

Pi represents the ratio of a circle’s circumference to its diameter, and it has an infinite number of decimal digits that never repeat or end. Calculating infinite Pi isn’t just a thrilling quest for mathematicians; it’s also a way to put computing power and storage capacity through the ultimate endurance test. Up to now, Google’s Cloud has held the world record for the largest Pi solve at 100 trillion digits. As of today, StorageReview has matched their number and done so in a fraction of the time.

Pi In The Sky, Above The Cloud(s)
Last year, Google Cloud Developer Advocate Emma Haruka Iwao announced that she and her team had calculated Pi to 100 trillion digits, breaking her previous record of 31.4 trillion digits from 2019. They used a program called y-cruncher running on Google Cloud’s Compute Engine, which took about 158 days to complete and processed around 82 petabytes of data. In the end, that run also would have had a massive cloud compute and storage invoice, combined with the mounting momentum for organizations to bring specific workloads back on-prem, which gave us an interesting idea…

We were impressed by the achievement of Emma and the Google Cloud, but we also wondered if we could do it faster, with a lower total cost. At StorageReview.com, we have access to some of the latest and greatest hardware in the industry, including AMD EPYC 4th gen processors, Solidigm P5316 SSDs, and obscene amounts of lithium batteries. Like a match made in heaven, we built out a high-performance server with just under 600TB of QLC flash and a unique high-availability power solution.

Here are the specifications of our compute system:
- 2 x AMD EPYC 9654 (96 cores, 2.4 GHz, 3.7 GHz boost)
- 24 x 64GB DDR5-4800 DIMMs, 1.5TB total
- 19 x Solidigm 30.72TB QLC P5316 SSDs
- Windows Server 2022 Standard 21H2
- Program: y-cruncher by Alexander Yee
While the total hardware might seem extreme, the cost to buy our hardware outright is still a fraction of running the same workload in the cloud for six months.
Data Center: Designed By Madmen
One of the first questions that came up when we were designing our rig for this test was, “How are we going to present a contiguous volume large enough to store a text file with 100 Trillion digits of Pi?”(This is definitely a direct quote that we totally said). The math is quite simple, 1 Pi digit = 1 byte, and having 100 Trillion decimal digits meant we needed 100TB for that and an additional 83TB for the 83 Trillion Hexadecimal that would also be calculated. Thankfully this is StorageReview, and if there is one thing we know how to do, it’s store lots of data with excessive amounts of stress.
Unfortunately, even Kevin does not have a 183TB Flash drive on his janitor-sized key ring of flash drives (yet). So after looking and testing various methods around the lab and exploring multiple ways to map an NAS or a file share, we noticed through testing that y-cruncher likes to have Direct IO control of the disks it is working with; not just the swap disks, but also the file output directory. Giving y-cruncher a volume that it can send SCSI commands to was our only option, as it yields optimal performance.
So the only logical thing to do next was to use an iSCSI target to a Supermicro storage server to store the output files, which were too large to fit on any single volume on the local compute host. This platform was more traditional in the sense of high-capacity storage, hosting “just” 200TB across four 50TB LUNs which we striped on our compute platform.
While RAID 0 might raise some eyebrows, in our defense, the file server storage was carved out of a mirrored Windows Storage Spaces pool, so redundancy was available on the remote host. It was then multi-pathed across a dual-port 10G interface, directly attached, and hardwired between both servers. Removing a switch from this equation was on purpose, as this Pi platform was designed to operate entirely separately in case the main lab was to go offline.
While power protection isn’t always a massive concern in the StorageReview lab, a project of this magnitude (spanning months), demanded extreme measures to ensure uptime. We leveraged three EcoFlow Delta Pro portable power stations, each with a 3600W output capacity and 3600Wh battery.
The AMD Genoa server leveraged two, with one Eaton 5PX uninterruptible power supply inline between one Delta Pro, to alleviate the switch-over delay from the EcoFlow during an outage. The fileserver had one Delta Pro dedicated to it, with one Eaton 5PX G2 for transfer delays.

In short, we created a UPS on steroids, combining the benefits of high-capacity portable power stations with the reliability of modern data center-grade battery backup gear. At peak compute load, we had a runtime spanning 4-8 hours on battery. We had numerous storms throughout the 100T Pi run, but we could sleep easily, knowing the Pi run would stay operational.
Meat, Potatoes, and Pi. Lots and Lots of Pi…
We started the calculation on Thu Feb 9 17:40:47 2023 EST, and it finished on Mon Apr 10 05:27:37 2023 EST. The elapsed Pi calculation time was 54 days, 17 hours, 35 minutes, and 48.96 seconds, with the total wall-to-wall time, including writing and validation, being 59 days, 10 hours, 46 minutes, and 49.55 seconds.
The total storage size was 530.1TB available, not including the 200TB iSCSI target for the write-out. Here are some highlights of counters from the y-cruncher validation file, available for download and verification.
The Numbers
Start Date: Thu Feb 9 17:40:47 2023
Working model:
- Constant: Pi
- Algorithm: Chudnovsky (1988)
- Decimal Digits: 100,000,000,000,000
- Hexadecimal Digits: 83,048,202,372,185
- Working Memory: 1,512,978,804,672 (1.38 TiB)
- Total Memory: 1,514,478,305,280 (1.38 TiB)
Logical Disk Counters:
- Logical Largest Checkpoint: 150,215,548,774,568 ( 137 TiB)
- Logical Peak Disk Usage: 514,540,112,731,728 ( 468 TiB)
- Logical Disk Total Bytes Read: 40,187,439,132,182,512 (35.7 PiB)
- Logical Disk Total Bytes Written: 35,439,733,386,707,040 (31.5 PiB)
Numbers Don’t Lie:
- Total Computation Time: 4728948.966 seconds
- Start-to-End Wall Time: 5136409.559 seconds
- Last Decimal Digits:
- 4658718895 1242883556 4671544483 9873493812 1206904813: 99,999,999,999,950
- 2656719174 5255431487 2142102057 7077336434 3095295560: 100,000,000,000,000
End Date: Mon Apr 10 05:27:37 2023
The ten digits of Pi leading up to 100 Trillion are 3095295560.
We calculated Pi to 100 trillion digits in about one-third the time, thanks in part to all local swap storage space compared to Google’s method. This shows the incredible performance, density, and efficiency of locally attached Solidigm P5316 QLC SSDs and, of course, AMD EPYC 4th gen processors.
Local storage was integral to this speed run. While Google’s run could tap into near-unlimited amounts of storage, it was limited to a 100Gb network interface. It’s odd to say 100Gb is slow, but at the scale of our test, it becomes a huge bottleneck. During our swap write bursts, we measured accumulative transfer speeds to the Solidigm P5316 QLC SSDs upwards of 38GB/s.
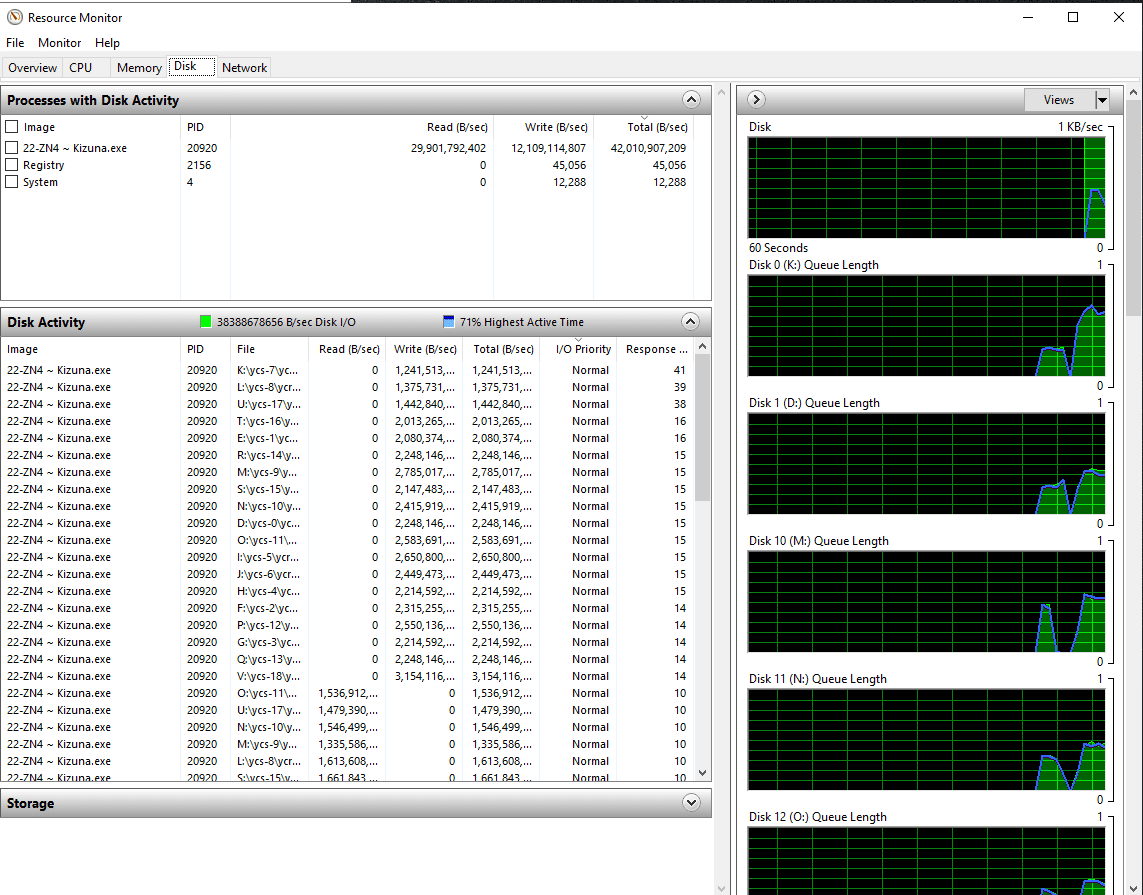
Read speeds were even higher. In network terms, you’d need multiple 400Gb links (redundancy) to flow that amount of data. While not impossible, many cloud environments just aren’t built for that level of bandwidth. Oracle’s bare metal Dense I/O instances probably come the closest to this scale of raw speed, but those are limited to eight NVMe SSDs and 54.4TB of capacity combined.
Solidigm QLC Flash for Performance, Endurance, and Density
To facilitate such a significant calculation, we needed space, and lots of it, as fast as we could find it. Swap mode is a feature in y-cruncher that allows computations to be performed using disk, which is required for performing large computations that cannot fit in main memory. Using multiple drives in parallel is necessary for better performance, and to further improve performance, Solid State Drives (SSDs) can be used. However, it has not been recommended in the past because the theoretical analysis of their write-wear is not encouraging.
The use of y-cruncher’s swap mode, instead of relying on the OS pagefile, is essential because the memory access patterns in y-cruncher are not directly disk-friendly. Thankfully, y-cruncher’s swap mode is designed to overcome this limitation by minimizing disk seeks and using sequential disk accesses. y-crunchers Swap mode was used in a RAID 0 configuration with 19 drives, which gave the application direct IO access to the NVMe disks for optimal performance.
The Solidigm P5316 SSDs we used in our test utilize a PCIe Gen4 interface and are equipped with 144-layer QLC NAND flash memory. They offer exceptional performance, with up to 7 GB/s of sequential read speed and up to 3.6 GB/s of sequential write speed.
QLC solid-state drives are recognized for their capability to lower expenses without compromising storage capacity and efficient performance. This makes QLC SSD technology beneficial for many business situations. For instance, VAST Data incorporates these drives in their products to eliminate the necessity of hard disk drives. At the same time, Pliops employs an accelerator card with QLC drives for a rapid and cost-efficient resolution.
We have had these drives in our lab since late 2021 and have put them through many tests, but this was one of the most intensive and extensive tests to date. Of the 19 drives we used, all were at 99-100% health at the start of the calculation.
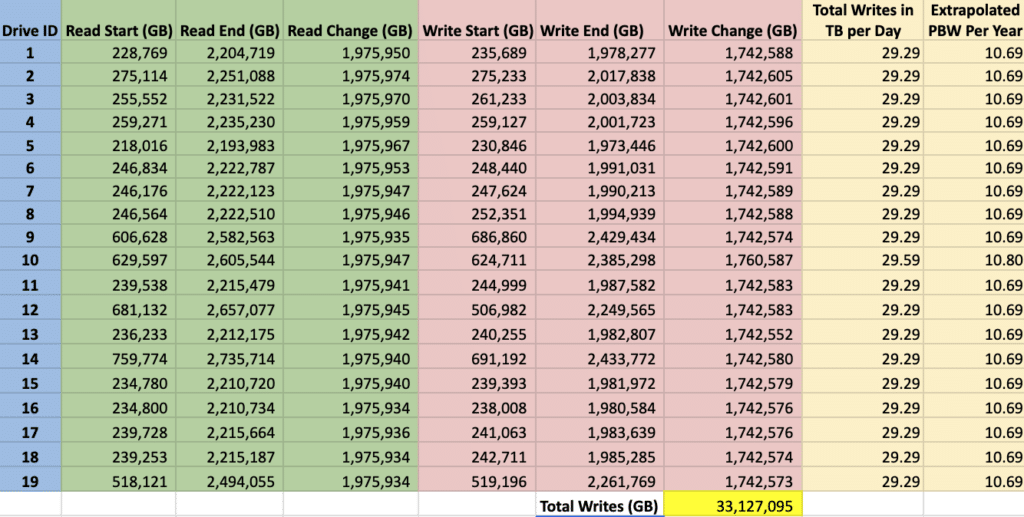
Over the 54.5 days this computation ran, we had a total of 33,127,095 GB of write to the drives, or about 1,742,500 GB per drive. Converting this to a daily overage over our run, that’s a little more than 29TB per drive per day.
Extrapolating for a simulated longer-term workload is about 10.69PB per year of data writes per drive. Solidigm lists the endurance of the P5316 at 22.9PBW for random workloads and 104.6PBW for sequential workloads. With the Pi workload staying in burst for its duration without heavily stressing the flash, it acted very sequentially, putting the workload toward the higher end of Solidigm’s endurance spectrum.
This means you could subject these to a similar workload for nearly a decade before you would run out of life. Impressive to say the least, considering this is QLC NAND and the drive warranty is five years. Anyone concerned about wearing out these drives can use this use case as another validation point that QLC is enterprise ready.
At the end of the 59.5-day run, health status was reported as 97-98% across all the drives in the server. We had barely made a dent in the endurance of these drives.
Epic AMD EPYC CPUs
AMD EPYC 4th gen processors are based on the Zen 4 microarchitecture and the 5nm process, making them the industry’s first 5nm x86 data center processors. They support up to 12 channels of DDR5 memory, AVX-512 VNNI, and BFloat16 instructions for enhanced performance in AI and ML applications. They offer up to 30% more performance per core than Intel’s Ice Lake processors and up to twice as much performance as AMD’s previous generation EPYC Milan processors.

Tuning was a big part of this run, as we had extensively tested and iterated through smaller, previously held records of Pi calculations, like 1 billion and 10 billion. Through some tuning with the BIOS and using the 10 Billion run time as a metric, we were able to eke out significant performance improvements for this workload. This gave us a significant advantage over utilizing cloud resources since we had granular control over the platform to optimize it for our application, which is not an option with off-the-shelf cloud instances.
We started by disabling SMT in the BIOS and picked up a few % improvements on the smaller tests’ run time. The next option that we explored was C-States. We noticed that when running y-cruncher, the CPU tended to jump in and out of lower power c-states quite often as it would step through different processes.
The tuning of the BIOS settings, including the disabling of SMT and controlling C-states, combined with some performance tweaks to the operating system, was a crucial factor in improving performance for this workload. A big shout out to Alexander Yee from y-Cruncher, and a friend from the overclocking scene, Forks, for helping to point out some tweaks and settings in both Windows and y-Cruncher to help make this run come together.
Pi; 100T Speed Run, 100%. Now what?
Well, folks, as we wrap up this Pi-lgrimage, let’s take a moment to bask in the glory of computing a whopping 100 trillion digits of Pi in just 54 bite-sized days! Thanks to the y-cruncher program, the Herculean strength of AMD EPYC 4th gen processors, and the lightning-fast Solidigm P5316 QLC SSDs, we’ve witnessed an achievement that’ll make your calculator blush.
Pushing the boundaries of raw computer might and oceanic-sized data storage, our trusty team of locally attached QLC flash storage units truly had their time to shine. Solidigm P5316 SSDs, with their exceptional endurance and performance, are like the superhero sidekicks of the business world. And let’s not forget our portable power stations and beefy battery backup gear, ensuring our Pi-rade kept rolling—even when Mother Nature tried to rain on our perfectly baked celebration.
So, as we say adieu to this record-breaking Pi extravaganza, let’s raise a slice to the endless possibilities in the worlds of mathematics and computer science that lie ahead. Cheers!


 Amazon
Amazon