

In August, NVIDIA split its top Blackwell desktop offering into two tracks for professionals: Workstation and Server. The RTX PRO 6000 Workstation card is designed for creators, engineers, and AI developers who require maximum compute and VRAM within a tower or desktop chassis. The RTX PRO 6000 Blackwell Server Edition is designed for rack servers and headless inference or rendering nodes in the data center. Now that we have the workstation card on the bench, we can focus on that for this review.

At $8,500, the RTX PRO 6000 brings a full-fat GB202 to the desk with 24,064 CUDA cores, 752 fifth-gen Tensor Cores, 188 fourth-gen RT Cores, and 96 GB of GDDR7 ECC. The appeal is immediately apparent. You get memory capacity that consumer cards cannot match, pro drivers, and a dual-slot form factor that fits real workstations without special power or airflow requirements.
NVIDIA positions this GPU for mixed workflows. That includes local LLM inference with long context, large scene rendering, complex simulation, and multi-GPU research rigs. Practical touches matter here. The card utilizes a standard PCIe 5.0 x16 interface, offers four DisplayPort 2.1b outputs for high-resolution, high-refresh-rate visualization, and provides a 600 W configurable TDP, allowing integrators to tune for optimal thermals, acoustics, or density.
Our goal is to evaluate how this workstation version performs in the lab across AI, rendering, and general computing, and to quantify the impact of the 96 GB pool on the capabilities of a single desktop node.
NVIDIA RTX PRO 6000 Workstation vs. Server Edition
The RTX PRO 6000 variants start from the same Blackwell GB202 foundation, so the raw math capability looks familiar on paper. The difference lies in how and where they are intended to live. The workstation card we are testing is a self-contained, actively cooled, dual-slot board with four DisplayPort 2.1b outputs and studio-class drivers. It slots into a tower or deskside workstation, drives local panels, and runs ISV-certified DCC and CAD apps alongside CUDA, TensorRT, and cuDNN. If workflows mix interactive viewport work, local visualization, and on-box AI, this is the path that keeps everything in one chassis with predictable acoustics and thermals.

The RTX PRO 6000 Blackwell Server Edition is designed for a distinctly different purpose. It is a headless, rack-first configuration intended for servers, featuring front-to-back airflow and remote management capabilities. There are no active display outputs since jobs are scheduled over the network and results are consumed remotely. Firmware, power, and thermal profiles are tuned for 24×7 duty under a scheduler, typically paired with NVIDIA AI Enterprise, container orchestration, and hypervisor passthrough. In short, the workstation model is the right choice when creators and engineers need to see and manipulate work locally while also running large inference or simulation batches. The server edition makes more sense when scaling out identical nodes behind a queue in a data center, where every watt, cable, and airflow path must fit within an OEM service plan.
NVIDIA RTX PRO 6000 Specifications
The table below outlines the specifications of the NVIDIA RTX PRO 6000 compared to the RTX 5090 and the previous Ada Lovelace generation RTX 4090.
| GPU Comparison | NVIDIA RTX PRO 6000 | NVIDIA RTX 5090 | NVIDIA RTX 4090 |
| GPU Name | GB202 | GB202 | AD102 |
| Architecture | Blackwell 2.0 | Blackwell 2.0 | Ada Lovelace |
| Process Size | 5 nm | 5 nm | 5 nm |
| Transistors | 92,200 million | 92,200 million | 76,300 million |
| Density | 122.9M / mm² | 122.9M / mm² | 125.3M / mm² |
| Die Size | 750 mm² | 750 mm² | 609 mm² |
| Slot Width | Dual-slot | Dual-slot | Triple-slot |
| Dimensions | 304 mm x 137 mm x 40 mm | 304 mm x 137 mm x 48 mm | 304 mm x 137 mm x 61 mm |
| TDP | 600W | 575W | 450W |
| Outputs | 4x DisplayPort 2.1b | 1x HDMI 2.1b,3x DisplayPort 2.1b | 1x HDMI 2.1, 3x DisplayPort 1.4a |
| Power Connectors | 1x 16-pin | 1x 16-pin | 1x 16-pin |
| Bus Interface | PCIe 5.0 x16 | PCIe 5.0 x16 | PCIe 4.0 x16 |
| Base Clock | 1590 MHz | 2017 MHz | 2235 MHz |
| Boost Clock | 2617 MHz | 2407 MHz | 2520 MHz |
| Memory Clock | 1750 MHz (28 Gbps effective) | 2209 MHz (28 Gbps effective) | 1313 MHz (21 Gbps effective) |
| Memory Size | 96 GB | 32 GB | 24 GB |
| Memory Type | GDDR7 ECC | GDDR7 | GDDR6X |
| Memory Bus | 512 bit | 512 bit | 384 bit |
| Memory Bandwidth | 1.79 TB/s | 1.79 TB/s | 1.01 TB/s |
| CUDA Cores | 24,064 | 21,760 | 16,384 |
| Tensor Cores | 752 | 680 | 512 |
| ROPs | 192 | 192 | 176 |
| SM Count | 188 | 170 | 128 |
| RT Cores | 188 | 170 | 128 |
| L1 Cache | 128 KB (per SM) | 128 KB (per SM) | 128 KB (per SM) |
| L2 Cache | 128 MB | 88 MB | 72 MB |
| Pixel Rate | 502.5 GPixel/s | 462.1 GPixel/s | 443.5 GPixel/s |
| Texture Rate | 1,968.0 GTexel/s | 1,637 GTexel/s | 1,290 GTexel/s |
| FP16 (half) | 126.0 TFLOPS (1:1) | 104.8 TFLOPS (1:1) | 82.58 TFLOPS (1:1) |
| FP32 (float) | 126.0 TFLOPS | 104.8 TFLOPS | 82.58 TFLOPS |
| FP64 (double) | 1.968 TFLOPS (1:64) | 1.637 TFLOPS (1:64) | 1,290 GFLOPS (1:64) |
| Launch Price (USD) | $8,500 | $1,999 | $1,599 |
Build and Design
The RTX PRO 6000 Workstation GPU carries forward NVIDIA’s clean, functional design, as seen on the RTX 5090 FE, with an industrial matte-black finish and a dual-axial fan layout optimized for workstation environments. Each fan is engineered to push airflow through the full-length 3D vapor chamber, helping maintain thermal equilibrium under sustained workloads. Measuring 304 mm × 137 mm × 40 mm, it fits comfortably within a dual-slot configuration, offering exceptional performance density given its 600 W TDP rating.

Along the top edge, the PRO 6000 features a single 16-pin power connector, delivering the current necessary to support its 96 GB of GDDR7 memory and full Blackwell 2.0 architecture. The build quality feels premium and rigid, with an aluminum shroud that channels air efficiently across the fin stack. NVIDIA’s subtle branding complements the professional aesthetic, with no RGBs or gaming flourishes, emphasizing reliability and performance in thermally demanding workstation chassis.

On the I/O side, NVIDIA provides four DisplayPort 2.1b outputs, ensuring compatibility with multi-monitor 8K setups, color-accurate HDR workflows, and advanced rendering environments. The use of DisplayPort 2.1b over HDMI reflects its professional orientation, with enhanced bandwidth for high-refresh and high-resolution displays.

Performance Testing
To evaluate the performance of our NVIDIA RTX PRO 6000 sample, we directly compared it with NVIDIA’s flagship consumer counterparts, the RTX 5090 Founders Edition and RTX 4090 Founders Edition. Testing was conducted across a mix of professional and AI-driven workloads to highlight both raw compute power and real-world application performance. Benchmarks included UL Procyon AI Text Generation, UL Procyon AI Image Generation, LuxMark, Geekbench 6, and V-Ray, providing a balanced overview of rendering, inference, and productivity performance.
In addition to these standard workloads, we also ran targeted tests designed to showcase the 96 GB of GDDR7 memory in the RTX PRO 6000, demonstrating its advantages in handling large models, high-resolution datasets, and professional visualization workloads where capacity and sustained throughput are critical.
- RTX PRO 6000
- GeForce RTX 5090 FE
- GeForce RTX 4090 FE
- RTX 6000 ADA
To fully leverage the benefits of the new NVIDIA RTX PRO 6000, we utilized our AMD ThreadRipper platform. This system, as configured, offers a 64-core CPU and a water-cooling loop. It has plenty of underlying CPU horsepower to let the GPU do its work without being held back. The complete system configuration is listed below.
StorageReview AMD ThreadRipper Test Platform
- Motherboard: ASUS Pro WS TRX50-SAGE WIFI
- CPU: AMD Ryzen Threadripper 7980X 64-Core
- RAM: 32GB DDR5 4800MT/s
- Storage: 2TB Samsung 980 Pro
- OS: Windows 11 Pro for Workstations
UL Procyon: AI Text Generation
The Procyon AI Text Generation Benchmark streamlines AI LLM performance testing by providing a concise and consistent evaluation method. It allows for repeated testing across multiple LLM models while minimizing the complexity of large model sizes and variable factors. Developed with AI hardware leaders, it optimizes the use of local AI accelerators for more reliable and efficient performance assessments. The results measured below were tested using TensorRT.
Across all four model tests, the NVIDIA RTX PRO 6000 consistently led the pack. Starting with Phi, the PRO 6000 achieved an overall score of 6,775, outpacing the RTX 5090 at 5,749, the RTX 4090 at 4,958, and the RTX 6000 Ada at 4,508. Its faster token generation rate (325.9 tokens/s) and lower latency (0.182 s to first token) underline its responsiveness in real-time text generation and chat-based AI workloads.
The trend continued with Mistral, where the PRO 6000 posted 7,346, maintaining a substantial margin over the 5090 (6,267), 4090 (5,094), and 6000 Ada (4,255). Its throughput of 271.8 tokens/s demonstrates the benefit of its larger 96 GB memory pool and optimized workstation tuning for high-context inference.
In Llama3, the PRO 6000 remained ahead with a score of 6,501, compared to 6,104 for the RTX 5090, 4,849 for the 4090, and 4,026 for the 6000 Ada. This highlights the consistency of NVIDIA’s Blackwell architecture, with the PRO 6000 sustaining performance advantages as transformer workloads scale in complexity and context length.
Finally, in Llama2, which emphasizes long-context inference and sustained performance, the PRO 6000 achieved 8,008, while the 5090, 4090, and 6000 Ada trailed at 6,591, 5,013, and 3,957, respectively. Even as sequence lengths and inference times grew, the PRO 6000 maintained clear dominance in both speed and stability, completing runs faster and with smoother throughput than any other GPU tested.
| UL Procyon: AI Text Generation | NVIDIA RTX PRO 6000 | NVIDIA RTX 5090 | NVIDIA RTX 4090 | NVIDIA RTX 6000 Ada |
| Phi Overall Score | 6,775 | 5,749 | 4,958 | 4,508 |
| Phi Output Time To First Token | 0.182 s | 0.244 s | 0.255 s | 0.288 s |
| Phi Output Tokens Per Second | 325.855 tok/s | 314.435 tok/s | 244.343 tok/s | 228.359 tok/s |
| Phi Overall Duration | 9.498 s | 10.280 s | 12.872 s | 13.869 s |
| Mistral Overall Score | 7,346 | 6,267 | 5,094 | 4,255 |
| Mistral Output Time To First Token | 0.229 s | 0.297 s | 0.322 s | 0.419 s |
| Mistral Output Tokens Per Second | 271.779 tok/s | 255.945 tok/s | 183.266 tok/s | 166.633 tok/s |
| Mistral Overall Duration | 11.493 s | 12.593 s | 17.010 s | 19.092 s |
| Llama3 Overall Score | 6,501 | 6,104 | 4,849 | 4,026 |
| Llama3 Output Time To First Token | 0.218 s | 0.234 s | 0.259 s | 0.348 s |
| Llama3 Output Tokens Per Second | 226.407 tok/s | 214.285 tok/s | 150.039 tok/s | 138.620 tok/s |
| Llama3 Overall Duration | 13.554 s | 14.304 s | 19.991 s | 22.062 s |
| Llama2 Overall Score | 8,008 | 6,591 | 5,013 | 3,957 |
| Llama2 Output Time To First Token | 0.307 s | 0.419 s | 0.500 s | 0.679 s |
| Llama2 Output Tokens Per Second | 145.595 tok/s | 134.502 tok/s | 92.853 tok/s | 78.532 tok/s |
| Llama2 Overall Duration | 20.712 s | 23.018 s | 32.448 s | 38.923 s |
UL Procyon: AI Image Generation
The Procyon AI Image Generation Benchmark provides a consistent and accurate method for measuring AI inference performance across various hardware, ranging from low-power NPUs to high-end GPUs. It includes three tests: Stable Diffusion XL (FP16) for high-end GPUs, Stable Diffusion 1.5 (FP16) for moderately powerful GPUs, and Stable Diffusion 1.5 (INT8) for low-power devices. The benchmark uses the optimal inference engine for each system, ensuring fair and comparable results.
Starting with Stable Diffusion 1.5 (FP16), the NVIDIA RTX PRO 6000 delivered a commanding 8,869 overall score, outperforming the RTX 5090 at 8,193, the RTX 4090 at 5,260, and the RTX 6000 Ada at 4,230. The PRO 6000 completed image generation in 11.27 seconds at an average of 0.705 seconds per image, making it the fastest in this test. This demonstrates how its workstation-optimized tuning and 96 GB of GDDR7 memory enable sustained, high-precision output without compromising efficiency.
In the Stable Diffusion 1.5 (INT8) test, which measures lightweight quantized inference performance, all GPUs performed closely. The PRO 6000 scored 79,064, nearly identical to the RTX 5090’s 79,272, while leading the RTX 4090 (62,160) and RTX 6000 Ada (55,901). Since INT8 workloads rely less on memory bandwidth and capacity, the differences were minimal, but the PRO 6000 maintained consistent results with an average generation time of 0.395 seconds per image.
The Stable Diffusion XL (FP16) test pushes GPUs with longer, more demanding inference runs that stress both memory and sustained compute throughput. Here, the PRO 6000 achieved a 6,991 overall score, landing just behind the RTX 5090’s 7,179, but well ahead of the RTX 4090’s 5,025 and the RTX 6000 Ada’s 3,043. It maintained a total render time of 85.8 seconds, or 5.36 seconds per image, showing that the PRO 6000 handles extended generation workloads efficiently and without slowdowns.
| UL Procyon: AI Image Generation | NVIDIA RTX PRO 6000 | NVIDIA RTX 5090 | NVIDIA RTX 4090 | NVIDIA RTX 6000 Ada |
| Stable Diffusion 1.5 (FP16) – Overall Score | 8,869 | 8,193 | 5,260 | 4,230 |
| Stable Diffusion 1.5 (FP16) – Overall Time | 11.274 s | 12.204 s | 19.011 s | 23.639 s |
| Stable Diffusion 1.5 (FP16) – Image Generation Speed | 0.705 s/image | 0.763 s/image | 1.188 s/image | 1.477 s/image |
| Stable Diffusion 1.5 (INT8) – Overall Score | 79,064 | 79,272 | 62,160 | 55,901 |
| Stable Diffusion 1.5 (INT8) – Overall Time | 3.162 s | 3.154 s | 4.022 s | 4.472 s |
| Stable Diffusion 1.5 (INT8) – Image Generation Speed | 0.395 s/image | 0.394 s/image | 0.503 s/image | 0.559 s/image |
| Stable Diffusion XL (FP16) – Overall Score | 6,991 | 7,179 | 5,025 | 3,043 |
| Stable Diffusion XL (FP16) – Overall Time | 85.819 s | 83.573 s | 119.379 s | 197.172 s |
| Stable Diffusion XL (FP16) – Image Generation Speed | 5.364 s/image | 5.223 s/image | 7.461 s/image | 12.323 s/image |
Blender 4.4
Blender is an open-source 3D modeling application. This benchmark was run using the Blender Benchmark utility. The score is measured in samples per minute, with higher values indicating better performance.
Across all three scenes, the NVIDIA RTX PRO 6000 took the top position, showcasing the benefits of its Blackwell architecture and expanded memory capacity. In the Monster scene, the PRO 6000 scored 7,870.17 samples per minute, ahead of the RTX 5090 at 7,421.50, while the RTX 4090 and RTX 6000 Ada followed at 5,733.97 and 5,632.60, respectively.
In the Junkshop scene, the PRO 6000 continued its lead with 4,158.91 samples per minute, compared to 3,980.15 for the RTX 5090, 2,827.83 for the RTX 4090, and 2,663.77 for the RTX 6000 Ada. Finally, in the Classroom scene, which tends to stress both shading and memory efficiency, the PRO 6000 reached 4,041.11 samples per minute, once again ahead of the RTX 5090’s 3,732.63 and significantly outperforming the RTX 4090 and RTX 6000 Ada at 2,909.35 and 2,818.83, respectively.
| Blender 4.4 (higher is better) | NVIDIA RTX PRO 6000 | NVIDIA RTX 5090 | NVIDIA RTX 4090 | NVIDIA RTX 6000 Ada |
| Monster | 7,870.17 | 7,421.50 | 5,733.97 | 5,632.60 |
| Junkshop | 4,158.91 | 3,980.15 | 2,827.83 | 2,663.77 |
| Classroom | 4,041.11 | 3,732.63 | 2,909.35 | 2,818.83 |
Luxmark
Luxmark is a GPU benchmark that utilizes LuxRender, an open-source ray-tracing renderer, to assess a system’s performance in handling highly detailed 3D scenes. This benchmark is particularly relevant for evaluating the graphical rendering capabilities of servers and workstations, especially in visual effects and architectural visualization applications, where accurate light simulation is crucial.
In the Food scene test, the NVIDIA RTX PRO 6000 led with a score of 24,287, edging out the RTX 5090 at 23,141, while the RTX 4090 and RTX 6000 Ada followed at 17,171 and 14,873, respectively. This demonstrates how the PRO 6000 maintains smooth ray tracing performance across highly detailed geometry and lighting workloads without stability loss or thermal throttling.
In the more demanding Hall scene, which stresses large-scale geometry and complex global illumination, the PRO 6000 again secured the top result at 52,588, narrowly ahead of the RTX 5090’s 51,725, and well above the RTX 4090 (38,887) and RTX 6000 Ada (32,132).
| Luxmark (higher is better) | NVIDIA RTX PRO 6000 | NVIDIA RTX 5090 | NVIDIA RTX 4090 | NVIDIA RTX 6000 Ada |
| Food Score | 24,287 | 23,141 | 17,171 | 14,873 |
| Hall Score | 52,588 | 51,725 | 38,887 | 32,132 |
Geekbench 6
Geekbench 6 is a cross-platform benchmark that measures overall system performance. The Geekbench Browser allows you to compare any system to it.
In this test, the NVIDIA RTX PRO 6000 achieved a GPU OpenCL score of 384,158, surpassing the RTX 5090 (374,807), the RTX 4090 (333,384), and the RTX 6000 Ada (336,882). The PRO 6000’s higher score reflects its optimized workstation design, enhanced memory bandwidth, and professional driver stack, which together enable consistent performance across a wide range of compute-heavy workloads.
| Geekbench (higher is better) | NVIDIA RTX PRO 6000 | NVIDIA RTX 5090 | NVIDIA RTX 4090 | NVIDIA RTX 6000 Ada |
| GPU OpenCL Score | 384,158 | 374,807 | 333,384 | 336,882 |
V-Ray
The V-Ray Benchmark measures rendering performance for CPUs, NVIDIA GPUs, or both using advanced V-Ray 6 engines. It utilizes quick tests and a simple scoring system to enable users to evaluate and compare their systems’ rendering capabilities. It’s an essential tool for professionals seeking efficient performance insights.
In our testing, the NVIDIA RTX PRO 6000 scored 12,128 vpaths, placing it between the RTX 5090, which led with 14,764, and the RTX 4090, which scored 10,847. The RTX 6000 Ada trailed slightly behind at 10,766. While the RTX 5090 maintained a slight lead in this GPU-intensive rendering test, the PRO 6000 demonstrated strong and consistent performance, reinforcing its workstation-oriented tuning and sustained efficiency under full rendering loads.
| V-Ray (higher is better) | NVIDIA RTX PRO 6000 | NVIDIA RTX 5090 | NVIDIA RTX 4090 | NVIDIA RTX 6000 Ada |
| vpaths | 12,128 | 14,764 | 10,847 | 10,766 |
LM Studio Multi-Model Inference Test
For this round of testing, we used LM Studio to evaluate how the NVIDIA RTX PRO 6000 performs across a range of popular large language models, including GPT-OSS 120B, Gemma 3 (4B, 12B, and 27B), Llama 3.1 (8B and 70B), and Llama 3.3 70B. Each model was prompted with the same instruction:
“Write a 500-word academic paper on the history of sloths.”
The primary focus in this test is on Tokens per Second (throughput) and Total Time (completion duration), which together highlight how efficiently the RTX PRO 6000 handles different model sizes and complexities under identical generation conditions.
Across the LM Studio inference tests, the NVIDIA RTX PRO 6000 demonstrated excellent performance and scalability across a wide range of model sizes, from smaller 4B-parameter models to massive 120B-class configurations.
The highlight of this test was the OpenAI GPT-OSS 120B, where the RTX PRO 6000 produced 163.1 tokens per second and completed the 500-word generation in 9.54 seconds. This result stands out because cards such as the RTX 5090 cannot load or execute a 120B model and often fail to handle even 70B models due to limited VRAM. The PRO 6000’s 96 GB of GDDR7 memory enables it to process these huge models locally, making it uniquely capable among workstation GPUs.
For smaller models, the Gemma 3.4 B achieved the highest throughput, completing the task at 226.7 tokens per second in 3.51 seconds. The Llama 3.1 8B Instruct followed closely, with 197.1 tokens per second and a total time of 4.17 seconds. These runs show the PRO 6000’s strong efficiency and quick response in mid-range inference workloads.
At the higher end, the Llama 3.1 70B Instruct and Llama 3.3 70B models averaged around 31.8 tokens per second with total generation times of 27.2 seconds and 25.3 seconds, showing consistent output despite their large size.
Overall, the RTX PRO 6000 delivers outstanding stability, throughput, and capability when running large-scale models. Its 96 GB memory capacity allows it to handle workloads that exceed the limits of consumer GPUs, making it an excellent choice for developers, researchers, and professionals who need reliable local performance for advanced AI and generative model development.
| LM Studio (Model Inference Results) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model Name | Tokens / Sec | Time to First Token (s) | Total Time (s) | Prompt Tokens | Predicted Tokens | Total Tokens | |||
| OpenAI GPT-OSS 120B | 163.15 | 0.193 | 9.543 | 81 | 1,557 | 1,638 | |||
| Gemma 3 4B | 226.73 | 0.113 | 3.51 | 25 | 796 | 821 | |||
| Gemma 3 12B | 117.15 | 0.068 | 8.06 | 25 | 944 | 969 | |||
| Gemma 3 27B | 68.06 | 0.221 | 12.048 | 25 | 820 | 845 | |||
| Meta Llama 3.1 8B Instruct | 197.07 | 0.062 | 4.171 | 49 | 822 | 871 | |||
| Meta Llama 3.1 70B Instruct | 31.84 | 0.159 | 27.227 | 49 | 867 | 916 | |||
| Meta Llama 3.3 70B | 31.74 | 0.323 | 25.329 | 49 | 804 | 853 | |||
NVIDIA RTX PRO 6000 Power Consumption
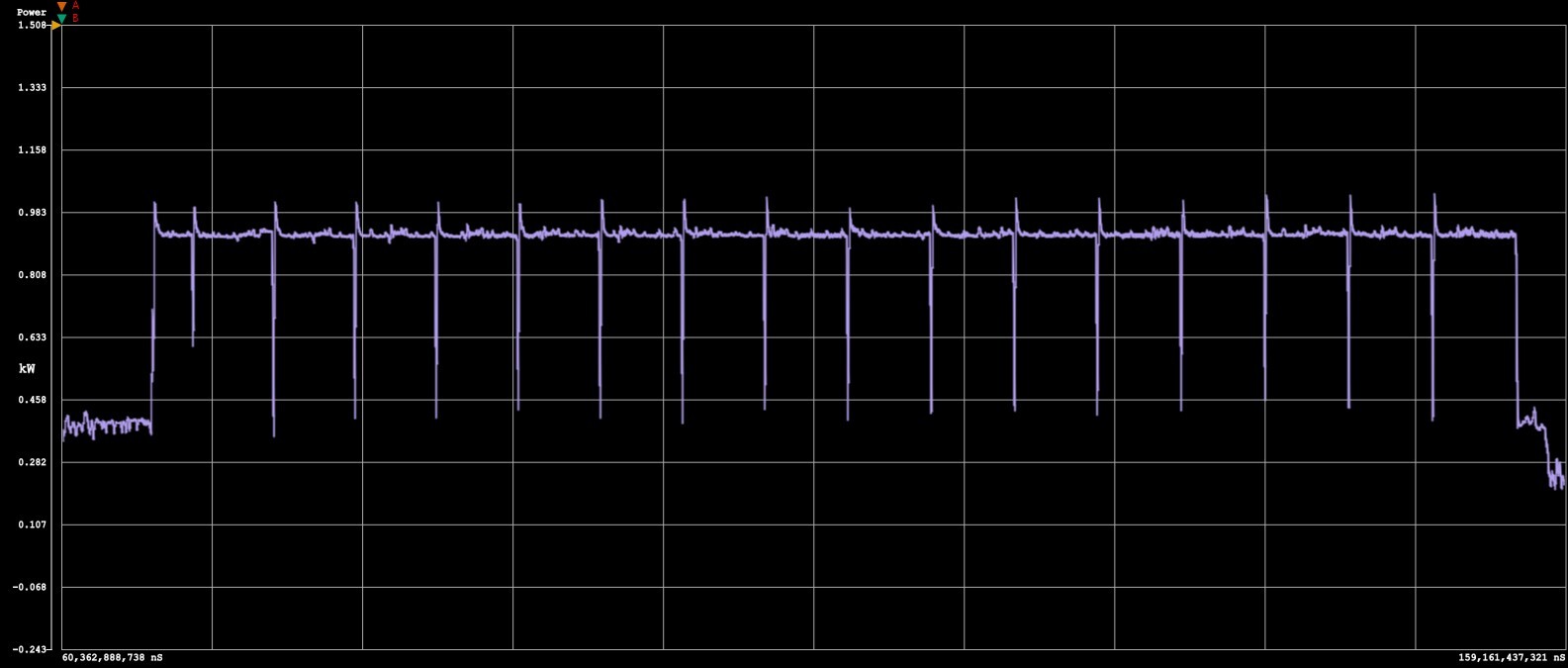
To evaluate the real-world efficiency of AI workloads, we utilized the UL Procyon AI Image Generation benchmark, specifically the Stable Diffusion XL FP16 test. This test focuses on the interval between the second and last generated images, capturing the time to complete the interval, peak and sustained power draw, and system idle power after completion.
During our testing, the RTX PRO 6000 maintained an average system draw of 918.5 W under sustained load, peaking at 1,036.3 W, with idle power settling at 152.3 W once the workload completed. The full test interval lasted 5.3 seconds, consuming a total of 1.35 Wh of energy. These results show excellent power-to-performance efficiency for a workstation-class GPU, keeping draw well-controlled while sustaining high output during extended inference workloads.
Compared with other GPUs, the RTX PRO 6000 closely aligns with the RTX 4090 in total energy consumption while maintaining a faster completion time, and it significantly outperforms the RTX 6000 Ada in both power efficiency and speed. Interestingly, the new Blackwell cards, which share the GB202 chip, exhibit very similar efficiency characteristics under this workload, with only minor differences in total energy use likely due to the PRO 6000’s higher TDP. This indicates that NVIDIA’s latest generation continues to refine performance per watt rather than drastically shift it.
| Stable Diffusion XL FP16 Image Power Used (lower is better) | NVIDIA RTX PRO 6000 | NVIDIA RTX 5090 | NVIDIA RTX 4090 | NVIDIA RTX 6000 Ada |
| Power Consumed | 1.35Wh | 1.16Wh | 1.35Wh | 1.76Wh |
| Test Duration | 5.3s | 5.1s | 7.3s | 12.6s |
Conclusion
The NVIDIA RTX PRO 6000 is, in aggregate, the most capable workstation GPU available for professional workflows, delivering data center-class performance in a desk-side form factor. With retail pricing of around $8,500 at the time of testing, it targets teams that require reliability, high compute density, and a massive ECC memory pool for production work. With 24,064 CUDA cores, 752 Tensor Cores, 96 GB of GDDR7 ECC, and Blackwell architecture, it handles workloads that exceed the practical limits of consumer cards like the GeForce RTX 5090 or 4090. Individual benchmarks may show a consumer card edging it in raw speed, but taken as a whole across capacity, stability, drivers, and ISV support, the RTX PRO 6000 is the stronger fit for professional use.
For AI and ML, the 96 GB pool is the headline. It enables long context inference and very large checkpoints locally, which we demonstrated by running 70B to 120B class models while maintaining strong tokens per second. Rendering and simulation also benefit from the larger L2 cache and memory bandwidth, delivering predictable, sustained performance in Blender, V-Ray, and LuxMark under extended loads.

The card fits real workstations. It features a true dual-slot design with a PCIe 5.0 x16 interface, four DisplayPort 2.1b outputs, and a single 16-pin power input. Plan for a quality PSU and chassis airflow to support the 600W board power. Multi-GPU is also straightforward, with OEM and ISV support for 2 to 8 GPUs across AI, rendering, and compute stacks.
If your work involves long context LLMs, very large scenes, or high precision simulation on a single node, the RTX PRO 6000 justifies its premium with capacity and consistency that other cards cannot match.


 Amazon
Amazon