

We’re no strangers to pushing the boundaries of computation, but this one takes the Pi(e). Hot on the heels of last year’s 100 trillion-digit benchmark, we decided to ratchet it up and push the known digits of Pi to 105 trillion digits. That’s 105,000,000,000,000 numbers after the 3. We made a few updates to the platform from last year’s run, found a few surprising things along the ride, and learned some things along the way—including the 105 Trillionth Digit of Pi;6!

Achieving a world-record-breaking calculation of Pi to 105 trillion digits, the StorageReview lab has underscored the incredible capabilities of modern hardware. This endeavor, powered by a cutting-edge 2P 128-core AMD EPYC Bergamo system equipped with 1.5TB of DRAM and nearly a petabyte of Solidigm QLC SSDs, represents a landmark achievement in computational and storage technology.
The Challenge
In the 100 trillion digital run, we encountered several technological limitations. The server platform, for example, only supported 16 NVMe SSDs in the front slots. While we had plenty of CPU power, this computation required massive storage during the process and on the back end when the final TXT file was output.
To solve the storage problem last time, we resorted to PCIe NVME adaptor sleds to squeeze in another three SSDs. Then, for the output, we had an HDD storage server in RAID0, mind you, with an iSCSI share back to the computation box. This time, we wanted to be a little more “enterprise” with this server, so we brought in a few friends to help. Interestingly, it’s not as easy as it may appear to add a bunch of NVMe SSDs to a server.
The Hardware
The heart of this monumental task was the dual-processor AMD EPYC 9754 Bergamo system, offering 128 cores each. AMD’s processors, known for their exceptional performance in high-complexity computational tasks (AI, HPC, Big Data Analytics), provided the necessary horsepower. Complementing this was 1.5TB of DRAM, ensuring swift data processing and transfer speeds. At the same time, nearly a petabyte of Solidigm QLC storage offered unprecedented capacity and reliability.

Our base chassis platform remained the same from last year (a QCT box), but we upgraded the CPUs to AMD EPYC 9754 Bergamo chips. We wanted to go after a speed and decimal improvement while avoiding using storage for the computation, which meant we had to call on SerialCables to provide a JBOF. This presented some challenges in its own right, which we’ll detail below.
| Parameter | Value |
|---|---|
| Start Date | Tue Dec 19 14:10:48 2023 |
| End Date | Tue Feb 27 09:53:16 2024 |
| Total Computation Time | 5,363,970.541 seconds / 62.08 Days |
| Start-to-End Wall Time | 6,032,547.913 seconds / 69.82 Days |
Computation Period: December 14, 2023 – February 27, 2024, spanning 75 days.
- CPU: Dual AMD Epyc 9754 Bergamo processors, 256 cores with simultaneous multithreading (SMT) disabled in BIOS.
- Memory: 1.5 TB of DDR5 RAM.
- Storage: 36x 30.72TB Solidigm D5-P5316 SSDs.
- 24x 30.72TB Solidigm D5-P5316 SSDs in a SerialCables JBOF
- 12x 30.72TB Solidigm D5-P5316 SSDs in the Server Direct Attached.
- Operating System: Windows Server 2022 (21H2).
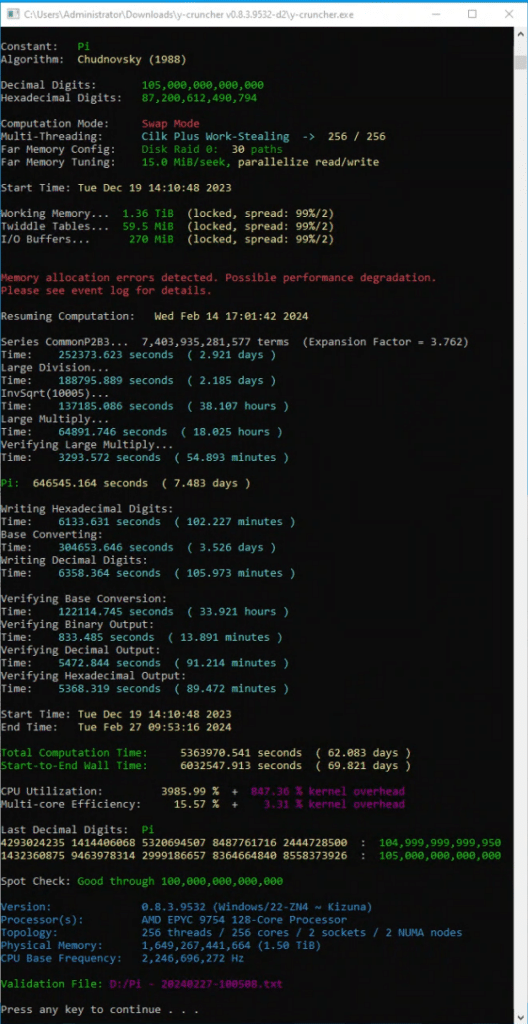
The Path to 105 Trillion
| Parameter | Value |
|---|---|
| Constant | Pi |
| Algorithm | Chudnovsky (1988) |
| Decimal Digits | 105,000,000,000,000 |
| Hexadecimal Digits | 87,200,612,490,794 |
| Threading Mode | Cilk Plus Work-Stealing -> 256 / 256 |
| Working Memory | 1,492,670,259,968 (1.36 TiB) |
| Total Memory | 1,492,984,298,368 (1.36 TiB) |
| Logical Largest Checkpoint | 157,783,654,587,576 (144 TiB) |
| Logical Peak Disk Usage | 534,615,969,510,896 (486 TiB) |
| Logical Disk Bytes Read | 44,823,456,487,834,568 (39.8 PiB) |
| Logical Disk Bytes Written | 38,717,269,572,788,080 (34.4 PiB) |
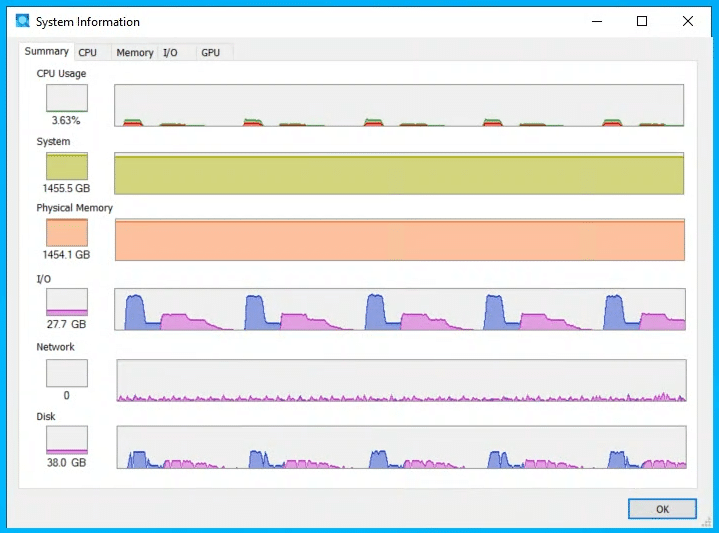
Encountered Challenges
A new component to this run, which was needed to expand the available storage to the processors, was adding an NVMe JBOF. Our test platform offered 16 NVMe bays, with the remaining eight only wired for SATA. While our 100 trillion run leveraged three internal PCIe U.2 adapters to expand our NVMe drive count to 19, it wasn’t optimal. For this re-run, we added a Serial Cables 24-bay U.2 JBOF, which helped significantly in two ways: more compute swap storage and internal output file storage. No more crazy RAID0 HDD storage server!

The Serial Cables 24-bay JBOF allowed us to nearly double the drive count from our original run. We allocated 30 drives to the y-cruncher swap space, leaving 6 SSDs for a Storage Spaces RAID5 output volume. A huge advantage of that approach came during the output stage, where we weren’t held back by the speed of a single 10Gb connection, like the first 100T Pi iteration. While the JBOF addressed the total drive count problem, it did introduce one limitation: individual drive performance.
In a server with direct-attached U.2 SSDs, there are four PCIe lanes per drive. If each drive is directly wired to the motherboard, that works out to 96 PCIe lanes for 24 SSDs. The JBOF’s total bandwidth is limited by the number of PCIe lanes it can connect back to the host.
In this case, we used two PCIe switch host cards, splitting the JBOF into two groups of 12 SSDs. Each group of 12 SSDs then shared 16 PCIe lanes. While still offering considerable advantages in connecting the SSDs to our host, we did have scenarios where swap drives running through the JBOF fell behind drives directly attached to the server. This isn’t a fault of the JBOF. It’s just a technical limitation or rather a limitation of how many PCIe lanes the server can work with.
Astute readers might wonder why we stopped at 36 SSDs in this run instead of going up to 40. It’s a funny story. Addressable PCIe space has its limits in many servers. In our case, at the 38 drive count, the last SSD took the PCIe address of the USB chipset, and we lost control of the server. To play it safe, we backed it down to 36 SSDs so we could still go into the BIOS or log into the server. Pushing boundaries does lead to some surprising discoveries.
Diagnostic Insight and Resolution
The first of the two main challenges we encountered was performance-related. What we discovered was Amdahl’s Law in action. A peculiar issue emerged when y-cruncher would appear to “hang” on our 256-core AMD Bergamo system during large swap mode operations. This hang, characterized by a lack of CPU and disk I/O activity, challenged conventional expectations of software behavior. This led to a deep dive into the intricacies of parallel computing and hardware interactions.
The discovery process revealed that the program was not truly hanging but operating in a severely limited capacity, running single-threaded across an expansive 256-core setup. This unusual behavior sparked questions about the potential impact of Amdahl’s Law, especially since the operations involved were not compute-intensive and should not have caused significant delays on a system equipped with 1.5 TB of RAM.
The investigation took an unexpected turn when the issue was replicated on a consumer desktop, highlighting the severe implications of Amdahl’s Law even on less extensive systems. This led to a deeper examination of the underlying causes, which uncovered a CPU hazard specific to the Zen4 architecture involving super-alignment and its effects on memory access patterns.

The issue was exacerbated on AMD processors by a loop in the code that, due to its simple nature, should have executed much faster than observed. The root cause appeared to be inefficient handling of memory aliasing by AMD’s load-store unit. The resolution of this complex issue required both mitigating the super-alignment hazard through vectorization of the loop using AVX512 and addressing the slowdown caused by Amdahl’s Law with enhanced parallelism. This comprehensive approach not only solved the immediate problem but also led to significant optimizations in y-cruncher’s computational processes, setting a precedent for tackling similar challenges in high-performance computing environments.
The next issue was encountered in the final steps of the calculation, which would halt unexpectedly and provide no information about the cause of the crash. Remote access was granted to Alexander Yee, and for the first time in over a decade, completing a Pi record required direct intervention from the developer.
We did not get involved with this diagnostic process, but there was a critical floating-point arithmetic error within the AVX512 code path of the N63 multiply algorithm. Alexander was able to remotely diagnose, provide a fixed binary, and resume from a checkpoint, culminating in a successful computation after implementing crucial software fixes.
Reflections and Moving Forward
This endeavor illustrates the complexities and unpredictabilities of high-performance computing. Resolving these challenges set a new Pi computation record and provided valuable insights into software development and testing methodologies. The latest y-cruncher release, v0.8.4, incorporates fixes for the identified issues, promising enhanced stability for future computations.
Calculating Pi to 105 trillion digits was no small feat. It involved meticulous planning, optimization, and execution. Leveraging a combination of open-source and proprietary software, the team at StorageReview optimized the algorithmic process to fully exploit the hardware’s capabilities, reducing computational time and enhancing efficiency.
With PCIe Gen4 saturating read performance and industry-leading capacities up to 61.44TBs, Solidigm QLC SSDs deliver unbelievable results. “Imagine what these drives can enable in high-performance compute or AI-intensive applications,” said Greg Matson, VP of Strategic Planning and Marketing at Solidigm. We’re thrilled that Solidigm’s SSDs could power Storagereview’s second record-breaking attempt to calculate pi. Their efforts prove the true capabilities of Solidigm’s storage drives, opening a world of possibilities for data-intensive AI applications.”
Conclusion
The run to 105 trillion digits of Pi was much more complex than we expected. Upon reflection, we should have expected to encounter new issues; after all, we’re completing a computation that had never been done before. But with the 100 trillion computation completed with a much more “duct tape and chicken wire” configuration, we thought we had it made. Ultimately, it took a collaborative effort to get this rig across the finish line.
While we rejoice with our partners in this record-breaking run, we must ask, “What does this even mean?” Five more trillion digits of Pi probably won’t make a huge difference to mathematics. Still, we can draw some lines between computational workloads and the need for modern underlying hardware to support them. Fundamentally, this exercise reflects that the proper hardware makes all the difference, whether an enterprise data center cluster or a large HPC installment.
For the Pi computation, we were completely restricted by storage. Faster CPUs will help accelerate the math, but the limiting factor to many new world records is the amount of local storage in the box. For this run, we’re again leveraging the Solidigm D5-P5316 30.72TB SSDs to help us get a little over 1.1PB of raw flash in the system. These SSDs are the only reason we could break through the prior records and hit 105 trillion Pi digits.
This does raise an interesting question, though. Many of our followers know that Solidigm has 61.44TB SSDs in its D5-P5336 and up to 30.72 TB in the D5-P5430 SSDs, available in multiple form factors and capacities. We’ve reviewed the drives and have many social media posts showcasing these amazingly dense drives. With 32 of these SSDs approaching 2PB of storage, one might wonder just how long that 105 trillion digits of Pi will stand as the world’s largest. We’d like to think, not very long.
Largest Known Decimal Digits of Pi
1432360875 9463978314 2999186657 8364664840 8558373926: Digits to 105,000,000,000,000


 Amazon
Amazon