

Meta outlined the rapid development of its Meta Training and Inference Accelerator (MTIA) program. It described four generations of chips created over roughly two years. These chips solve a key infrastructure problem that Meta considers essential for AI worldwide: quickly adjusting to evolving model architectures at low cost, without depending on long silicon development cycles. MTIA is part of a broader silicon strategy, and Meta reaffirmed its collaboration with Broadcom to develop these chips.
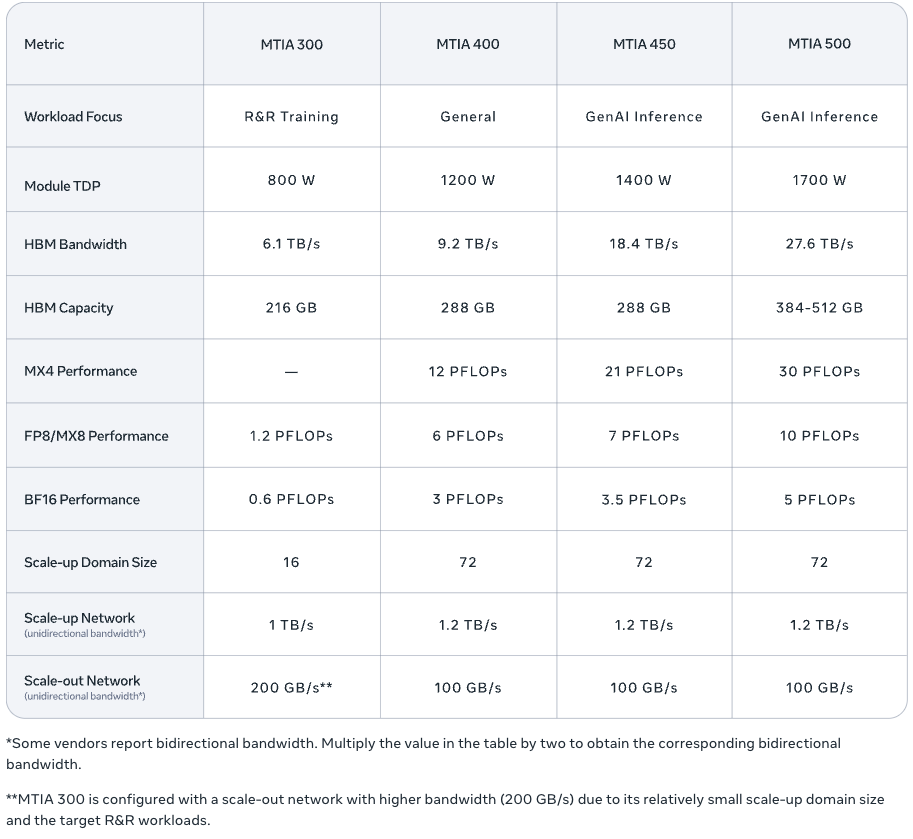
According to Meta, it has already deployed hundreds of thousands of MTIA devices in production and has integrated several internal models. The validation work includes testing large language models such as Llama. The company previously published technical details on the first two MTIA generations, MTIA 100 and MTIA 200, in ISCA research papers. It is now expanding the platform with MTIA 300, 400, 450, and 500. These new components extend coverage from ranking and recommendation (R&R) inference to R&R training and, increasingly, to general GenAI workloads, especially inference, with deployments underway or planned for 2026 and 2027.
Iteration as a Design Principle
A key theme is cadence. Meta argues that model evolution is faster than traditional chip development, which can take 2 years from design to production. Meta builds MTIA chips on the open-source RISC-V architecture, with Taiwan Semiconductor Manufacturing Corporation (TSMC) handling fabrication. The response is an iterative, modular design approach. Each generation builds on reusable chiplets and is fine-tuned using the latest insights on operators and serving. The company also emphasized the importance of reuse beyond the chip itself. MTIA 400, 450, and 500 share the same chassis, rack, and network infrastructure. This allows for quick upgrades, reducing the time from silicon readiness to data center deployment.
MTIA 300: Networking and Collectives Built Into the Silicon
MTIA 300 forms the basis of the new roadmap. It was initially optimized for R&R training, Meta’s primary workload before the rise of GenAI. The architecture includes built-in networking chiplets, dedicated message engines for efficient collective communication, and near-memory computing to lessen the load on collective operations. Although focused on R&R, these communication components also support GenAI training and inference efficiency in later versions.
At the block level, Meta described MTIA 300 as a multi-chiplet design featuring one compute chiplet, two network chiplets, and multiple HBM stacks. The compute block is arranged as a grid of processing elements (PEs), with extra PEs to enhance yield. Each PE includes two RISC-V vector cores, a dot-product engine for matrix operations, a specialized function unit for activations and element-wise operations, a reduction engine for accumulation and PE-to-PE communication, and a DMA engine for local data transfer.
MTIA 400: A Pivot Toward GenAI With Competitive Throughput Claims
MTIA 400 upgrades MTIA 300 to better support GenAI while maintaining R&R capabilities. Meta describes MTIA 400 as a major upgrade, reporting 400% higher FP8 FLOPS and 51% higher HBM bandwidth than MTIA 300. Architecturally, MTIA 400 combines two compute chiplets to increase compute density and adds support for improved MX8 and MX4 low-precision formats, which Meta considers essential for efficient GenAI inference.

System design remains a key focus. Meta described a rack-scale deployment in which 72 MTIA 400 devices connect via a switched backplane, forming a single scalable domain. For flexible deployments, Meta mentioned air-assisted liquid cooling (AALC) racks to accelerate setup in existing data centers. It also noted that the platform can support liquid cooling solutions.
MTIA 450: GenAI Inference Optimization Starts With Memory Bandwidth
MTIA 450 is an improved version of MTIA 400, focused on inference and driven by increased demand for GenAI inference. Meta identified HBM bandwidth as the main factor limiting inference performance and doubled it from MTIA 400 to MTIA 450. The company also reported a 75% boost in MX4 FLOPS to improve mixture-of-experts computations, along with hardware acceleration to reduce common bottlenecks in attention and feed-forward operations, particularly in the behavior of Softmax and FlashAttention.
Meta highlighted its work on data types as an important factor. MTIA 450 goes beyond FP8 and MX8, achieving MX4 throughput at six times the speed of FP16/BF16. The chip supports mixed low-precision calculations without requiring software conversions. It features custom innovations for data types designed to preserve model quality while increasing FLOPS with minimal area impact. MTIA 450 is scheduled for mass deployment in early 2027.
MTIA 500: More Bandwidth, More Capacity, Further Chiplet Decomposition
MTIA 500 continues the focus on inference with further improvements in memory and compute. Meta stated that MTIA 500 increases HBM bandwidth by 50% over MTIA 450, raises HBM capacity by up to 80%, and increases MX4 FLOPS by 43%. The chiplet design advances with a 2×2 configuration of smaller compute chiplets, surrounded by multiple HBM stacks and two network chiplets. It also includes a System-on-Chip (SoC) chiplet for PCIe connectivity to the host CPU and scale-out NICs. Meta mentioned additional hardware acceleration and changes to data types to address inference bottlenecks.
MTIA 500 is scheduled for mass deployment in 2027.
Easy Adoption
Meta is aligning MTIA with a goal of easy adoption, emphasizing industry-standard tools rather than a specialized framework. The company described MTIA as PyTorch-native, working seamlessly with PyTorch 2.x compilation processes and supporting both eager and graph execution. In graph mode, developers can use torch.compile and torch.export to optimize graphs without needing to rewrite MTIA-specific models, enabling parallel deployment across GPUs and MTIA.
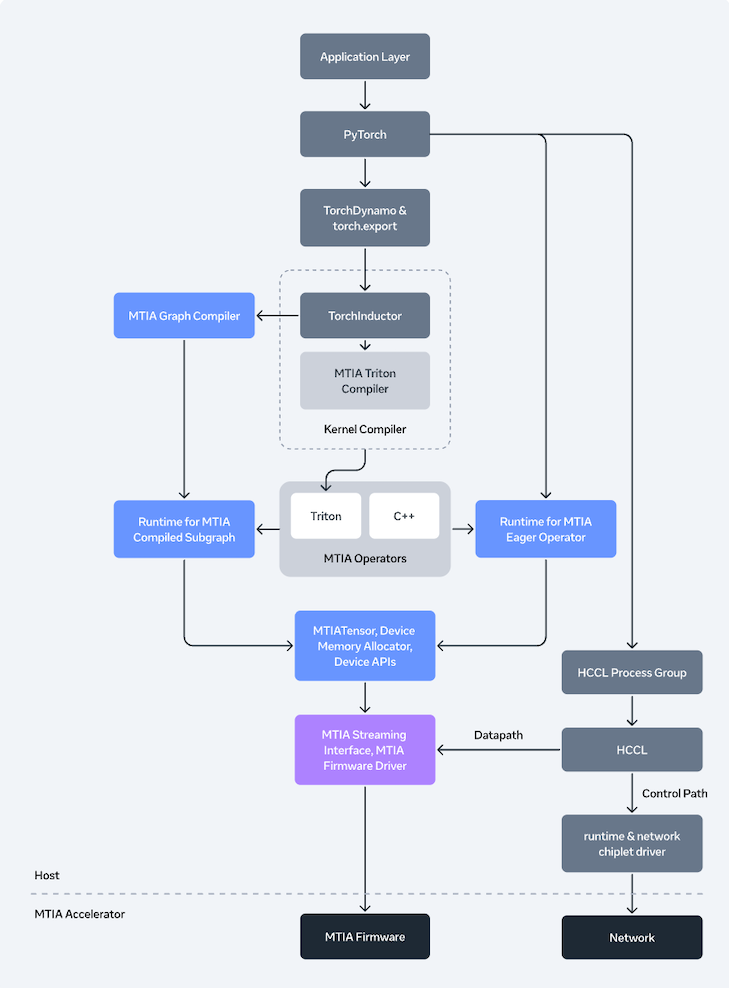
Behind the scenes, Meta detailed an MTIA compiler stack built on Torch FX IR and TorchInductor. The lower layers use Triton, MLIR, and LLVM, along with MTIA-specific optimizations, including improvements to kernel fusion and extensions for performance-critical parts. Autotuning is a key feature for selecting among different compilation strategies.
For distributed execution, Meta introduced its Hoot Collective Communications Library (HCCL). This library is similar to GPU collective stacks but is optimized for MTIA’s built-in networking chiplets and message engines. It uses near-memory compute to accelerate reduction operations. Meta also supports compute-collective fusion to lower latency and has a transport stack designed to manage the data path and reduce host overhead.
At runtime, Meta demonstrated a device runtime that manages memory, scheduling, and coordination across eager and graph modes. It also introduced a Rust-based user-space driver, shifting away from the traditional in-kernel Linux driver. The firmware is written in bare-metal Rust, emphasizing low latency and safety.
For GenAI serving, Meta described its vLLM integration using a plugin system. This replaces key operators like FlashAttention and fused LayerNorm with MTIA-specific kernels. It also enables graph mode via a custom torch.compile backend. Moreover, Meta mentioned tools for managing large MTIA deployments, including monitoring, profiling, debugging, and observability across hosts and devices.
What’s Next
Meta’s updated MTIA roadmap emphasizes the economics of GenAI inference, highlighting HBM bandwidth and low-precision formats as key factors. If Meta meets its deployment timelines, MTIA 450 and 500 will serve as the first large-scale tests to determine whether an inference-first accelerator strategy, based on quick chiplet iterations and standardized software, can maintain advantages over mainstream GPU platforms for delivering GenAI services.


 Amazon
Amazon