

NVIDIA has published results for MLPerf Inference v6.0, highlighting system-level gains driven by tight co-design across hardware, software, and models. The company positions inference throughput and token economics as the primary metrics for AI factory performance, moving beyond peak accelerator specifications to measured output under real workloads.
In this round, systems built on NVIDIA Blackwell Ultra GPUs delivered the highest throughput across all submitted models and scenarios. The ecosystem around the platform also expanded, with 14 partners submitting results, including major OEMs, cloud providers, and integrators such as ASUS, Cisco, CoreWeave, Dell Technologies, GigaComputing, Google Cloud, HPE, Lenovo, Nebius, Netweb Technology, QCT, Red Hat, Supermicro, and Lambda.
Expanded Benchmark Coverage Reflects Emerging Workloads
MLPerf Inference v6.0 introduces several new benchmarks to represent current AI deployments better. NVIDIA was the only vendor to submit across all new tests, spanning large language models, multimodal systems, generative video, and recommendation engines.
Key additions include DeepSeek-R1 Interactive, which evaluates higher interactivity with faster token delivery and reduced time to first token compared to prior server scenarios. The suite also adds Qwen3-VL-235B-A22B, marking the first multimodal vision-language model in MLPerf Inference, and GPT-OSS-120B, a mixture-of-experts reasoning model tested across offline, server, and interactive scenarios.
| Scenario | DeepSeek-R1 | GPT-OSS-120B | Qwen3-VL | Wan 2.2 | DLRMv3 |
|---|---|---|---|---|---|
| Offline | 2,494,310 tokens/sec* | 1,046,150 tokens/sec | 79 samples/sec | 0.059 samples/sec | 104,637 samples/sec |
| Server | 1,555,110 tokens/sec* | 1,096,770 tokens/sec | 68 queries/sec | 21 secs** (Single Stream) |
99,997 queries/sec |
| Interactive | 250,634 tokens/sec | 677,199 tokens/sec | *** | *** | *** |
* Not a new scenario in MLPerf Inference v6.0
** Wan 2.2 features a single stream scenario, which measures end-to-end request latency, instead of a server scenario. Lower is better.
*** Not tested in MLPerf Inference v6.0
Generative media and recommendation workloads are now included. The Wan 2.2 text-to-video model features both latency-sensitive and throughput-focused tests, while DLRMv3 replaces previous recommendation benchmarks with a transformer-based architecture that boosts compute intensity and model complexity.
Software Optimization Drives Measurable Gains
A notable aspect of this submission is the performance uplift achieved on existing hardware through software updates. NVIDIA reports up to 2.7x higher token throughput on the GB300 NVL72 platform for DeepSeek-R1 server scenarios compared to results from six months prior. This improvement translates to materially lower cost per token and higher utilization of deployed infrastructure.
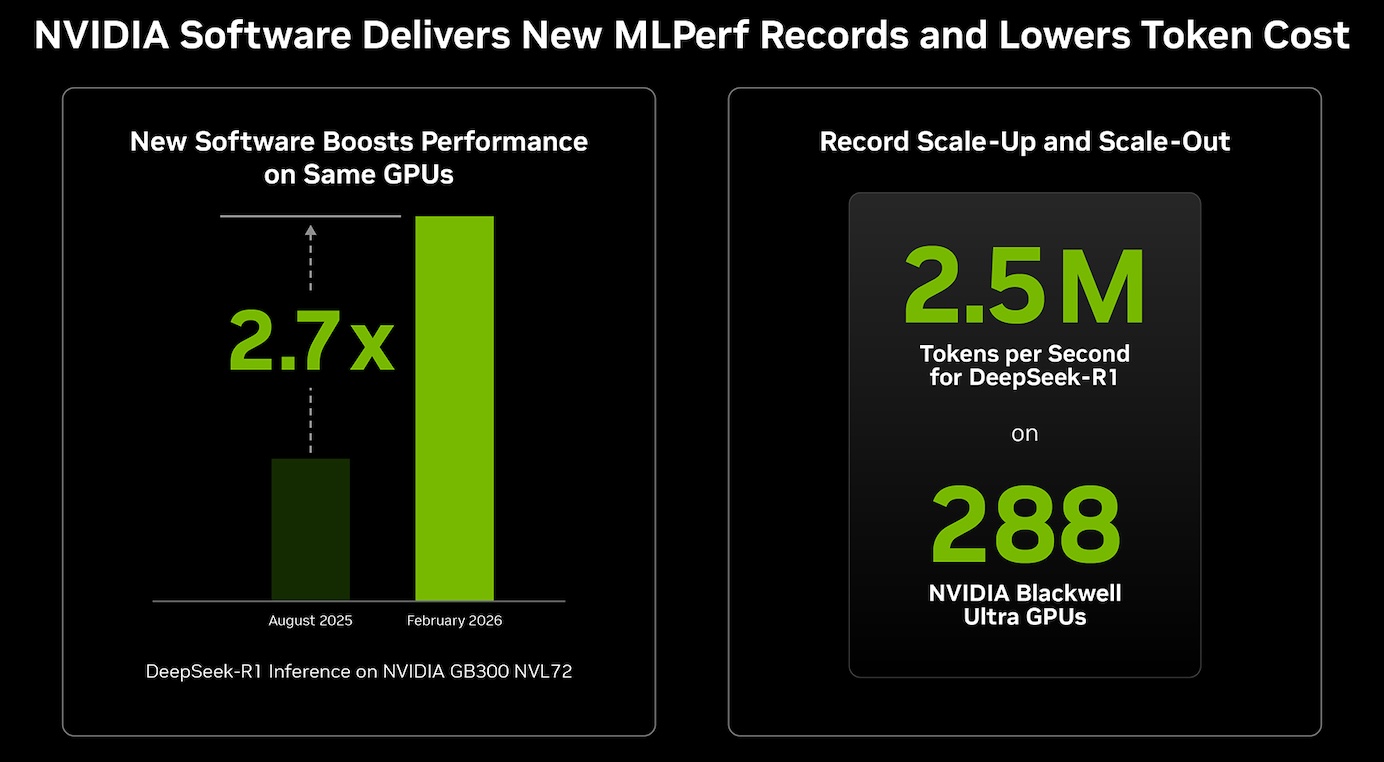
These gains are attributed to updates in the TensorRT-LLM stack and associated frameworks. Kernel-level optimizations and fusion techniques reduce execution overhead, while improved attention data parallelism more effectively balances workloads across GPUs. Additional enhancements in the Dynamo distributed inference framework enable disaggregated serving, allowing independent optimization of prefill and decode phases.
For mixture-of-experts models, techniques like Wide Expert Parallel distribute expert weights across GPUs to reduce memory bottlenecks. Multi-token prediction boosts compute efficiency in low-batch, latency-sensitive scenarios by generating and validating multiple tokens at once. KV-aware routing further enhances scheduling by directing inference requests based on estimated compute costs.
| Benchmark | GB300 NVL72 v5.1 |
GB300 NVL72 v6.0 |
Speedup |
|---|---|---|---|
| DeepSeek-R1 (Server) |
2,907 tokens/sec/gpu | 8,064 tokens/sec/gpu | 2.77x |
| DeepSeek-R1 (Offline) |
5,842 tokens/sec/gpu | 9,821 tokens/sec/gpu | 1.68x |
| Llama 3.1 405B (Server) |
170 tokens/sec/gpu | 259 tokens/sec/gpu | 1.52x |
| Llama 3.1 405B (Offline) |
224 tokens/sec/gpu | 271 tokens/sec/gpu | 1.21x |
NVIDIA also demonstrated continued scaling on established models. On Llama 3.1 405B, the GB300 NVL72 platform achieved a 1.5x performance increase in server scenarios, indicating ongoing optimization for dense LLMs alongside newer architectures.
Open Ecosystem and Framework Integration
Submissions across new workloads leveraged a mix of NVIDIA and open-source frameworks. The Qwen3-VL benchmark used the vLLM framework, reflecting the rapid development in multimodal inference optimization. The Wan 2.2 text-to-video results were powered by TensorRT-LLM VisualGen, targeting diffusion-based pipelines on GPUs.
For DLRMv3, NVIDIA combined its recsys-example framework with GPU-accelerated embedding lookup technologies to handle the increased demands of transformer-based recommendation models. These integrations underscore the role of the broader software ecosystem in extracting performance from the underlying hardware.
Scale-Out Performance with InfiniBand
NVIDIA also showcased large-scale inference performance using four GB300 NVL72 systems connected via Quantum-X800 InfiniBand. This setup, with a total of 288 Blackwell Ultra GPUs, marks the largest MLPerf Inference submission to date and achieved system-level throughput of millions of tokens per second on DeepSeek-R1.
| DeepSeek-R1 | 4x GB300 NVL72 | Tokens/Second |
|---|---|
| Offline | 2,494,310 |
| Server | 1,555,110 |
The results highlight the importance of high-performance interconnects in scaling inference workloads, particularly for distributed LLM serving and high-throughput batch processing.
Toward Service-Level Benchmarking
Looking ahead, NVIDIA is helping develop the MLPerf Endpoints within the MLCommons consortium. This upcoming benchmark aims to measure deployed inference services using real API traffic, giving insight into latency, throughput, and efficiency at the service level rather than just at the component level.
As AI workloads develop into agentic systems with longer context windows, benchmarks that measure end-to-end service performance are expected to become more important for both cloud providers and enterprise deployments.


 Amazon
Amazon