

NVIDIA has announced numerous new technologies and partnerships, including a new version of its TensorRT inference software, the integration of TensorRT into Google’s TensorFlow framework, and that its speech recognition software, Kaldi, is now optimized for GPUs.
VIDIA’s TensorRT4 software accelerates deep learning inference across a variety of applications with accurate INT8 and FP16 network execution, indicating that it will decrease datacenter costs by up to 70%. TensorRT4 can also be used to quickly optimize, validate and deploy trained neural networks in hyperscale datacenters, embedded and automotive GPU platforms. NVIDIA also claims that the new software boasts upwards of 190x faster in deep learning inference when compared to CPUs for common applications. Moreover, NVIDIA and Google engineers have integrated TensorRT into TensorFlow 1.7, making it easier to run deep learning inference applications on GPUs.
NVIDIA has optimized Kaldi to achieve faster performance running on GPUs, which will result in more accurate and useful virtual assistants for consumers, and lower deployment costs for datacenter operators.
Further partnership announcements include:
- AI support for Windows 10 applications, as NVIDIA partnered with the IT giant to build GPU-accelerated tools so developers incorporate more intelligent features in Windows applications.
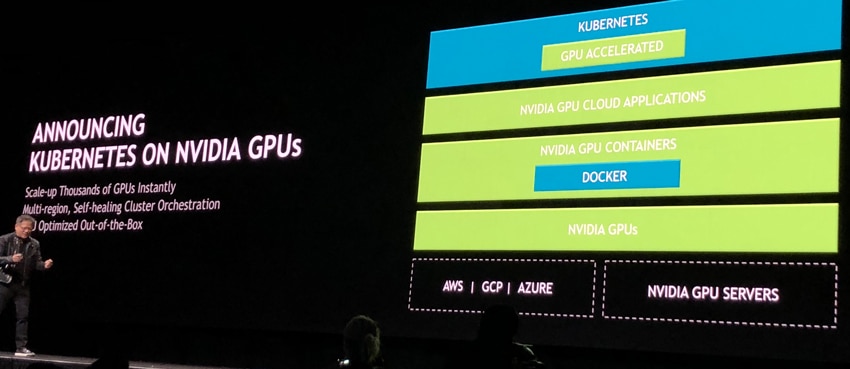
- GPU acceleration for Kubernetes to facilitate enterprise inference deployment on multi-cloud GPU clusters.
- MathWorks today announced TensorRT integration with their flagship software, MATLAB. NVIDIA indicates that engineers and scientists can now automatically generate high-performance inference engines from MATLAB for Jetson, NVIDIA Drive and Tesla platforms.
Next, NVIDIA specifies that TensorRT can be deployed on NVIDIA DRIVE autonomous vehicles and NVIDIA Jetson embedded platforms while deep neural networks can be trained on NVIDIA DGX systems in the datacenter on every framework, and then deployed into all types of technologies for realtime inferencing at the edge.
TensorRT will allow developers to focus on creating novel deep learning-powered instead of performance tuning for inference deployment. NVIDIA adds that developers can leverage TensorRT to deliver extremely fast inference via INTS or FP16 precision. This will reduce latency, which will, in turn, improve capabilities such as object detection and path planning on embedded and automotive platforms.


 Amazon
Amazon