
…GPUs, positioned for single-node deployments. Lenovo claimed up to 3x performance gains for vision AI and up to 4x performance for content generation compared to NVIDIA L4. ThinkAgile HX650a: paired…


…GPUs, positioned for single-node deployments. Lenovo claimed up to 3x performance gains for vision AI and up to 4x performance for content generation compared to NVIDIA L4. ThinkAgile HX650a: paired…

…is targeting these systems for enterprise-scale AI factory deployments and HPC environments that require sustained accelerator performance and predictable thermal performance under heavy load. To complement the node-level systems, the…
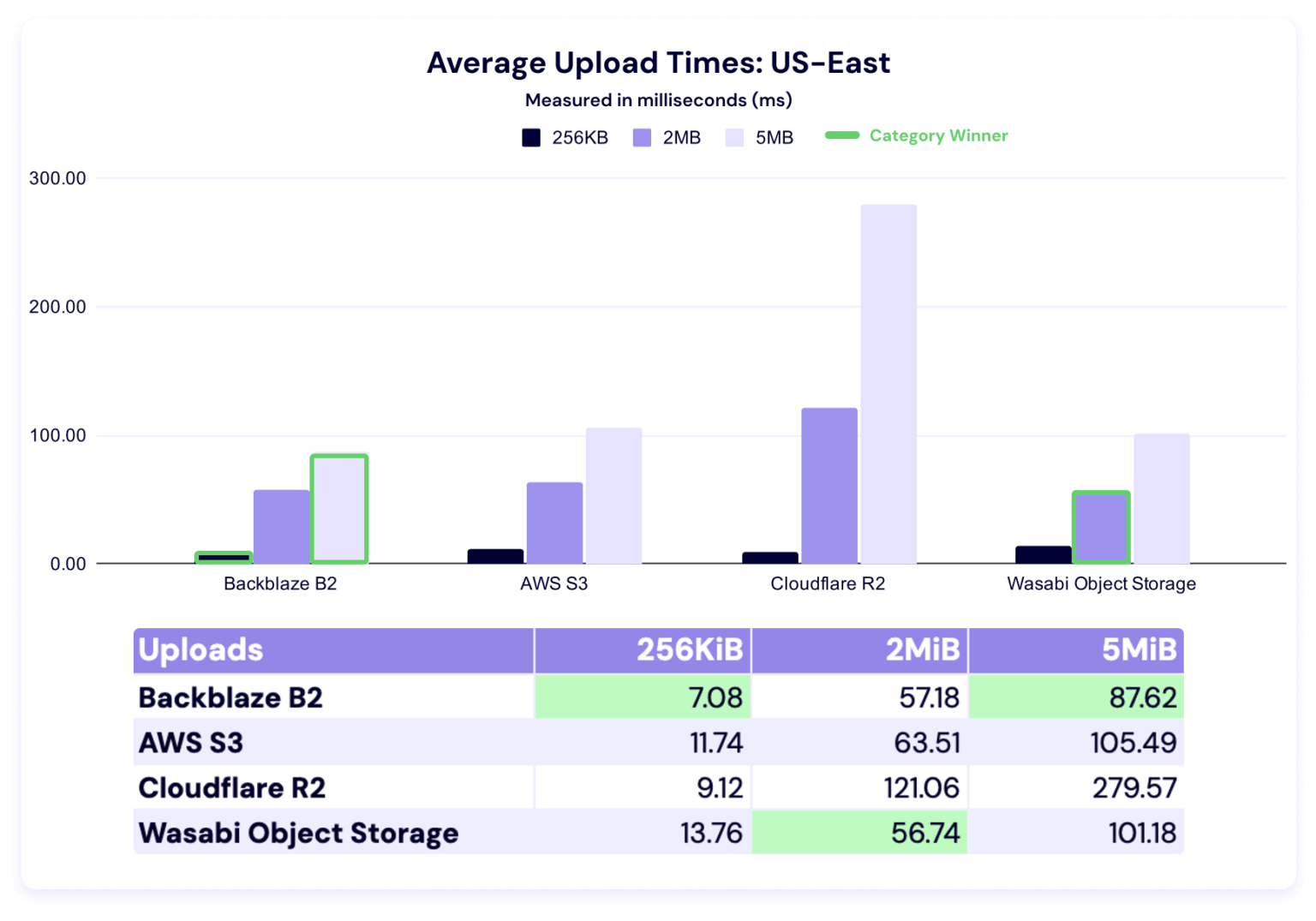
…locality. Backblaze also said that they cannot control routing and peering once traffic leaves the test node, and that caching, traffic shaping, or rate limiting may have affected some results….
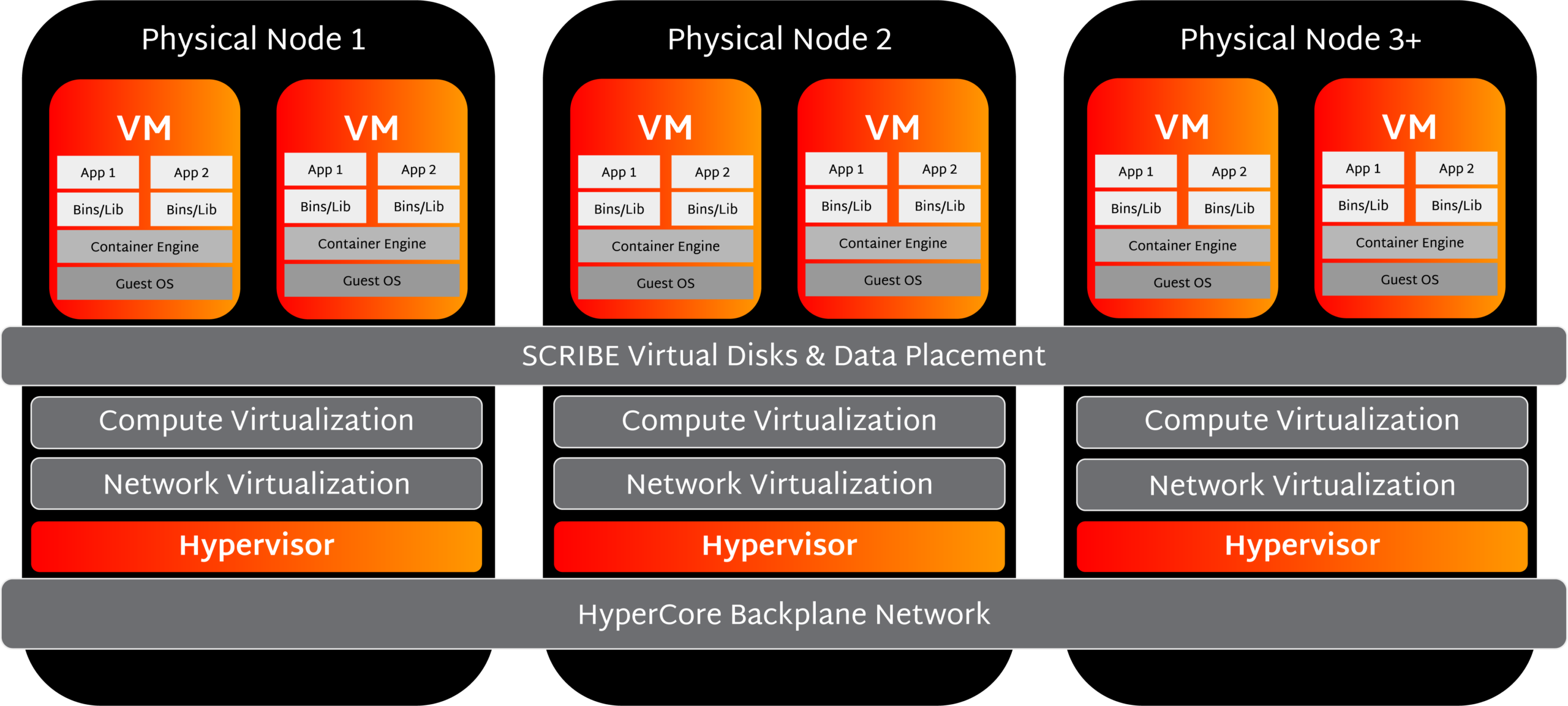
…unstructured datasets outpace compute needs, forcing IT teams into inefficient and costly node expansions. To address this imbalance, Scale Computing and Nexsan have introduced a joint architecture that integrates the…
…and 175 GB/s write throughput per node, with up to 7 million IOPS. The platform also supports NVIDIA GPUDirect Storage, enabling direct data paths between storage and GPUs, as well…

…the update as a cost efficiency play for the latest PowerMax 2500 and 8500 systems. The updated node-pair architecture is designed to increase IOPS density while reducing the total cost…

…addition of a new 2-node VxRail system with a special integrated hardware witness. Dell and VMware have co-engineered HCI solutions supporting Data Processing Units (DPUs) running on VxRail to expand…
…throughput in a single node, 16GB/s for a minimum four-node cluster and up to 1.6TB/s for a 400-node cluster, QF2 delivers the world’s highest all-flash read performance on standard hardware…

…RAID1 boot volume. Dell VxRail VD-4520c Node In terms of connectivity, the nodes both offer support for four SPF+ or SFP28. Each node also has an iDRAC port, diagnostic ports,…
…3.0, up to 8x 3.5″ hot-swap HDD bays per U in 4U 4-node or up to 6x double-width NVIDIA GPU/Intel Xeon Phi Coprocessor per node in 4U 2-node configuration NVMe,…


 Amazon
Amazon