expanded this lineup with variants like the H100 NVL, which serves as the replacement for the original 80GB PCIe model, offering 94GB of memory and a higher 400W TDP while adding NVLink support for dual-GPU configurations. The H100 family also extends to 8-GPU SXM configurations and the newer H200, which shares the same GPU die but delivers enhanced performance in both PCIe and SXM form factors.

The distinction between the L40S and H100 highlights a strategic divergence in data center GPU design. The H100 is a pure compute-focused card, optimized exclusively for AI and high-performance computing workloads. The target is large-scale AI training, where maximum computational throughput is the primary goal. Every aspect of its design, from the massive HBM2e memory bandwidth to the specialized Tensor Cores, is engineered for the most demanding neural network training scenarios.
In contrast, the L40S is a universal GPU designed for versatility, targeting AI inference alongside graphics-intensive workloads and NVIDIA vGPU deployments. While it serves as a competent and cost-effective solution for AI inference, its true strength lies in supporting a diverse range of graphics-intensive applications that the H100 is just not built for.
Graphics-Intensive Workloads and Professional Applications
The L40S excels in numerous graphics-intensive domains that require both computational power and advanced rendering capabilities. In 3D rendering and animation, studios rely on the L40S for complex scene rendering, where its RT Cores accelerate ray tracing calculations that would be impossible on compute-only GPUs. Film and television production houses use these capabilities for real-time previsualization, allowing directors and cinematographers to see photorealistic renders of CGI scenes during filming, dramatically reducing post-production time and costs.
Architecture and engineering firms leverage the L40S for real-time architectural visualization and product design, where clients can walk through photorealistic building renderings or examine detailed product prototypes before physical construction begins. The card’s professional graphics capabilities also make it ideal for CAD workstations, where engineers need both the computational power for complex simulations and the graphics acceleration for smooth, high-fidelity viewport performance.

In the media and entertainment sector, the L40S powers render farms that process final-quality animation frames. At the same time, its vGPU capabilities enable cloud-based creative workflows where artists can access powerful graphics workstations remotely. Video editing and post-production facilities use the L40S for real-time effects processing, color grading, and compositing workflows that demand both graphics acceleration and substantial computational resources.
The virtual desktop infrastructure (VDI) market represents another key application area, where the L40S’s vGPU technology enables multiple users to share GPU resources for graphics-accelerated virtual desktops. This makes professional graphics capabilities accessible in enterprise environments without dedicating individual GPUs to each user.
The Evolution Toward Physics-Based AI Training
More importantly, the L40S provides capabilities that the H100 completely lacks. The key differentiator lies in the L40S’s 142 third-generation RT Cores, which enable real-time ray tracing and photorealistic rendering. While the H100 has no RT cores and cannot perform graphics acceleration, the L40S’s RT cores make it the clear choice for applications requiring both AI computation and advanced graphics.

Source: Nvidia
This distinction becomes increasingly critical as we witness the rising popularity of AI-generated 3D modeling, digital twin simulations, and Universal Scene Description (OpenUSD) workflows. The next frontier in artificial intelligence isn’t just about training larger language models; it’s about developing world models that understand physics, spatial relationships, and real-world interactions. This evolution requires a fundamental shift in how we approach training data generation.
While training traditional AI models relies heavily on NVIDIA’s flagship compute GPUs, training the next generation of physically-grounded world models requires a different approach. These advanced AI systems need vast amounts of training data that capture not just visual information, but also physical properties, lighting behavior, material interactions, and spatial relationships. GPUs like the L40S become essential for large-scale training data generation, where their RT Cores enable the creation of physically accurate synthetic environments that serve as the foundation for training more sophisticated AI models.
This capability for advanced graphics rendering, powered by the dedicated RT Cores, is precisely what makes the L40S the ideal engine for NVIDIA’s Omniverse platform and the broader ecosystem of physics-based AI development.
Omniverse
Omniverse is a development platform of APIs, SDKs, and services that allows developers to build applications and workflows based on Universal Scene Description (OpenUSD). It’s designed to create and connect physically accurate, real-time 3D virtual worlds. This is achieved by integrating NVIDIA’s RTX technology for photorealistic, ray-traced rendering directly into industrial and robotic simulation workflows. The L40S, with its powerful RT Cores, provides the essential hardware acceleration to drive these demanding RTX rendering workloads, allowing developers to simulate light, materials, and physics with stunning realism.
More than just a visualization tool, Omniverse is a platform for developing the next generation of physical AI. By creating these true-to-reality virtual worlds, or “digital twins,” developers can simulate complex industrial facilities, test entire fleets of robots, and validate autonomous vehicles in a safe, virtual setting before real-world deployment. Crucially, these high-fidelity simulations become the foundation for generating vast amounts of physically-based synthetic data; a critical resource for training the powerful AI models that run on compute-focused GPUs.
Synthetic Manipulation Motion Generation for Robotics
The NVIDIA Isaac GR00T blueprint for synthetic manipulation motion generation provides a framework for robotics training, demonstrating how the L40S’s RT Core capabilities enable the creation of large datasets from minimal human demonstrations. This workflow addresses one of the key challenges in robotics development: the time-consuming and expensive process of collecting sufficient high-quality training data for robot manipulation tasks.
Traditional robotics training relies heavily on supervised or imitation learning, where robots acquire new skills by observing and mimicking expert human demonstrations. However, creating perfect demonstrations is challenging, and collecting extensive, high-quality datasets in the real world is tedious, time-consuming, and expensive. A properly trained human operator typically takes about one minute to record a single high-quality demonstration, which is difficult to scale due to the significant human effort required and the potential for errors.
The Isaac GR00T blueprint addresses this challenge by leveraging synthetic data generated from physically accurate simulations to accelerate the data-gathering process. Organizations can collect exponentially more data from just a couple of hours of human demonstrations.
The Isaac GR00T blueprint consists of three key components that work together to create a comprehensive synthetic data generation pipeline:
- GR00T-Teleop enables skilled human operators to control virtual robots using spatial computing devices such as the Apple Vision Pro. This system allows operators to demonstrate complex manipulation tasks in photorealistic virtual environments, capturing not only the motion trajectories but also the environmental context and object interactions. The Apple Vision Pro streams hand tracking data to Isaac Lab, which simultaneously streams an immersive view of the robot’s environment back to the device, enabling intuitive and interactive control of the robot.
- GR00T-Mimic takes the recorded demonstrations and multiplies them into larger synthetic datasets using advanced simulation techniques. This component uses the recorded demonstrations as input to generate additional synthetic motion trajectories in Isaac Lab, supporting both single-arm and bi-manual humanoid robot manipulation. The process involves annotating key points in the demonstrations and using interpolation to ensure that the synthetic trajectories are smooth and contextually appropriate.
- GR00T-Gen leverages the NVIDIA Omniverse and Cosmos platforms to expand synthetic datasets through 3D upscaling and domain randomization. This component adds additional diversity by randomizing background, lighting, and other variables in the scene. It augments the generated images through NVIDIA Cosmos Transfer, achieving photorealism that helps reduce the simulation-to-real gap.
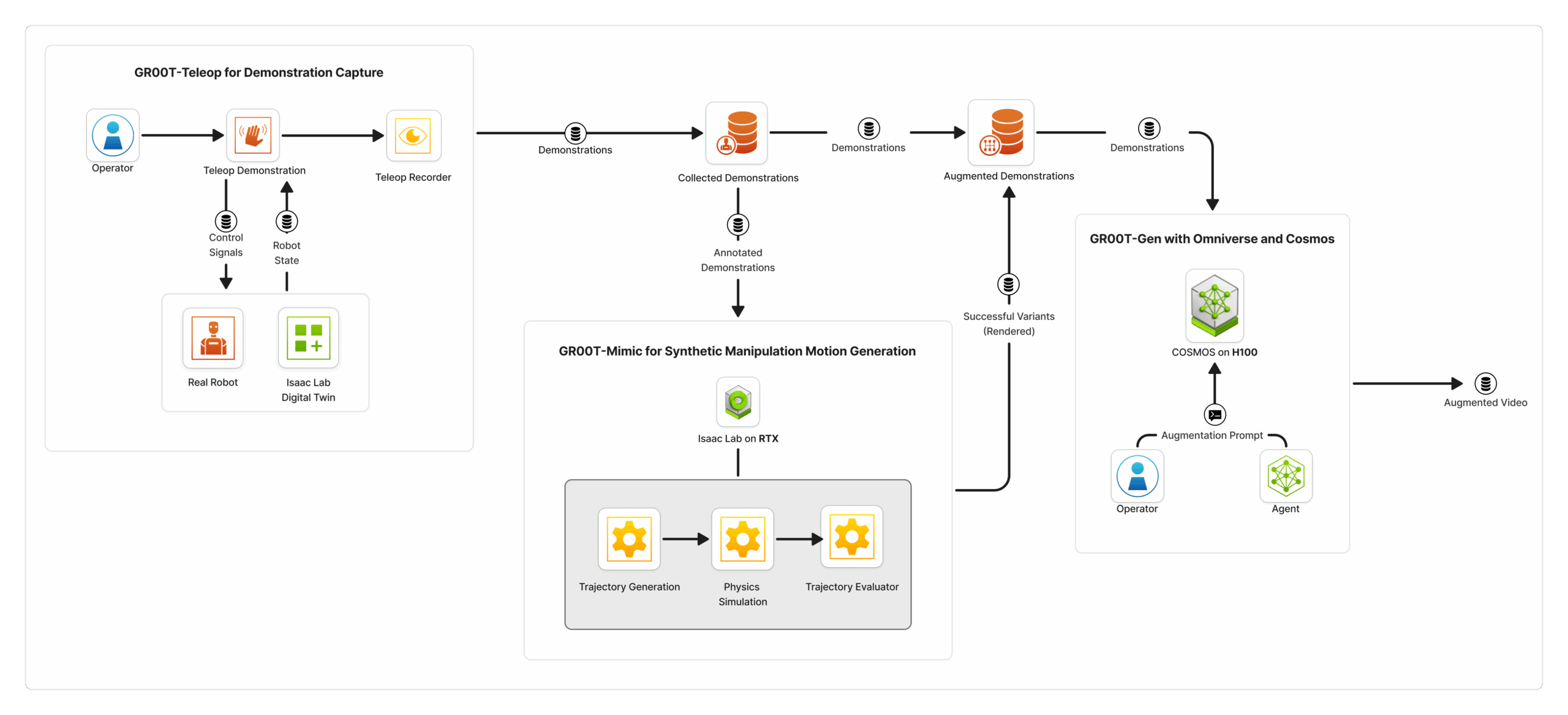
This pipeline perfectly illustrates the specialized, complementary roles of modern data center GPUs. The L40S, with its dedicated RT Cores, serves as the world-builder. It is indispensable for the initial stages of data generation, where it handles the physically-based rendering, real-time ray tracing, and domain randomization needed to create a photorealistic and diverse virtual environment.
This high-fidelity virtual world then becomes the canvas for the next stage of generation. Generative AI models, like those within NVIDIA Cosmos, are run on compute-centric GPUs like the H100 to produce the final training data. The H100 leverages the realistic environment crafted by the L40S to generate millions of dynamic, physically-aware scenarios.
AI Inference Performance Benchmarks
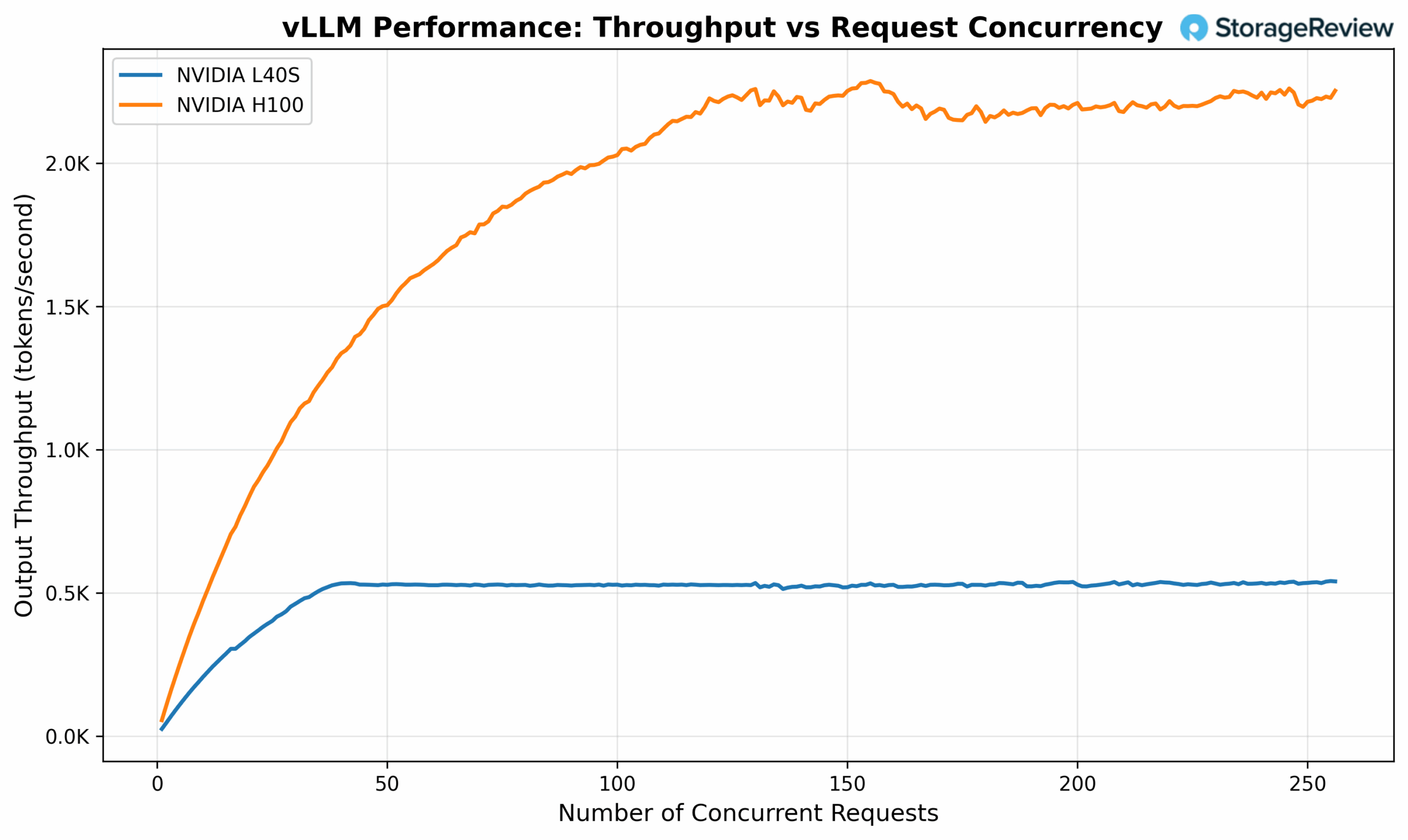
Another use case where cards like the L40S are popular is for cost-efficient inferencing. To evaluate the real-world AI inference capabilities of the L40S compared to the H100, we benchmarked LLM performance using vLLM running Nvidia’s Open Reasoning Nemotron 14B parameter model at BF16 with 32K max token length.
vLLM Benchmark Results
The H100 demonstrates clear performance leadership, delivering approximately 4.2x higher throughput than the L40S. This advantage stems directly from the H100’s doubled Tensor Core performance and more than doubled memory bandwidth (2 TB/s vs 864 GB/s).
However, performance per dollar tells a different story. The L40S typically costs less than one-third the price of an H100, making it more cost-effective for many inference workloads. Organizations running inference services where absolute peak performance isn’t critical often find the L40S provides better total cost of ownership.
Double clicking into the section with linear performance, we see L40S delivers a very acceptable level of performance, being able to serve 16 concurrent requests with ~52ms TPOT (Time Per Output Token) SLO.
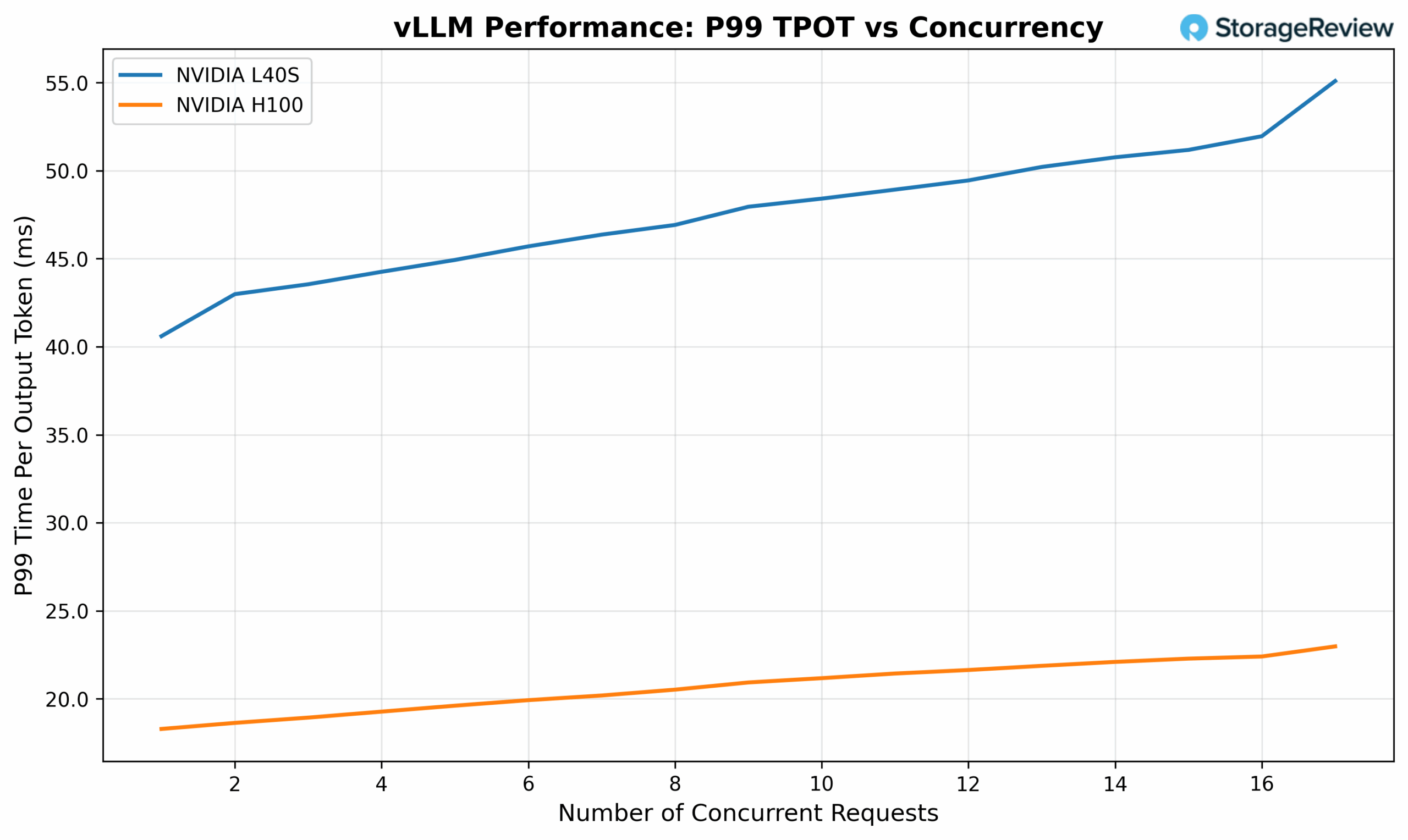
An important factor to note is that AI inference, particularly the decode phase of text generation, is fundamentally a memory bandwidth-intensive operation. During inference, the model must repeatedly access weights stored in GPU memory to generate each new token, making memory throughput a critical performance bottleneck. This characteristic explains why the H100, with its superior memory bandwidth and enhanced Tensor Core performance, naturally achieves higher inference throughput.
However, for deployment scenarios requiring both AI inference and graphics acceleration, such as real-time rendering with AI-enhanced effects, interactive applications with AI-powered features, the L40S becomes the only viable option.
Conclusion
The NVIDIA L40S and the latest Blackwell RTX Pro 6000 successors emerge as a strategically positioned GPU that addresses the evolving demands of modern data centers, where AI computation and advanced graphics capabilities increasingly converge. While the H100 and B200 classes of GPUs remain the undisputed leaders for pure AI training and inference workloads, the L40S carves out a distinct and valuable niche as a universal GPU that bridges the gap between compute-focused AI cards and traditional professional visualization solutions.
The L40S’s unique value proposition becomes most apparent in scenarios that demand both AI inference capabilities and graphics acceleration. Its 142 third-generation RT Cores enable applications that are simply impossible on compute-only GPUs like the H100, from real-time ray tracing in professional workflows to photorealistic synthetic data generation for next-generation AI training. This dual capability makes it indispensable for emerging applications in digital twin development, physics-based AI training, and the growing Omniverse ecosystem.
From an economic perspective, the L40S offers compelling value for organizations that don’t require the absolute peak AI performance of the H100. At approximately one-third the cost of an H100, the L40S delivers respectable inference performance while providing graphics capabilities that add tremendous versatility to data center deployments. For many organizations, this combination of cost-effectiveness and versatility makes the L40S a more practical choice than investing in separate AI and graphics solutions.


 Amazon
Amazon