

Axle AI delivers real-time edge video workflows with AI tagging, powered by HPE DL145 G11, Solidigm Gen5 SSDs, and NVIDIA L4 GPU.
The demand for rapid, high-quality video content has never been greater. In today’s media landscape, small news teams, independent content creators, and event production crews are expected to capture, edit, and publish professional-grade footage in real time, often without the support of a post-production team or centralized infrastructure.
That’s why on-premise AI search, delivered through edge-based production systems, is becoming a must-have, as the amount of footage explodes and the need for reuse increases. By enabling teams to work directly with footage at the point of capture, edge workflows eliminate bottlenecks and empower creators to spend less time hunting for and managing footage, and more time producing the best possible content.

Axle AI, an AI-powered media asset management and automation platform, is designed specifically for this decentralized, fast-paced workflow. When combined with industry-leading hardware, such as the HPE ProLiant DL145 Gen11 server, an NVIDIA L4 GPU, and Solidigm PCIe Gen5 SSDs, the result is a powerful, portable production environment. It brings professional AI-assisted media capabilities to even the leanest teams.
System Architecture Overview
The HPE ProLiant DL145 Gen11 edge server is a strong candidate for Axle AI deployments in field and event environments where space, power, and cooling are limited. With its 2U short-depth design measuring just 16 inches deep, this server is purpose-built for portability and installation in tight spaces such as mobile racks and flight cases. Unlike traditional enterprise gear, it supports an extended operating temperature range of -5°C to 55°C, making it suitable for less controlled environments. Despite its compact size, it offers enterprise-class features such as redundant power and boot drive options, making it ideal for teams that need robust, edge-capable infrastructure without the overhead of full-sized hardware.

On the CPU side, the DL145 supports AMD EPYC 8004 (Siena) series processors, with support for eight to 64 cores. Our test system is equipped with the EPYC 8434P, offering 48 cores and 96 threads. With a 200W TDP, it strikes a strong balance between efficiency and computational power, making it ideal for intensive workloads. The processor supports 96 lanes of PCIe 5.0 and offers six channels of DDR5 memory, enabling speeds up to 4800 MT/s with excellent memory bandwidth. While the minimum requirements for Axle AI call for at least 16 CPU cores and 32GB of RAM, our configuration comfortably exceeds these requirements with 48 cores and 256GB of DDR5 memory.

Storage performance is critical in any media pipeline, and the DL145 supports up to six EDSFF E3.S NVMe drives to meet these demands. In our configuration, we used six Solidigm D7-PS1010 E3.S SSDs, each with a capacity of 7.68 TB. These PCIe 5.0 x4 drives deliver up to 14,500 MB/s read and 10,000 MB/s write speeds, combining for nearly 46 TB of high-speed storage. Designed for AI and media workflows, these SSDs offer impressive energy efficiency and can deliver up to 50% higher throughput in specific pipeline phases compared to conventional NVMe drives. For teams requiring additional capacity, this setup can scale up to 15.36 TB per drive, providing a combined 92 TB of fast, dense storage in a compact form factor.

The DL145 supports up to three single-slot GPUs, and in our configuration, we deployed a single NVIDIA L4, a power-efficient accelerator built on the Ada Lovelace architecture. Designed for video processing, AI inference, visual computing, and virtualization workloads, the L4 delivers robust performance while consuming just 72 watts. It features 24 GB of GDDR6 VRAM and connects via a PCIe 4.0 x16 interface for both power and data. Axle AI recommends a minimum of 16 GB of VRAM, and the L4 comfortably exceeds this with an additional 8 GB, ensuring headroom for high-resolution media tasks and AI-driven operations.

Nvidia L4 single-slot GPU
For the application layer, we deployed Axle AI MAM and Axle AI Tags using Proxmox Virtual Environment (8.3.5). The system is configured with two dedicated virtual machines: one running the Axle AI MAM and the other running Axle AI Tags. This structure provides a clean separation between media management and AI-powered metadata processing, while still allowing seamless communication between components.
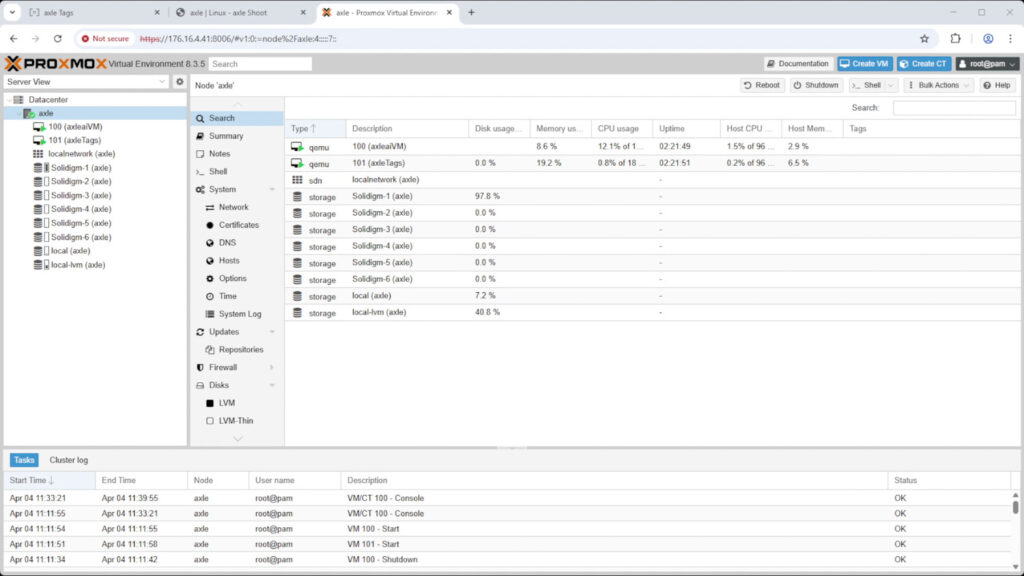
Summary of Proxmox Environment and Hardware
Running alongside MAM, Axle AI Tags brings on-premise AI capabilities, including semantic vector search, object and logo recognition, and trainable face detection. It’s deployed in a Docker container and leverages the NVIDIA L4 GPU through PCIe pass-through for efficient, real-time inference. The browser-based training and admin interface allows flexible tuning, and its modular design supports Intel/NVIDIA or AMD/NVIDIA hardware configurations. While fully integrated with MAM in our setup, Axle AI Tags also offers REST API compatibility for use with other platforms.
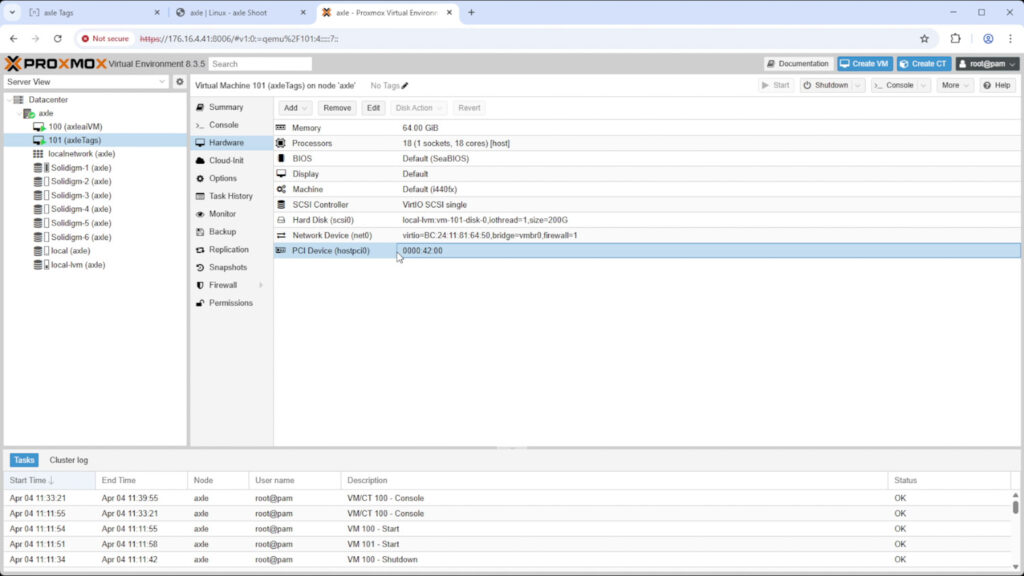
Hardware Configuration of Axle AI Tags virtual machine
The Solidigm PS1010 drives are mounted into the Axle AI MAM virtual machine, ensuring high-speed, low-latency access to footage. By virtualizing the entire stack and assigning dedicated compute resources to each component, this setup delivers higher uptime, better resource management, and multi-user support far beyond what a single workstation could offer. This makes it ideal for a collaborative, high-volume production environment.
Together, these components form a tightly integrated hardware solution that enables fast, local, AI-powered media workflows. It’s an efficient, field-ready platform for remote teams that require reliable performance where space and power are limited, yet where AI processing remains essential.
HPE ProLiant DL145 Gen11 Performance
Before diving into benchmarking, the table below outlines the system configuration of the HPE ProLiant DL145 Gen11. While testing with Axle AI was performed on a virtualized installation running Proxmox, the system was transitioned to Ubuntu Server 22.04.5 to measure the storage performance in our GDSIO and FIO tests.
| HPE ProLiant DL145 Gen 11 | Hardware Overview |
|---|---|
| CPU | Single AMD EPYC 8434P |
| RAM | 256GB ECC DDR5 |
| Storage | 6x Solidigm D7-PS1010 E3s SSDs 7.68tb |
| Boot Storage | NS204 port 2x populated (480GB Samsung PM9A3 M.2) |
| GPU | Single NVIDIA L4 |
| Operating System | Ubuntu Server 22.04.5 |
Peak Synthetic Performance
The FIO test is a flexible and powerful benchmarking tool used to measure the performance of storage devices, including SSDs and HDDs. It evaluates metrics such as bandwidth, IOPS (Input/Output Operations Per Second), and latency under various workloads, such as sequential and random read/write operations. This test is designed to capture peak performance and stress the storage system across multiple workloads, making it particularly useful for comparing different devices or configurations. In this case, a full-surface test was executed, exercising the entire capacity of the drives to provide a comprehensive view of their sustained performance characteristics.
In the sequential read test using 128K blocks, the system delivered a bandwidth of 56.4 GB/s and sustained 430,000 IOPS with an average latency of 1.78 milliseconds. Sequential write performance at the same block size reached 45.4 GB/s, producing 346,000 IOPS and an average latency of 2.22 milliseconds. For random read operations using 4K blocks, the system achieved 46.6 GB/s with 11.4 million IOPS and a low average latency of 0.269 milliseconds, highlighting the high-throughput potential of the NVMe storage array under intensive access patterns. Random write operations at 4K measured 29.1 GB/s, reaching 7.1 million IOPS with an average latency of 0.432 milliseconds, confirming solid sustained write capability even under fragmented access.
| HPE DL145 Gen 11 FIO Benchmark Summary | Bandwidth – GB/s | IOPS | Avg Latency |
|---|---|---|---|
| Sequential Read (128K) | 56.4 GB/s | 430k | 1.78 ms |
| Sequential Write (128K) | 45.4 GB/s | 346k | 2.22 ms |
| Random Read (4KB) | 46.6 GB/s | 11.4M | 0.269 ms |
| Random Write (4K) | 29.1 GB/s | 7.1M | 0.432 ms |
GPU Direct Storage
One of the tests we conducted on this testbench was the Magnum IO GPU Direct Storage (GDS) test. GDS is a feature developed by NVIDIA that allows GPUs to bypass the CPU when accessing data stored on NVMe drives or other high-speed storage devices. Instead of routing data through the CPU and system memory, GDS enables direct communication between the GPU and the storage device, significantly reducing latency and improving data throughput.
How GPU Direct Storage Works
Traditionally, when a GPU processes data stored on an NVMe drive, the data must first travel through the CPU and system memory before reaching the GPU. This process introduces bottlenecks, as the CPU becomes a middleman, adding latency and consuming valuable system resources. GPU Direct Storage eliminates this inefficiency by enabling the GPU to access data directly from the storage device via the PCIe bus. This direct path reduces the overhead associated with data movement, allowing faster and more efficient data transfers.

AI workloads, especially those involving deep learning, are highly data-intensive. Training large neural networks requires processing terabytes of data, and any delay in data transfer can lead to underutilized GPUs and longer training times. GPU Direct Storage addresses this challenge by ensuring that data is delivered to the GPU as quickly as possible, minimizing idle time and maximizing computational efficiency.
In addition, GDS is particularly beneficial for workloads that involve streaming large datasets, such as video processing, natural language processing, or real-time inference. By reducing the reliance on the CPU, GDS accelerates data movement and frees up CPU resources for other tasks, further enhancing overall system performance.
GDSIO Read Sequential
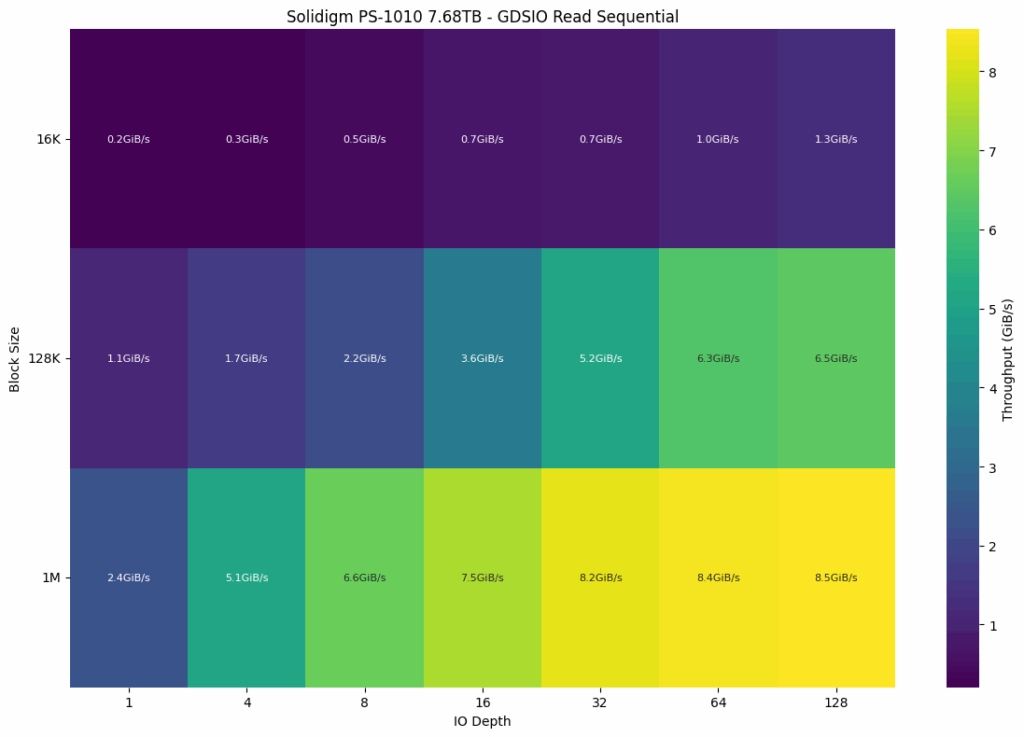
In the GDSIO sequential read test of the Solidigm PS1010 7.68TB drive, performance scaled significantly with both block size and I/O depth. At the smallest 16K block size, throughput started at just 0.2 GiB/s at a queue depth of 1 and gradually rose to 1.3 GiB/s at a depth of 128, showing limited scalability at that granularity. Moving up to 128K blocks, performance improved more dramatically, beginning at 1.1 GiB/s and climbing to 6.5 GiB/s at the highest depth. The best results were obtained with a 1M block size, where throughput initially reached 2.4 GiB/s and peaked at 8.5 GiB/s at a queue depth of 128, indicating that the drive’s optimal performance profile is achieved with large sequential reads and deeper queues.
GDSIO Write Sequential
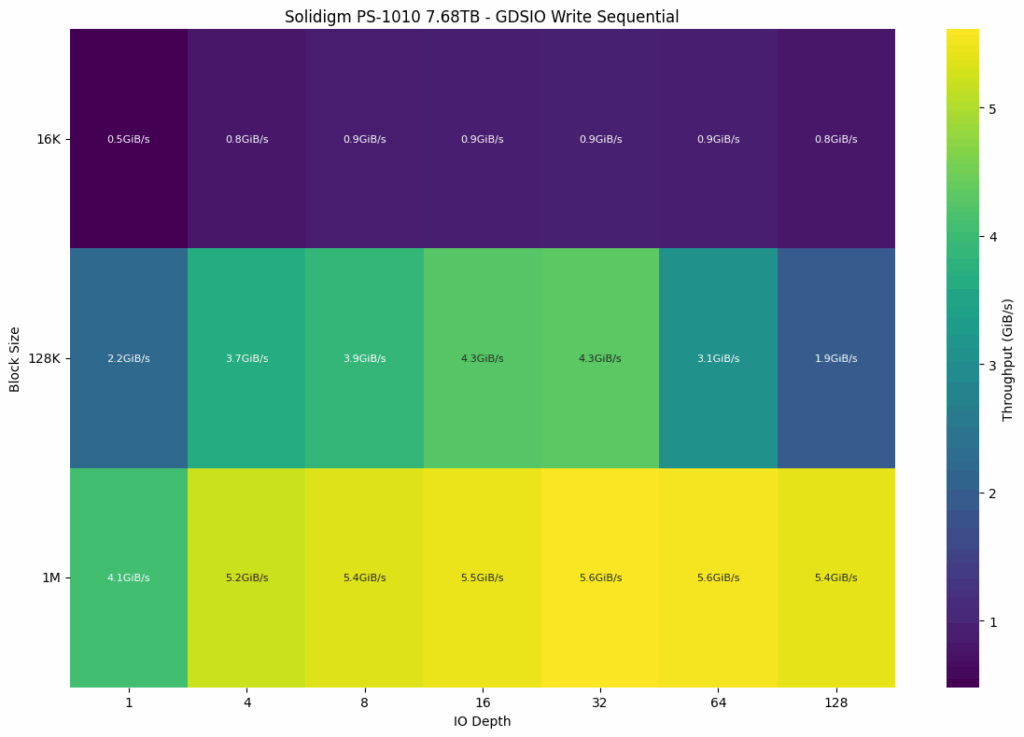
Sequential write performance on the Solidigm PS1010 exhibits solid scalability at larger block sizes, but shows some regression at higher queue depths in mid-sized workloads. At the smallest 16K block size, write speeds started at 0.5 GiB/s and peaked modestly at 0.9 GiB/s from queue depths 8 through 64, before dipping slightly to 0.8 GiB/s at depth 128. With 128K blocks, performance began at 2.2 GiB/s, improved to a high of 4.3 GiB/s at depth 32, then declined to just 1.9 GiB/s at the deepest queue, indicating potential write saturation or throttling. The best sustained performance was achieved with 1M block sizes, where throughput scaled cleanly from 4.1 GiB/s at depth 1 to 5.6 GiB/s at depths 32 and 64, remaining steady through 128.
GDSIO Summary
This table provides a clear breakdown of GDSIO performance metrics for latency and IOPS collected on the Solidigm D7-PS1010 SSD, measured at block sizes of 16K, 128K, and 1M with an IO depth of 128. At a queue depth of 128, latency and IOPS scale predictably with block size. The 16K block read averaged 1.549ms with 82.3K IOPS, while write latency was 2.429ms with 52.6K IOPS. With 128K blocks, read latency increased to 2.414ms (52.9K IOPS) and write latency to 8.050ms (15.9K IOPS). At 1M, read latency reached 14.643ms with 8.7K IOPS, and write latency rose to 23.030ms with 5.6K IOPS.
| GDSIO Chart (16K,128K,1M Block Size Averages) | HPE DL145 Gen 11 (6 x Solidigm D7-PS1010 E3s SSD 7.68TB) |
|---|---|
| (16K Block Size 128 IO Depth) Average Read | 1.3 GiB/s (1.549ms) IOPS: 82.3K |
| (16K Block Size 128 IO Depth) Average Write | 0.8GiB/s (2.429ms) IOPS: 52.6K |
| (128K Block Size 128 IO Depth) Average Read | 6.5 GiB/s (2.414ms) IOPS: 52.9K |
| (128K Block Size 128 IO Depth) Average Write | 1.9 GiB/s (8.050ms) IOPS: 15.9K |
| (1M Block Size 128 IO Depth) Average Read | 8.5 GiB/s (14.643ms) IOPS: 8.7K |
| (1M Block Size 128 IO Depth) Average Write | 5.4 GiB/s (23.030ms) IOPS: 5.6K |
Media Production at the Edge
What Is Axle AI?
Axle AI is an on-prem AI-powered media asset management (MAM) platform that simplifies video workflows for small and mid-sized media teams. It automates key tasks, such as ingest, tagging, and media search, without the cost or complexity of traditional MAM systems. Designed for speed and ease of use, Axle AI enables teams to manage and deliver content more efficiently, whether they’re in the office or working remotely.
The platform supports the whole production pipeline. It automatically ingests footage, creates proxies, applies AI-driven metadata using features such as object recognition, face detection, and semantic search, and integrates with industry-standard editing tools, including Adobe Premiere Pro and DaVinci Resolve. This allows teams to quickly locate, edit, and publish content without bottlenecks or delays.
Real-World Use Cases
Axle AI is trusted by a diverse range of media teams, including broadcasters, documentary filmmakers, corporate video departments, marketing agencies, and live event producers. These teams often work across multiple locations and require reliable access to their media libraries without the need for heavy infrastructure.
With Axle AI, users can collaborate remotely via a browser-based interface that provides instant access to proxy media. Editors can begin cutting footage immediately in their preferred non-linear editing systems (NLEs), while producers and stakeholders review, tag, or approve clips in real-time (no large file transfers or specialized technical skills required).
Whether you’re a team of five or fifty, Axle AI enables faster, more efficient workflows. Its simple interface, rapid deployment, and compatibility with existing storage systems make it a smart solution for high-volume, distributed media production.
The fervent demand for instant social media has dramatically increased the pace of media production. It’s a very “if you’re not first, you’re last” mentality, especially as it pertains to live events and the content creation around them. Media companies needed an efficient way to organize and quickly review large amounts of footage. Tools like Axle AI, with its ability to scale down to small operations, enable this workflow to be practical in the field. When paired with the proper workflow, like cameras that can record proxies and raw footage simultaneously, the opportunities for efficiency increase.
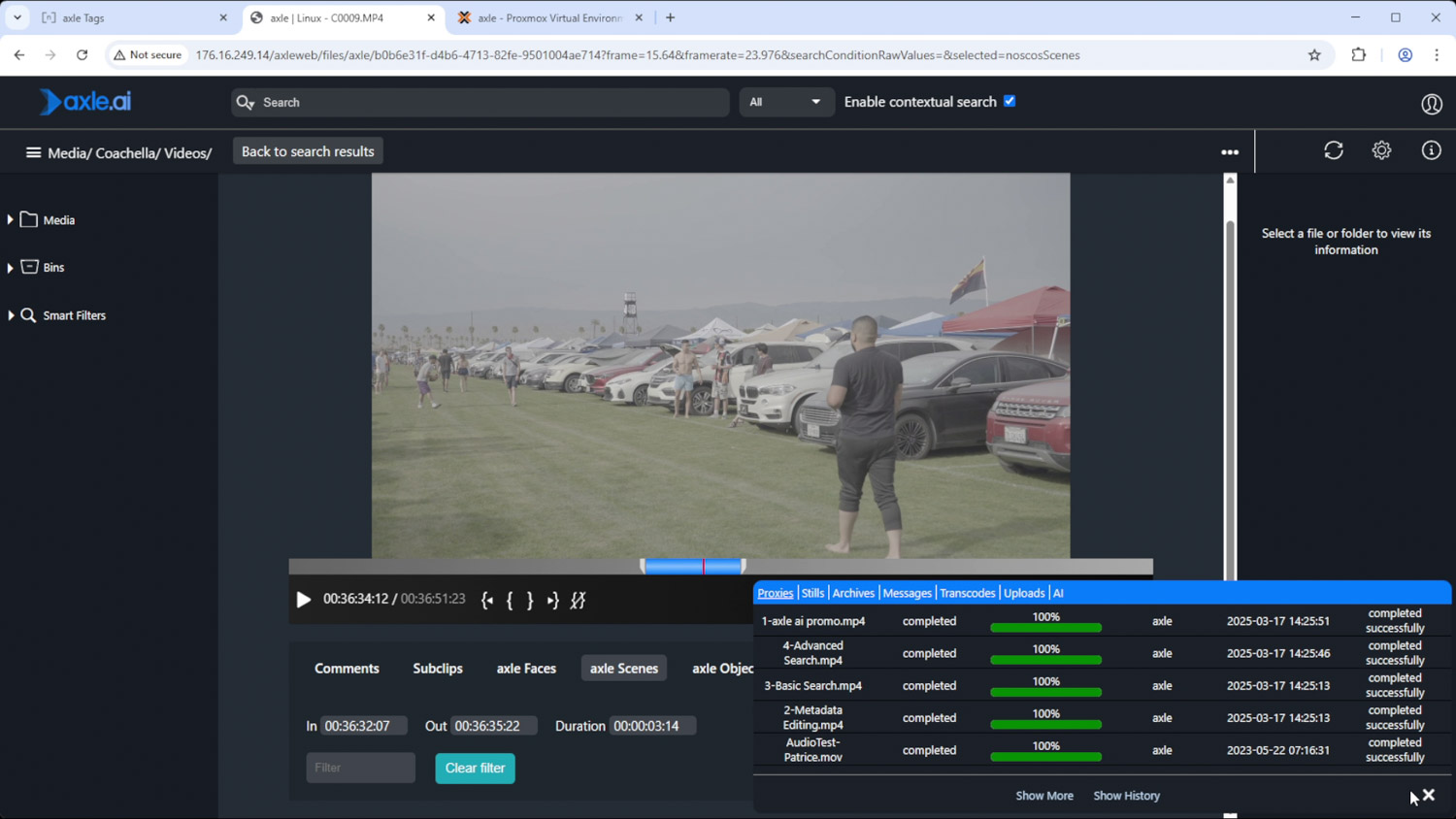
Saving both high-resolution and low-resolution proxy media on capture and processing smaller proxy files immediately in Axle AI Tags can make all the footage searchable almost instantly. Editors can get to work immediately with Axle AI’s integration with most major NLEs like Adobe Premiere Pro, DaVinci Resolve, and Avid Media Composer. It also takes a big lift off the shoulders of the production team, allowing them to focus on other tasks or avoid burnout.
Traditionally, logging has been one of the most laborious and most often skipped aspects of a media capture workflow. Axle AI logs media automatically with AI-generated scene descriptions instead of just traditional metadata fields, allowing an editor to read what a clip contains before taking the time to scrub through it. It also provides semantic search tools, enabling editors and producers to quickly find relevant material using concepts and themes, rather than relying on specific tags.
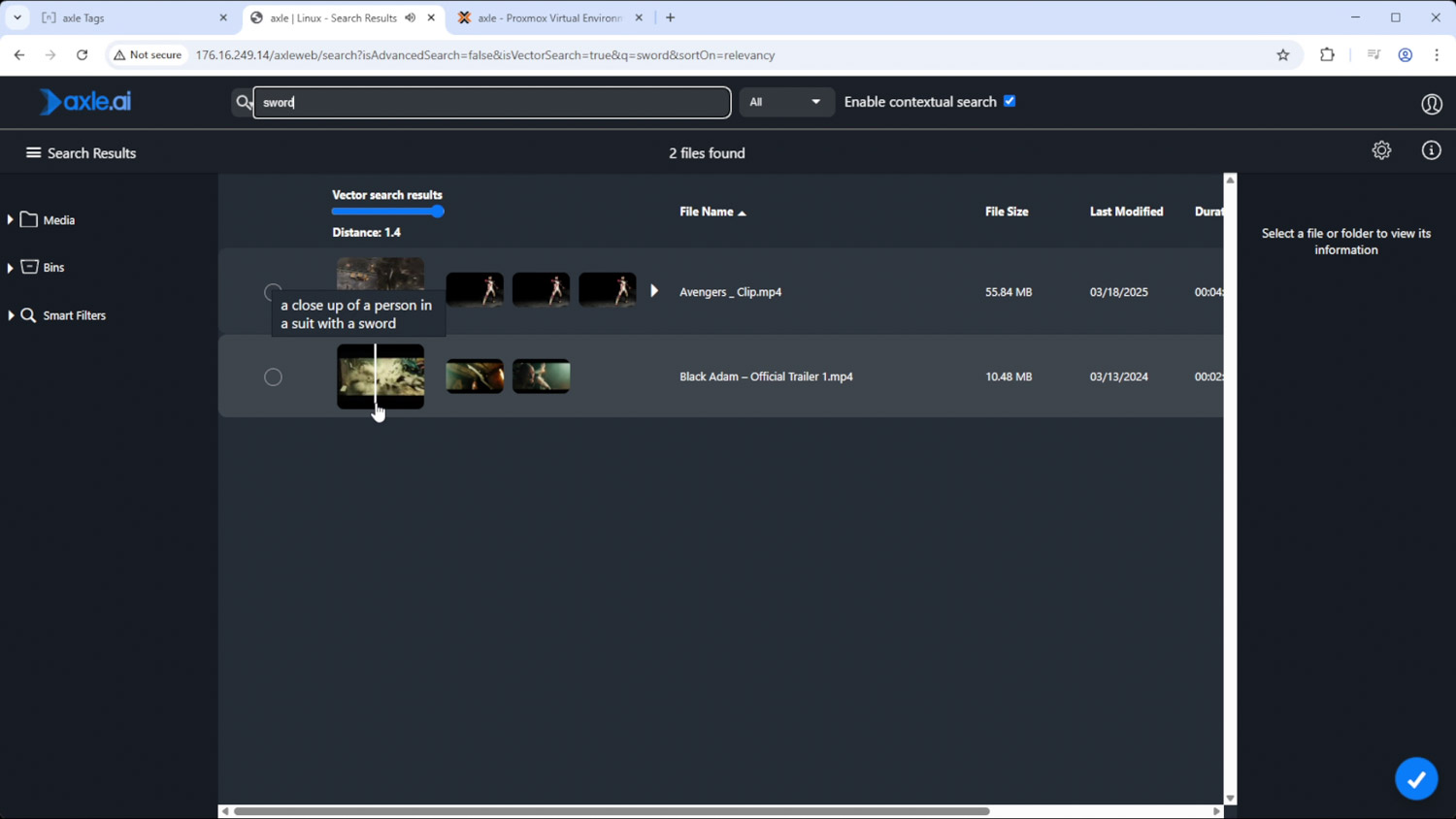
Scalability is also key, as not all jobs require fast-paced, on-site media production. Axle AI can be set up on a more powerful, stationary system with access to a media company’s backlog of footage over a network share. This enables editors and producers to find relevant media more quickly, or even discover media they may not have considered before that has been “lost” in the archives. Content creators and broadcasters can significantly benefit from this kind of backlog index, creating more value from media that would otherwise sit idle on a server. While certainly not foolproof, it can give media companies a head start on some of the most time-consuming aspects of the media creation process.
The HPE ProLiant DL145 Gen11 serves as the hardware foundation for this edge AI deployment, delivering an impressive balance of compute density, storage throughput, and GPU acceleration in a compact footprint. Powered by a 48-core AMD EPYC 8434P processor from the energy-efficient 8004 Series, this system is optimized for multithreaded workloads while maintaining a low-power envelope. The configuration includes 256GB of RAM and a single NVIDIA L4 GPU, a highly efficient accelerator well-suited for AI inference at the edge. Storage is provisioned with six Solidigm D7-PS1010 E3.S SSDs, each with a capacity of 7.68TB, providing ample high-performance flash storage for media assets and metadata-intensive workloads. With support for up to three single-wide GPUs and a total of six E3.S drives, the DL145 Gen11 is well-positioned to scale with demanding video and AI use cases. This setup emphasizes the importance of carefully assembling modern hardware components, including CPU, GPU, and SSDs, to enable exceptional performance for edge-focused AI workflows, such as those powered by Axle AI.
Conclusion
Axle AI is transforming the way video content is produced, particularly for teams working in real-time with limited resources. By combining intelligent media asset management with powerful inference tools, Axle AI enables a level of automation and responsiveness that traditional MAM systems can’t match. When paired with the HPE ProLiant DL145 Gen11 edge server, NVIDIA L4 GPU, and Solidigm Gen5 SSDs, the rig we built provides a compact, high-performance environment optimized for modern media workflows. Whether used in the field or as part of a hybrid editing pipeline, this configuration provides a scalable and efficient way to ingest, tag, search, and deliver video content faster than ever before, without compromising quality or control. For teams tasked with staying ahead in a fast-paced content landscape, the combination of edge infrastructure and AI-assisted workflows offers a significant competitive advantage.
Engage with StorageReview
Newsletter | YouTube | Podcast iTunes/Spotify | Instagram | Twitter | TikTok | RSS Feed