

Meta Platforms has selected the NVIDIA DGX A100 system for the AI Research SuperCluster (RSC). When fully deployed, Meta’s RSC is expected to be the largest NVIDIA DGX A100 system. The AI Research SuperCluster (RSC) is already training new models to advance AI.
Meta Research SuperCluster

Meta’s AI Research SuperCluster features hundreds of NVIDIA DGX systems linked on an NVIDIA Quantum InfiniBand network to accelerate the work of its AI research teams.
RSC is expected to be fully built out later this year and Meta will use it to train AI models with more than a trillion parameters. RSC will make advances in fields such as natural language processing for jobs like identifying harmful content in real-time. In addition to performance at scale, Meta cited extreme reliability, security, privacy, and the flexibility to handle “a wide range of AI models” as its key criteria for RSC.

AI supercomputers are built by combining multiple GPUs into compute nodes, which are then connected by a high-performance network fabric to allow fast communication between those GPUs. RSC today comprises a total of 760 NVIDIA DGX A100 systems as its compute nodes, for a total of 6,080 GPUs — with each A100 GPU being more powerful than the V100 used in the previous system.

The GPUs communicate via an NVIDIA Quantum 200 Gb/s InfiniBand two-level Clos fabric that has no oversubscription. RSC’s storage tier has 175 petabytes of Pure Storage FlashArray, 46 petabytes of cache storage in Penguin Computing Altus systems, and 10 petabytes of Pure Storage FlashBlade.


Early benchmarks on RSC, compared with Meta’s legacy production and research infrastructure, have shown that it runs computer vision workflows up to 20 times faster, runs the NVIDIA Collective Communication Library (NCCL) more than nine times faster, and trains large-scale NLP models three times faster. That means a model with tens of billions of parameters can finish training in three weeks, compared with nine weeks before.
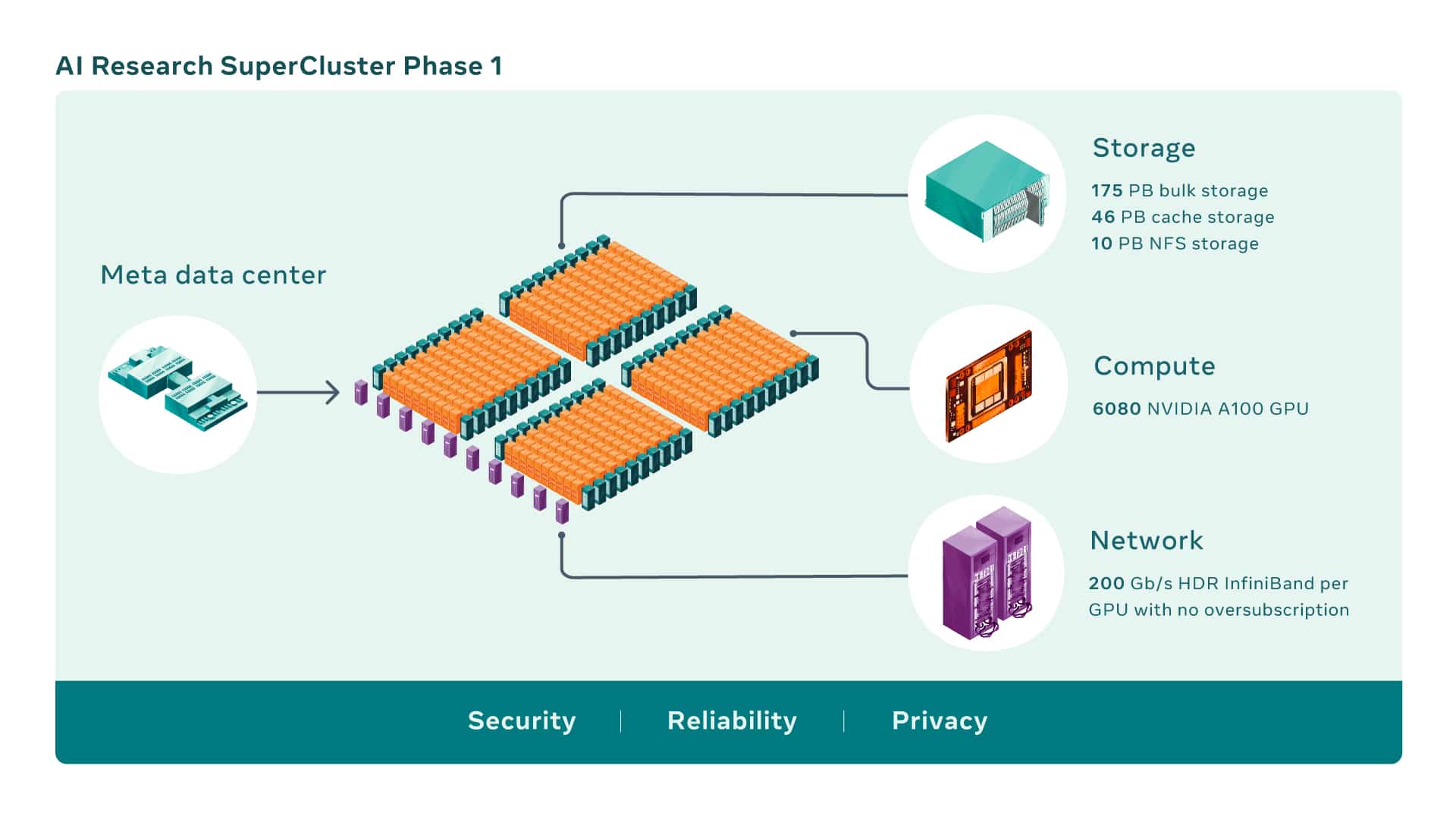
When RSC is complete, the InfiniBand network fabric will connect 16,000 GPUs as endpoints, making it one of the largest such networks deployed to date. Additionally, the designed caching and storage system can serve 16 TB/s of training data, and scale it up to 1 exabyte.

While RSC is up and running today, its development continues. Once phase two of building out RSC is complete, it is expected to be the fastest AI supercomputer in the world, performing at nearly 5 exaflops of mixed-precision compute.

Work will continue through 2022 to increase the number of GPUs from 6,080 to 16,000, increasing AI training performance by more than 2.5x. The InfiniBand fabric will expand to support 16,000 ports in a two-layer topology with no oversubscription. The storage system will have a target delivery bandwidth of 16 TB/s and exabyte-scale capacity to meet increased demand.


 Amazon
Amazon