

Those in the market for a high-performance all-flash storage array, would be well met with the NetApp AFF A800. The end-to-end NVMe array delivers massive performance and comes from NetApp’s strong line of AFF arrays. We have previously reviewed the A800 over Fibre Channel and found it to be a beast of a performer netting our Editor’s Choice award. For this review we are testing the same array only this time leveraging NVMe over Fabrics (NVMeOF).

Since this is a follow up review we won’t be getting into things like design and build, specifications, or management. Our initial review goes well into each of those areas. The setup for the review is essentially the same with a different networking interface to see the performance difference. It should be noted that this isn’t exactly an apples to apples comparison. The array offers various connectivity for different users’ needs and we are reviewing different types to give those users an idea what to expect with which connectivity option.
First introduced in 2014, NVMeOF is the concept of using a transport protocol over a network versus just leveraging the NVMe devices through the PCIe bus. NVM Express, Inc. published the standard for NVMeOF in 2016. NVMeOF allows the NVMe host to connect to an NVMe target storage while keeping the latency low. The general idea is to get more performance without substantially adding to the latency. To date there have been many approaches from different vendors on which protocol is being supported, or of it can run in multiple modes at the same time. The ONTAP-equipped AFF A800 is capable of running CIFS, NFS, iSCSI, FCP and FC NVMeOF at the same time, all with barely breaking a sweat. Not all platforms are made this way, with even the NetApp EF600 (designed with slightly different goals in mind) can run in either FCP or FC NVMeOF, but not both at the same time.
Performance Configuration
The configuration of our NetApp AFF A800 included 8 32Gb FC ports with 24 1.92TB NVMe SSDs installed. Out of the 24 1.92TB SSDs deployed in our A800, we split them up into two RAID-DP Aggregates, with effectively 23 SSDs in use and two half partitions held as hot-spare. Half of each SSD is partitioned off to both controllers, so each controller can utilize the performance of all SSDs installed. The array was connected via 32Gb through two Brocade G620 switches, which then had 16 32Gb links to 12 Dell PowerEdge R740xd servers running SLES 12 SP4.
Each server was provisioned with 2 350GB LUNs, putting a total storage footprint of 8.4TB.
Performance
When it comes to benchmarking storage arrays, application testing is best, and synthetic testing comes in second place. While not a perfect representation of actual workloads, synthetic tests do help to baseline storage devices with a repeatability factor that makes it easy to do apples-to-apples comparison between competing solutions. These workloads offer a range of different testing profiles ranging from “four corners” tests, common database transfer size tests, as well as trace captures from different VDI environments. All of these tests leverage the common vdBench workload generator, with a scripting engine to automate and capture results over a large compute testing cluster. This allows us to repeat the same workloads across a wide range of storage devices, including flash arrays and individual storage devices.
Profiles:
- 4K Random Read: 100% Read, 128 threads, 0-120% iorate
- 4K Random Write: 100% Write, 64 threads, 0-120% iorate
- 64K Sequential Read: 100% Read, 16 threads, 0-120% iorate
- 64K Sequential Write: 100% Write, 8 threads, 0-120% iorate
- Synthetic Database: SQL and Oracle
The primary performance advantage of NVMeOF with the A800 is an increase to read performance and lower latency. With our previous tests focusing performance inside VMware using the FCP protocol, with VMDKs attached to multiple VMs, our NVMeOF tests focus on bare-metal performance. Therefore you can’t make a direct one-to-one comparison with our existing data. It is important to also note that for consistent testing across all of our storage arrays, we’ve kept the thread count the same for each storage array. With the NVMeOF testing on the A800, we did notice some areas where our test finished prior to a significant latency increase. First of all this shows that the platform is performing exceptionally well, driving low latency at impressive performance stats. The downside though is some amount of performance was left on the table. NetApp has stated that under certain circumstances the A800 can drive even higher performance that what we measured.
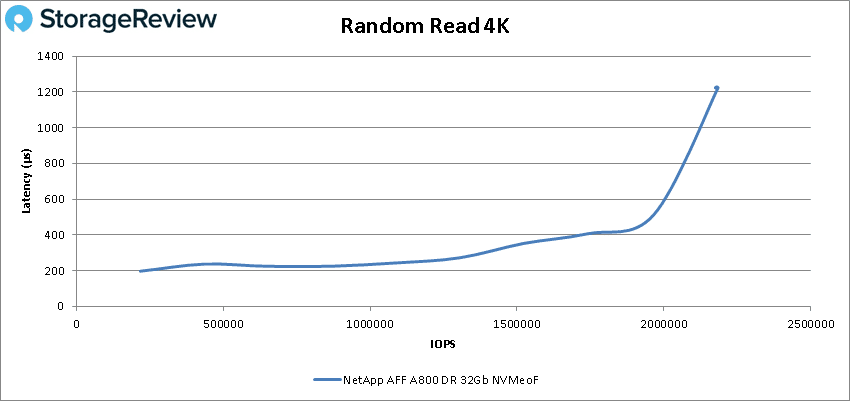
Starting with 4K read the A800 with NVMeOF started off at 217,460 IOPS with a latency of only 196.8µs and went on to peak at 2,184,220 IOPS with a latency of 1.22ms.
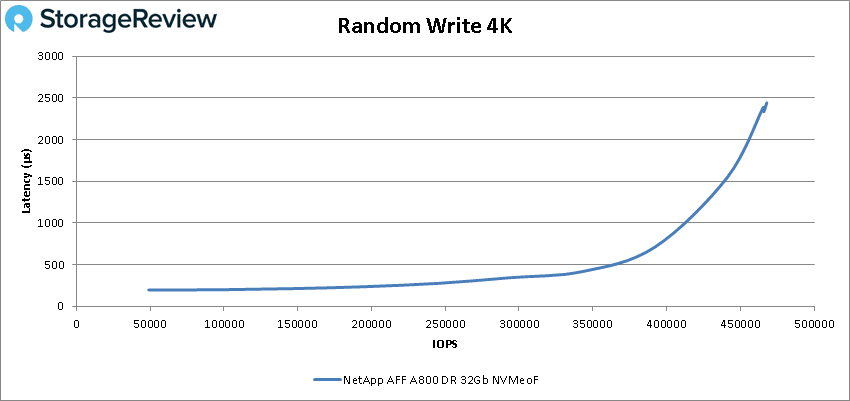
For 4K writes the array started at 48,987 IOPS with a latency of 196µs and went on to peak at 465,445 IOPS at a latency of 2.44ms.
Next up are our 64K sequential workloads. For 64K read the A800 was able to maintain sub-millisecond latency throughout with a peak performance of about 403K IOPS or 25GB/s with a latency of 800µs before a slight drop off.
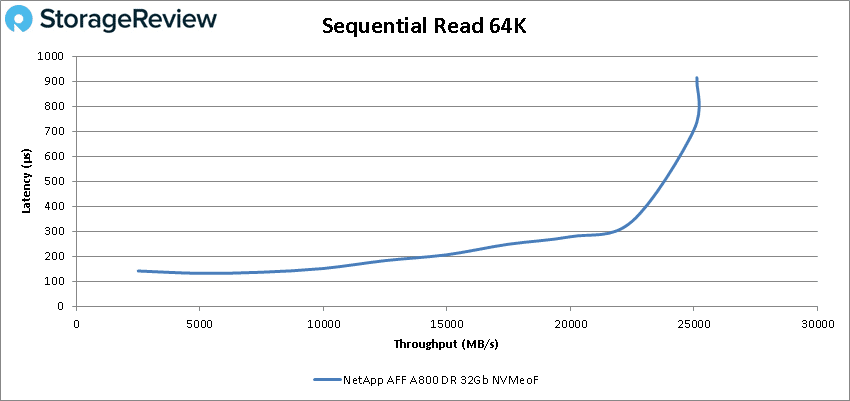
For 64K write the A800 with NVMeOF start strong and stayed under 1ms until about 110K IOPS or about 7GB/s and went on to peak at 120,314 IOPS or 7.52GB/s with a latency of 1.48ms.
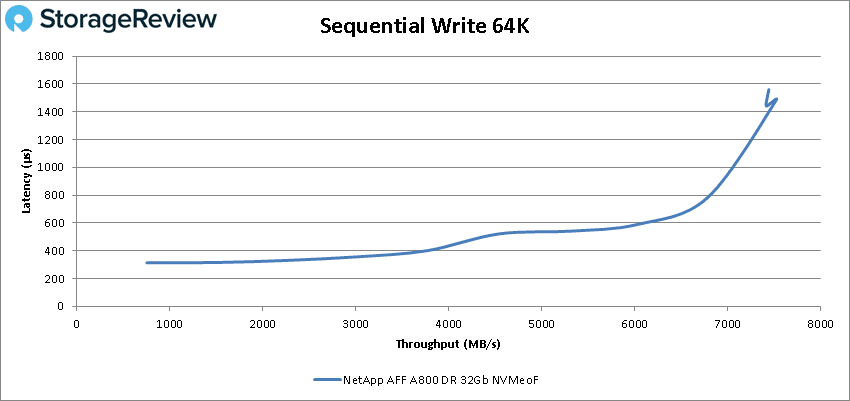
Our next batch of benchmarks are our SQL tests. In SQL the A800 stayed below 1ms throughout with an impressive peak of 1,466,467 IOPS at a latency of only 496.6µs.
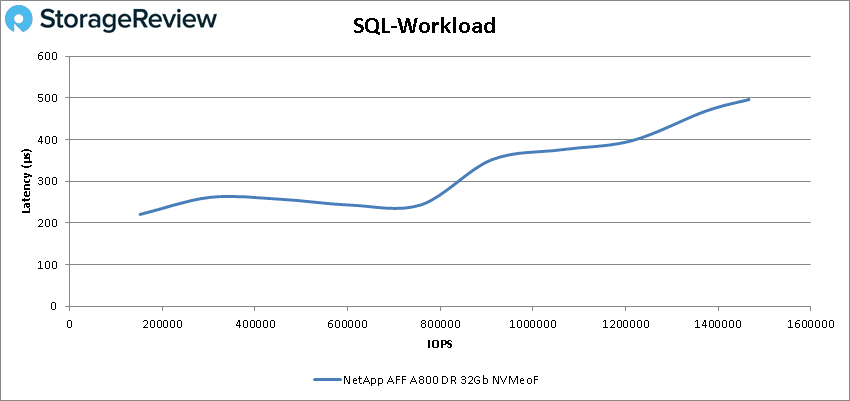
For SQL 90-10 the A800 with NVMeOF had another impressive run of sub-millisecond latency performance starting at 139,989 IOPS and peaking at 1,389,645 IOPS with a latency of just 539.6µs.
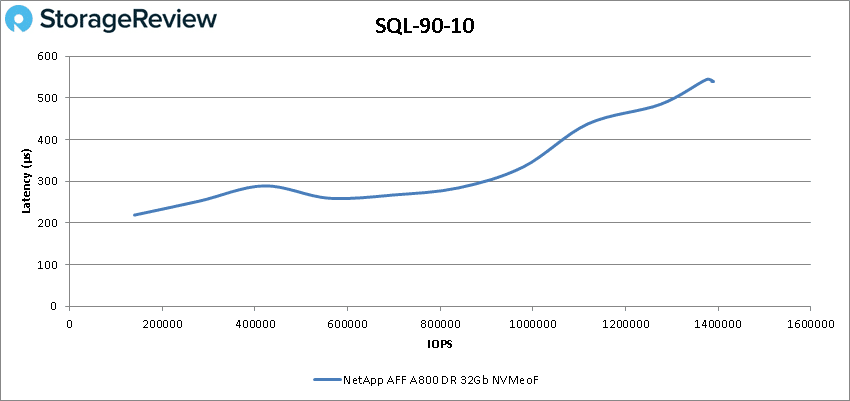
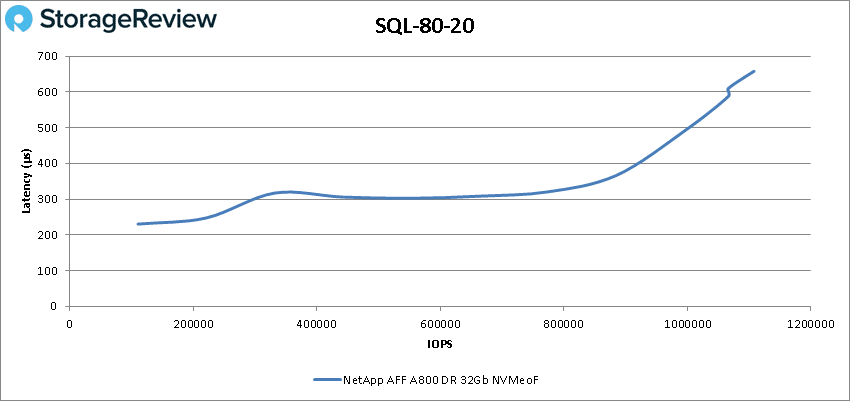
SQL 80-20 once again saw sub-millisecond latency throughout with a peak of 1,108,068 IOPS at 658µs latency.
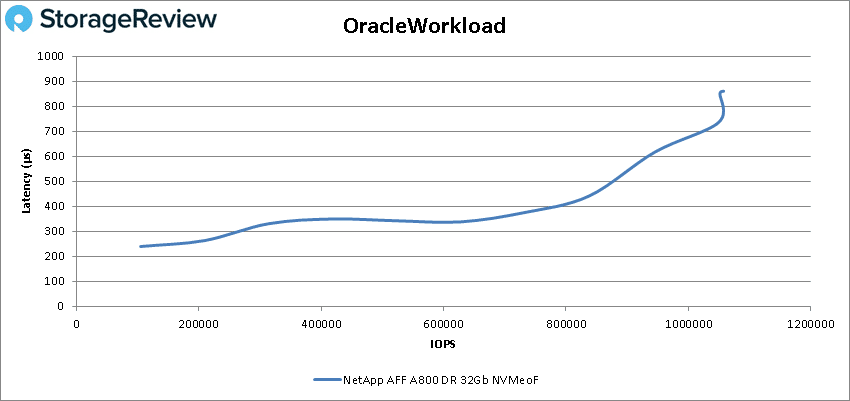
Moving on to our Oracle workloads, the A800 with NVMeOF stayed below 1ms with a peak score of 1,057,570 IOPS at a latency of 860.4µs.
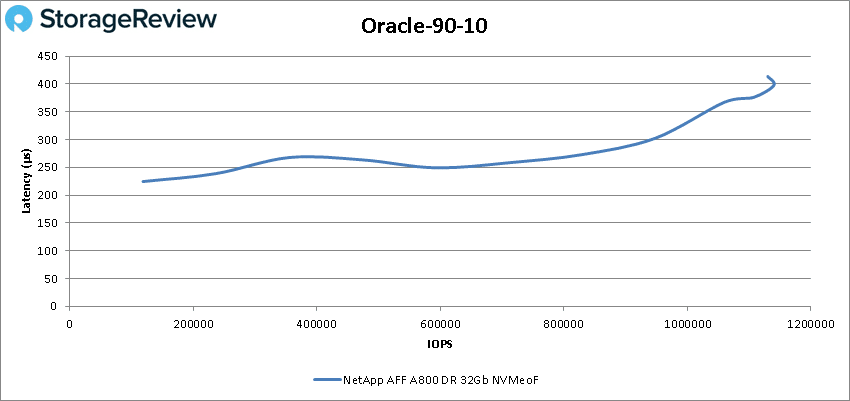
Oracle 90-10 saw the A800 start at 118,586 IOPS and peak at 1,140,178 IOPS at a latency of 397.6µs.
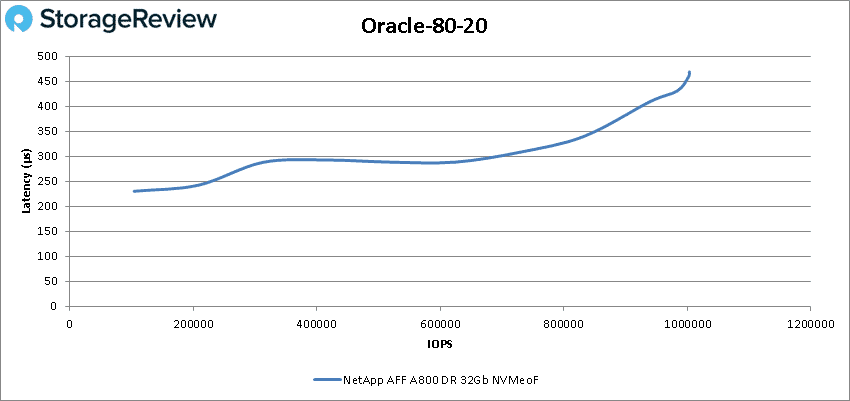
In Oracle 80-20 we saw the A800 once again had sub-millisecond latency throughout starting at 104,206 IOPS and peaking at 1,003,577 IOPS at 468.8µs latency.
Conclusion
The NetApp AFF A800 is a 4U, all-flash array that supports block and file access, as well as end-to-end NVMe support. The A800 is aimed at those that have the most demanding workloads needing lots of performance and plenty of storage, with a maximum effective capacity of 316.8PB. While our first award winning review looking at this array over traditional Fibre Channel, this review leverages NVMe over Fabrics to see how things shook out.
For our VDBench workloads, the NetApp AFF A800 offered an impressive set of numbers across the board. In our basic four corners run we saw random 4K peak performance of 2.2 million IOPS read and 465K IOPS write. In our sequential 64K workloads we saw 25GB/s read and 7.52GB/s write. In our SQL workloads we saw peaks of 1.5 million IOPS, SQL 90-10 saw 1.4 million IOPS, and SQL 80-20 saw 1.1 million IOPS. Our Oracle tests showed impressive 1.1 million IOPS, Oracle 90-10 gave us 1.14 million IOPS, and Oracle 80-20 had 1 million IOPS. More impressive was SQL and Oracle workloads staying under 1ms of latency throughout.
Even though we saw great results with the A800 configured for NVMeOF, especially in terms of read performance, it’s worth noting that the system still has more to give. In our testing the load generation servers were all VMware hypervisor based, which adds another layer of complexity. Additionally, VMware doesn’t fully support NVMeOF at this time. For mainstream enterprises that want to take full advantage of NVMeOF with NetApp systems, bare metal will drive the best performance. That said, many will want to use NVMeOF ONTAP systems in a hybrid configuration, using both fabrics and standard Fibre Channel connectivity. In either case, NetApp continues to lead the pack in terms of adopting and deploying leading generation technologies to be sure their arrays are ready for whatever their customers need, whenever they need it. The A800 does especially well here, which is why we awarded it an Editor’s Choice in our initial review. The NVMeOF adds a massive performance boost that should appeal to enterprises requiring maximum throughput and microsecond latency for their business-critical applications.


 Amazon
Amazon