

Some servers extend what already exists, while others reset expectations. The Dell PowerEdge R7725xd belongs to the second category. In our recent testing, configured with 24 Micron 9550 PRO PCIe Gen5 NVMe SSDs and four 2x 200GbE NICs, this 2U server achieved higher raw storage throughput than any system we have measured before. Internally, the platform sustained over 300 GB/s across the NVMe pool. Over the network, it delivered 160 GB/s using standard RDMA, with no added complexity.

This is not just a faster storage server. It is a system that changes how data-intensive computing is architected. Modern AI training and inference pipelines are often constrained not by GPU horsepower, but by how quickly data can be staged, streamed, shuffled, and checkpointed. Large GPU nodes will sit idle if storage cannot keep up. Teams address these limitations by using caches, oversizing, and complex tiering to ensure that accelerators receive data quickly enough to justify their costs.
The Dell PowerEdge R7725xd addresses the bottleneck at the source. The server is built around a 24-bay U.2 backplane, with each drive receiving a dedicated PCIe Gen5 x4 link directly to the AMD EPYC CPU complex. There is no bandwidth fan-out, and no midplane expander is used to reduce concurrency. Performance scales cleanly because the hardware is architected to aggregate throughput without contention. In a traditional 2-socket configuration, the CPUs are connected by 4 XGMI links for inter-socket communication. In the R7725xd, one of these links are repurposed for an additional 16 lanes of PCIe Gen5, per CPU, giving the server a total of 160 lanes of PCIe Gen5 (96 for the front SSDs and 64 for the four rear PCIe slots. When paired with Micron’s 9550 PRO SSDs, which are designed for sustained write workloads and high endurance, the system becomes a high-throughput data engine capable of supporting checkpoint-intensive and continuous streaming workloads.
We layered PEAK:AIO on top of this architecture to leverage parallel submission paths and maintain efficiency as concurrency increased. The result was not only peak performance but also sustained performance under load. The platform can operate as a local execution node for preprocessing, training, or transformation, or it can serve high-bandwidth storage across multiple GPU systems over the network. If you’re feeling adventurous, you can do both simultaneously.
Key Takeaways
- Unprecedented Throughput in a Single Node: The R7725xd sustained over 300 GB/s of internal bandwidth and 160 GB/s over NVMe-oF RDMA, rivaling multi-node storage clusters inside a 2U chassis.
- True Gen5 Architecture, No Switches, No Fan-Out: All 24 Micron 9550 PRO SSDs receive dedicated x4 PCIe Gen5 lanes directly from the CPU complex, allowing line-rate scaling without contention.
- Powered by AMD EPYC 9005 Series: Dual AMD EPYC 9575F processors provide the lane count, memory bandwidth, and NUMA topology necessary for sustained high-concurrency I/O.
- Designed for AI, Analytics, and Checkpoint-Heavy Workloads: The system eliminates the I/O bottlenecks that stall modern GPU pipelines, enabling continuous, high-bandwidth data delivery.
- PEAK:AIO Unlocks Full Parallelism: PEAK:AIO’s software stack keeps queue structures saturated under load, delivering enterprise performance at a compelling dollar-per-GB ratio.
Purpose-Built for NVMe Throughput
In the latest crop of servers, Dell moved away from using PCIe switches in storage-dense server configurations. Models such as the PowerEdge R770 or R7725 offer PCIe Gen5 x4 bays, supporting up to 16 SSD configurations, and switch to x2 bays in larger storage backplane configurations. Previous-generation servers, such as the PowerEdge R760, would include a PCIe switch in 24-bay NVMe configurations. To simplify builds and remove the complexity introduced by a PCIe switch, new servers adopted a strategy of reducing the number of PCIe lanes in storage-dense builds. That is, until the R7725xd.
The distinction between the standard R7725 and the R7725xd comes down to how the platforms allocate PCIe root-complex resources. The base R7725 distributes PCIe lanes across storage, GPU expansion, and general-purpose I/O. The ‘xd’ variant reallocates that budget so that the NVMe subsystem becomes the primary consumer of PCIe bandwidth. The 24 U.2 bays are wired directly into the CPU’s PCIe Gen5 roots, with each SSD receiving its own x4 endpoint, not a shared uplink exposed through a PCIe switch or re-timer tree. This gives every drive independent queue structures and independent DMA paths back to the memory controller.

The backplane and riser topology reflect this commitment. Dell groups the NVMe connectors and PCIe slots across both AMD EPYC sockets, so each processor has direct ownership of a portion of the drive set. In practice, this creates two symmetric NVMe domains, each with local latency characteristics and full read/write concurrency. When we installed four Broadcom dual-port 200GbE NICs as add-in cards, slot placement allowed each NIC to land in a PCIe domain aligned to the corresponding NVMe group. Under NVMe-over-RDMA, this meant network traffic remained local to the socket handling the associated drive I/O, avoiding the inter-socket Infinity Fabric hop that typically adds latency and consumes bandwidth under load.
Thermal behavior also supports sustained throughput. U.2 remains advantageous in dense Gen5 configurations because it provides a defined airflow channel and predictable heatsink surface area for each device. The R7725xd’s high-static-pressure fan modules and chassis ducting maintain consistent airflow across all 24 bays, allowing full-drive write workloads to run continuously without throttling. The mechanical design complements the electrical one: each drive can maintain full-rate performance because the platform is built to cool 24 concurrent Gen5 devices at load.
This combination of root-complex alignment, consistent non-uniform memory access (NUMA) lane layout, socket-aware NIC placement, and thermally stable U.2 packaging enables the system to achieve line-rate I/O at scale. The architecture avoids bottlenecks and optimizes performance.
Dell PowerEdge R7725xd iDRAC 10 Overview
This generation of the R7725xd, like many other 17th Gen platforms we have evaluated, features Dell’s new iDRAC 10 platform, which serves as the central point for remote management, health monitoring, and out-of-band control. The dashboard view gives an immediate summary of overall system health, storage status, and recent activity. For our test unit, the system and storage health report is green, confirming that the server is operating normally. Key system details such as model, hostname, BIOS version, iDRAC firmware level, IP address, and licensing information are displayed on the right side of the interface.
The dashboard also includes a task summary panel that shows completed, pending, and in-progress operations. Below this, a listing of recent logs captures chassis intrusion events and power supply messages, providing quick insight into hardware state changes without requiring navigation to deeper menus. The virtual console panel is available in the lower-right corner for full remote KVM control.
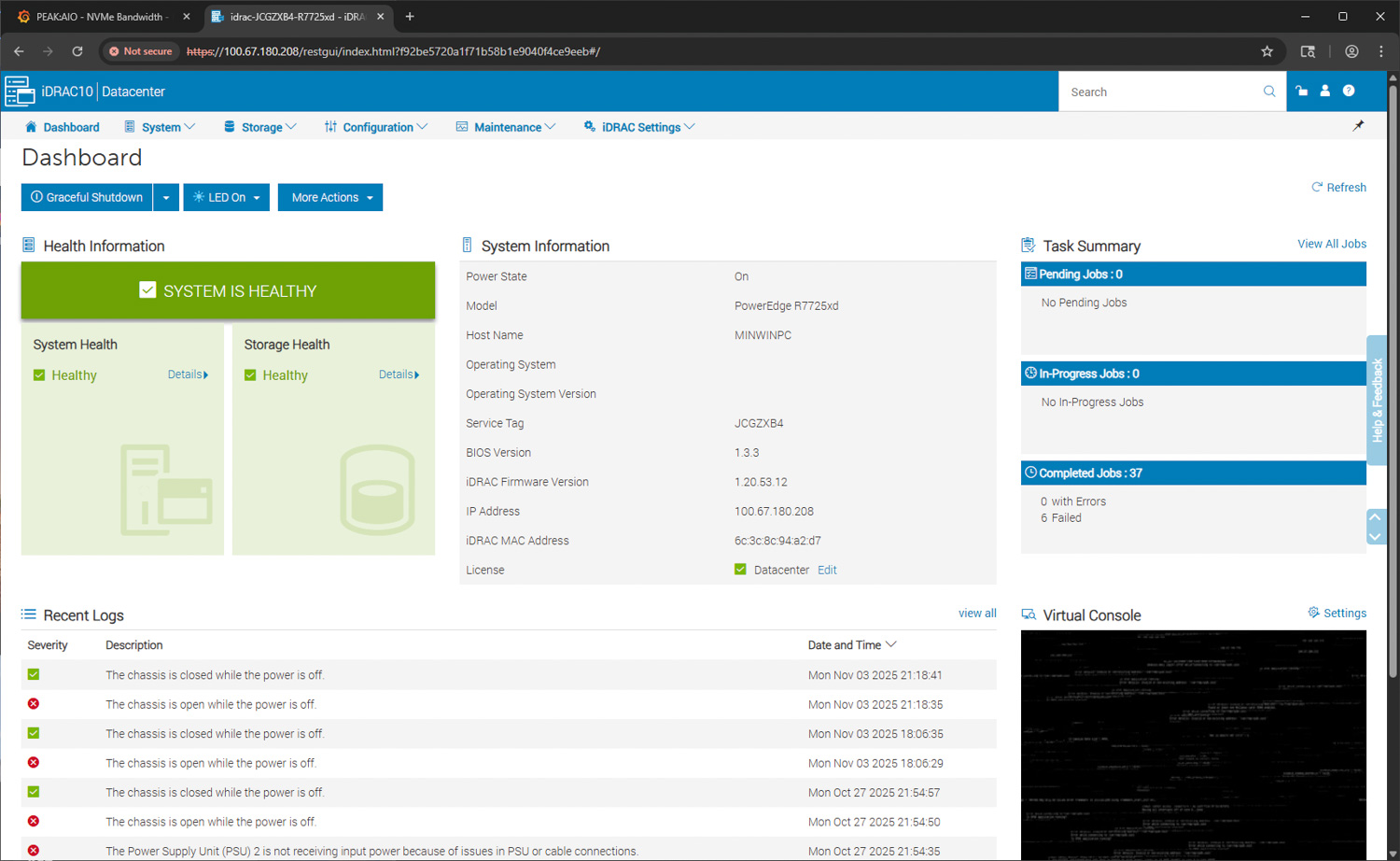
The storage section of iDRAC 10 presents a complete overview of all physical disks installed in the R7725xd. The summary panel displays a high-level count of all connected drives, accompanied by a visual pie chart that illustrates the drive states. In this configuration, 24 NVMe SSDs are active and reporting as ready, with two additional boot devices present in the system, separate from the primary front NVMe bank.
On the right, the Summary of Disks panel breaks these down into physical disks and any associated virtual disks. Since the R7725xd uses a direct NVMe architecture without traditional RAID controllers, all drives are reported as Non-RAID and individually addressable, aligning with the system’s design for large NVMe pools and SDS platforms.
Below the status summary, the Recently Logged Storage Events area lists insertion logs for each PCIe SSD, organized by bay and slot. This record confirms proper detection across all drive bays and helps identify any issues with seating, cabling, or hot-swap activity. For large deployments, these logs are useful when tracking drive provisioning or verifying that capacity has been populated as expected.
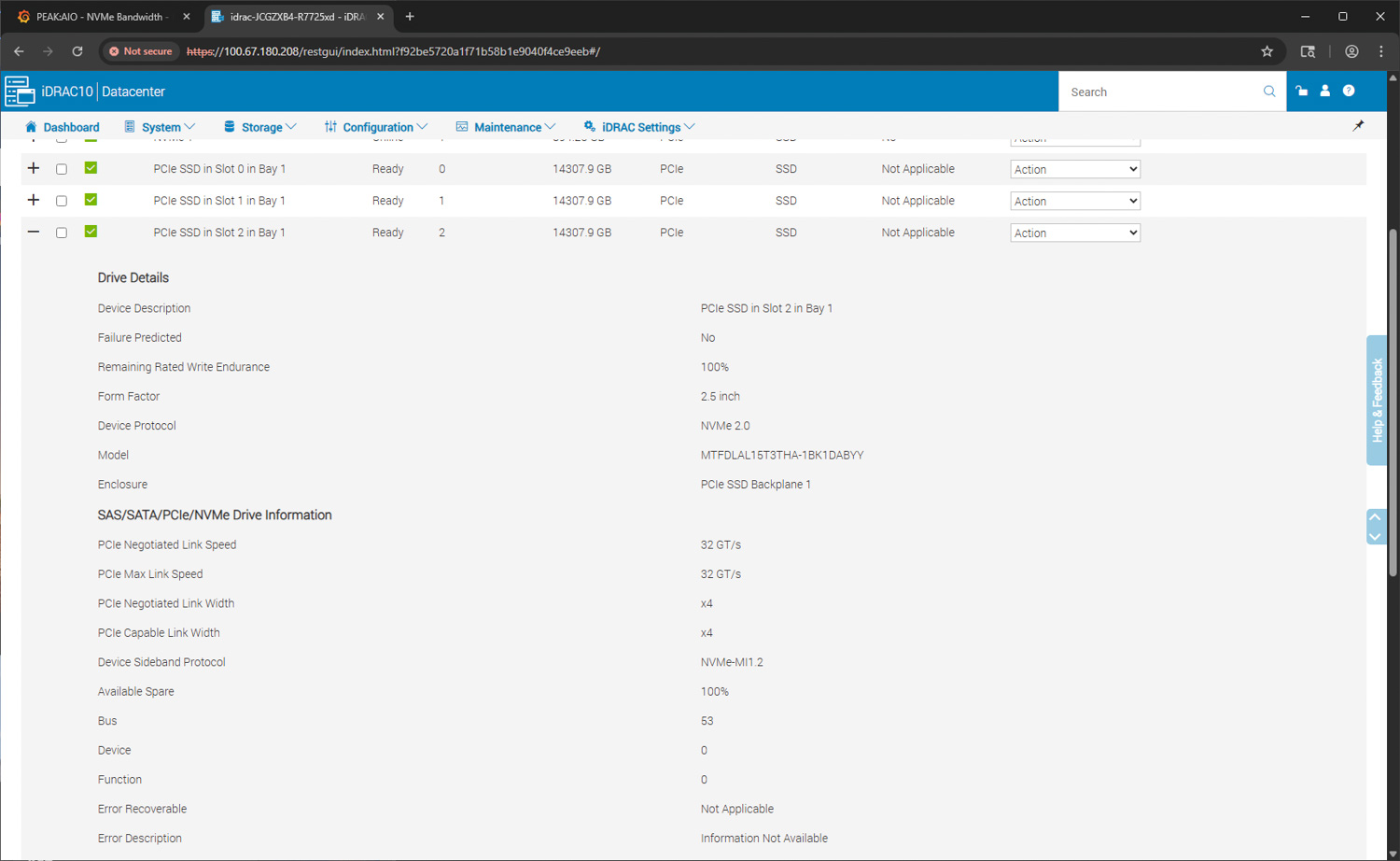
The final screenshot shows the detailed NVMe device view within iDRAC10. Each NVMe drive installed in the system is listed with its status, capacity, and bay location. Selecting an individual drive opens a complete breakdown of its characteristics.
In this example, the drive information panel displays the full model string, device protocol, form factor, and negotiated PCIe settings. The NVMe devices are running at 32 GT/s link speed with a negotiated x4 connection, confirming that the drives are operating at full bandwidth on the system’s PCIe Gen5 backplane. The information section also reports endurance percentage, available spare status, and protocol type, helping administrators monitor drive health and lifecycle expectations.
This granular drive reporting is valuable in high-density NVMe configurations where link width, negotiated speed, and media health directly influence workload behavior and storage performance.
Overall, the iDRAC 10 interface provides a clear, hardware-centric view of the R7725xd’s NVMe storage architecture, enabling easy validation of link health, drive status, and system integrity at a glance.
Dell PowerEdge R7725xd Performance
Before testing, our system was configured with a balanced yet high-performance loadout. The system is equipped with two AMD EPYC 9575F processors, each featuring 64 high-frequency cores, and paired with 24 32GB DDR5 DIMMs operating at 6400 MT/s. For storage, the chassis is fully populated with 24 15.36TB Micron 9550 PRO U.2 NVMe SSDs, each connected through a dedicated PCIe Gen5 x4 link. This provides a total raw capacity of 368.64 TB, and the Micron 9550 PRO drives deliver sequential read speeds of up to 14,000 MB/s and sequential write speeds of up to 10,000 MB/s. Networking is handled by four Broadcom BCM57608 adapters that supply a combined eight 200Gb ports, along with a BCM57412 OCP NIC offering two additional 10-gigabit ports.

Test System Specifications
- CPU: 2x AMD EPYC 9575F 64-Core High-Frequency Processors
- Memory: 24x 32GB DDR5 @ 6400MT/s
- Storage: 24x 15.36TB Micron 9550 PRO U.2 drives (connected at 4x lanes of PCIe Gen5 each); supports up to 128TB drives today with higher capacities on the horizon
- Network: 4x Broadcom BCM57608 2x200G NICs, 1x BCM57412 2x10Gb OCP NIC
- Switch: Dell PowerSwitch Z9664
FIO Performance Benchmark
To measure the storage performance of the PowerEdge R7725xd, we used industry-standard metrics and the FIO tool. In this section, we focus on the following FIO benchmarks:
- Random 4K – 1M
- Sequential 4K – 1M

FIO – Local – Bandwidth
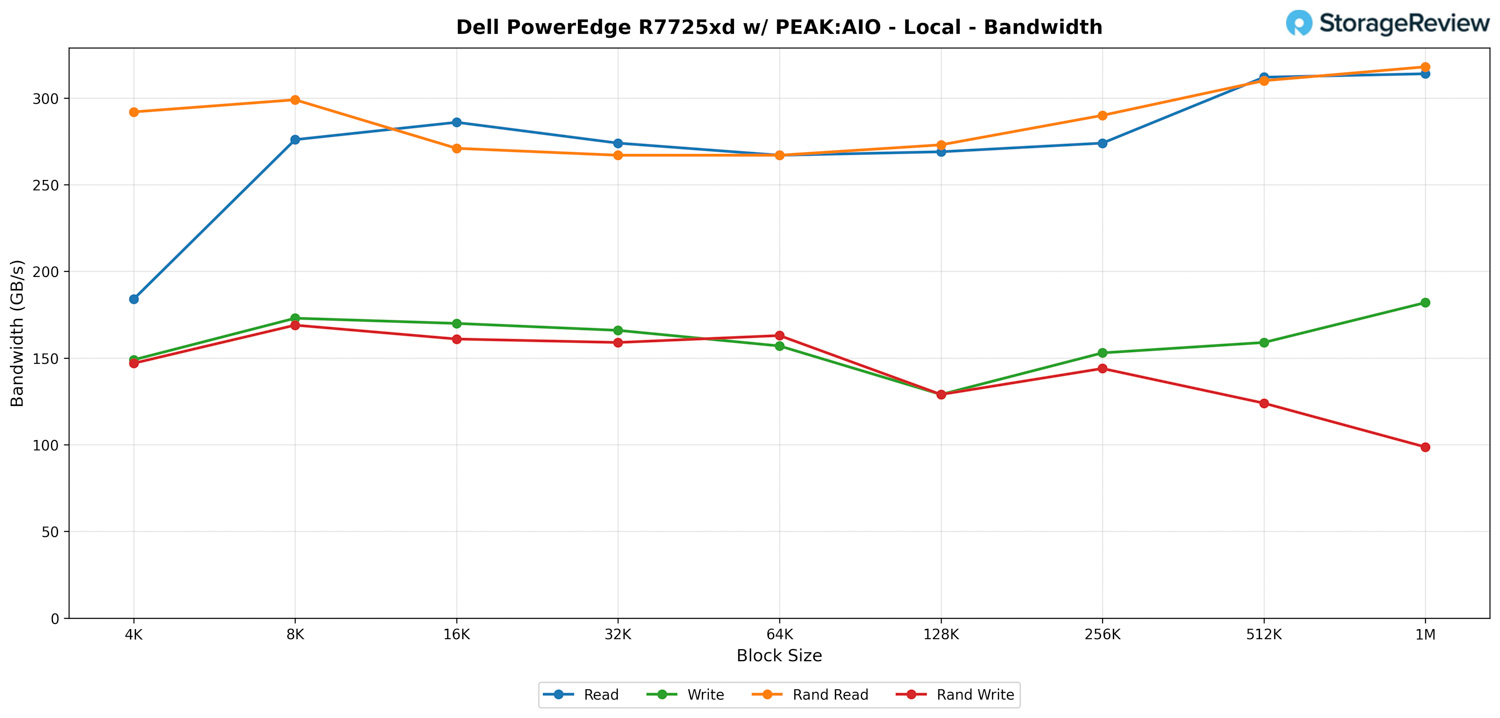
When testing local access to the 24 PCIe Gen5 NVMe drives inside the Dell PowerEdge R7725xd, the system shows exactly what you would expect from a platform where every drive is connected to the CPUs using a full x4 lane PCIe Gen5 link. With no network layer involved, this is the pure, internal throughput of Dell’s Gen5 storage layout and the AMD EPYC platform’s PCIe bandwidth working without restriction.
Sequential reads begin at 184 GB/s with 4K blocks and scale quickly as block size increases. From 512K to 1M, the server maintains a consistent 312 to 314 GB/s, which is a strong indication of how well the system can aggregate all 24 × 4 Gen5 lanes into sustained read bandwidth without any controller-stage bottlenecks.
Sequential writes follow a different curve but stay firmly in the expected range. Starting at 149 GB/s, results rise through the mid-100s and reach 182 GB/s at 1 million. This aligns with the write behavior of the Micron 9550 PRO SSDs and the overhead inherent to high-parallel NVMe writes across so many independent devices.
Random read performance is another highlight. The system achieves speeds of nearly 300 GB/s at the smallest block sizes, dips slightly in the mid-range, and then recovers to the upper 200s and low 300s at larger block sizes. At 1M, random reads reach a maximum of 318 GB/s, demonstrating the platform’s ability to distribute mixed operations evenly across all 24 drives.
Random writes come in at a lower rate, which is typical for dispersed metadata and write-allocation tasks across a broad NVMe set. Results remain in the 140 to 160 GB/s range for most of the test and taper to just under 100 GB/s at 1 M.
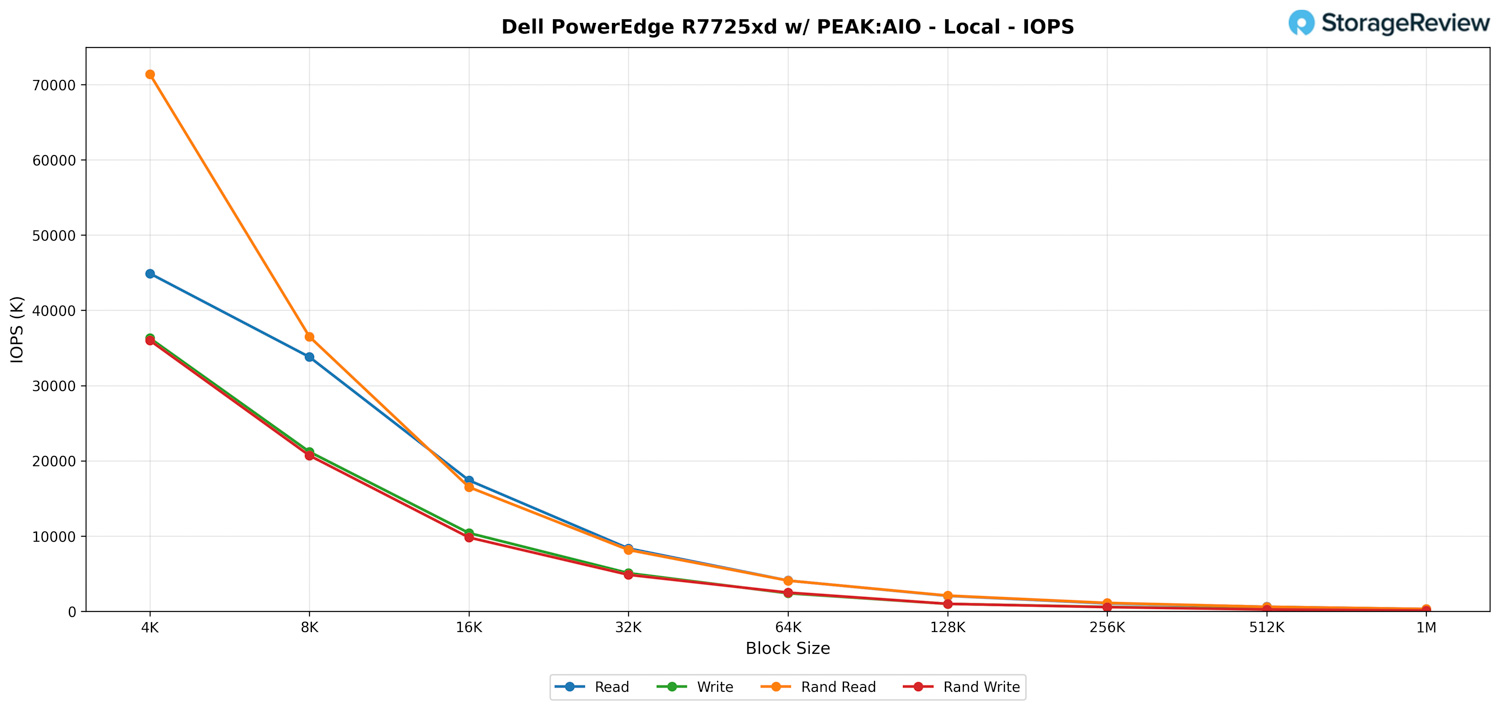
FIO – Local – IOPS
When examining the IOPS side, the R7725xd demonstrates robust small-block performance, with request rates reaching well into the tens of millions before larger block sizes shift the workload toward a bandwidth-driven profile.
At 4K, reads hit 44.9 million IOPS and writes come in at 36.3 million. Random reads reach even higher levels at 71.4 million IOPS, demonstrating the system’s ability to efficiently distribute high-queue workloads across all drives. These values naturally taper as block sizes increase, but the progression remains consistent through the 8K, 16K, and 32K ranges.
By 16K and 32K blocks, reads settle at 17.4 million and 8.35 million IOPS, with random reads closely matching at 16.5 million and 8.15 million. Writes follow the expected pattern, tracking lower but remaining stable across both sequential and random access patterns.
As we move into 64K and above, the test transitions from pure IOPS to a more bandwidth-bound scenario. IOPS fall into the low-million range and eventually into the hundreds of thousands. At 1M block size, read IOPS land around 300K, writes at about 174K, and random operations finish in the same neighborhood.
Overall, the local IOPS results clearly show the system’s ability to sustain very high queue-depth workloads across small blocks, with predictable scaling as transfers grow and bandwidth becomes the dominant factor.
PEAK:AIO: Why the Dell PowerEdge R7725xd Fits This Workload
PEAK:AIO is designed for environments that demand extremely fast, low-latency access to large datasets, typically for AI training, inference pipelines, financial modeling, and real-time analytics. The platform thrives on dense NVMe storage, balanced PCIe bandwidth, and predictable latency at scale. To meet these requirements, the underlying hardware must deliver sustained throughput while maintaining consistent and repeatable performance under concurrent heavy loads.
This is where the Dell PowerEdge R7725xd aligns naturally with PEAK:AIO. The system’s architecture is designed to maximize PCIe Gen5 resources, exposing the full bandwidth of its 24 front-mounted U.2 NVMe bays directly to the CPUs, without relying on traditional RAID controllers. This layout gives PEAK:AIO the parallelism and latency profile it expects from modern NVMe-based data pipelines. The system configuration divided the NVMe SSDs into two RAID0 groups.

In the tested scenario, we used two client systems connected to the R7725xd, each equipped with Broadcom BCM57608 2x 200G NICs. That created a total of four 200G uplinks feeding into each client, pushing the R7725xd into a realistic high-performance configuration that mirrors what PEAK:AIO deployments see in production. This level of network bandwidth gave us the headroom to fully stress the NVMe subsystem, the PCIe topology, and the CPU interconnects without bottlenecking at the NIC layer.
The result is a platform that aligns effectively with PEAK:AIO workloads. The R7725xd provides dense NVMe capacity, PCIe Gen5 throughput, dual AMD EPYC 9005 processors for parallelism, and the networking capability to sustain multi-client data ingestion at hundreds of gigabits per client. All of these characteristics are foundational to achieving PEAK:AIO’s performance expectations.
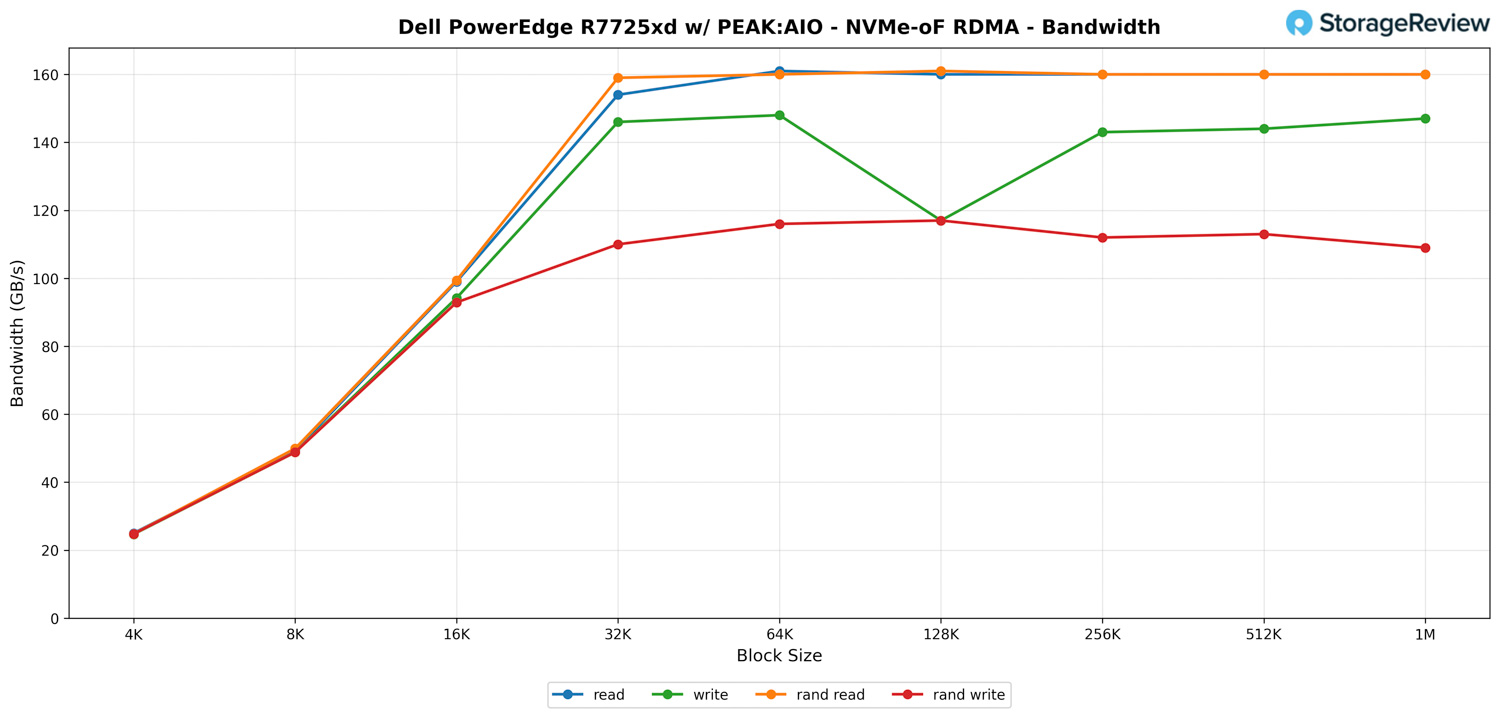
PEAK:AIO – NVMe-oF RDMA – Bandwidth
Examining the NVMe-oF RDMA bandwidth results on the PowerEdge R7725xd with PEAK:AIO, the overall trend is precisely what we expect from a system with this much PCIe and network bandwidth. As the block size increases, throughput rises rapidly until it levels off near the platform’s practical limit.
At the small block sizes, performance starts in the mid-20GB/s range for both reads and writes, which is normal because 4K and 8K transfers push the IOPS path much harder than the throughput path. Once we get into the 16K and 32K blocks, the pipeline opens up. Reads jump to around 154 GB/s at 32K and continue climbing to the 160 GB/s range, which is right where we would expect a dual-client setup over four 200 Gb/s links to land.
Random read performance mirrors sequential almost perfectly. PEAK:AIO does a nice job of keeping command queues fed, so random read bandwidth essentially tracks sequential read bandwidth all the way up, settling at roughly 159 to 161 GB/s from 32K through 1M. This indicates that the storage stack is not bottlenecking under mixed access patterns, and the R7725xd’s PCIe topology is distributing the load evenly across the 24 Gen5 NVMe drives.
Write performance follows a similar curve, although it tops out slightly lower than reads. Sequential writes remain in the 140 to 148 GB/s range through the mid-sized blocks, dipping to approximately 117 GB/s at 128K but recovering as the block size increases. Random writes behave differently and flatten out closer to 110-117 GB/s, which is normal for mixed-queue workloads that introduce additional overhead.
The key takeaway from this section is that the R7725xd has no trouble sustaining extremely high bandwidth over NVMe-oF, even with multiple clients driving the system to its limits. Once block sizes reach 32K or higher, the server consistently saturates its available network and storage bandwidth. This is exactly the type of performance PEAK:AIO is designed to extract, making these results a strong validation of the platform’s ability to scale under real-world conditions.
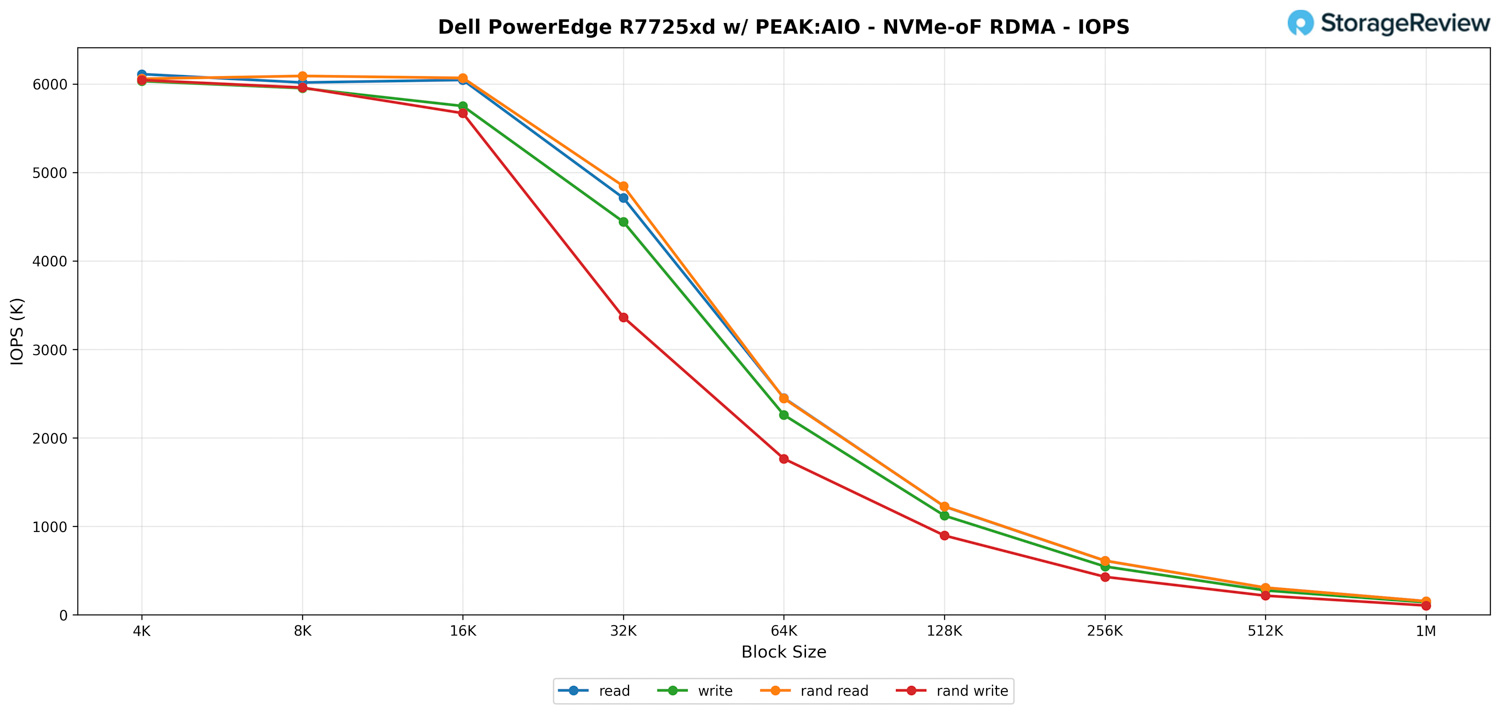
PEAK AIO – NVMe-oF RDMA IOPS
On the IOPS side, the PowerEdge R7725xd exhibits strong small-block performance, although we initially observed lower-than-expected numbers; this issue is expected to be addressed with improved network driver support in the future. Even with that in play, the overall scaling trend appears exactly as NVMe-oF RDMA typically behaves when the block size increases.
At the smallest block size, the system can deliver more than 6 million IOPS across both sequential and random workloads. Read, write, random read, and random write all sit in roughly the same range at 4K and 8K, indicating that the front-end clients, PCIe infrastructure, and the NVMe drives themselves have no trouble keeping up with the request rate.
As the block sizes grow, the expected drop in IOPS begins. At 32K, reads land around 4.7 million IOPS, while writes trail slightly behind at about 4.4 million. Random writes take the biggest hit here, falling to roughly 3.3 million IOPS, which aligns with the additional queue and CPU overhead introduced by mixed-access patterns.
Moving into the large blocks, IOPS continues to taper in a predictable linear fashion. By the time we reach 256K and 512K transfers, throughput becomes the dominant metric, and IOPS naturally drops into the mid-hundreds of thousands. At a 1M block size, all workloads converge to 140K-153K IOPS, consistent with the bandwidth numbers we saw in the previous section.
GPUDirect Storage Performance
One of the tests we conducted on the R7725xd was the Magnum IO GPUDirect Storage (GDS) test. GDS is a feature developed by NVIDIA that allows GPUs to bypass the CPU when accessing data stored on NVMe drives or other high-speed storage devices. Instead of routing data through the CPU and system memory, GDS enables direct communication between the GPU and the storage device, significantly reducing latency and improving data throughput.
How GPUDirect Storage Works
Traditionally, when a GPU processes data stored on an NVMe drive, the data must first travel through the CPU and system memory before reaching the GPU. This process introduces bottlenecks, as the CPU becomes a middleman, adding latency and consuming valuable system resources. GPUDirect Storage eliminates this inefficiency by enabling the GPU to access data directly from the storage device via the PCIe bus. This direct path reduces data movement overhead, enabling faster and more efficient data transfers.
AI workloads, especially those involving deep learning, are highly data-intensive. Training large neural networks requires processing terabytes of data, and any delay in data transfer can lead to underutilized GPUs and longer training times. GPUDirect Storage addresses this challenge by ensuring that data is delivered to the GPU as quickly as possible, minimizing idle time and maximizing computational efficiency.
In addition, GDS is particularly beneficial for workloads that involve streaming large datasets, such as video processing, natural language processing, or real-time inference. By reducing the reliance on the CPU, GDS accelerates data movement and frees up CPU resources for other tasks, further enhancing overall system performance.
Beyond raw bandwidth, GPUDirect with NVMe-oF (TCP/RDMA) also delivers ultra-low-latency I/O. This ensures GPUs are never starved for data, making the system ideal for real-time AI inferencing, analytics pipelines, and video replay.
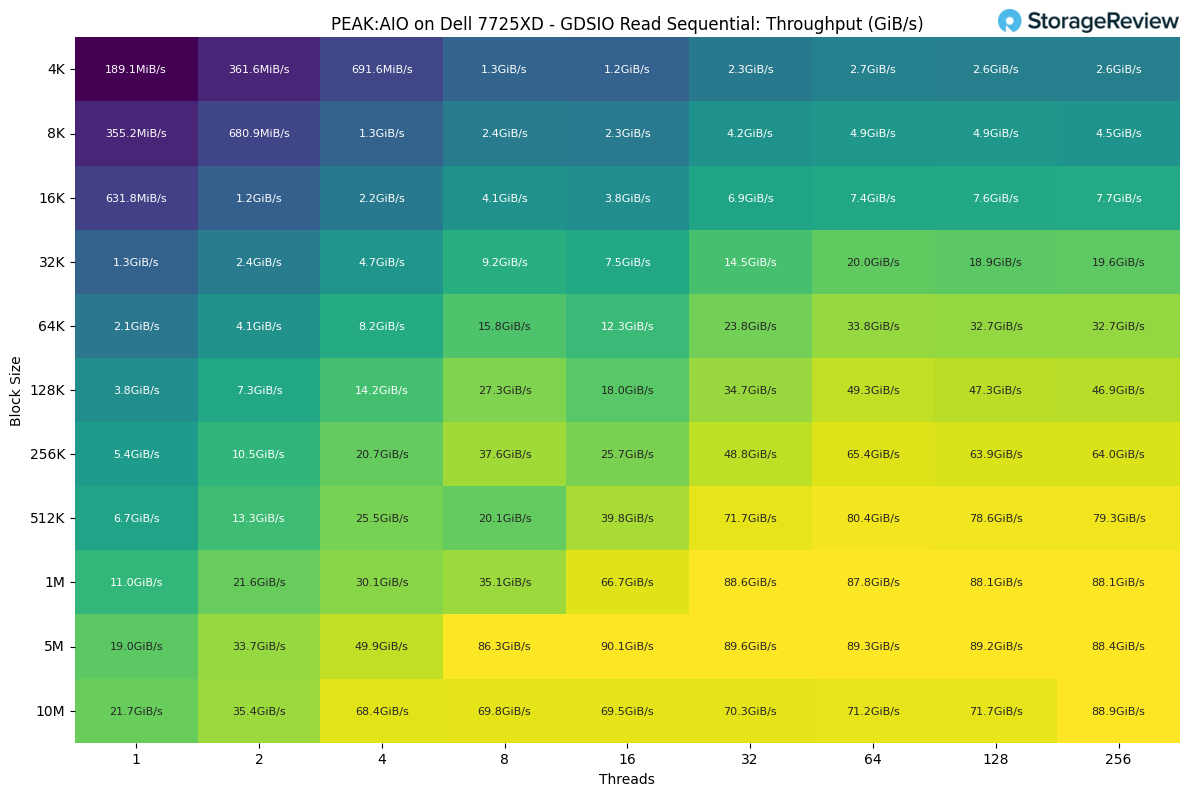
GDSIO Read Sequential
When examining PEAK:AIO with one client using GDSIO, the read throughput exhibits a clear scaling pattern as both block size and thread count increase. This single client was connected via two 400G links, limiting its total potential to 90 GB/s.
At the smallest block sizes and low thread counts, performance is modest, with 4K reads starting around 189 MiB/s at a single thread. As soon as we increase thread parallelism, the system responds immediately, pushing 691MiB/s at four threads and breaking into the multi-GiB/s range as we step into larger blocks.
The mid-range block sizes show the strongest sensitivity to thread count. At 32K, throughput grows from 1.3 GiB/s at a single thread to nearly 20 GiB/s by 64 threads, with only slight tapering beyond that. A similar pattern appears at 64K and 128K, where the system transitions from low single-digit GiB/s at low parallelism to over 30 GiB/s as the workload scales.
Once we reach the larger block sizes, throughput begins to level off as the system approaches its performance ceiling for a single client. At 1 MiB, performance climbs from 11GiB/s at one thread to around 88GiB/s at high thread counts. The 5 MiB and 10 MiB transfers show the same plateau, topping out around 89–90GiB/s regardless of whether the test is running at 64, 128, or 256 threads.
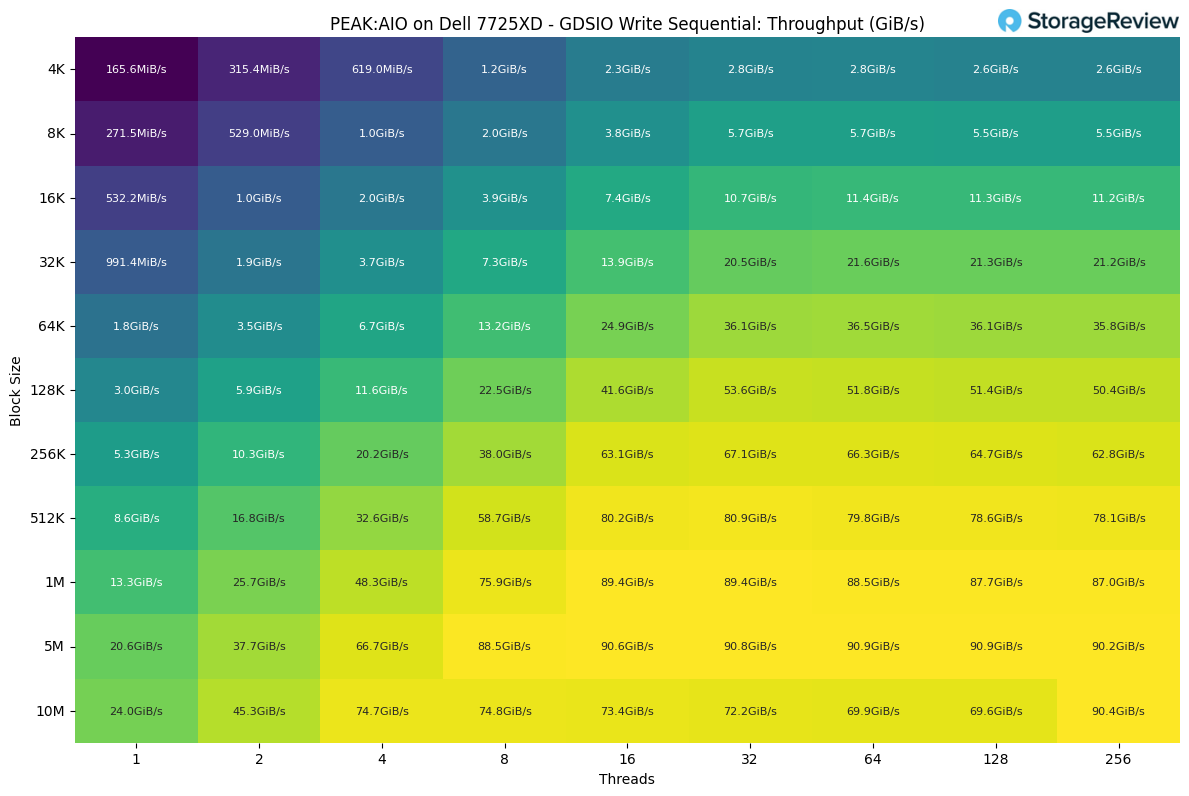
GDSIO Write Sequential
On the write side, the scaling behavior follows a similar pattern to the reads, but with slightly lower performance across most block sizes, which is expected for sequential write workloads. At the smallest block sizes, throughput begins at 165 MiB/s for a single thread at 4K and rises steadily as parallelism increases. At four threads, that grows to just over 619MiB/s before climbing past 1GiB/s at eight threads.
Mid-range block sizes show stronger gains as thread counts rise. At 32K, throughput starts at just under 1 GiB/s and scales to over 21 GiB/s at higher thread levels. The 64K and 128K ranges continue the trend, moving from low single-digit GiB/s to mid-30 GiB/s and 50 GiB/s as the workload becomes more parallel.
Larger transfers are when the system settles into its natural write-throughput ceiling. At 1 MiB, performance climbs from 13.3GiB/s at a single thread to just under 90GiB/s at high thread counts. The 5 MiB and 10 MiB tests follow a similar pattern, with results peaking around 90 GiB/s regardless of whether the system is running at 64, 128, or 256 threads.
Redefining Performance in the Gen5 Era
The Dell PowerEdge R7725xd is more than a storage server; it represents a shift in how bandwidth is delivered inside the rack. By eliminating PCIe switches and giving every NVMe drive a direct path to the CPU, Dell created a system where throughput scales cleanly, thermals remain predictable, and concurrency becomes an asset rather than a challenge.
When paired with Micron’s 9550 PRO SSDs and PEAK:AIO’s parallel I/O software, the R7725xd transforms from a dense NVMe chassis into a true data engine. It can saturate its local PCIe fabric, feed GPUs over RDMA at line rate, or act as both compute and storage simultaneously, all within a 2U envelope.

Dell PowerEdge R7225xd
In practical terms, this configuration delivers more than 300 GB/s of local throughput and 160 GB/s over the network, rivaling the performance of multi-node storage clusters at a fraction of the complexity and cost. It’s a demonstration of what happens when every layer of the stack, from silicon to software, is aligned around efficiency and sustained bandwidth.
The R7725xd sets a new benchmark for single-node storage performance in the Gen5 era. For organizations building next-generation AI pipelines, high-speed analytics, or checkpoint-heavy training environments, it’s a glimpse of what’s possible when the bottlenecks are designed out of the system entirely.
This report is sponsored by Dell Technologies. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.


 Amazon
Amazon