

Today at the AWS Global Summit, Alluxio announced the latest version of its data orchestration technology, Alluxio 2.0. The latest version comes with new innovations for data engineers and is aimed at multi-cloud analytics and AI.
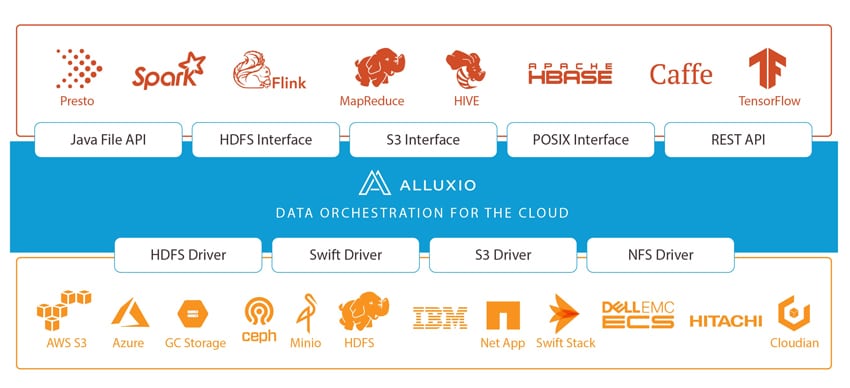
As we initially stated, Alluxio states that they are the world's first system that unifies data at memory speed. The “memory speed” would enable businesses to access data quickly across disparate storage systems, which in turn means that they can manage their data more efficiently, discover valuable insights faster, and ease their adoption of the hybrid cloud. Currently, Alluxio runs critical workloads for companies such as Alibaba, Baidu, Barclay's Bank, CERN, ESRI, Huawei, Intel, and Juniper.
The world is shifting to cloud-based compute intensive workloads. This new focus means that compute needs to scale independently from storage in an elastic way. While there are several benefits to this from a performance angle, it introduces potential headaches for data engineers. Alluxio aims to fix this by adding an abstraction layer that brings data locality, data accessibility and data elasticity to compute across data silos, zones, regions and even clouds.
Features and capabilities include:
- Data Orchestration Innovation for Multi-cloud:
- Policy-driven Data Management
- Alluxio 2.0 includes a new capability that allows data engineers to automate data movement across storage systems based on pre-defined policies on an automated and on-going basis. This means that as data is created and hot, warm, cold data is managed, Alluxio can automate tiering of data across any number of storage systems across on-premises and across all clouds.
- Data platform teams can now reduce storage costs by automatically managing only the most important data in expensive storage systems and moving other data to cheaper storage alternatives.
- Improved Administration of Data Access Policies: In addition to fine grained policies at the file level, now users can configure policies at any directory and folder level to streamline access of data as well as performance of workloads. These include defining behaviors for individual datasets on various core functions like writing data or syncing data with storage systems under Alluxio.
- Cross Cloud Storage Efficient Data Movement via Data Service: The new data service allows for highly efficient data movement including across cloud stores like AWS S3 and Google GCS, making expensive operations on object storage seamless to the compute framework.
- Policy-driven Data Management
- Compute Optimized Data Access for Cloud Analytics:
- Compute-focused Cluster Partitioning: Users can now partition a single Alluxio based on any dimension, so that datasets for each framework or workload isn’t contaminated by the other. Most common usage includes partitioning the cluster by framework Spark, Presto etc. In addition, this allows for reduced data transfer costs, constraining data to stay within a specific zone or region.
- Integration with External Data Sources Over REST: Users can now bring in data even from web-based data sources to aggregate in Alluxio to perform their analytics. Any web location with files can be simplify pointed to Alluxio to be pulled in as needed based on the query or model run.
- Other Features, Include:
- Highly Distributed Data Services – 2.0 introduces the Alluxio Data Service, a distributed clustered service, that data operations such as replication, persistence, for enabling high performance and massive scale.
- Adaptive Replication for Increased Data Locality – New feature to configure a range for the number of copies of data stored in Alluxio that are automatically managed.
- High Availability with Embedded Journal – A new fault tolerance and high availability mode for file and object metadata called the embedded journal that uses the RAFT consensus algorithm and is independent of any other external storage systems. This is particularly helpful for abstracting object storage.
- Alluxio POSIX API – Alluxio’s FUSE feature enables a POSIX compatible API so that frameworks like Tensorflow, Caffe and other Python-based models can directly access data from any storage system via Alluxio using traditional file system access.
- Amazon AWS Support:
- AWS Elastic Map Reduce (EMR) Service Integration: As users move to cloud services to deploy analytical and AI workloads, services like AWS EMR are increasingly used. Alluxio can now be seamlessly bootstrapped into an AWS EMR cluster making it available as a data layer within EMR for Spark, Presto and Hive frameworks. Users now have a high-performance alternative to cache data from S3 or remote data while also reducing data copies maintained in EMR.
Availability
Both Alluxio 2.0 Community and Enterprise Edition are now available.
Discuss this story


 Amazon
Amazon