

NVIDIA has announced two significant moves targeting high-performance computing and AI: the acquisition of SchedMD, the company behind the Slurm workload manager, and the launch of the Nemotron 3 family of open models, data, and tools for multi-agent AI. Together, these efforts reinforce NVIDIA’s position across HPC, generative AI, and enterprise AI infrastructure while maintaining a strong emphasis on open, vendor-neutral software.
Slurm and SchedMD: Strengthening Open, Vendor-Neutral HPC Scheduling
SchedMD is the primary developer of Slurm, one of the most widely deployed open-source workload managers for HPC and AI clusters. Slurm is used to queue, schedule, and allocate compute resources across large-scale clusters that run tightly coupled parallel workloads. As cluster sizes and model complexity increase, efficient scheduling becomes critical to maintain utilization and throughput.

Slurm’s footprint in HPC is substantial. It is used in more than half of the top 10 and top 100 systems on the TOP500 list, driven by its scalability, high throughput, and support for complex policy management. For AI workloads, Slurm has become a key component of the infrastructure used by foundation model developers and AI builders to orchestrate large-scale model training and inference on GPU-accelerated systems.
Following the acquisition, NVIDIA plans to continue developing and distributing Slurm as open-source, vendor-neutral software. The company states that Slurm will remain accessible to the broader HPC and AI community and will continue to support heterogeneous environments across a wide range of hardware and software platforms. NVIDIA has collaborated with SchedMD for more than a decade, and this formal acquisition is intended to accelerate that roadmap rather than represent a strategic pivot.

SchedMD leadership views the deal as validation of Slurm’s central role in HPC and AI. The company noted that NVIDIA’s expertise in accelerated computing should help advance Slurm to meet future AI and supercomputing requirements while preserving its open-source model and community engagement.
Customer Impact and Platform Support
For existing SchedMD customers, NVIDIA intends to maintain continuity in Slurm support, training, and development. Current Slurm deployments span cloud providers, manufacturers, AI companies, and research organizations across sectors such as autonomous driving, healthcare and life sciences, energy, financial services, government, and general manufacturing.
NVIDIA also expects to accelerate SchedMD’s access to new systems and architectures. For customers standardizing on NVIDIA’s accelerated computing platform, this should translate into faster support for new GPU generations and system configurations. At the same time, NVIDIA reiterates that Slurm will continue to support a broad set of heterogeneous environments, enabling mixed-vendor clusters to adopt new Slurm capabilities without being locked into a single hardware stack.
The combined effort between NVIDIA and SchedMD is framed as part of a broader initiative to strengthen the open-source software ecosystem in HPC and AI, enabling innovation across industries and deployment scales.
Nemotron 3: Open MoE Models for Multi-Agent, Agentic AI
At the same time, NVIDIA has introduced the Nemotron 3 family, an open ecosystem of models, datasets, and libraries for building transparent and efficient agentic AI systems. As organizations move from single-model chatbots to more complex multi-agent architectures, they encounter challenges such as communication overhead among agents, context drift across long workflows, and escalating inference costs. There is also growing demand for transparency to enable understanding and trust in AI systems embedded in critical business processes.

Nemotron 3 targets these requirements with a hybrid latent mixture-of-experts (MoE) architecture designed for multi-agent workloads at scale. The models are intended to support collaborative agent behavior, specialized skills, and efficient task routing while maintaining predictable performance and cost profiles.
Jensen Huang, founder and CEO of NVIDIA, emphasized that open innovation is essential for AI advancement. He highlighted that Nemotron transforms cutting-edge AI into an accessible platform, enhancing transparency and efficiency to support the development of large-scale agentic systems.
National and regional AI initiatives across Europe, South Korea, and other regions are already considering Nemotron as a foundation for open, locally controlled AI development. Early adopters, including Accenture, Cadence, CrowdStrike, Cursor, Deloitte, Palantir, Perplexity, and others, are incorporating Nemotron models into workflows that span manufacturing, cybersecurity, software engineering, media, and communications.
Model Lineup: Nano, Super, and Ultra
Nemotron 3 consists of three main MoE model tiers, each targeted at different classes of workloads:
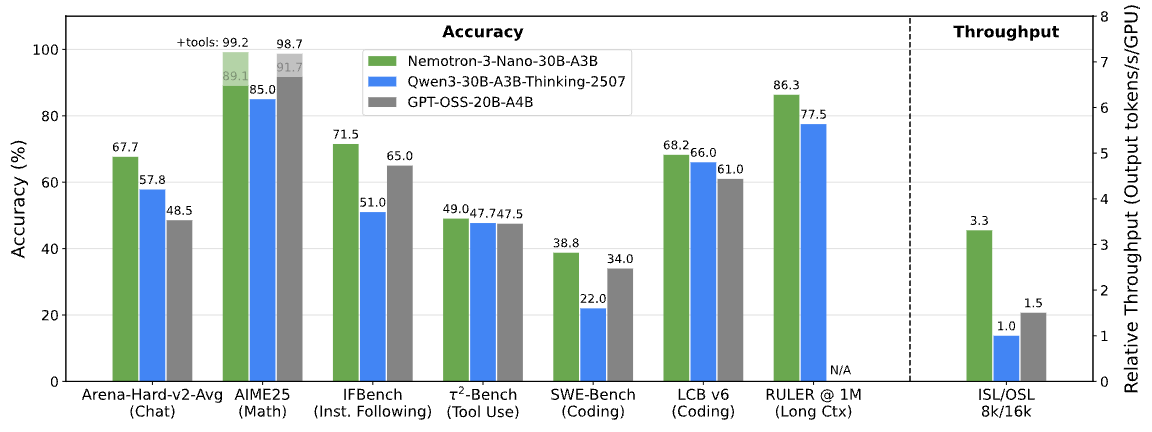
- Nano is a small, approximately 30-billion-parameter model that activates up to 3 billion parameters per token for efficient inference. It is suitable for tasks like debugging, summarization, AI pipelines, and information retrieval, where low latency and cost are crucial. Its hybrid MoE design delivers up to 4x the token throughput of Nemotron 2 Nano and reduces reasoning costs by up to 60 percent, lowering overall inference costs. With a 1-million-token context window, Nemotron 3 Nano maintains more state across long workflows, improving accuracy and connecting distant context. Independent benchmarks rank it among the most open and efficient models in its class, with top accuracy among peers.
- Super is a higher-accuracy reasoning model with roughly 100 billion parameters and up to 10 billion active parameters per token. It is designed for multi-agent applications in which many agents collaborate to achieve complex objectives under low-latency requirements. Super is suitable for scenarios where reasoning depth, tool usage, and coordination across agents need to scale without incurring the cost profile of the largest models.
- Ultra is the top-tier model and functions as a large reasoning engine, with approximately 500 billion parameters and up to 50 billion active parameters per token. It is intended for the most demanding AI workflows, including deep research, strategic planning, and complex decision-support systems that require high-quality reasoning across very long contexts.
Nemotron 3 Super and Ultra are trained using NVIDIA’s 4-bit NVFP4 format on the Blackwell architecture. This training format significantly reduces memory footprint and improves training throughput while maintaining accuracy comparable to higher-precision formats. For enterprises and service providers, this can enable larger models to be trained on existing infrastructure or reduce the hardware footprint required for a given scale.
With this tiered family, developers can match model size and capabilities to specific workloads and cost targets, scaling from dozens to hundreds of agents while maintaining faster, more accurate long-term reasoning across complex, multi-step workflows.
Routing, Token Economics, and Hybrid Model Strategies
As multi-agent systems mature, many organizations are adopting hybrid model strategies. Frontier proprietary models are used for the most complex reasoning tasks, while efficient, customizable open models handle routine or domain-specialized workloads. Nemotron 3 is explicitly designed for this kind of routing-based architecture.
In a typical setup, an agent router analyzes tasks in real time. It dispatches them either to a fine-tuned Nemotron model, such as Nemotron 3 Ultra, or to a proprietary model when that provides unique value. This approach helps optimize token economics by reserving expensive frontier capacity for the most demanding cases and leveraging Nemotron for high-throughput, high-efficiency workloads.
Partners building AI assistants and agent platforms report that this routing strategy enables them to deliver greater responsiveness and better cost control while maintaining the flexibility to integrate different model providers and training strategy over time.
Open Data, Libraries, and Safety Tooling
Beyond the models themselves, NVIDIA is releasing a substantial set of open resources to support custom agent development:
Training and RL Datasets
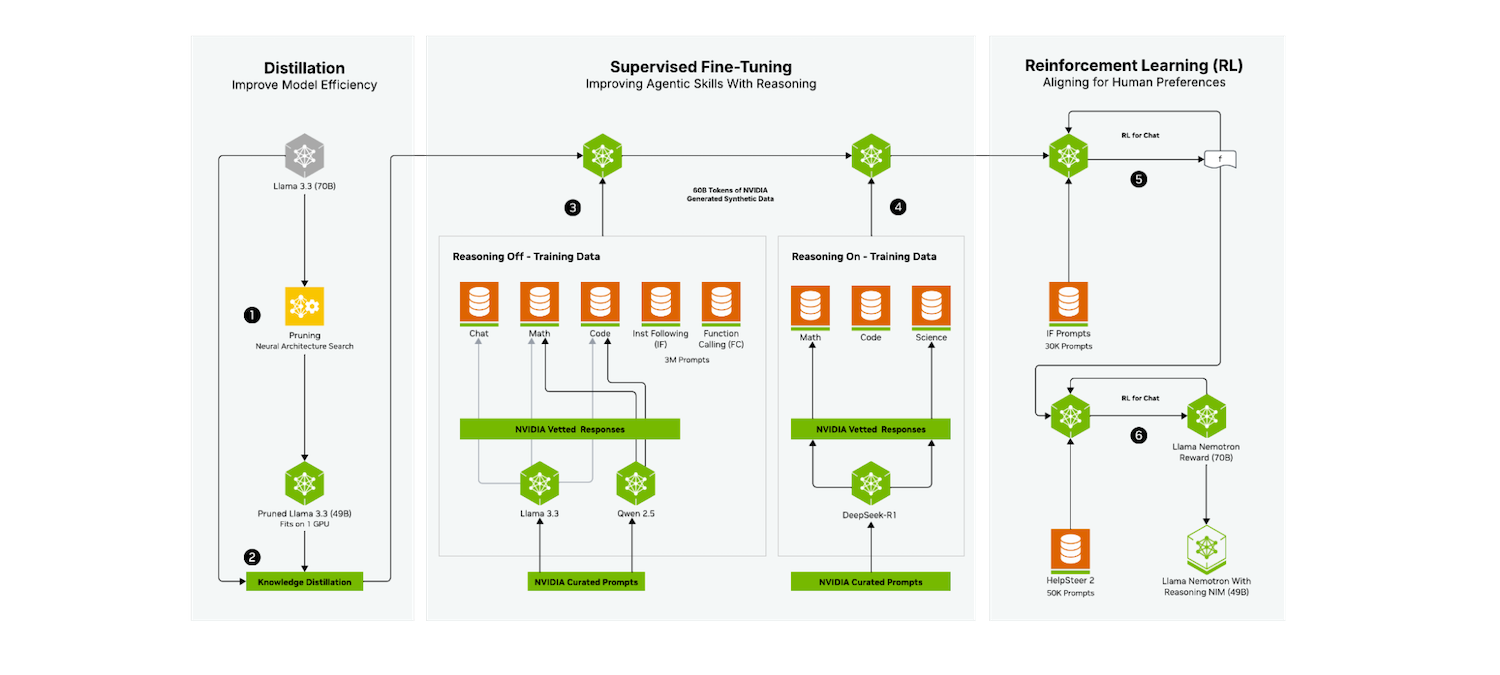
NVIDIA is providing 3 trillion tokens of Nemotron datasets for pre-, post-, and reinforcement learning. These datasets include a wide range of examples involving reasoning, coding, and multi-step workflows that can be used to train or fine-tune domain-specific agents. The Nemotron Agentic Safety Dataset offers real-world telemetry data that teams can use to evaluate and enhance the safety of complex, autonomous systems.
NeMo Gym and NeMo RL
To simplify reinforcement learning and post-training, NVIDIA has released NeMo Gym and NeMo RL as open-source libraries. These provide training environments and post-training foundations aligned with Nemotron models, which can also be extended or adapted for other architectures. NeMo Evaluator is included to assess model safety and performance across a range of benchmarks and use cases.
All of these tools and datasets are available on GitHub and Hugging Face, enabling teams to integrate them into existing MLOps pipelines and training workflows. Ecosystem players like Prime Intellect and Unsloth are already integrating NeMo Gym training environments into their platforms to simplify reinforcement learning for enterprise users.
Nemotron 3 models are also compatible with popular inference and deployment frameworks, including LM Studio, llama.cpp, SGLang, and vLLM, which make it easier to conduct local experimentation and deploy to various environments.
Availability
Nemotron 3 Nano is available today through multiple distribution channels outlined below.
Model Hubs and Inference Providers: The Nemotron 3 Nano model is available on Hugging Face and through inference providers including Baseten, DeepInfra, Fireworks, FriendliAI, OpenRouter, and Together AI. These services give teams a fast path to evaluate the model and integrate it into existing applications.
Enterprise Platforms: Nemotron models are being integrated into enterprise AI and data platforms, including Couchbase, DataRobot, H2O.ai, JFrog, Lambda, and UiPath. This enables customers to embed Nemotron-powered capabilities directly into their data, orchestration, and automation stacks.
Public Cloud and NIM Microservices: For public cloud users, Nemotron 3 Nano will be available on AWS via Amazon Bedrock for serverless inference, and will also be available on Google Cloud, CoreWeave, Crusoe, Microsoft Foundry, Nebius, Nscale, and Yotta.
Nemotron 3 Nano is also offered as an NVIDIA NIM microservice for secure, scalable deployment on NVIDIA-accelerated infrastructure, giving enterprises more control over privacy, data locality, and performance.
Nemotron 3 Super and Ultra are expected to be available in the first half of 2026, giving organizations time to standardize on the Nano tier for early agentic use cases and plan future migrations to larger models as requirements grow.


 Amazon
Amazon