

The AI infrastructure market is not moving in a single direction; it is separating into two distinct worlds. On one side are frontier training clusters, built to develop foundation models at a massive scale, tightly coupled to proprietary fabrics and a narrow set of accelerators. The other is the rapidly expanding reality of enterprise inference, where organizations deploy models to serve users, process live data, and generate measurable business value. The Dell PowerEdge XE7740 is designed explicitly for this second world.

Key Takeaways
- The PowerEdge XE7740 is built for enterprise inference, with dual-zone thermals, structured PCIe Gen5 topology, and scale-out networking aligned to real production workloads.
- System balance is intentional, combining Xeon 6 core density, high memory bandwidth, and PCIe Gen 5 E3.S NVMe to support KV cache offload and orchestration.
- Silicon flexibility is foundational, supporting a broad range of PCIe Gen5 accelerators without forcing infrastructure redesign.
- The platform scales cleanly over time, from partial GPU population in a single chassis to distributed inference across racks using eight rear Gen5 x16 dedicated networking slots.
At the core of the XE7740 is a commitment to silicon diversity. Rather than anchoring the platform to a single accelerator roadmap, Dell has built a system that adapts to availability, cost, and organizational readiness. The XE7740 supports a range of PCIe Gen5 accelerators, including NVIDIA’s RTX PRO 6000, H100/200, L40S, L4, and A16 GPUs for organizations that value broad ecosystem compatibility, and Intel Gaudi 3 for teams seeking a more cost-effective, readily available inference path. Gaudi 3 accelerators are available today, allowing organizations to move from planning to deployment without the procurement delays that often shape accelerator strategy.
As inference becomes the dominant AI workload, the availability and cost structure matter. Most enterprises are not training frontier-scale models. They are running inference pipelines, serving mid-size language models, powering retrieval-augmented generation workflows, and deploying computer vision in production. In this context, Gaudi 3 is positioned as one of the most affordable modern inference accelerators on the market, offering a contemporary architecture with high-bandwidth memory and Ethernet-based scale-out without the cost profile of flagship training GPUs. Within the XE7740, Gaudi 3 is less about displacement and more about enabling sustainable inference deployments.
The platform surrounding the accelerators is equally deliberate. The XE7740 is built on Intel Xeon 6 processors, and in inference-focused systems, the CPU remains a critical component. High core counts and increased memory bandwidth provide the headroom required for schedulers, tokenization, preprocessing, and orchestration tasks that sit directly on the inference critical path. Front-mounted E3.S NVMe storage further supports local data staging and KV cache offload, reducing accelerator load and improving overall system efficiency. This balanced design reflects an understanding that inference performance is shaped by the entire system, not by accelerators alone.

The XE7740 is also engineered to scale cleanly over time. Organizations can begin with a modest configuration, such as two or four accelerators, and extract immediate value without fully populating the chassis. As requirements grow, the same platform can scale vertically or transition into distributed inference. Eight rear-facing PCIe Gen5 x16 slots deliver dedicated bandwidth for high-speed networking, enabling the XE7740 to serve as a building block for scale-out inference clusters. Optional DPU support extends this flexibility further by offloading networking and communication tasks as deployments mature.
Key Dell PowerEdge XE7740 Specifications
| Specification | PowerEdge XE7740 |
|---|---|
| Features of PowerEdge XE7740 | |
| Processor | Two Intel® Xeon® 6 series processors, with up to 86 cores per processor |
| Slots | |
| PCIe Accelerators | 8x PCIe Gen 5 x16 DW-FHFL up to 600 W, or
16x PCIe Gen 5 x16 SW-FHFL up to 75 W |
| PCIe NICs |
|
| Form factor | |
| Form factor | 4U rack server |
| Memory | |
| DIMM speed, maximum capacity | Up to 6400 MT/s, 4 TB max |
| Memory module slots | 32 DDR5 DIMM slots Supports registered ECC DDR5 RDIMM only. |
| Storage | |
| Front bays | Up to 8 x EDSFF E3.S Gen5 NVMe (SSD) max 122.88 TB |
| Storage controllers | |
| Internal boot | Boot Optimized Storage Subsystem (BOSS-N1 DC-MHS): HWRAID 1, 2 x M.2
NVMe SSDs |
| Power supply | |
| Power supply | 3200 W Titanium 200-240 V AC or 240 V DC, hot swap redundant
Multi-capacity for 3200 W PSU:
Multi-capacity for 2400 W PSU:
CAUTION: The system requires at least one PSU in the CPU zone and one PSU in the GPU zone to maintain BMC and standby power. If the GPU zone has no PSU installed, then the system will remain on hold. To ensure full redundancy, install N+N PSUs in each zone: 1+1 in the CPU zone and 3+3 in the GPU zone. Removing all PSUs from the CPU zone while the system is powered on will cause an immediate shutdown and may result in data loss. |
| Cooling Options | |
| Cooling Options | Air Cooling |
| Fans | Up to four sets of high-performance (HPR) platinum-grade fans (dual fan module) installed in the mid tray
Up to twelve high-performance (HPR) platinum-grade fans installed on the front of the system All are hot-swap fans |
| Ports | |
| Network options | 1 PCIe Gen 5 OCP 3.0 Compatible I/O (supported by x8 PCIe lanes) |
| Front ports | 1 x USB 2.0 Type-A (optional) 1 x Mini-Display port (optional) 1 x USB 2.0 Type-C dual mode (Host/iDRAC Direct port) |
| Rear ports | 1 x Dedicated iDRAC/BMC Direct Ethernet port 2 x USB 3.1 Type A port 1 x VGA |
| Internal ports | 1 x USB 3.1 Type-A |
XE7740 Design and Build
Dual-Zone Architecture: CPU and GPU Separation
One of the most distinctive design choices in the XE7740 is its physical separation into two distinct thermal and power zones. The upper 1U section houses the CPU zone, comprising both Xeon 6 processors, all 32 DIMM slots, the storage, and the DC-SCM management module. The CPU zone uses four sets of high-performance dual-fan modules (40×40×56mm) that supply 47.4 CFM of airflow.

The lower 3U section is the GPU zone, containing all accelerator slots with their own dedicated cooling infrastructure, alongside the PCIe Base Board (PBB), rear-facing PCIe expansion slots, and OCP NIC connectivity. The GPU zone employs twelve larger high-performance fans (60×60×56mm) with significantly higher airflow capacity up to 122.2 CFM per fan compared to the CPU fans. All fans are hot-swappable. This dual-zone cooling approach means that the thermal demands of high-TDP accelerators (up to 600W per card) do not compromise CPU and memory cooling, and vice versa, in a 19-inch standard rack.

Dell has paid close attention to airflow optimization in the XE7740. Accelerator-dense systems inherently require substantial internal cabling, including GPU auxiliary power leads, PCIe signal cables between the HPM board and the PBB, and fan board connections. In the XE7740, these cables are routed along the side walls of the chassis using dedicated cable-holding brackets and cable-cover assemblies. Each cable is built to the exact length required; there’s no excess cable bundles inside the system. By keeping cabling out of the central airflow channel, the design preserves a clear front-to-rear airflow path and minimizes impedance across both the CPU and GPU cooling zones.

In a chassis housing up to eight 600W accelerators, even small obstructions in the airflow path can create localized hot spots and force fans to run at higher speeds—increasing both power consumption and acoustic output. Dell’s cable management approach keeps the center of the chassis clear for direct, unobstructed airflow over the components that need it most.
PCIe Switch Topology and Data Flow
The XE7740’s PCIe subsystem is built around four PCIe Gen 5 switches on the PBB (PCIe Base Board), designated SW1 through SW4. These switches form the backbone of the system’s I/O architecture, connecting accelerators, networking, and storage to the two Xeon 6 processors in a carefully organized topology.
The 16 internal GPU slots are divided into two banks of eight, with each bank served by a pair of PCIe switches, each connected upstream to a CPU. Within each bank, pairs of adjacent double-width GPU slots interleave across the two switches. On the CPU0 side, SW1 serves GPU slots 21 and 25, as well as rear PCIe slots 8 and 9, while SW2 serves GPU slots 23 and 27, as well as rear PCIe slots 6 and 7. On the CPU1 side, SW3 serves GPU slots 29 and 33, as well as rear PCIe slots 3 and 4, while SW4 serves GPU slots 31 and 35, as well as rear PCIe slots 1 and 2.

Each CPU domain, therefore, owns four double-width accelerator slots, four rear-facing NIC/I/O slots, and four of the eight front-facing E3.S NVMe storage bays. This switch topology has significant implications for data flow, particularly for RDMA-based traffic. Because each switch hosts both accelerator and rear NIC slots, an accelerator and a network adapter on the same switch can perform RDMA transfers entirely within the switch fabric. The data never needs to traverse the CPU’s root complex, eliminating the CPU bounce buffer that would otherwise be required when a PCIe device on one root port communicates with a device on another. This reduces latency, avoids consuming precious CPU memory bandwidth, and frees CPU cycles for other work.

Communication within a single CPU’s domain between its two switches routes through the CPU root complex but stays local to that socket. Cross-CPU communication, however, must traverse the UPI links between the two Xeon 6 processors. The 6787P provides four UPI 2.0 links at 24 GT/s each, offering substantial inter-socket bandwidth. However, traffic between an accelerator on CPU0’s switch bank and a NIC on CPU1’s switch bank will inherently carry higher latency than switch-local or same-socket transfers.
The switches themselves are not directly interconnected. All cross-switch traffic routes through the CPU root complex, so understanding the affinity between GPU slots, NIC slots, storage, and CPU sockets is important. To simplify this complexity for organizations, Dell offers validated and optimized configurations for popular accelerators.
Dual-Zone Power Supply
The XE7740’s power delivery mirrors its thermal architecture with a somewhat unusual dual-zone PSU design. The system supports up to eight hot-swappable power supply units, divided across two zones: Zone 1 (CPU zone) holds PSUs 1 and 2, while Zone 2 (GPU zone) holds PSUs 3 through 8.

The system requires at least one PSU in each zone to maintain BMC and standby power. If either zone loses AC power while the system is running, the system immediately shuts down to prevent data loss. The zones are interdependent for operation, even though they are physically and electrically separated. For full redundancy, Dell recommends a 1+1 configuration in the CPU zone and a 3+3 configuration in the GPU zone, meaning all eight PSU bays should be populated for a fully redundant deployment.

Dell AIOps, Management, and Enterprise Reliability
Dell’s PowerEdge platform has earned a reputation in the industry for reliability and serviceability. Enterprise customers consistently highlight the same themes: PowerEdge systems are built to last, Dell’s support organization resolves issues quickly, and the management tooling is mature and well-integrated. The XE7740 continues this tradition, and Dell has made meaningful advances in both hardware management and security with this generation.
iDRAC 10
The XE7740 ships with Dell’s next-generation iDRAC 10, a substantial facelift over the already capable iDRAC 9 that Dell customers have relied on for years. Implemented as a Data Center Secure Control Module (DC-SCM) in accordance with the OCP DC-MHS standard, iDRAC 10 is not merely a firmware update; it represents new hardware. The controller features four 1 GHz cores with a 64-bit architecture and 2 GB of DDR4 memory (twice that of the previous generation), delivering significantly improved performance and responsiveness for management operations.
On the security front, iDRAC 10 introduces several notable enhancements. The platform features stronger cryptographic support across the board, including SHA-384 and SHA-512 authentication and quantum-safe AES-256 encryption, as the industry prepares for post-quantum cryptographic threats. A dedicated integrated security enclave within the iDRAC 10 silicon manages cyber resiliency functions, including device-level attestation and Dell’s custom Root-of-Trust. This hardware-based Root-of-Trust ensures that all firmware (BIOS, iDRAC, and component firmware) is cryptographically verified before execution, protecting against supply chain attacks and firmware tampering.
Secured Component Verification validates that systems delivered from Dell’s factory arrive with the exact components and configurations specified by the customer, maintaining integrity from manufacturing through deployment. The latest iDRAC 10 firmware also delivers a refreshed, modular user interface that improves the day-to-day administrative experience.
OpenManage Enterprise
For fleet management at scale, Dell’s OpenManage Enterprise provides centralized monitoring, firmware updates, and configuration management across entire PowerEdge deployments. A notable recent addition for AI-focused deployments is that OME now supports direct visibility into GPU and accelerator statistics: power consumption, temperature, utilization, error counts, and more, without requiring separate vendor-specific tools. For organizations managing dozens or hundreds of XE7740 nodes in an inference cluster, this unified management plane is a significant operational simplification.
Intel Xeon 6
At the heart of the XE7740 are two Intel Xeon 6 6787P processors, the flagship of the Xeon 6700P series. Built on the Granite Rapids architecture using Intel 3 nm technology, the 6787P delivers 86 P-cores (172 threads) per socket at a 350W TDP, with a base clock of 2.0 GHz and a turbo clock of 3.8 GHz.
What makes Granite Rapids particularly relevant for AI infrastructure is its combination of high core counts and its memory subsystem. Each 6787P processor provides eight DDR5 memory channels at up to 6400 MT/s. With a dual-socket XE7740 populated with 32 DIMMs, the system can be configured for up to 4 TB of total system memory.

Memory capacity and bandwidth are critical for AI workloads, especially when employing KV cache offloading. As large language models increase context length, the KV cache scales proportionally and can consume a significant amount of accelerator memory. Offloading portions of the KV cache to system memory or fast storage enables the accelerator’s HBM to be used more efficiently for active computation, reducing time to first token (TTFT) for multi-turn chats.
It’s also worth noting the Xeon 6’s AMX tensor units, which handle significant work on the CPU side. These include preprocessing, tokenization, and hybrid inference tasks that involve matrix ops. This becomes especially useful with inference frameworks like SGLang, which use the CPU for Radix Tree for KV Cache Management and Zero Overhead scheduling.
Intel Gaudi 3 Add-in Cards: Competitive Inference at Scale
Intel’s Gaudi 3 is the Company’s flagship AI accelerator, launched in Q4 2024. Intel is positioning these accelerators very aggressively rather than competing head-to-head with the highest-tier data center training accelerators. The Gaudi 3 is being aimed squarely at the inference segment.

Transformer-based model inference in all popular LLMs today is fundamentally memory-bound. During the decode phase of autoregressive generation, the model generates tokens one at a time, reading the model weights and KV cache entries for each token produced. The bottleneck is not compute capabilities but the memory bandwidth, which is how quickly the accelerator can stream data from HBM to the compute engines.
The Gaudi 3 features 128 GB of HBM2e with 3.7 TB/s of memory bandwidth. Architecturally, the Gaudi 3 is built on TSMC’s 5nm process and uses a dual-die chiplet design: two identical silicon dies joined by a high-bandwidth interconnect, presenting as a single unified device to software. Compute is organized into four Deep Learning Cores (DCOREs), each containing 2 MMEs, 16 TPCs, and 24 MB of local SRAM cache. The total 96 MB of on-die SRAM provides 12.8 TB/s of internal bandwidth. The accelerator also integrates 14 dedicated media decoders (H.265, H.264, JPEG, VP9), enabling fast vision preprocessing for multi-modal workloads.

A large chunk of the frontier open-source AI models being released today are either natively FP8-trained or hybrid models that mix FP8 (E4M3) and BF16 weights. The Gaudi 3 provides native FP8 acceleration for these across its 8 Matrix Multiplication Engines and 64 Tensor Processor Cores, delivering 1.8 PFlops of FP8 compute.

The Gaudi 3 also integrates RDMA over Converged Ethernet (RoCEv2) networking with 24×200 GbE ports on the OAM version, built directly into the silicon. While the PCIe add-in card variant used in the XE7740 does not expose all of these ports in the same way, the add-in card variants support bridging 4 cards for faster communication between them.
Performance and Benchmarks
XE7740 configuration details:
- 2 x Intel Xeon 6787P Processor (86-Cores, 2.00 GHz)
- 2TB DDR5 (32 x 64GB 5200MT/s DDR5
- 4 x Intel Gaudi 3 PCIe AI Accelerator w/ 128GB of HBM
- Ubuntu 24.04.5 Server
vLLM Online Serving Performance
To evaluate the inference capabilities of the Dell XE7740 powered by Intel Gaudi 3 accelerators, we benchmarked vLLM online serving performance across a range of popular models spanning different architectures, parameter counts, and precision formats. Each model was tested across three workload profiles with concurrent request counts scaling from 1 to 128.
LLM inference consists of two distinct phases. The prefill phase processes all input tokens in parallel before any output token can be generated, making it a compute-bound operation that scales linearly with the number of input tokens. The decode phase then generates output tokens one at a time (autoregressively), where each new token requires reading the full model weights from memory, but performs relatively little per-token computation—making it memory-bandwidth bound.
These two phases stress fundamentally different parts of the accelerator, so we test three workload profiles that shift the balance between them:
- Equal (1024 input/1024 output tokens) represents balanced chat interactions.
- Prefill Heavy (8192 input/1024 output) simulates retrieval-augmented generation or long-context summarization, in which the system must process large input contexts.
- Decode Heavy (1024 input/8192 output) represents long-form content generation where sustained memory bandwidth determines throughput.
We focus on two primary metrics throughout this section. Total token throughput, measured in tokens per second, captures the system’s overall serving capacity under load. Time to first token (TTFT) measures the delay between submitting a request and receiving the first generated token. Because the model must complete the entire prefill phase before it can emit the first token, TTFT is directly tied to the accelerator’s compute throughput. This makes the prefill-heavy scenario (combined with TTFT) a particularly useful proxy for understanding the raw compute capabilities of the Gaudi 3 accelerators, since the system must process all 8,192 input tokens before the user sees any response.
Conversely, the decode-heavy scenario tests the accelerators’ memory bandwidth, as the system must sustain high throughput for thousands of generated tokens. TTFT is critical for interactive applications in which users wait for a response before streaming can begin. A system can achieve excellent throughput under heavy batching but still feel sluggish if TTFT rises too high, so both metrics matter for production deployments.
A note on FP8 precision results: while Intel Gaudi 3 accelerators include native FP8 compute acceleration (and FP8 should, in theory, deliver higher throughput than BF16), the FP8 performance numbers in our benchmarks are lower than their BF16 counterparts. This is not a hardware limitation but rather a software maturity issue within Intel’s fork of vLLM. The version we tested (vLLM installer 2.7.1 on Gaudi Docker 1.22.2) has not yet fully optimized its FP8 code paths. Intel has a new plugin-based version of vLLM currently in beta that may address many of these performance challenges.
Llama 3.1 8B Instruct
Llama 3.1 8B Instruct is a dense transformer model from Meta, meaning every parameter is active for every token generated. With 8 billion parameters, it is among the more open-source models. Models in this size class are popular for everyday tasks such as summarizing short documents, drafting emails and messages, answering straightforward questions, and powering simple chatbot interactions where speed and cost efficiency matter more than deep reasoning.
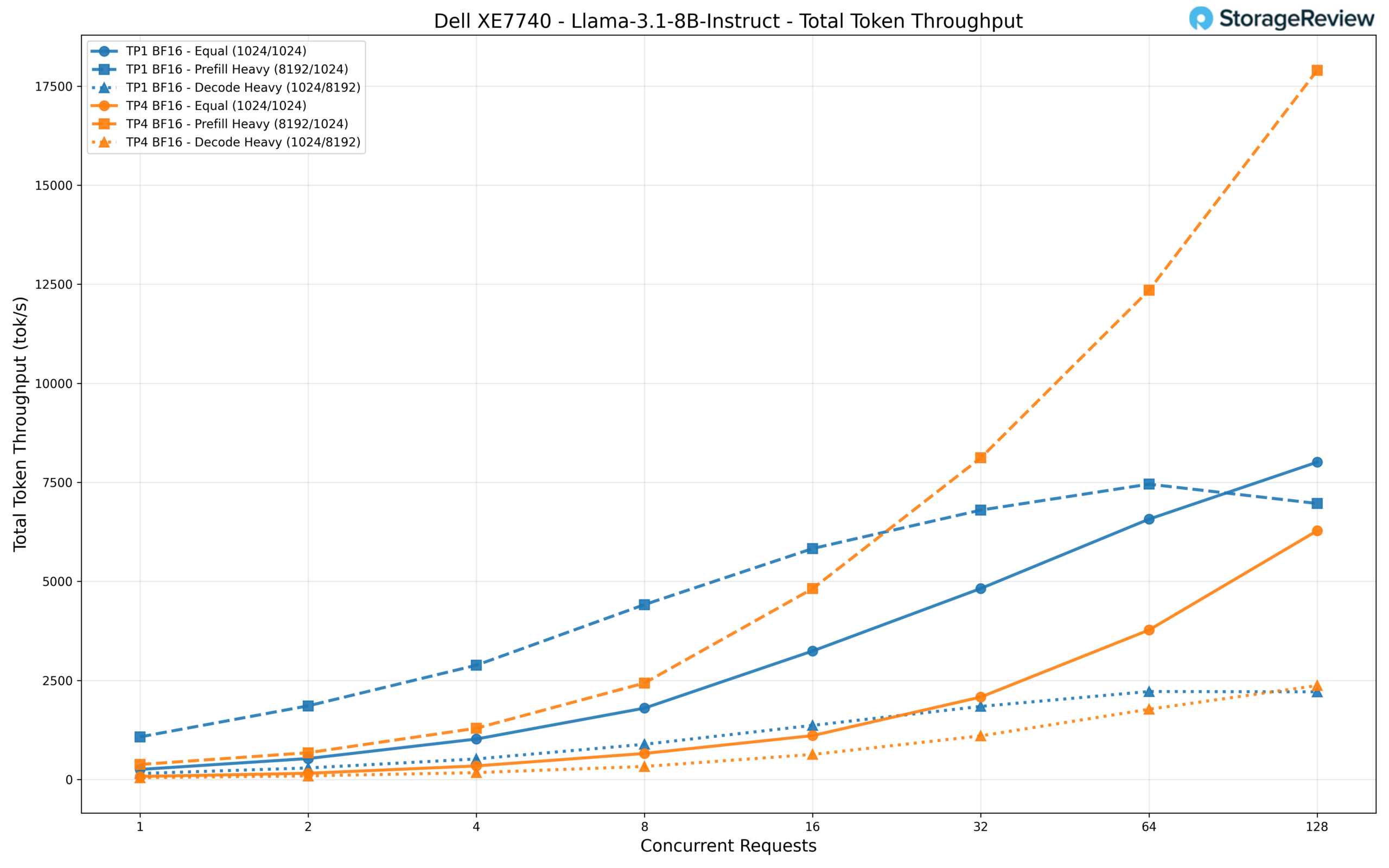
We tested this model in both TP1 (single accelerator) and TP4 (all four Gaudi 3 accelerators) configurations. Running on TP1, the model achieves roughly 8,000 tok/s total throughput at 128 concurrent requests in the equal workload, scaling cleanly from around 250 tok/s at a single request. The prefill-heavy scenario shows an interesting pattern: while TP1 peaks at around 7,000 tok/s, TP4 surges to over 17,900 tok/s at 128 concurrent requests, leveraging additional accelerators to process the large input context more efficiently.
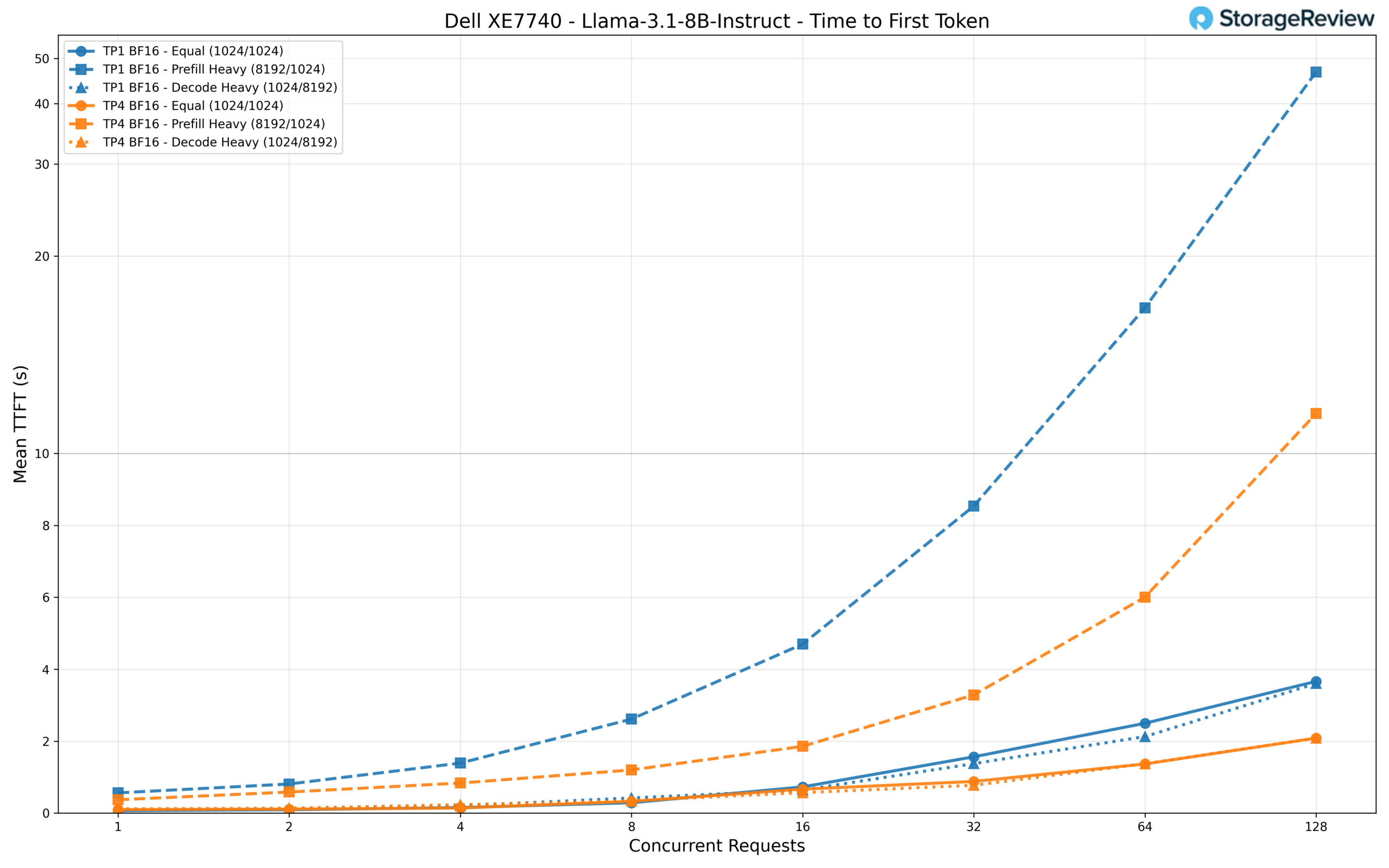
For single-user latency, TP1 actually delivers lower TTFT at low concurrency (67ms versus 98ms for TP4), reflecting the overhead of coordinating across four accelerators for a model that fits comfortably on one. As the load increases, however, TP4 pulls ahead decisively. At 128 concurrent requests, TP4 holds TTFT to around 2 seconds for equal and decode workloads, while TP1 climbs to 3.7 seconds and 6.6 seconds, respectively. The prefill-heavy scenario is where the gap becomes most dramatic: TP1 reaches nearly 47 seconds of TTFT at 128 requests, while TP4 keeps it to around 11 seconds.
Llama 3.1 70B Instruct
Llama 3.1 70B Instruct is the larger dense model in Meta’s Llama 3.1 family. With 70B parameters, it delivers substantially better instruction-following and multilingual capabilities than the 8B variant. Models at this scale are well-suited for more intensive agentic workloads, such as customer support agents, multi-step research assistants, complex document analysis, and tasks that require maintaining coherent context over longer interactions.
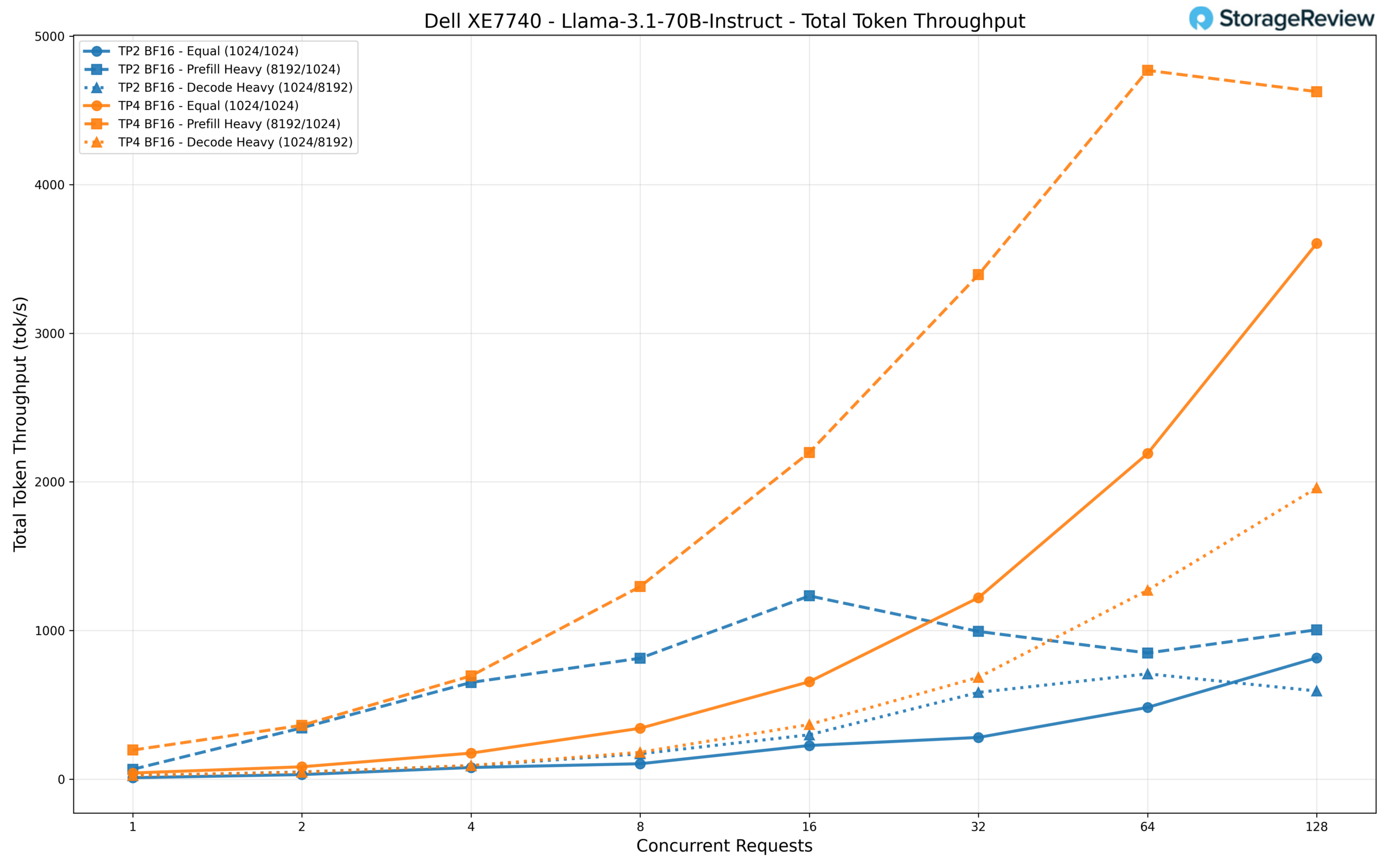
We tested this model with TP2 and TP4 configurations. The throughput difference between the two is substantial. At 128 concurrent requests, TP4 delivers roughly 3,600 tok/s in the equal workload and peaks near 4,600 tok/s in the prefill-heavy scenario. This is approximately 4.4x and 4.6x the throughput of TP2, which maxes out around 816 tok/s and 1,005 tok/s, respectively. Even the decode-heavy workload reaches about 1,960 tok/s on TP4, compared with 593 tok/s on TP2.
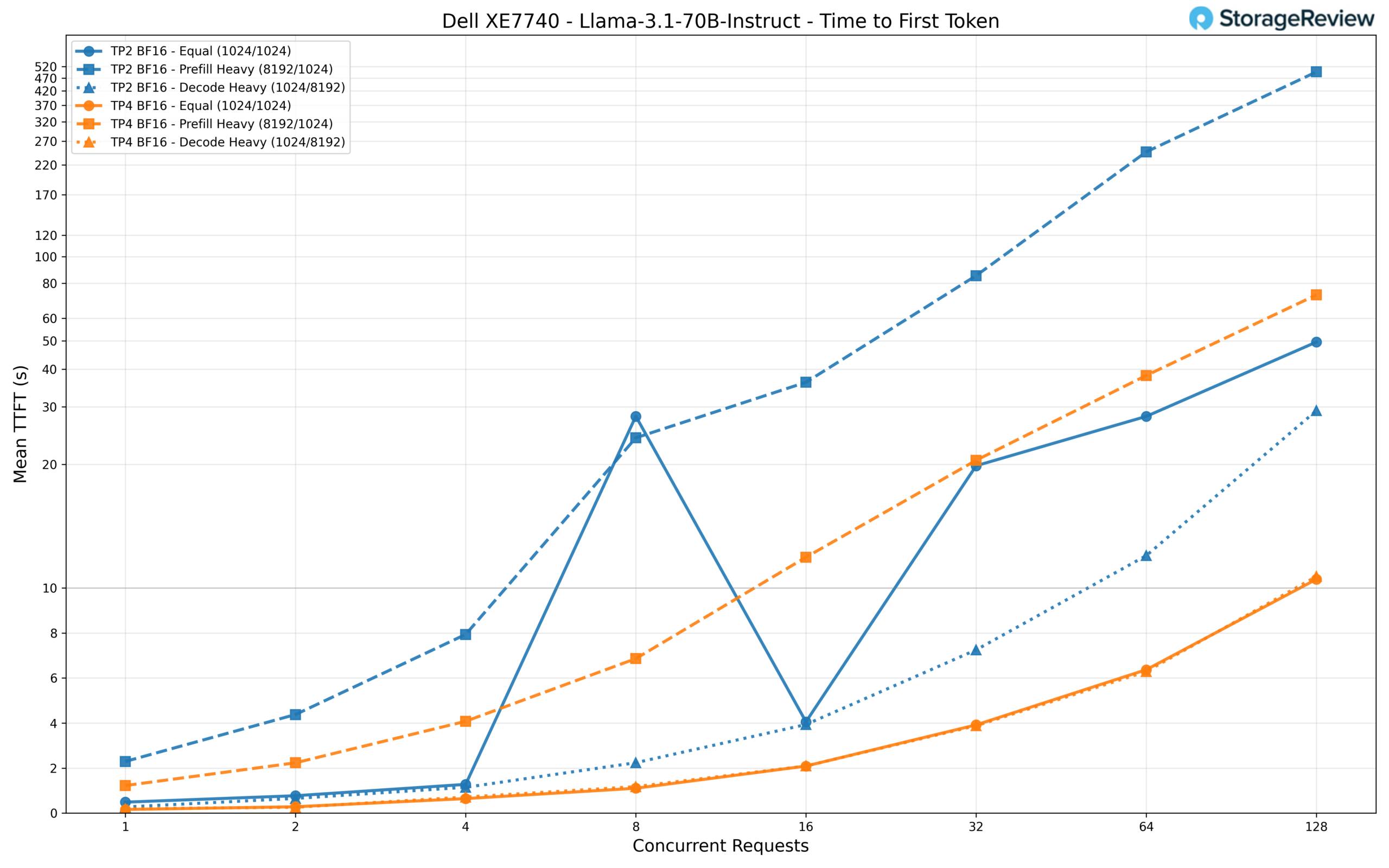
For TTFT, TP2 struggles under load with the prefill-heavy workload, climbing to a staggering 496 seconds at 128 concurrent requests, making it essentially unusable for interactive applications. TP4 brings this down to around 73 seconds. For the equal and decode workloads, TP4 holds TTFT to roughly 10 seconds at 128 requests, while TP2 reaches 50 and 29 seconds, respectively. At low concurrency, TP4 delivers first-token responses in about 160ms for the equal workload, compared to 486ms on TP2.
Qwen3 Coder 30B-A3B Instruct
Qwen3 Coder 30B-A3B is one of the most popular coding models for local inference deployments and uses a Mixture-of-Experts (MoE) architecture. Unlike dense models, where every parameter participates in every forward pass, MoE models route each token through a small subset of specialized expert networks. The Qwen3 Coder maintains a full model size of 30B parameters at BF16 precision while activating only 3B parameters per generated token. This sparse activation pattern means the model can deliver the quality of a much larger network while requiring only a fraction of the compute per token, making it extremely efficient on hardware that supports the routing overhead. For end users, this model is well-suited to everyday coding assistance, such as generating boilerplate, completing functions, explaining code, writing unit tests, and handling routine development tasks that benefit from a code-specialized model without requiring heavyweight reasoning.
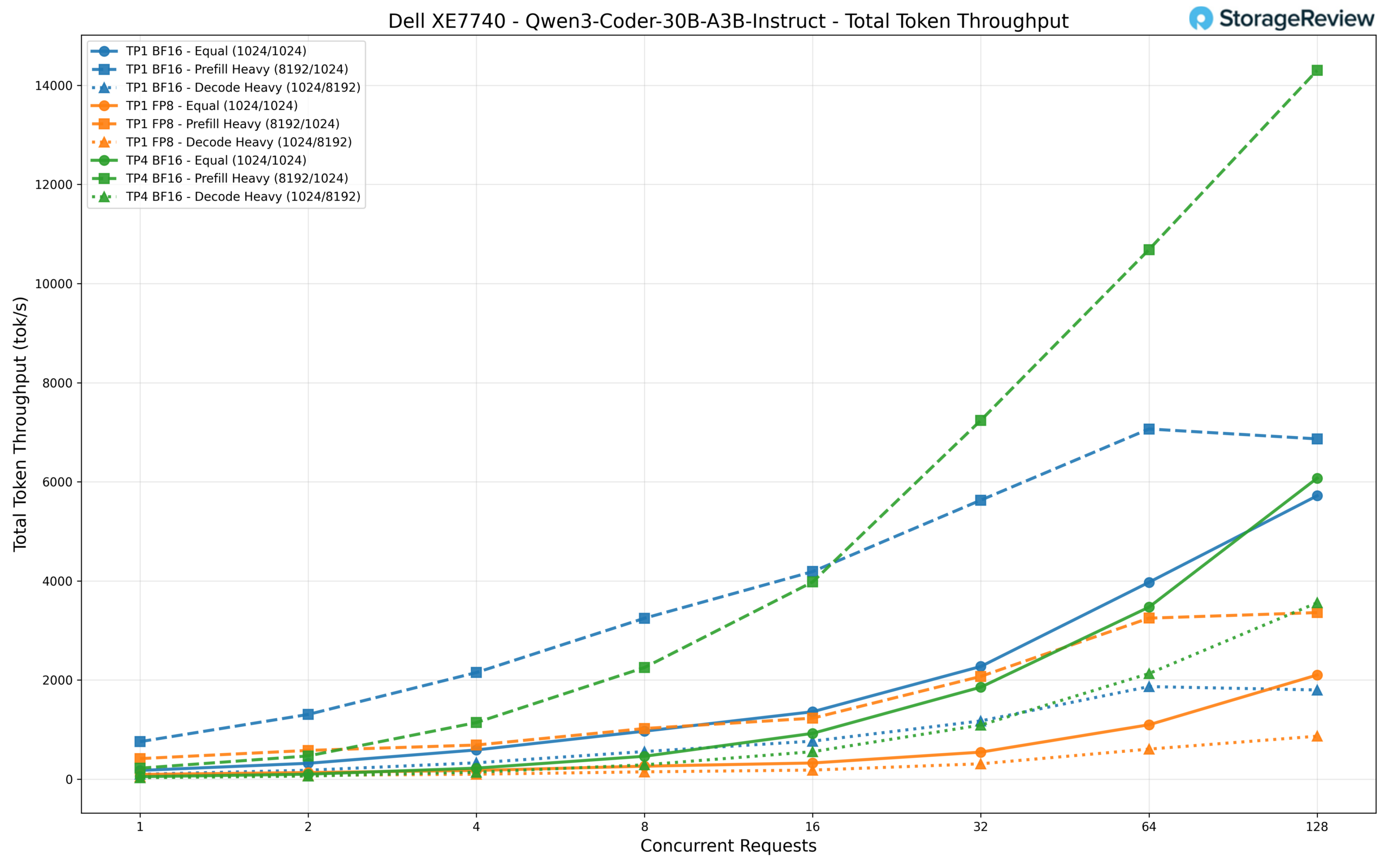
We tested three configurations: TP1 BF16, TP1 FP8, and TP4 BF16. At 128 concurrent requests, TP4 BF16 leads the pack with roughly 14,300 tok/s in the prefill-heavy scenario, the highest throughput figure we recorded across any model in our test suite. TP1 BF16 follows with about 6,900 tok/s in the same scenario, while TP1 FP8 trails at around 3,360 tok/s. In the equal workload, the gap narrows somewhat with TP4 at 6,073 tok/s, TP1 BF16 at 5,718 tok/s, and TP1 FP8 at 2,101 tok/s. As discussed in the FP8 note above, the lower FP8 numbers here reflect the current state of Intel’s vLLM fork rather than a hardware bottleneck.
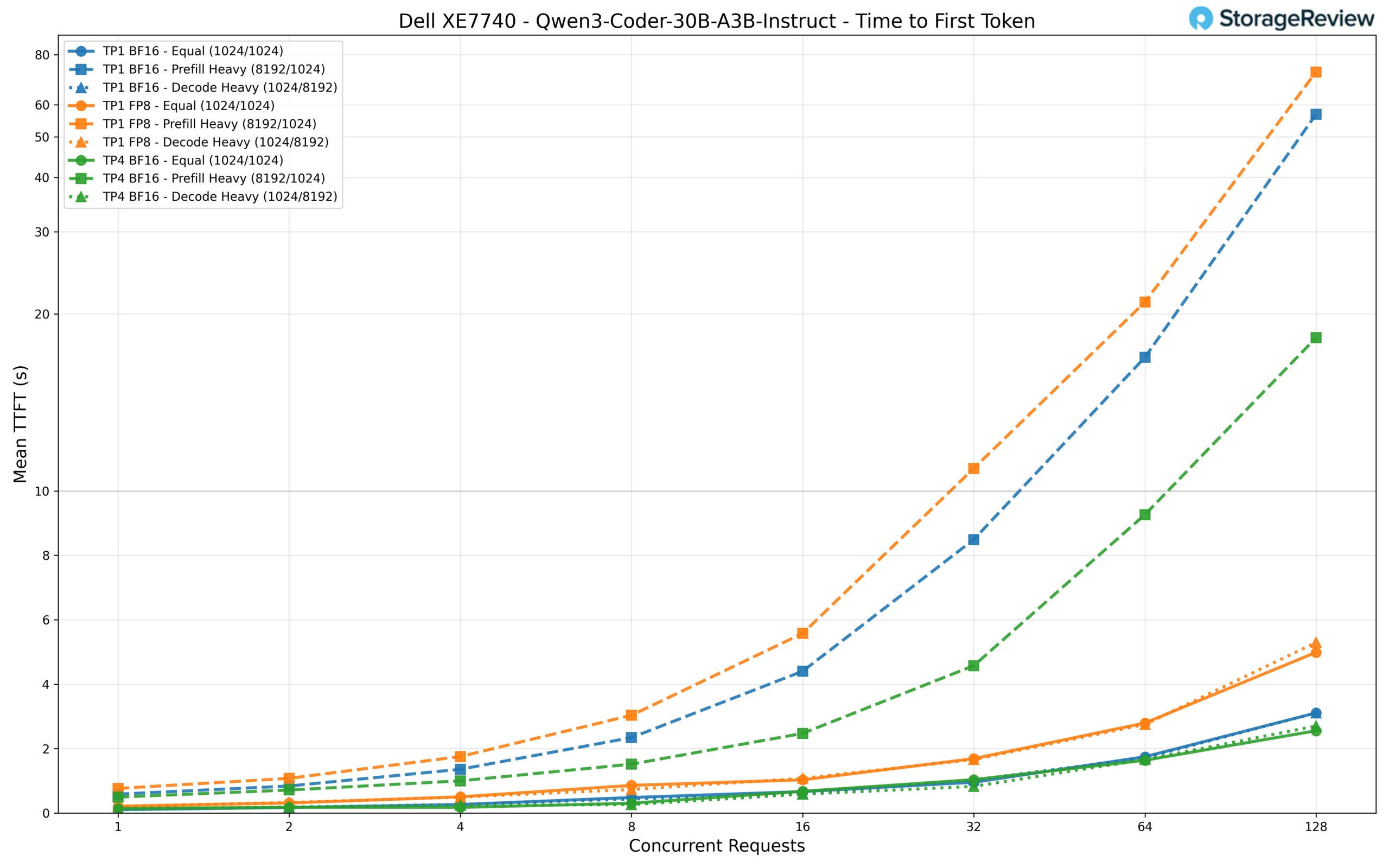
TTFT stays low thanks to the sparse activation pattern. TP4 BF16 delivers first-token latency of around 140ms at single-user load and holds to roughly 2.6 seconds at 128 concurrent requests in the equal workload. TP1 BF16 is comparable at low concurrency (106ms) but climbs to 3.1 seconds under full load. The prefill-heavy scenario again clearly differentiates the configurations: TP4 reaches about 18 seconds at 128 requests, TP1 BF16 hits 57 seconds, and TP1 FP8 extends to 72 seconds.
Qwen3 235B-A22B Thinking
The largest model in our benchmark suite, Qwen3 235B-A22B Thinking, is a massive MoE reasoning model with 235B total parameters and 22B active parameters per token. Beyond its sheer scale, this model includes built-in chain-of-thought reasoning capabilities, allowing it to break down complex problems step by step before arriving at an answer at the cost of more decode tokens. This makes it particularly well-suited for the most challenging tasks: advanced code generation and debugging, mathematical problem-solving, multi-step logical reasoning, and complex, agentic workflows where accuracy matters more than raw speed. This model requires TP4 to run, and we tested it in both BF16 and FP8 precision.
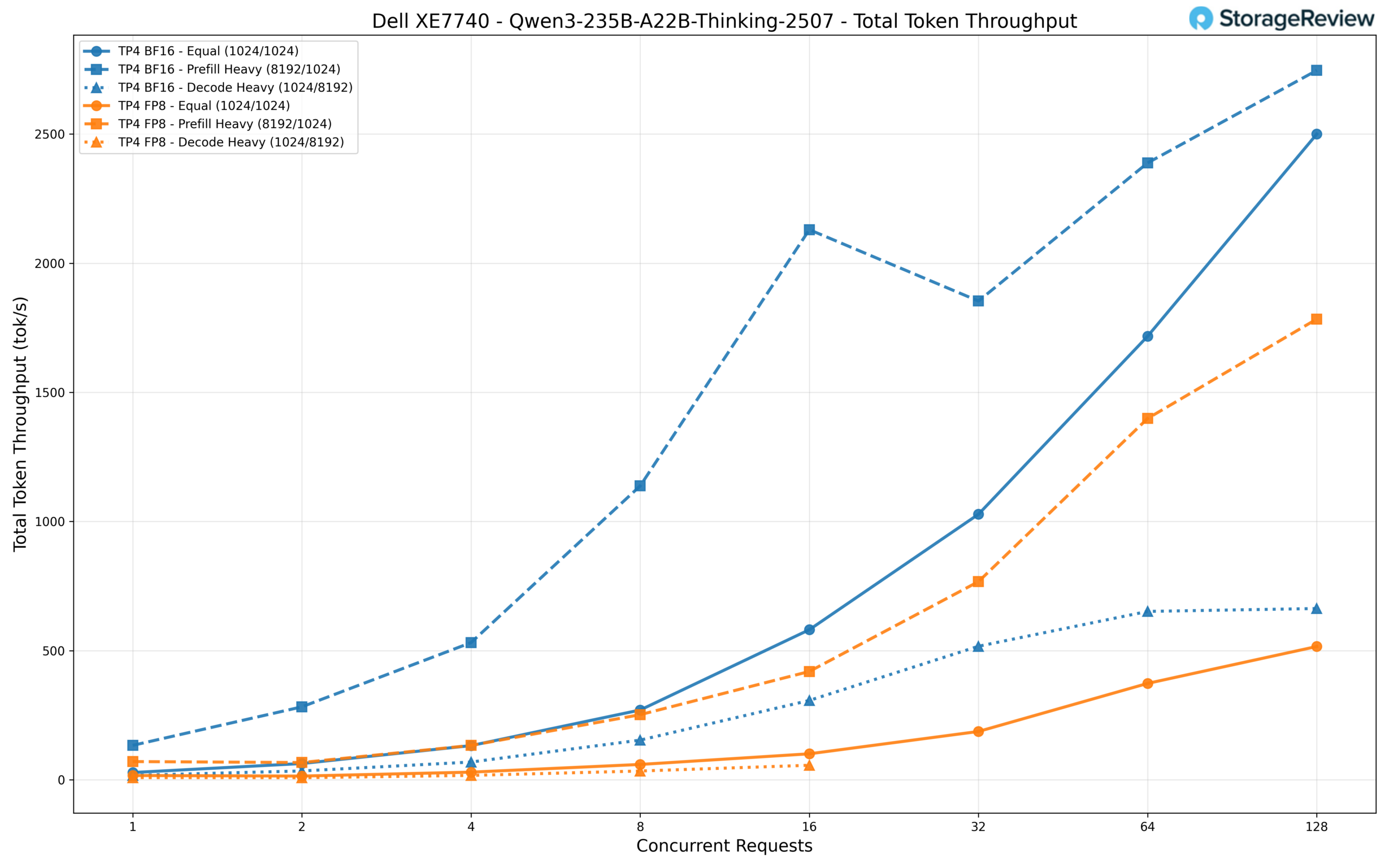
BF16 clearly outperforms FP8 across the board. At 128 concurrent requests, BF16 reaches approximately 2,750 tok/s in the prefill-heavy workload and 2,500 tok/s in the equal workload, while FP8 manages about 1,784 tok/s and 516 tok/s, respectively. The FP8 variant also experienced timeouts in the decode-heavy scenario at higher concurrency levels (32+ requests).
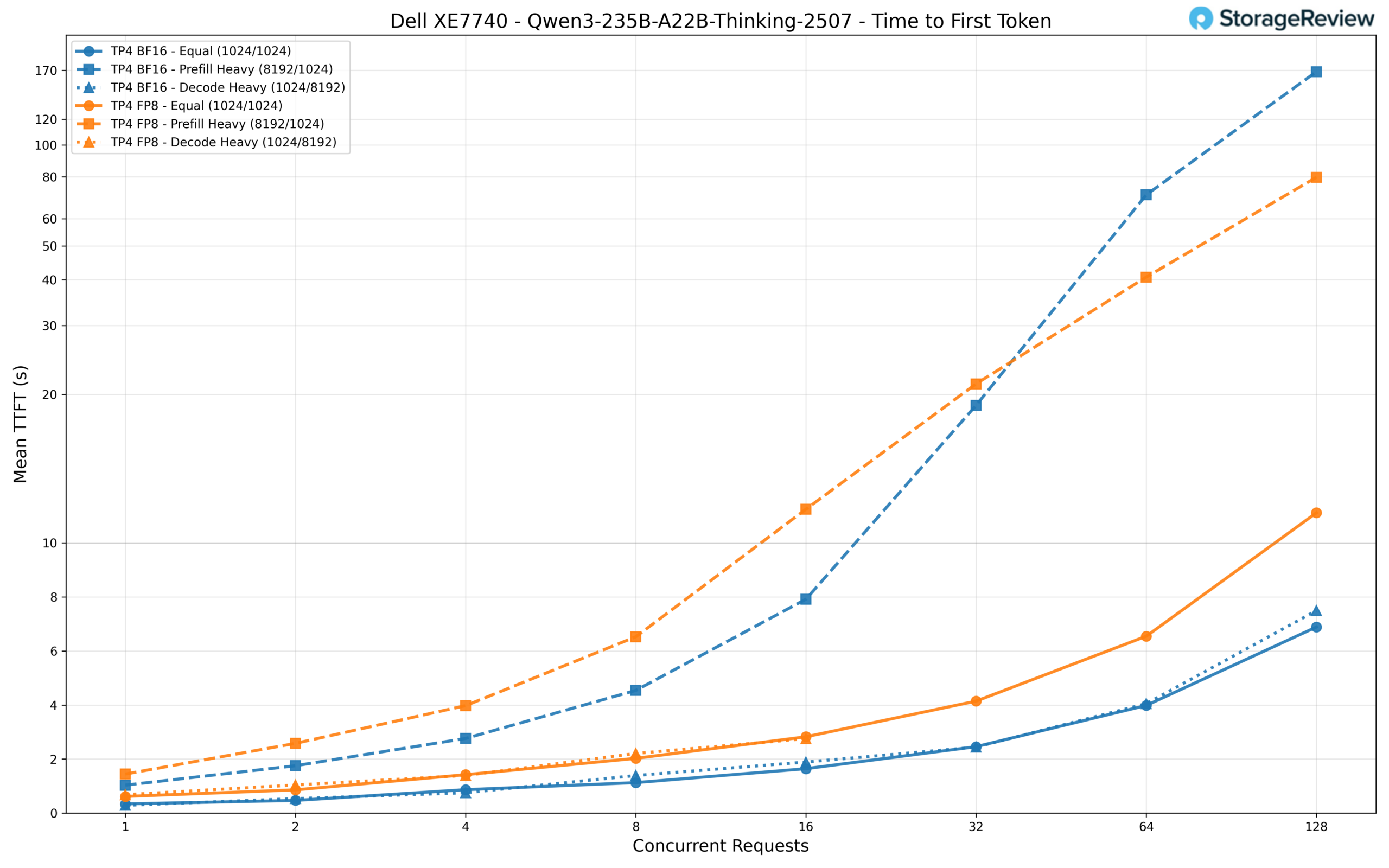
For TTFT, BF16 starts at around 340ms for a single equal-length request and scales to approximately 6.9 seconds at 128 concurrent requests. This is quite responsive for a model of this scale. FP8 is roughly 2x slower throughout, beginning at 615ms and reaching about 11.2 seconds at full load. The prefill-heavy workload is the most demanding scenario, with BF16 climbing to 168 seconds and FP8 to 80 seconds at 128 requests.
Who is this for?
Inference demand is not slowing down. Whether organizations are deploying models internally to accelerate developer teams, embedding AI into customer-facing products, or standing up automation pipelines that run around the clock, the compute requirements keep rising. And with that demand comes a familiar bottleneck: procurement. Lead times on popular accelerators can stretch for months, stalling projects that have already been funded and staffed.

The XE7740, configured with Intel Gaudi 3, addresses this constraint directly. Gaudi 3 accelerators are available now, and Intel provides validated deployment templates so teams can move from unboxing to serving inference in hours. Dell further lowers the barrier with try-and-buy programs that place XE7740 systems directly in your environment, letting you validate performance against your actual workloads, data, and infrastructure before committing to a full rollout. That combination of immediate availability, fast time-to-value, and low-risk evaluation makes the Gaudi 3 configuration particularly attractive for organizations that need inference capacity today and cannot afford to wait on allocation queues.
That said, the XE7740 is not a single-accelerator platform. With Dell’s commitment to silicon diversity, the same platform can be had with a variety of options and every popular accelerator on the market, and the right choice depends entirely on the workload. Video processing pipelines, for example, are a natural fit for NVIDIA L4s, and the XE7740 can be equipped with 16 L4 GPUs alongside 8 PCIe Gen5 x16 NIC slots for a no-compromise streaming and transcoding system. Organizations running mixed AI workloads across departments can standardize on the XE7740 chassis and simply vary the accelerator configuration to match each deployment, simplifying fleet management while tailoring compute to the task.
Conclusion
The Dell PowerEdge XE7740 is engineered for the realities of enterprise inference. Its dual-zone thermal design, structured PCIe topology, high-bandwidth memory architecture, and scale-out networking capacity form a system built for sustained production workloads. These are not incidental design choices; they reflect an infrastructure model where inference runs continuously, scales predictably, and integrates cleanly into existing data center operations. In this evaluation, Intel Gaudi 3 demonstrates that the XE7740 delivers inference today across dense and MoE architectures, with predictable scaling behavior and strong memory-bound throughput. Software optimizations will continue to improve, but the platform’s architectural foundation is already sound.

More importantly, the XE7740 establishes a durable blueprint for enterprise AI infrastructure. Organizations can standardize on a consistent chassis, management stack, and deployment model while evolving accelerator strategy over time. As models grow, workloads diversify, and inference becomes embedded more deeply in business operations, the need for stable, adaptable infrastructure will only increase. The PowerEdge XE7740 is positioned to meet that trajectory. It delivers the architectural balance, operational maturity, and expansion headroom required for enterprise AI as it moves from rapid adoption to long-term integration.
This report is sponsored by Dell Technologies. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.


 Amazon
Amazon