

Everpure is aligning its FlashBlade//EXA platform with NVIDIA’s evolving AI Factory architectures while previewing a new automation layer called Everpure Data Stream. The announcement extends Evergreen//One support to EXA and introduces a service designed to streamline data movement across AI pipelines, targeting one of the most common enterprise AI challenges: projects that work in pilot environments but stall before reaching production scale.
FlashBlade//EXA is positioned as the high-performance data backbone for these deployments, supporting large training runs and high-concurrency inference workloads. The upcoming Data Stream service focuses on automating data ingestion, preparation, and delivery to GPU infrastructure, reducing the operational complexity that often slows AI programs as they move from experimentation to production environments.
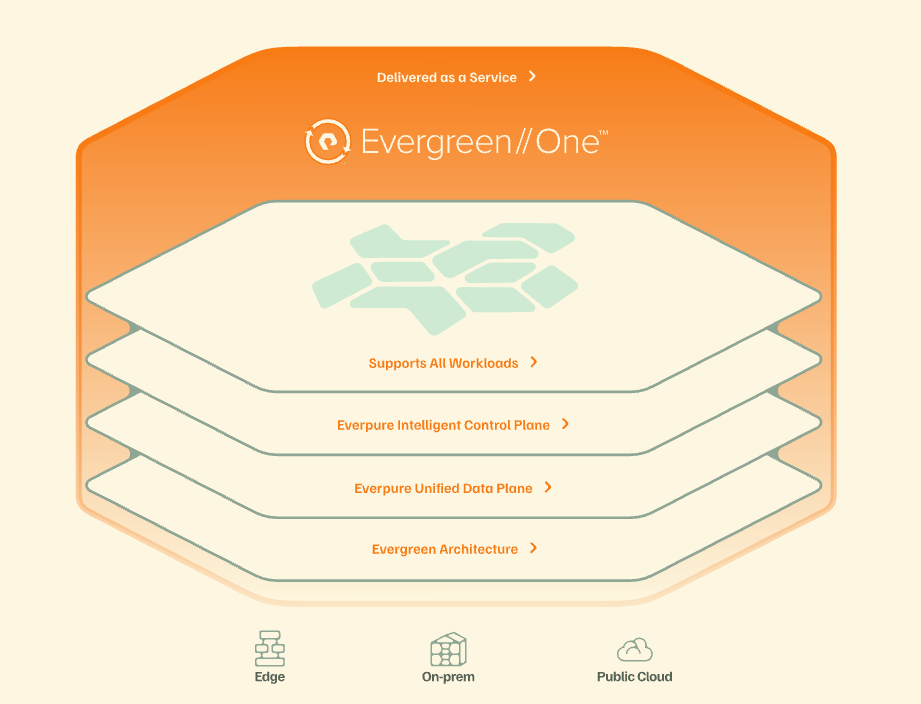
EG1 for AI now extends from FlashBlade//EXA to deliver the performance, scale, and throughput needed for larger training runs and high‑concurrency inference. Everpure Data Stream, entering beta later in 2026, is designed to automate data movement from ingestion to model execution, reducing manual pipeline work and operational delays that often slow down AI projects.
Kaycee Lai, Everpure’s AI Vice President, frames the problem as treating AI as “just another workload” rather than as a data‑centric, continuous system. She highlighted that Everpure positions its stack to collapse data silos and move AI programs from experimentation to repeatable production outcomes, enabled by predictable performance and operational flexibility.
Benchmark‑Proven AI Storage and Data Path
For AI deployments, storage and data infrastructure must keep high‑value GPUs running near full utilization. Everpure is aligning FlashBlade//EXA with NVIDIA’s modular STX reference architecture to support next‑generation AI Factory designs built on the Vera Rubin platform.
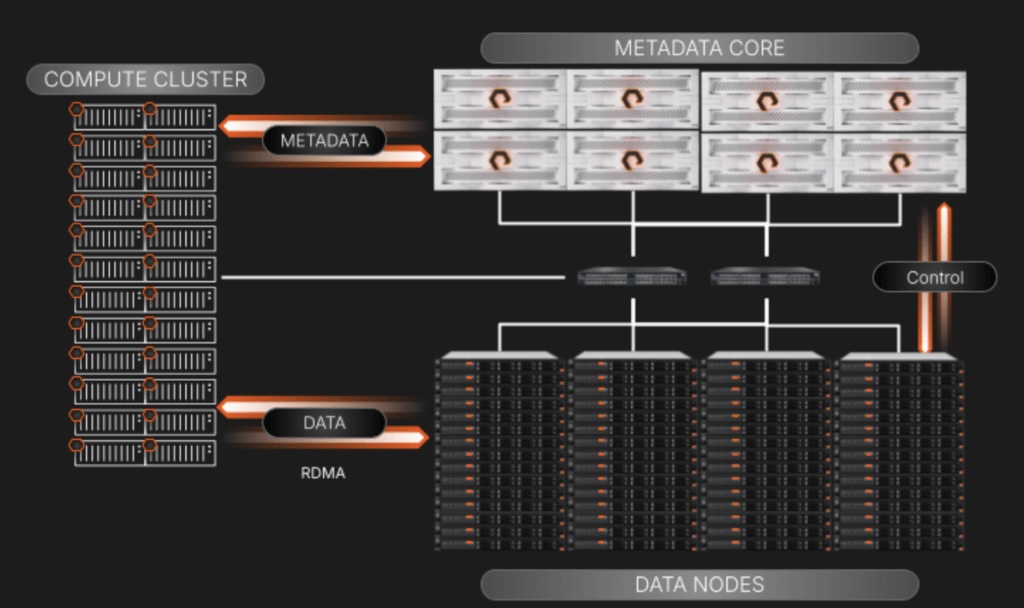
The combined architecture integrates EXA’s scalable file and object performance with STX components, such as BlueField-enabled storage controllers and context memory architectures. The goal is to optimize the entire AI data pipeline: data preparation, feature and embedding creation, and long‑context inference. Special emphasis is placed on context memory because large-scale, agentic, multi-step reasoning systems rely on quick access to extensive context windows and history. The EXA/STX design addresses these giga‑scale inference demands by delivering sustained bandwidth and minimizing tail latency.
Recent industry benchmarks validate the platform’s behavior under realistic, high‑concurrency AI workloads. The benchmarks include:
- SPECstorage Solution 2020 AI_Image: FlashBlade//EXA achieved the highest score recorded for the SPEC Storage AI_Image benchmark, powering 6,300 simultaneous AI jobs. This result illustrates the system’s ability to support large numbers of concurrent training and preprocessing tasks at full performance, an increasingly common pattern in multi‑tenant and multi‑team AI environments.
- MLPerf‑aligned GPU Utilization and Throughput: Internal, model‑driven workloads aligned with MLPerf show that FlashBlade//EXA can transfer data nearly twice as fast as its closest competitor while using less than half the storage footprint of a rack. In tests, the platform maintained over 90% GPU utilization across large H100 clusters. This suggests the storage system is unlikely to be a bottleneck, allowing expensive accelerators to stay busy as datasets and models grow. EXA’s design scales linearly, maintaining this utilization as more compute and storage are added.
Everpure is also expanding NVIDIA‑Certified Storage (NVCS) validation to FlashBlade//EXA. This effort provides a clearer baseline for compatibility and performance and serves as a stepping stone to the NVCS “NCP” certification level, aligned with NVIDIA Cloud Partner reference architectures. For enterprises standardizing on NVIDIA-focused AI solutions, this type of storage certification helps reduce integration risk and makes it easier to adopt reference designs.
Automating AI Data Orchestration
High storage performance alone does not guarantee AI success if data pipelines into the AI stack remain fragmented and manual. Everpure Data Stream is introduced as an orchestration layer that automates key steps from data ingestion through preparation and delivery into GPU infrastructure.
The service focuses on curating and orchestrating “AI‑ready” data so that training and inference systems are continuously fed with current datasets without requiring heavy operational intervention. The intent is to shorten the time from the initial experiment to a stable production run by reducing ad hoc scripting, manual data staging, and repeated engineering workarounds for dataset refreshes.
An AI Data Platform (AIDP) for Everpure Data Stream, co-engineered with Supermicro, offers a compact reference design for organizations seeking a smaller initial footprint. This combination integrates Supermicro’s server and accelerator hardware with Everpure’s software-defined storage layer, providing a ready-made solution for deploying a data plane that supports both training and inference pipelines.
As part of this AIDP strategy, Everpure also supports accelerated platforms, including the NVIDIA RTX PRO 6000 Blackwell Server Edition, and plans to extend support to the RTX PRO 4500 Blackwell Server Edition. These configurations target customers who need strong inference and edge or departmental training capabilities without having to immediately invest in large data center GPU clusters.
Continuous Data Optimization
Everpure builds its platform around the idea that AI infrastructure isn’t just a one-time investment but an ongoing process of data improvement and performance testing. In this view, AI readiness isn’t just about deploying technology but involves a continuous cycle of collecting new data, retraining or tuning models, and verifying performance as workloads change.
By integrating FlashBlade//EXA, Evergreen//One’s consumption model, Data Stream automation, and alignment with NVIDIA STX and NVCS certifications, Everpure aims to help organizations move ready from isolated AI pilots to repeatable, production‑grade AI factories, while maintaining focus on GPU utilization and operational efficiency.
Internal MLPerf component measurements support some of these claims, although they were not submitted as official MLPerf results. From a technical perspective, the key points are the demonstrated concurrency under SPECstorage AI_Image, the reported GPU utilization figures in H100 environments, and the move toward fully validated NVIDIA‑aligned reference architectures.


 Amazon
Amazon