

Edge servers facilitate real-time decision-making by providing computing resources away from data centers and the cloud. In this article, we run several edge benchmarks on a SuperMicro IoT SuperServer SYS-210SE-31A, a versatile multi-node edge server. Clearly, the engineers had edge inferencing in mind during its conception, as this box was born to inference.
SuperMicro IoT SuperServer SYS-210SE-31A Overview
Our full review of the SuperMicro IoT SuperServer SYS-210SE-31A reveals its promise not only for 5G and IoT but retail and even storage if paired with a PCIe storage card and a high-speed NIC.

This server’s multi-node nature makes it highly versatile. It fits three CPU nodes, each with the following:
- One third-generation Intel Xeon Scalable processor (“Ice Lake”) up to 32C/64T and 205W, with options for 270W chips with special configuration.
- Four fan modules.
- Eight DIMM slots; the memory ceiling is 2TB using 256GB 3DS DIMMS.
- Two M.2 2280/22110 PCIe Gen4 slots.
- Two PCIe Gen4 x16 full-height/half-length and one PCIe Gen4 x16 half-height/half-length.
- One GbE for IMPI 2.0 and a KVM dongle.
Here you can see the nodes pulled out, like mini rackmount servers of their own.

This is the inside of a node. Note how tightly everything fits together.

This server’s main weakness is storage, with in-node storage limited to two M.2 boot drive slots and no native 2.5-inch or 3.5-inch bays. As noted, you could add PCIe storage fairly easily. Network storage is also an option; its connectivity beyond 1GbE is dependent on expansion cards.

Highlighting this server’s edge focus is its ability to operate in environments up to 45 degrees C, with brief stints at 55 degrees C, and its available dust filter.
Edge Inferencing: The Case for Edge Servers
Our feature, Edge Inferencing is Getting Serious Thanks to New Hardware, explains the state of edge computing. Today’s move to the edge would have seemed like a backward move in the legacy days, where the hierarchal “hub and spoke” approach was to get data back to a central location. Real-time decision-making drives today’s move towards the edge, delivering faster insights and response times and less dependency on network connectivity.
Edge inferencing can be done in the cloud, though typically only for non-time-sensitive, non-critical applications. Of course, lack of network connectivity means the cloud is a no-go.
Testing the Edge on the SuperMicro IoT SuperServer SYS-210SE-31A
And now, onto our testing. A GPU’s ability to process data drives edge inferencing, and edge servers typically stick to single-slot, low-profile cards like NVIDIA A2 and the older but popular T4. The SuperMicro IoT SuperServer SYS-210SE-31A we’re evaluating has the T4. Below are the two cards, the T4 on the right, and A2 to the left. The hardware configuration of each node included an Intel Xeon Gold 6330 CPU and 128GB of DDR4 RAM.

And here’s the T4 installed in one of the SuperMicro nodes.

The T4’s 70-watt profile means it gets all its power from the PCIe slot. Its Turing architecture features tensor cores for much better FP32, FP16, INT8, and INT4 precision performance than a CPU could manage. The NVIDIA A2 has a slightly lower 40W to 60W profile but a newer, more efficient architecture. See comparisons between the two cards in our edge inferencing article where we tested them in the Lenovo ThinkEdge SE450.
We are working with the MLPerf Inference: Edge benchmark suite, which compares inference performance for popular DL models in various real-world edge scenarios. In our testing, we have numbers for the ResNet50 image classification model and the BERT-Large NLP model for Question-Answering tasks. Both are run in Offline and SingleStream configurations.
The Offline scenario evaluates inference performance in a “batch mode,” when all the testing data is immediately available, and latency is not a consideration. In this task, the inference script can process testing data in any order, and the goal is to maximize the number of queries per second (QPS=throughput). The higher the QPS number, the better.
By contrast, the Single Stream config processes one testing sample at a time. Once inference is performed on a single input (in the ResNet50 case, the input is a single image), the latency is measured, and the next sample is made available to the inference tool. The goal is to minimize latency for processing each query; the lower the latency, the better. The query stream’s 90th percentile latency is captured as the target metric for brevity.
The image below is from an NVIDIA blog post about MLPerf inference 0.5, which visualizes the scenarios very well. You can read more about the various scenarios in the original MLPerf Inference paper here.
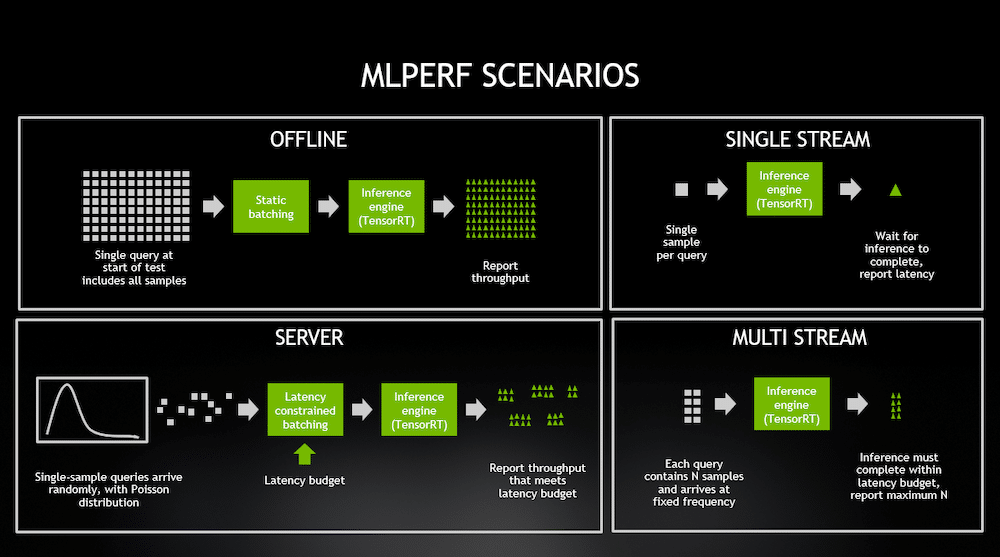
We tested the workload operating on two nodes inside the SuperMicro IoT SuperServer SYS-210SE-31A. The third node was set as a spare.
| Benchmark | Node 1 (NVIDIA T4) | Node 3 (NVIDIA T4) |
| RestNet50 Offline | 5,587 samples/s | 5,492 samples/s |
| BERT SingleStream | 6.8 ms (90th pct) | 7.0 ms (90th pct) |
| BERT Offline | 397 samples/s | 396 samples/s |
The NVIDIA T4 overall impressed. Node 1 showed marginally better performance. That said, the T4 is an older card with a higher power profile than the newer A2. We saw testing the A2 in the ThinkEdge SE450 that it also has lower latency than the T4 in certain spots, while using much less power. The applications and power considerations should determine the choice between the two. For now though, we’re pleased with the density the Supermicro chassis can provide for these types of workloads.
Final Thoughts
The race to the edge brings rapid advancements in edge computing. Nowhere is that more evident than GPUs, specifically low-profile, low-power options like the NVIDIA T4 and newer A2. We tested the T4 in the SuperMicro IoT SuperServer SYS-210SE-31A, a highly versatile three-node edge server.
The T4 showed excellent performance, which is even more impressive considering its age. It does sip a little more power than the A2 though, so select wisely depending on your edge inferencing need. We expect the venerable GPU still has much of its life ahead of it as edge-driven companies continue to optimize GPU utilization.
Further, the Supermicro IoT server is very well equipped to handle these cards, delivering very dense inferencing performance at the edge.


 Amazon
Amazon