

When Intel® Optane™ persistent memory (PMem) first came out, we knew that it would radically alter the way business is done in the datacenter, but we couldn’t fully predict the number of ways in which it would. As is the case with all new technologies, we knew the initial use cases for persistent memory, but we also understood that additional use cases would appear once they became widely available.

In our discussions with enterprises, we knew that they needed the performance gains that in-memory systems provided to stay competitive. Using DRAM for this had cost and size limitations that made it difficult considering the size of the data that they wanted to store in memory. In this paper, we will look at how Intel Optane PMem is being leveraged by Hazelcast and MemVerge, to overcome the limitations of DRAM to create an infrastructure construct that supports fast, real-time applications that use large data sets.
We joined forces with MemVerge, Hazelcast, Intel, and Dell Technologies to demonstrate how infrastructure can be deployed to enable real-time analytics. Specifically, we set up an environment that had a fast-incoming stream of real-time data that was ingested and transformed prior to being stored into an in-memory data mart. The key objective was to show how Intel Optane PMem is critical to enabling large-scale, real-time systems and that additional software is needed to allow Intel Optane PMem to realize its full potential.
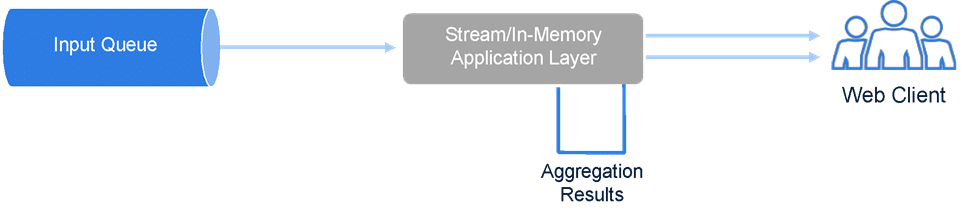
Before highlighting the testing that we did, here is a brief refresher on Intel Optane PMem, Hazelcast, and MemVerge.
Intel Optane PMem
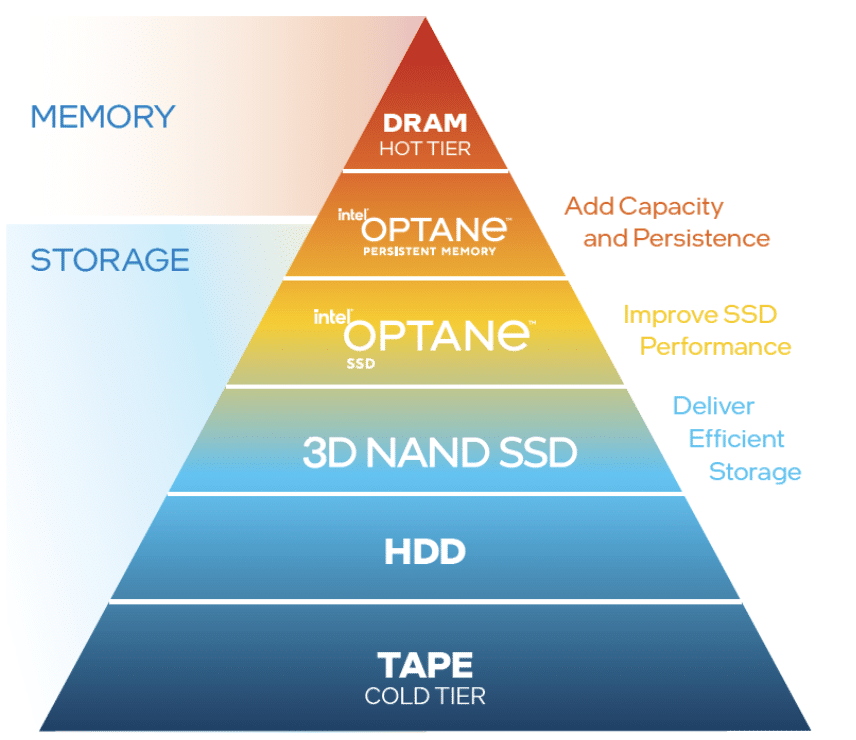
Persistent memory, as a concept, has been around since the mid-1980s, but it only became an actual usable product for commercial data centers in 2018 when Intel began to release their Intel Optane Persistent Memory Modules (PMMs). Intel Optane PMem is a game-changer for the industry as it is slightly slower than DRAM but is considerably faster than solid-state drives (SSDs).
While it is slower than DRAM, Intel Optane PMem does have some distinct advantages over it as it is considerably cheaper, comes in larger memory capacity sizes than traditional DRAM; and, as the name suggests, when enabled in-app direct mode, is persistent – meaning that the data stored on it will survive a power outage or reboot of the device on which it resides.
One of the secrets of Intel Optane PMem’s low latency is that it resides on the memory bus, which allows it to have DRAM-like access to data.
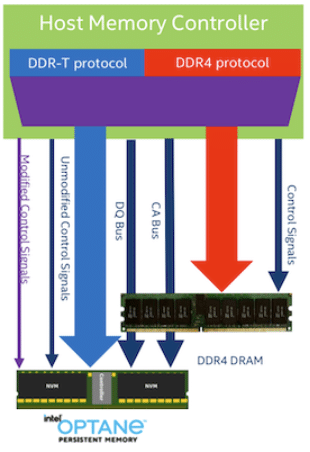
While DDR4 has a theoretical per-module maximum capacity of 128GB, the most commonly used capacities are between 4GB to 64GB (but even 64GB modules, while available, are not commonly being used).
Intel is currently shipping Intel Optane PMem in 128GB, 256GB, and 512GB modules. This provides up to 16 times the capacity of DRAM.
On a cost-per-GB basis, Intel Optane PMem is about half that of DRAM. Due to its larger capacity and lower price, a server can have more low-latency data available for applications at a lower cost than that of a server with just DRAM. And, as you see from our testing, for many applications the latency difference between DRAM and PMem in real-life usage is negligible.
 Although the name of the technology includes the word “persistence,” the persistence of data that lives in Intel Optane PMem is often overlooked and in the past has not been fully exploited. MemVerge, however, has devised ways to take advantage of data persistence to offer additional services to enterprises.
Although the name of the technology includes the word “persistence,” the persistence of data that lives in Intel Optane PMem is often overlooked and in the past has not been fully exploited. MemVerge, however, has devised ways to take advantage of data persistence to offer additional services to enterprises.
MemVerge
With the great power that Intel Optane PMem provides comes the responsibility to use it wisely, and this is where MemVerge comes in. Whereas most server-monitoring and management tools look at legacy hardware such as CPU, disk, and network metrics, MemVerge® Memory Machine™ is laser-focused on the monitoring, management, and utilization of DRAM and Intel Optane PMem.
One of the early challenges of Intel Optane PMem was determining how to allow applications to use it. Without MemVerge Memory Machine you can use Intel Optane PMem as an alternative to DRAM, but not as a drop-in replacement since Intel Optane PMem uses a specialized API. MemVerge abstracts away that API so that Intel Optane PMem looks just like DRAM to all applications. Using Memory Machine, Intel Optane PMem is presented to applications the same as DRAM is to applications. By doing this, existing applications can use Intel Optane PMem without having to be rearchitected, thereby saving a company the cost of reprogramming applications, and, more importantly, the time it would take to do so. Through its patented technology, Memory Machine creates a pool of memory and then tiers Intel Optane PMem and DRAM to maximize its impact on applications by moving data between the two as needed to optimize application performance.
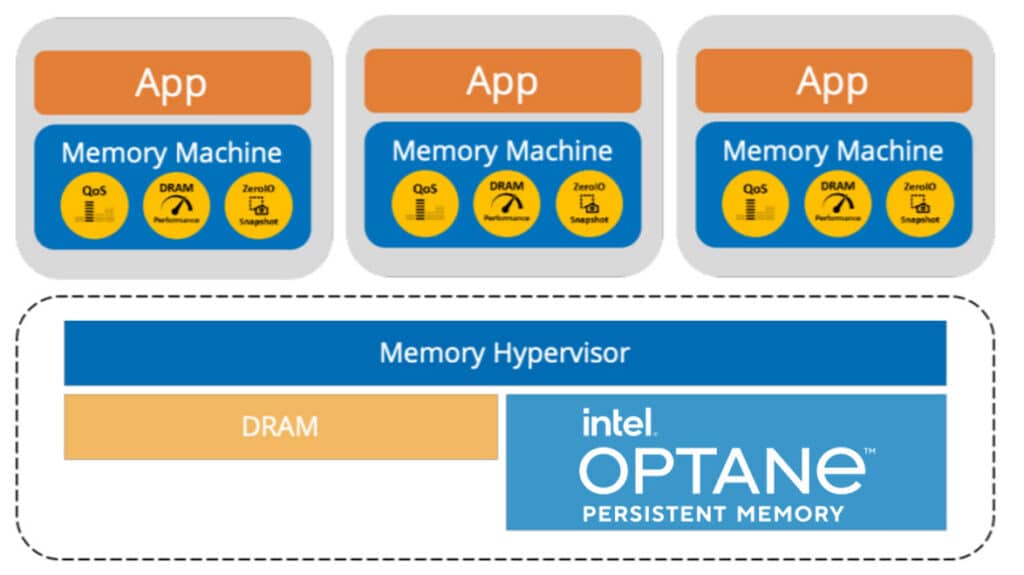
Memory Machine’s innovative ZeroIO allows memory-to-memory snapshots (i.e., snapshots of the data contained on DRAM to Intel Optane PMem), which in effect makes DRAM persistent.
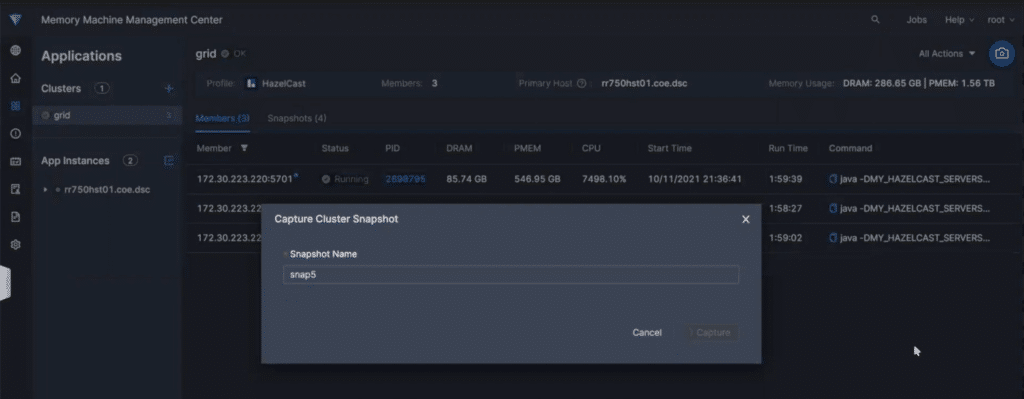
In the past, we were forced to store in-memory snapshots on traditional storage, a process that could take as long as an hour. Using ZeroIO, however, the same operation can take place, non-disruptively, in a matter of seconds.
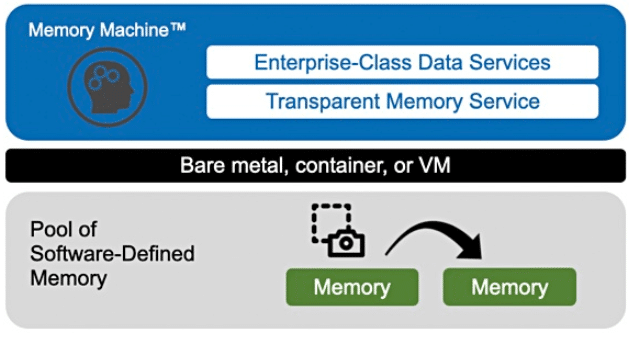
MemVerge leverages ZeroIO to provide other memory data services. Time Travel allows an application to revert to previously taken snapshots, and closely coupled with this feature is AutoSave which automatically takes snapshots on time-based intervals. In instances where the data stored in memory needs to be moved to another physical server, a ZeroIO snapshot can be moved to it.
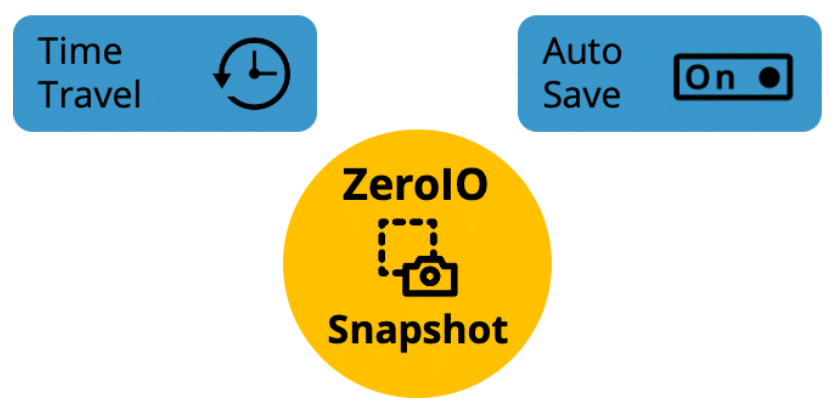
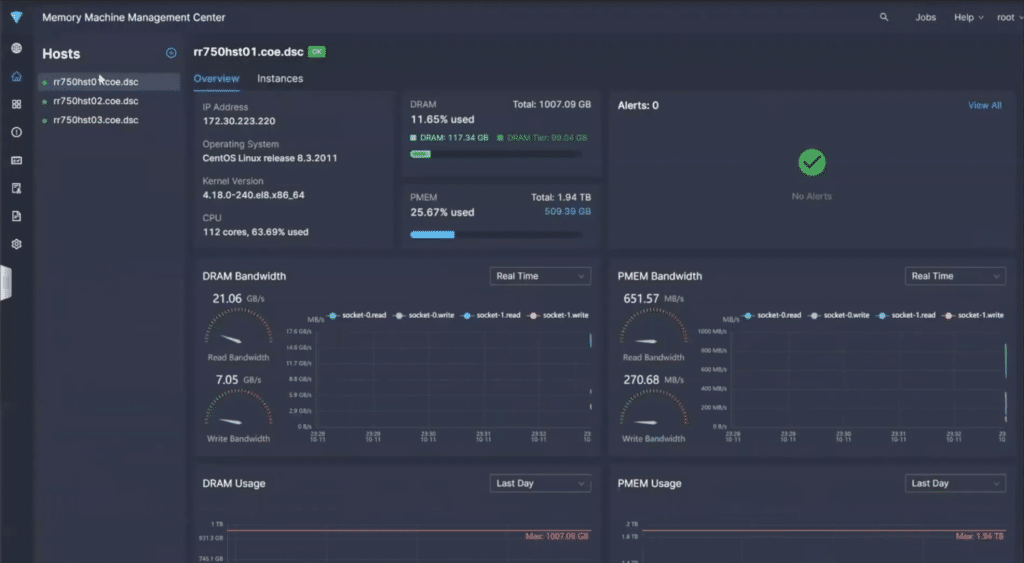
The memory monitoring, as well as the facilitating of the above services, is done through the MemVerge Memory Machine Management Center (M3C).
Although we’ve mentioned that Memory Machine is used with databases, it also supports a wide range of applications: from Autodesk’s Maya 3D for animation and rendering to TensorFlow (a machine learning framework) as well as other applications, including Hazelcast, a product we will be highlighting in this article.
Hazelcast
Hazelcast is a key innovator and leader in the growing field of in-memory computing platforms. Their platform is used by financial, e-commerce, and other types of organizations where real-time information is critical; for example, for fraud detection and to assist with making trading decisions.
Hazelcast supports fast applications on two levels. First, it offers an in-memory store that distributes data across multiple servers in a cluster to enable a scalable virtual pool of fast memory. The process of adding more data simply involves adding another server to the cluster. Second, Hazelcast includes a compute engine that handles application logic that is broken up into subtasks that are then distributed across all the CPUs in a cluster of servers. Not only does this leverage the collective computing power of the cluster, but it also allows the parallel processing of data in an efficient and high-speed manner (this includes transformation, enrichment, aggregation, and analysis). Since Hazelcast can process data immediately upon its creation via its streaming data capabilities, it is useful for building the next generation of real-time applications.
Analyzing Real-Time Data
Real-time systems are primarily driven by two main characteristics: speed and scale. Whereas speed ensures you can keep up with the data that is being created, scale guarantees that you can handle the volume of that data. To further complicate matters, data can come from many different sources. Of course, higher speeds and higher scale equates to a higher cost, unless innovative means are utilized, such as replacing expensive DRAM with more affordable Intel Optane PMem.
Real-time data analysis capabilities provide immediate insight into a variety of situations that businesses and organizations might face and give them the information that they need to respond to them. For example, compliance with initiatives like Basel III, where banks are required to maintain higher liquidity than before, means they have less money to leverage to generate revenue. At the same time, they must prove that their daily risks are understood so that they are not penalized by auditors and supervisors with even higher liquidity requirements. By having real-time systems for risk management and compliance, banks can have instantaneous views of their trading positions to more effectively understand and report their risk exposure.
To highlight another example, stock-trading analysis systems track trades and present them in an analyzable form in real-time. These systems can justify their high expense due to the clear return on investment (ROI) via the earned revenues from stock trading.
Testing Scenario
The application that we chose to use to investigate these technologies is based on a trade-monitoring code base created by Hazelcast to show how cost-effective “on-demand analytics” is a suitable alternative to high-cost, real-time systems.

As this was a small-scale research project, we made some trade-offs that made our testing environment not fully reflective of a typical production environment. For example, the compute power of the Dell EMC servers that we used was far more powerful than our available data source needed, so we did not take full advantage of the available CPU power in them. Also, for the sake of simplicity, we didn’t optimize the external data delivery system. In a production system, all the components would have been optimized and tuned to improve the performance and cost-effectiveness of this setup.

Testing Objectives
The most critical aspect of our testing was to ascertain if Intel Optane PMem could sustain a real-time feed of data.
We deflected testing the access speeds of the aggregated/indexed data in an in-memory data mart that was supported by Intel Optane PMem; in previous tests by MemVerge and Hazelcast, benchmarks have shown data access speeds have been very close to those of DRAM (in many cases, identical speeds for both reads and writes were demonstrated), and thus much faster than disk- or SSD-based data accesses. Since we knew the data access speeds provided an advantage over other architectural configurations, we focused our tests on the ingestion side only.
For our testing, we generated fictitious data on the data source server. Each data element in the incoming data feed represented a stock trade. The stock symbol, quantity, price, and time were the most critical values. Each stock symbol was used multiple times in the generated dataset to simulate multiple trades in a day for a given stock. Those separate trades were then aggregated to give a running total of trades for a given stock symbol.
The generated data was stored in Apache Kafka due to its ability to capture a fast stream of data. Each record from Kafka required 210 bytes, including all metadata in the payload. Kafka was configured to run three separate brokers, all on a single data source machine, and with four partitions on each broker. This configuration, of course, would not be used in a production environment as it is unrealistic to have a single-source machine for a distributed technology; however, it was suitable for the purposes of our testing.
Testing Environment
We used three Dell EMC PowerEdge R750 servers and one Dell EMC PowerEdge R74xd server for our testing; three ran the analytics applications using MemVerge Memory Machine and Hazelcast, while the fourth created and stored the test data.

Analytics Servers
| Model | Dell EMC PowerEdge R750 |
| CPUs | Dual Intel® Xeon® Gold 6330 processors @ 2GHz (Ice Lake)
28 cores each (56 total, 112 with Intel® Hyper-Threading technology) |
| DRAM | 16 DIMMs of 64GB DRAM DDR4
1 TB per server |
| Intel Optane PMem | 16 DIMMs of 128GB Intel Optane PMem DDR-T Interface
2 TB per server |
| Network Interface | 10 GbE |
| Software | MemVerge Memory Machine 1.2
Hazelcast Platform 5.0 |
Data Source Server
| Model | Dell EMC PowerEdge R740xd |
| CPUs | Dual Intel® Xeon® Gold 6140 processors @ 2.3GHz (Skylake)
18 cores each (36 total; 72 with Intel® Hyper-Threading technology) |
| DRAM | 12 DIMMs of 32GB DRAM DDR4 (384GB)
2 DIMMs of 16GB NVDIMM DDR4 (32GB) |
| Intel Optane PMem | Not needed |
| Network Interface | 10 GbE |
| Software | Apache Kafka 2.8
Data generation tool supplied by Hazelcast |
During our testing, we found that the amount of DRAM in the analytic servers could have been significantly smaller; while DRAM was mostly used by the operating system, the application primarily used Intel Optane PMem with only a small amount of DRAM. To optimize cost savings, an absolute minimum of DRAM on the server would be a reasonable configuration.
Test Results
We created approximately 5 billion records that were stored in Kafka to create the data source. The ingestion applications running on the three application servers were then started to ingest the data across the three Hazelcast instances (one Hazelcast server per Dell Technologies server).
We tested the application when only using DRAM and compared that to using Intel Optane PMem with MemVerge. The results of our testing showed that for workloads that were predominantly writes, we saw a 32% performance penalty of using only Intel Optane PMem versus pure DRAM (242K vs. 357K). But when using the Intel Optane PMem + DRAM configuration, we saw only a 9% penalty. This could have been further narrowed by having an increased number of servers in the cluster to spread out the writes even more. The extra cost of additional servers could be offset by procuring lower-powered CPUs since the given workload would not necessarily exploit the entire CPU power of this tested hardware configuration.
| Configuration | Performance (Records Per Second) |
| DRAM only | 357,000 |
| Intel Optane PMem assisted with 50GB DRAM + Memory Machine | 325,000 |
| Intel Optane PMem + Memory Machine only | 242,000 |
We considered pricing out each of the configurations we tested but declined to do so given potential fluctuations in cost and other factors that could make these estimates soon outdated. Regardless of the set costs, however, Intel Optane PMem assisted with DRAM will be significantly less than a DRAM-only-based server.
Test Interpretation
Our key takeaway from our testing was that a cluster of Intel Optane PMem-enabled servers could perform at nearly the same speed as a cluster that just used DRAM – but at a significantly lower cost.
Another important takeaway for us was that weeks or months of data could be captured and stored by using Intel Optane PMem, which provides businesses the ability to not only analyze data in real-time but also to have data available for high-speed analysis of historical data. This opens up opportunities for analyzing trends and patterns that might reveal additional insights using advanced analytics tools such as machine learning (ML).
In other words, businesses can deploy a real-time analytics environment covering a wide time range, and explore new forms of analytics, without the cost or speed trade-offs when deploying data warehouses or data lakes.
Other Testing
While we had the environment set up, we also wanted to test some of MemVerge Memory Machine’s other capabilities, in particular, its snapshot and recovery features. Fortunately, Memory Machine has integration with Hazelcast cluster so snapshots and snapshot recovery can be managed in M3C directly.
The snapshots can be taken any time on-demand or on a set schedule, and we tested both methods during our cluster’s peak operations. The snapshots were completed in seconds without any issues or affecting the performance of the analytics. If anything had happened to the Hazelcast cluster, such as a power outage, the data could have been recovered using one of our snapshots.
The snapshot function is not only useful for protection but it can also be used to increase the utilization rate of servers. In financial institutions, servers are heavily utilized during typical trading hours but are relatively idle during off-hours. By using a hot start scheme, the utilization rate of the servers can be dramatically improved. For example, at the end of the trading day, a snapshot of the trading database can be taken. Then when the trading database is shut down, the servers can be set to other data processing tasks such as data mining. At the beginning of a trading day, the trading database can be quickly restored, and trading operations can be resumed.
Conclusion
Intel Optane PMem is an exciting and transformative technology that is starting to reshape the datacenter, but as with all other technologies, it fortunately does not exist in a vacuum. Leading, forward-thinking companies such as Dell Technologies, Intel, MemVerge, and Hazelcast are finding synergies and starting to exploit this new technology to find its true potential in the datacenter: Intel Optane PMem modules are offered at around half the cost of DRAM; Dell Technologies has servers that support the massive amounts of low-latency memory capacity that Intel Optane PMem provides; Hazelcast allows applications to take advantage of these technologies on a grand scale; and MemVerge provides the monitoring, management, and data services for Intel Optane PMem, and, by abstracting away the DRAM API, it makes Intel Optane PMem appear as DRAM to existing applications thereby allowing them to run without being modified or re-architected.

If everything else is equal, businesses would opt for real-time activities versus batched activities. But since everything is not equal, batch processing is often the chosen pattern to avoid the costs associated with real-time processing. However, as customer expectations continue to rise in a world that is increasingly more real-time-oriented, businesses need to find new ways to create a competitive advantage. By leveraging real-time speeds without suffering the traditional costs of in-memory computing, leading businesses can make the leap with technologies like Intel Optane PMem, MemVerge, and Hazelcast to build solutions that help them respond to their demands, and that of their customers, faster than ever before.
This report is sponsored by MemVerge. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration. Intel, the Intel logo, and Intel Optane are trademarks of Intel Corporation or its subsidiaries.


 Amazon
Amazon