

PEAK:AIO has introduced an innovative solution designed to unify KVCache acceleration with GPU memory expansion, targeting the demands of large-scale AI workloads. This new platform addresses the needs of inference, agentic systems, and model creation, as AI applications move beyond static prompts to dynamic context streams and long-running agents. The shift in AI workload complexity requires a corresponding evolution in infrastructure, and PEAK:AIO’s latest offering is engineered to meet these challenges head-on.
Eyal Lemberger, Co-Founder and Chief AI Strategist at PEAK:AIO, underscores the critical need to treat token history as memory rather than traditional storage. He points out that modern AI models can require more than 500GB of memory per instance, and that scaling memory must keep pace with advances in compute. Lemberger notes that as transformer models grow and become more complex, legacy approaches, such as retrofitting storage stacks or overextending NVMe, are no longer sufficient. The new 1U Token Memory Platform from PEAK:AIO is purpose-built for memory-centric operations, not file storage, marking a significant departure from conventional architectures.
Token-Centric Architecture for Scalable AI
The PEAK:AIO platform is the first to implement a token-centric architecture leveraging CXL memory, Gen5 NVMe, and GPUDirect RDMA to deliver up to 150 GB/sec sustained throughput with sub-5 microsecond latency.
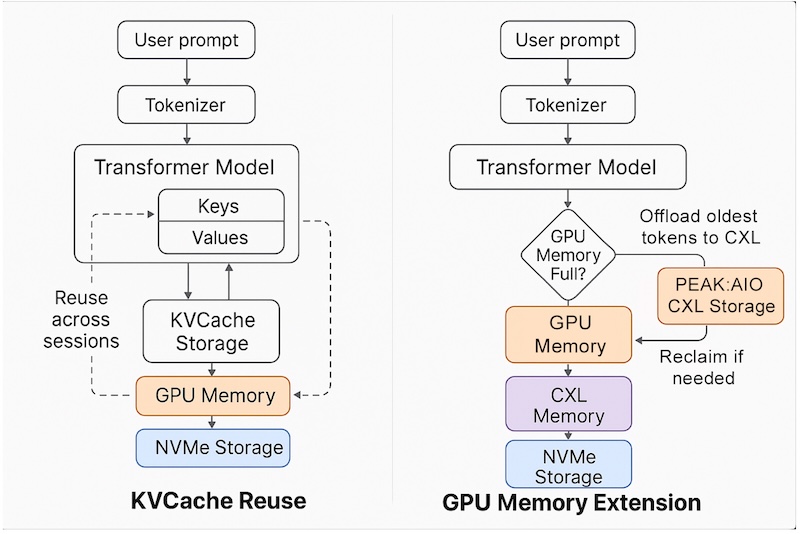
The platform supports KVCache reuse across sessions, models, and nodes, allowing for more efficient memory utilization and faster context switching. It also enables context-window expansion, critical for maintaining longer LLM histories and supporting more complex AI interactions. By offloading GPU memory through true CXL tiering, the solution alleviates GPU memory saturation, a common bottleneck in large-scale AI deployments. Ultra-low latency access is achieved using RDMA over NVMe-oF, ensuring token memory is available at memory-class speeds.
Unlike traditional NVMe-based storage solutions, PEAK:AIO’s architecture is designed to function as a true memory infrastructure. This allows teams to cache token history, attention maps, and streaming data with the speed and efficiency of RAM, rather than treating these elements as files. The platform fully aligns with NVIDIA’s KVCache reuse and memory reclaim models, providing seamless integration for teams working with TensorRT-LLM or Triton. This plug-in compatibility accelerates inference and reduces integration overhead, delivering a significant performance advantage.
Lemberger emphasizes that while other vendors attempt to adapt file systems to behave like memory, PEAK:AIO has developed infrastructure that inherently operates as memory. This distinction is crucial for modern AI, where the priority is rapid, memory-class access to every token, not just file storage.
Mark Klarzynski, co-founder and chief strategy officer at PEAK:AIO, highlights using CXL technology as a key differentiator. He describes the platform as a true memory fabric for AI, unlike competitors who stack NVMe devices. Klarzynski notes that this innovation is essential for delivering genuine memory capabilities at scale and supporting the next generation of AI workloads.
The solution is fully software-defined and runs on off-the-shelf servers, making it accessible and scalable for various enterprise and cloud environments. PEAK:AIO expects the platform to enter production by Q3, positioning it as a transformative technology for technical sales, engineering teams, and executives seeking to future-proof their AI infrastructure.


 Amazon
Amazon