

At GTC 2026 in San Jose, NVIDIA CEO Jensen Huang delivered a keynote outlining the company’s next-generation AI infrastructure platform and a sweeping set of announcements spanning silicon, systems, software, and ecosystem partnerships. With more than 30,000 attendees from over 190 countries, GTC 2026 served as the stage for NVIDIA’s most comprehensive platform refresh since the introduction of Blackwell, anchored by the full production rollout of the Vera Rubin architecture and the integration of Groq 3 LPU technology into the NVIDIA data center ecosystem. As Huang put it on stage, the agentic AI inflection point has arrived, and Vera Rubin is kicking off what NVIDIA describes as the greatest infrastructure buildout in history.

The central theme of the keynote was the emergence of a fourth AI scaling law: agentic scaling, in which AI systems communicate not just with humans but with other AI agents, driving exponential demand for low-latency, large-context inference at unprecedented scale. NVIDIA positioned the Vera Rubin platform as the infrastructure foundation to serve this new frontier. It combines seven co-designed chips across five new rack-scale systems purpose-built for the AI factory. The platform also drew endorsements from Frontier AI labs: Anthropic CEO and Co-Founder Dario Amodei noted, “Enterprises and developers are using Claude for increasingly complex reasoning, agentic workflows, and mission-critical decisions. That demands infrastructure capable of keeping pace. NVIDIA’s Vera Rubin platform gives us the compute, networking, and system design to keep delivering while advancing the safety and reliability our customers depend on.” OpenAI CEO Sam Altman stated, “NVIDIA infrastructure is the foundation that lets us keep pushing the frontier of AI. With NVIDIA Vera Rubin, we’ll run more powerful models and agents at massive scale and deliver faster, more reliable systems to hundreds of millions of people.”
Vera Rubin Platform: Opening the Agentic AI Frontier
Building on the Vera Rubin NVL72 architecture first unveiled at CES 2026, GTC 2026 expanded the platform into a comprehensive POD-scale AI factory ecosystem. NVIDIA is framing this as a shift from discrete chips and standalone servers to fully integrated rack-scale systems, pod-scale deployments, and sovereign AI factories. The Vera Rubin platform brings together NVIDIA Vera CPUs, Rubin GPUs, NVLink 6 Switches, ConnectX-9 SuperNICs, BlueField-4 DPUs, Spectrum-6 Ethernet Switches, and a newly integrated NVIDIA Groq 3 LPU, all designed to operate as a single unified AI supercomputer with deep co-design across compute, networking, and storage, supported by an ecosystem of more than 80 MGX partners with a global supply chain.
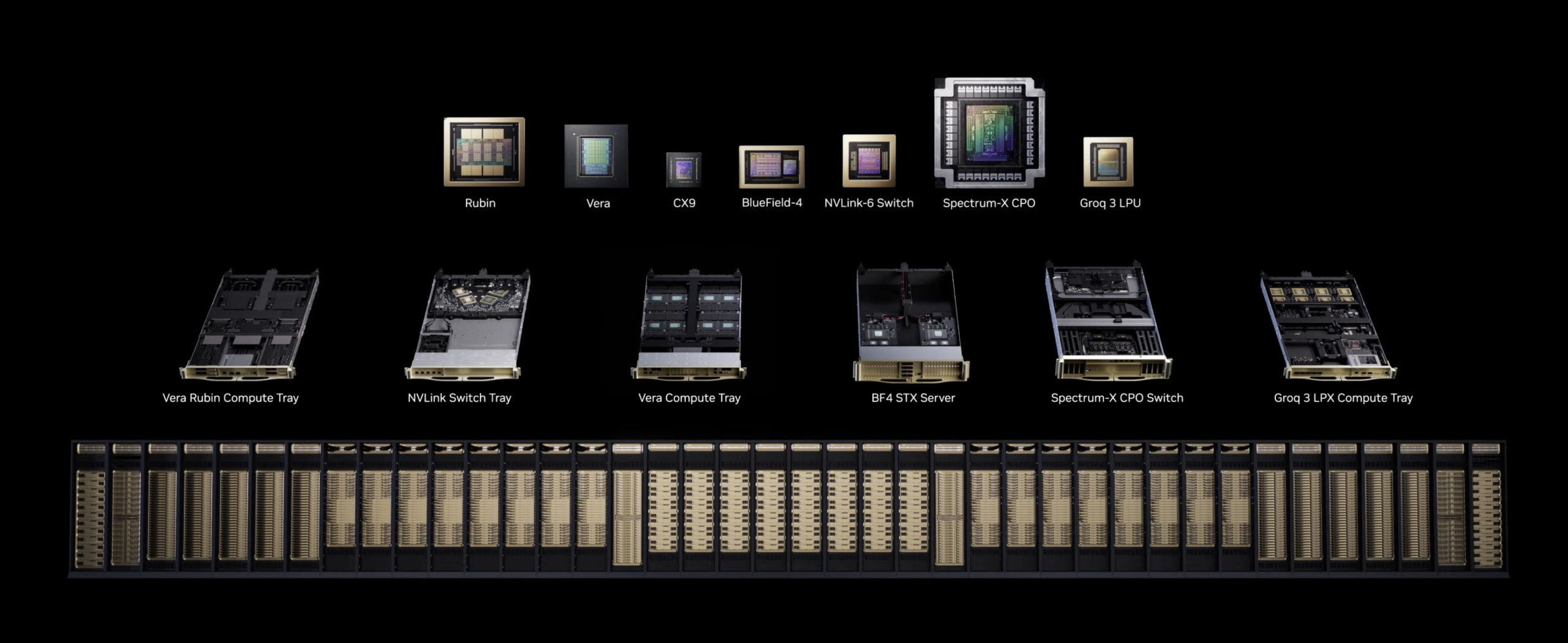
NVIDIA claims the platform delivers up to 10x more inference throughput per watt and one-tenth the cost per token compared to the Blackwell generation across the full spectrum of AI workloads. For training large Mixture-of-Experts models, Vera Rubin requires only one-fourth as many GPUs to achieve equivalent performance. The NVL72 scales seamlessly with NVIDIA Quantum-X800 InfiniBand and Spectrum-X Ethernet to sustain high utilization across massive GPU clusters while reducing time-to-train and total cost of ownership.
Generational Comparison: Blackwell Ultra vs. Vera Rubin NVL72
| Specification | GB300 NVL72 (Blackwell Ultra) | VR NVL72 (Vera Rubin) |
|---|---|---|
| Compute Architecture | ||
| GPU Count | 72 Blackwell Ultra GPUs | 72 Rubin GPUs |
| CPU Count | 36 Grace CPUs | 36 Vera CPUs |
| CPU Cores | 72 ARM cores per CPU | 88 Olympus ARM cores per CPU |
| AI Performance | ||
| FP4 Inference Performance | 1.44 ExaFLOPS | 3.6 ExaFLOPS |
| NVFP4 per GPU (Inference) | 20 PFLOPS | 50 PFLOPS |
| NVFP4 per GPU (Training) | 10 PFLOPS | 35 PFLOPS |
| Memory | ||
| GPU Memory Type | HBM3e | HBM4 |
| GPU Memory Bandwidth | ~8 TB/s | ~22 TB/s |
| Interconnect | ||
| NVLink Generation | NVLink 5 | NVLink 6 |
| NVLink Bandwidth (per GPU) | 1.8 TB/s | 3.6 TB/s |
| Rack-Scale NVLink Bandwidth | 130 TB/s | 260 TB/s |
| Networking | ||
| Scale-Out NIC | ConnectX-8 (800 Gb/s) | ConnectX-9 (1.6 TB/s) |
| CPU-GPU Interconnect | NVLink-C2C (900 GB/s) | NVLink-C2C (1.8 TB/s) |
Vera Rubin-based products will be available from partners starting in the second half of 2026. Including leading cloud providers Amazon Web Services, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure, as well as NVIDIA Cloud Partners CoreWeave, Crusoe, Lambda, Nebius, Nscale, and Together AI. Global system manufacturers Dell Technologies, HPE, Lenovo, and Supermicro are expected to deliver servers based on Vera Rubin products, as well as ASUS, Foxconn, GIGABYTE, Inventec, Pegatron, QCT, Wistron, and Wiwynn.
From CPX to LPX: How NVIDIA’s Groq Acquisition Reshaped Decode Acceleration
Last year at the AI Infra Summit, NVIDIA announced the CPX rack in a couple of configurations designed for accelerating long-context inference queries. When we covered that announcement, it raised several questions for us about the CPX’s actual function. At first glance, although it was an interesting architectural concept, the CPX didn’t appear to offer anything materially beyond the Rubin GPU itself, aside from perhaps additional acceleration for attention operations.

Then came the Groq acquisition, which was enormously popular in the industry and sparked speculation about how NVIDIA would integrate Groq’s LPU technology into the broader Vera Rubin platform. Well, NVIDIA cleared the air at GTC 2026 with the LPX announcement. From what was presented, it appears that the CPX rack concept has evolved into the Groq 3 LPX Rack, with the original CPX’s context-processing focus giving way to a fundamentally different decode-acceleration architecture built around Groq’s silicon.
Rubin GPU vs. Groq 3 LPU: Complementary Architectures
| Specification | Rubin GPU | Groq 3 LPU (LP30) |
|---|---|---|
| Memory Type | HBM4 | Stacked SRAM |
| Memory Capacity (per chip) | 288 GB | 500 MB |
| Memory Bandwidth | 22 TB/s | 150 TB/s |
| Strength | High-throughput training and prefill | Ultra-low-latency token decode |
| Deployment | VR NVL72 (72 per rack) | LPX Rack (256 per rack) |
| Aggregate Rack Memory | ~20.7 TB HBM4 | 128 GB SRAM |
| Scale-Up Bandwidth (Rack) | 260 TB/s NVLink 6 | 640 TB/s |
A single LPX Rack houses 256 Groq 3 LPUs. With each LPU containing approximately 500 MB of stacked SRAM, the rack provides roughly 128 GB of aggregate on-chip SRAM and 640 TB/s of scale-up bandwidth, purpose-built for ultra-low-latency decode acceleration. The contrast between the two processor types is stark: a Rubin GPU provides 288 GB of HBM4 at 22 TB/s bandwidth, while the LPU trades capacity for raw bandwidth, delivering 150 TB/s from its SRAM pool per chip. When co-deployed with the VR NVL72 via a custom Spectrum X-based interconnect, the two racks are supposed to process every decode token cooperatively with attention decode existing on Rubin and Feed Forward layers being offloaded to LPUs. Optimized for trillion-parameter models and million-token context, the co-designed LPX architecture pairs with Vera Rubin to maximize efficiency across power, memory, and compute. The LPX Rack is fully liquid-cooled, built on MGX infrastructure, and will be available in the second half of 2026, coincident with the broader Vera Rubin rollout.
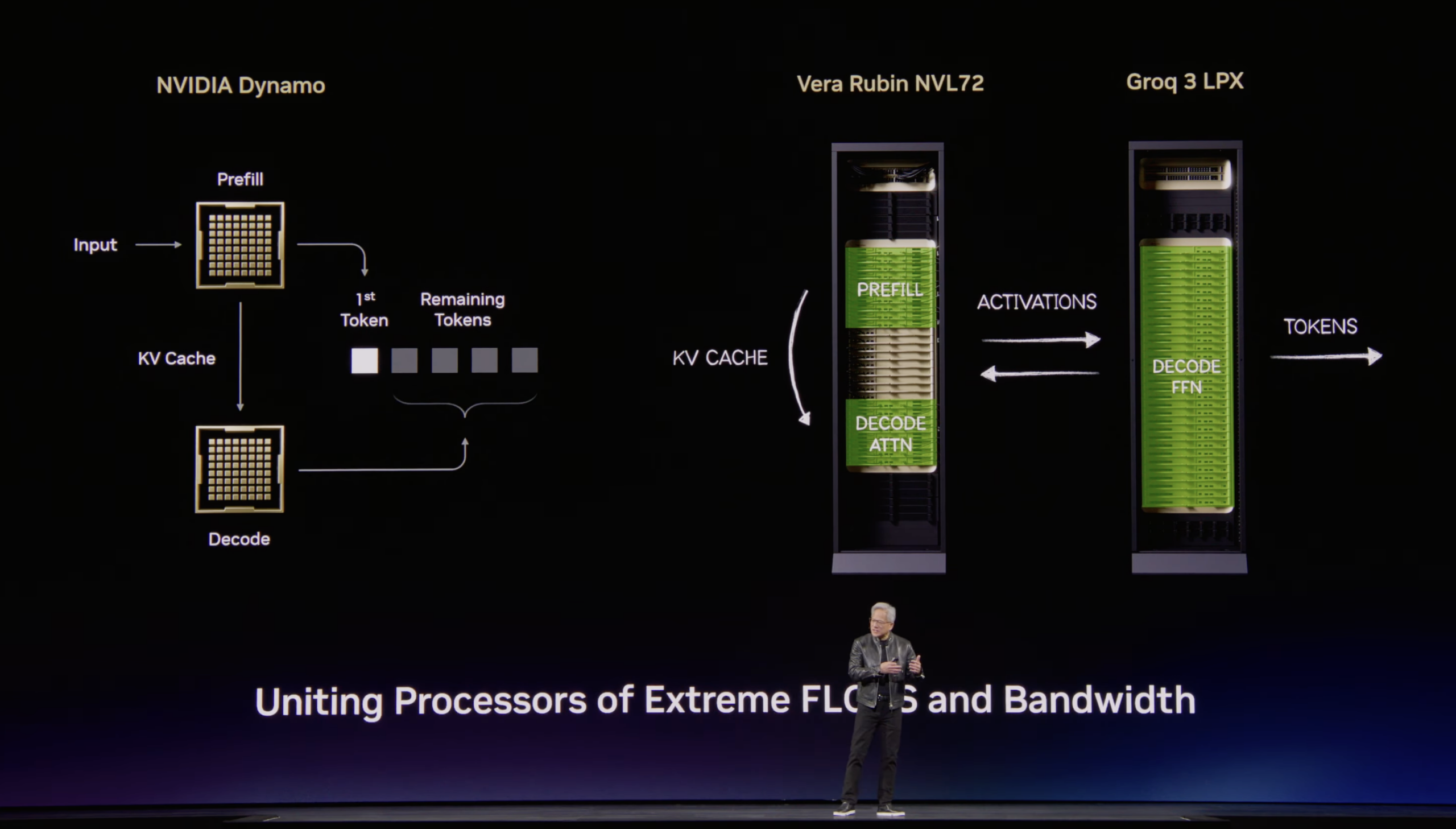
Importantly, NVIDIA confirmed that no changes to CUDA are required. The LPU operates as an accelerator to the existing CUDA stack running on the Vera and NVL72 platform, with computation offloaded transparently on a per-token basis. During the GTC Q&A, NVIDIA described the LPU as a “decode model booster” and explained that they will be “working deeply with the AI labs and the AI frontier model builders who are deploying these trillion-parameter models” to enable the next generation of premium and ultra-premium model serving. Many of Groq’s founders and engineers have joined NVIDIA, and the collaboration between the two teams has reportedly been excellent as they pull forward the Groq roadmap to build into the MGX infrastructure. The LPX deployment will initially focus on model builders and service providers rather than broad OEM availability. We look forward to seeing the real-world performance improvements from the NVIDIA and Groq integration.
Vera CPU Rack: Purpose-Built Compute for Reinforcement Learning and Agentic Workloads
Why Agentic AI Demands a New Class of CPU
To understand why NVIDIA built a dedicated CPU rack, it helps to understand how reinforcement learning (RL) works in the post-training phase of modern AI development. Post-training is the stage after a model has been pre-trained on a massive dataset, where the model is refined and specialized for target use cases.
In a reinforcement learning setup, the training loop involves three core components: a policy model (the model being trained), an environment in which the model takes actions and receives feedback, and a reward signal that evaluates the quality of those actions. The policy model generates candidate outputs, which are then executed in the environment, scored by the reward model, and the resulting gradients are used to update the policy.

Vera CPU node in the center
For agentic AI workloads, this RL environment is not an abstract simulation; it is a real computational sandbox. Consider, for example, post-training an agentic coding model with tools like Claude Code or similar autonomous coding agents. In this regime, you need three distinct compute pools operating simultaneously. First, there is a training pool of GPU accelerators updating the policy model weights. Second, inference accelerators run the current policy model checkpoint to generate candidate actions (code edits, tool calls, file operations) at scale. Third, and critically, there is a large pool of conventional CPU compute where the actual RL environments run. These environments are where the agents execute their generated code, run test suites, perform tool calls, issue SQL queries, compile binaries, interact with file systems, and carry out all sandbox operations that produce the reward signals that feed back into the training loop.
The scale of this conventional compute requirement is substantial. Each execution from the policy model may trigger dozens of sequential tool calls, each of which must be executed, evaluated, and returned before the next step can proceed. When you are generating thousands of data points in parallel across the training run, you need an enormous fleet of fast CPUs to keep the GPU training cluster from stalling on environment execution. Any latency in the CPU sandbox pool directly translates to idle GPU cycles and wasted training compute. The same dynamic applies at inference time for deployed agentic systems. Every tool call, code compilation, and sandbox execution an agent performs is CPU work that must be completed quickly enough to keep the end-to-end agentic pipeline responsive. As NVIDIA’s press materials put it, the CPU is no longer simply supporting the model; it’s driving it.
The Vera CPU Rack: NVIDIA’s Answer
To satisfy this requirement, NVIDIA launched the Vera CPU, which the company calls the world’s first processor purpose-built for the age of agentic AI and reinforcement learning. The Vera CPU Rack is a dedicated rack-scale system containing 256 liquid-cooled Vera processors capable of sustaining more than 22,500 concurrent CPU environments, each running independently at full performance. AI factories can quickly deploy and scale to tens of thousands of simultaneous instances and agentic tools in a single rack. The rack delivers 400 TB of total memory, 300 TB/s of aggregate memory bandwidth, and 64 BlueField-4 DPUs, all of which are compatible with the Vera Rubin and DGX ecosystems and built on the NVIDIA MGX modular reference architecture.
The Vera CPU itself is built on 88 custom NVIDIA-designed Olympus cores with full Armv9.2 compatibility. Each core supports two simultaneous tasks using NVIDIA Spatial Multithreading. The second-generation low-power memory subsystem is built on LPDDR5X, delivering up to 1.2 TB/s of bandwidth, twice the bandwidth at half the power compared with general-purpose CPUs.
Beyond the performance characteristics, the Vera Rack also addresses a practical supply chain concern: organizations operating AI factories at the scale of tens of thousands of GPUs need equally massive fleets of CPUs for environment execution, and sourcing that volume of high-performance x86 processors from AMD or Intel at the required scale and timeline can introduce significant procurement and availability challenges. A vertically integrated NVIDIA CPU rack simplifies that dependency.
Customers collaborating with NVIDIA to deploy Vera CPU include Alibaba, ByteDance, Meta, and Oracle Cloud Infrastructure, as well as CoreWeave, Crusoe, Lambda, Nebius, Nscale, Cloudflare, Together AI, and Vultr. Manufacturing partners include Dell Technologies, HPE, Lenovo, Supermicro, ASUS, Cisco, Foxconn, GIGABYTE, and QCT, among others.
BlueField-4 STX and NVIDIA CMX: The Reference Architecture Behind Inference Context Memory Storage
At CES 2026, NVIDIA announced the Inference Context Memory Storage (ICMS) platform, a new class of AI-native storage infrastructure built specifically for KV cache management in large-scale LLM inference. At GTC 2026, NVIDIA unveiled the reference architecture that powers it: the BlueField-4 STX, a modular design that seamlessly extends GPU memory across the pod for agentic context and KV cache data. The first rack-scale implementation of STX is the new NVIDIA CMX context memory storage platform, which expands GPU memory with a high-performance context layer for scalable inference and agentic systems.
The need for a dedicated storage tier becomes clear when you examine how transformer-based inference scales. Every generated token must attend to all previous tokens via the attention mechanism, and the key-value (KV) cache stores precomputed attention matrices for reuse, avoiding recomputation. The problem is that the KV cache size grows with sequence length and batch size. In multi-tenant environments handling thousands of concurrent requests across million-token context windows, GPU HBM becomes exhausted. Operators must either reduce batch sizes, shorten context windows, or add more GPUs, all of which degrade economics or capability.
The BlueField-4 STX addresses this by providing a high-bandwidth, shared storage layer, purpose-built for KV cache access patterns, that sits between GPU HBM and conventional storage. It is accelerated by the Vera Rubin platform and harnesses a storage-optimized BlueField-4 processor that combines the Vera CPU with ConnectX-9 SuperNIC, together with Spectrum-X Ethernet networking, NVIDIA DOCA, and NVIDIA AI Enterprise software. NVIDIA claims the CMX platform delivers up to 5x tokens per second compared with traditional storage, 4x higher energy efficiency compared with traditional CPU architectures for high-performance storage, and 2x faster data ingestion for enterprise AI data.
NVIDIA is also introducing DOCA Memos, a new DOCA framework that supercharges BlueField-4 storage with dedicated KV cache processing to boost inference throughput while significantly improving power efficiency. The result is POD-wide context that delivers faster multi-turn interactions with AI agents, more scalable AI services, and higher overall infrastructure utilization. This ties into the open-source NVIDIA Dynamo project, which provides the software framework for disaggregated prefill/decode phases, smart routing, and tiered storage offloading.
The STX is a reference architecture that NVIDIA is not selling directly but providing to storage ecosystem partners. Storage providers co-designing next-generation infrastructure on STX include Cloudian, DDN, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data, and WEKA. Manufacturing partners building STX-based systems include AIC, Supermicro, and QCT. Leading AI labs and cloud providers planning to adopt STX for context memory storage include CoreWeave, Crusoe, IREN, Lambda, Mistral AI, Nebius, Oracle Cloud Infrastructure, and Vultr. STX-based platforms will be available from partners in the second half of 2026.
Vera Rubin DSX AI Factory Reference Design and Omniverse DSX Blueprint
Beyond individual racks and pods, NVIDIA announced the Vera Rubin DSX AI Factory reference design and general availability of the NVIDIA Omniverse DSX Blueprint, together providing a comprehensive framework for designing, building, and operating co-designed AI infrastructure that maximizes tokens per watt and accelerates time to first production. By tightly integrating compute, networking, storage, power, and cooling, the architecture increases energy efficiency and ensures that AI factories can scale reliably under continuous, high-intensity workloads while maintaining maximum uptime.
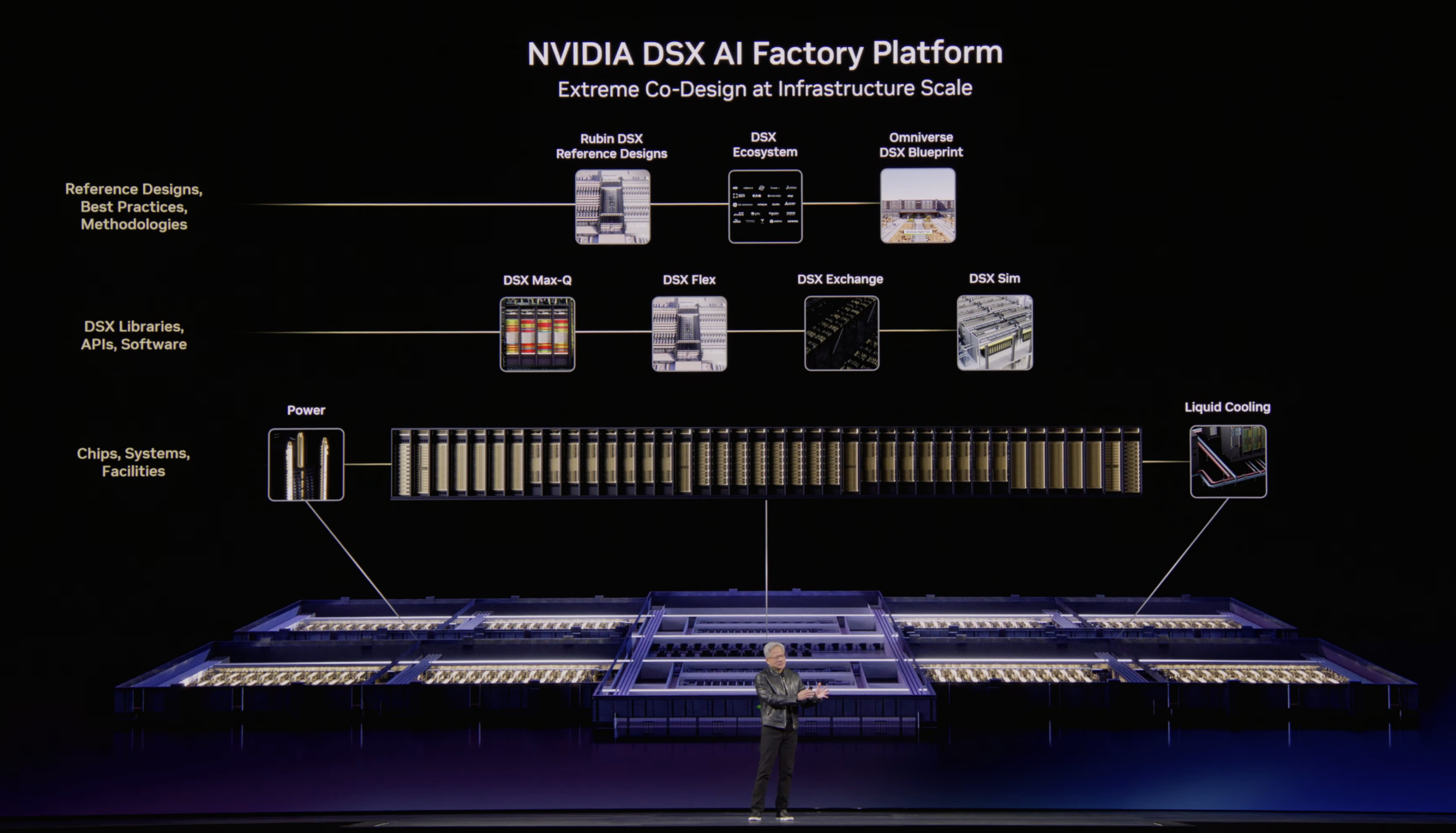
The Rubin DSX software stack is open, modular, and composable, connecting cluster hardware with power and cooling systems. It includes several component libraries: DSX Max-Q enables dynamic power provisioning across the entire AI factory, resulting in the deployment of 30% more AI infrastructure within a fixed-power data center. DSX Flex enables AI factories to become grid-flexible assets, unlocking what NVIDIA estimates is 100 gigawatts of stranded grid power, a critical capability given that energy is now the biggest bottleneck for AI infrastructure buildouts, with over $300 billion in equipment backlogs and more than 200 GW of projects waiting in U.S. interconnection queues. DSX Exchange enables scalable and secure integration of compute, network, energy, power, and cooling signals between IT, operational technology, and operations agents. DSX Sim models validate AI factories as high-fidelity digital twins using the NVIDIA DSX Air platform.
The Omniverse DSX Blueprint, now generally available on build.nvidia.com and fully compatible with the Vera Rubin DSX reference design, allows developers to build physically accurate digital twins of their AI factories, simulate operations in real time, and optimize performance before construction or deployment begins. This unifies power, cooling, networking, and operations into a single environment to accelerate time-to-revenue and AI efficiency.
Industry leaders contributing to the DSX architecture and blueprint include Cadence, Dassault Systèmes, Eaton, Jacobs, Nscale, Phaidra, Procore Technologies, PTC, Schneider Electric, Siemens, Switch, Trane Technologies, and Vertiv. Notably, Nscale and Caterpillar are bringing DSX Vera Rubin reference designs to life in West Virginia at a multi-gigawatt site described as one of the world’s largest AI factories. On the energy side, Emerald AI, GE Vernova, Hitachi, and Siemens Energy are using the DSX reference architecture to unlock grid capacity and deliver the power needed for new AI factory buildouts. Phaidra has integrated DSX Max-Q into a self-learning AI agent that delivers approximately 10% more compute by reducing cooling spikes while maintaining safety.
NVIDIA Agent Toolkit and OpenCLAW: The Software Stack for Autonomous Agents
TC 2026 also spotlighted the rapid rise of agentic AI workloads, with NVIDIA describing autonomous agents as the fastest-growing workload the company has ever seen. Central to the software announcements was OpenCLAW, described as likely the single most important software release in history and an orchestration framework for long-running, self-evolving agents called CLAWs, autonomous systems that can plan, act, and execute entire missions rather than individual tasks. NVIDIA characterized CLAWs as the new application layer for AI, noting that we have moved from prompting with “what, how, or why” to prompting with “build, create, or make.”
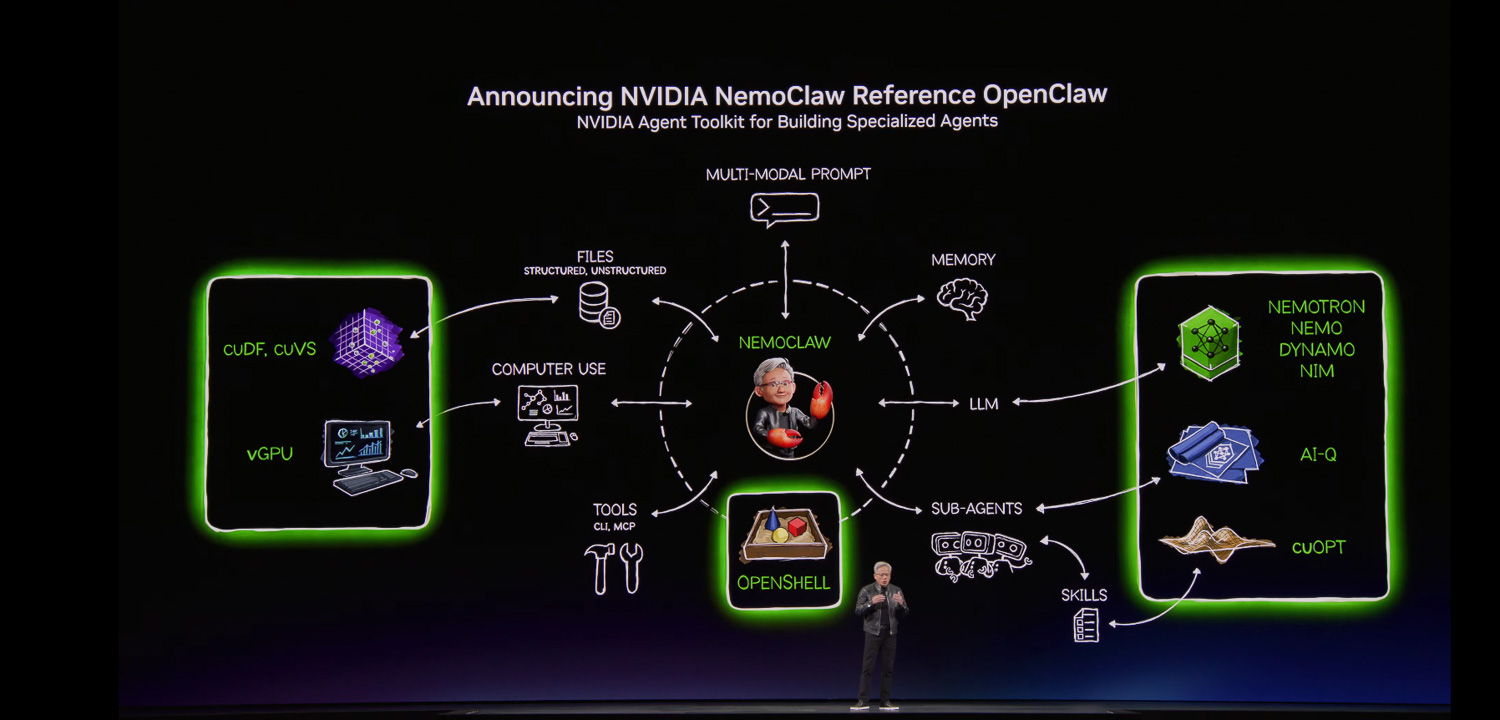
NVIDIA announced the NVIDIA Agent Toolkit, a fully open-source collection of models, runtimes, and blueprints for building, evaluating, and optimizing long-running autonomous agents. Key components include Nemotron open models for reasoning, coding, and speech; Nemo for agent profiling and customization; NIM for model inference; and Dynamo 1.0 for scale-out serving. New additions include NVIDIA OpenShell, an open-source safety and security runtime providing policy-based network, privacy, and security guardrails for agent execution, and IQ, an open-source blueprint combining frontier and open model intelligence for deep research agents, the first research system to top both the Deep Research Bench 1 and the Complex Deep Research Bench 2 benchmarks. A new cuOPT skill brings expertise in optimization problems described in natural language.
NVIDIA also announced Nemo CLAW, its contribution to the OpenCLAW community, developed in collaboration with OpenCLAW builder Peter Steinberger. Nemo CLAW installs OpenCLAW, along with Nemotron models and the OpenShell runtime, in a single command, providing a foundation for agents to develop and learn new skills while operating within defined privacy and security guardrails. It can run on any platform, from cloud infrastructure to on-premises RTX PCs, DGX Station, and DGX Spark.
DGX Spark and DGX Station: Local CLAW Development Platforms
Recognizing that many developers prefer local development environments with full control over their compute resources, NVIDIA introduced two new platforms, purpose-built for CLAW agent development. DGX Spark is a high-performance, power-efficient platform for running secure, always-on autonomous agents, with DGX Spark and GB10-based OEM partner systems now available globally. DGX Station, positioned as the ultimate local CLAW development platform, enables developers to run models with frontier-level intelligence entirely on-premises without cloud connectivity, which is critical for development, where everything stays local for complete control and security. DGX Station systems are available to order from OEM partners starting March 16, 2026.
Vera Rubin Space Modules: AI Infrastructure Beyond Earth
NVIDIA announced that its latest accelerated computing platforms are unlocking a new era of space innovation, bringing AI compute to orbital data centers (ODCs), geospatial intelligence, and autonomous space operations. The NVIDIA Vera Rubin Space Module delivers up to 25x more AI compute for space-based inference than the NVIDIA H100 GPU, enabling large language models and advanced foundation models to operate directly in orbit. Its tightly integrated CPU-GPU architecture provides the performance and memory needed to process massive data streams from space-based instruments in real time.

Alongside the Vera Rubin Space Module, NVIDIA IGX Thor provides industrial-grade durability for mission-critical edge environments in orbit, while Jetson Orin delivers high-performance AI inference in an ultra-compact module optimized for SWaP-constrained spacecraft. On the ground, the RTX PRO 6000 Blackwell Server Edition GPU delivers up to 100x faster performance versus legacy CPU-based batch systems for geospatial intelligence processing. Partners, including Aetherflux, Axiom Space, Kepler Communications, Planet Labs, Sophia Space, and Starcloud, are building on these platforms for next-generation space missions spanning orbital data centers, autonomous space operations, and real-time Earth observation.
NVIDIA Dynamo 1.0: The Inference Operating System for AI Factories
Rounding out the GTC 2026 announcements, NVIDIA entered production with Dynamo 1.0 open-source software that the company positions as the first distributed operating system for AI factory inference. Just as a computer’s operating system coordinates hardware and applications, Dynamo 1.0 functions as the distributed orchestration layer for AI factories, seamlessly managing GPU and memory resources across the cluster to power complex, heterogeneous AI workloads at scale.
Dynamo 1.0 splits inference work across GPUs with intelligent routing and the ability to move data between GPUs and lower-cost storage tiers, reducing wasted computation and easing memory constraints. For agentic AI and long-context workloads, Dynamo can route requests to GPUs that already hold the most relevant KV cache data from earlier steps, then offload that memory when it is not needed, a capability that ties directly into the BlueField-4 STX/ICMS storage architecture. In recent industry benchmarks, Dynamo boosted the inference performance of NVIDIA Blackwell GPUs by up to 7x, lowering token cost and increasing revenue opportunities for millions of deployed GPUs, all with free, open-source software.
NVIDIA is accelerating the open-source ecosystem by integrating Dynamo and TensorRT-LLM optimizations into popular inference frameworks, including LangChain, llm-d, LMCache, SGLang, and vLLM. Core Dynamo building blocks, KVBM for memory management, NIXL for fast GPU-to-GPU data movement, and Grove for simplified scaling, are also available as standalone modules. NVIDIA also contributes TensorRT-LLM CUDA kernels to the FlashInfer project for native integration into open-source frameworks.
The adoption breadth is notable. The NVIDIA inference platform is now integrated with cloud providers, including AWS, Microsoft Azure, Google Cloud, and Oracle Cloud Infrastructure, as well as NVIDIA cloud partners Alibaba Cloud, CoreWeave, Crusoe, DigitalOcean, Nebius, Nscale, and Together AI. AI-native companies Cursor, Hebbia, and Perplexity have adopted the platform, as have inference endpoint providers Baseten, Deep Infra, and Fireworks. Global enterprises, including Amazon, AstraZeneca, BlackRock, ByteDance, Coupang, Instacart, Meituan, PayPal, Pinterest, Shopee, and SoftBank Corp., have adopted the NVIDIA inference stack. Dynamo 1.0 is available today to developers worldwide.


 Amazon
Amazon