

Comino recently sent us the latest version of the Comino Grando for review, configured with eight NVIDIA RTX PRO 6000 Blackwell cards, each with 96GB of VRAM, for a total of 768GB of GPU memory. We reviewed the Comino back in in 2024, configured with 6x RTX 4090s, offering 144GB of total GPU memory, as well as a version with NVIDIA H100’s. This latest update marks a substantial generational leap in both raw memory capacity and the range of workloads the platform can address.

The Grando is a purpose-built 4U platform designed to resolve the critical conflict between high-density GPU compute and thermal management. While standard air-cooled chassis crumble under the sustained 600W+ TDP demands of modern professional cards, the Grando takes a fundamentally different approach, built from the ground up around a liquid-cooled architecture capable of dissipating a massive 6.5kW of continuous heat. This is not a retrofit or an afterthought; the entire chassis, from its inverted motherboard layout to its color-coded quick-disconnect manifold system, has been engineered around the cooling loop.
The result is a platform that can sustain eight full-TDP professional GPUs in a single 4U chassis, running 24/7 in ambient environments of 3-38°C, without thermal throttling, without the acoustic assault of high-RPM air cooling, and without compromising serviceability. For organizations deploying AI inference, machine learning training, or high-performance simulation workloads at scale, the Grando offers something genuinely rare: a server that does not ask you to choose between density, thermals, and reliability.
Comino Grando Specifications
The table below shows the physical specifications and supported hardware configurations for the Comino Grando platform.
| Specification / Feature | Comino Grando |
|---|---|
| Comino Grando Server & Rackable Workstation | |
| Cooling Capacity | 6.5kW (Maximum 6 500 W @ 20°C intake air T) |
| Motherboards | Up to EATX & EBB |
| GPUs (Server) | Up to 8; NVIDIA: RTX A6000, RTX 6000 ADA, RTX PRO 6000, A40, L40, L40S, A100, H100, H200 |
| GPUs (Rackable Workstation) | Up to 6; NVIDIA: 3090, 4090, 5080, 5090, RTX A6000, RTX 6000 ADA, RTX PRO 6000, A40, L40, L40S, A100, H100, H200; AMD: W7800, W7900 |
| CPUs | Up to 2; Single Socket: Intel Xeon W-2400/2500 & 3400/3500, Intel Xeon Scalable 4th Gen, 5th Gen, XEON 6, AMD Threadripper PRO 5000WX, 7000WX, 9000WX, AMD EPYC 9004/9005 Dual Socket: Intel Xeon Scalable 4th Gen, & 5th Gen, XEON 6, AMD EPYC 9004/9005 |
| RAM | Up to 2TB |
| M2 drives | Up to 8x NVME |
| Storage | Back panel hot swap cages: up to 4x hot swap SSDs (4x 7mm or 2x 15mm) and up to 4 more (4x 7mm or 2x 15mm) instead of 4th PSU; Internal 3.5″ cage up to 4x 3.5″ or 4x 2.5″ 15mm or 12x 2.5″ 7mm; Internal 2.5″ slots: up to 4x 2.5″ SSD 7mm |
| Power Supply & Operating Voltage | Up to 4x 2000W Hot Swap CRPS @ 180-264V Up to 4x 1000W Hot Swap CRPS @ 90-140V Redundancy modes: 4+0, 3+1, 2+2 |
| Noise level | 39dB-70dB |
| Lan | Up to 2x 10 Gbit/s on the MoBo and up to 400Gbit/s in PCIe |
| OS | Ubuntu / Windows 11 (Pro/Home) / Windows Server |
| Physical & Cooling Specifications | |
| Liquid cooling | CPU with VRM and GPU with GDDR and VRM |
| Reservoir | Comino custom 450ml with integrated pumps |
| Fans | 3x Ultra High Flow 6200RPM (high noise level) or 3x High Flow 3000RPM (low noise level) |
| Installation | 19″ rack-mountable or standalone as a Workstation |
| Required rack space | 4U |
| Size | 439 x 681 x 177mm (without handles and protruding parts) |
| Weight | 4 GPUs: 49kg (net), 67kg (gross) 6 GPUs: 52kg (net), 70kg (gross) 8 GPUs: 55kg (net), 72kg (gross) |
| Operating & storage temperature range | Storage: -5..50°C / 23..122°F Operating: 3..38°C / 38..100°F |
| Comino Monitoring System (CMS) | |
| Overview | Controller Board with Sensors & Software for Real-Time Monitoring |
| Key Advantages | Cooling System & CPU/GPU Monitoring, Web Interface, Cooling System Log, Centralized Monitoring for Workgroups |
| Sensors & Connected Devices | Temperature (air and coolant), % Humidity, Voltage, Coolant flow, Reservoir coolant level, Fans, Pumps, Motherboard, Display, and buttons |
| Integration Possibilities | Establish monitoring via a REST API and push sensor data to monitoring software (e.g., Zabbix, Grafana) or databases (e.g., InfluxDB). |
| CMS Technical Requirements | |
| OS | Windows 11/10 Ubuntu 22.04/20.4 (Dependency for Ubuntu: the target system must have nvidia-smi and sensors utilities installed) |
| Web Browsers | Mozilla Firefox, Google Chrome, Chromium, Apple Safari, Microsoft Edge (Attention: Internet Explorer 11 is not supported) |
| Hard disk drive | 300MB |
| Controller firmware version | 1.0.6 or newer |
| Controller PCB version | 2.xx.xx |
Design, Build, and GPU Density
Chassis Layout and Deployment
The Grando Server is a masterclass in space optimization, measuring 17.3 x 26.8 x 6.97 inches (4U). Unlike traditional servers, it places the motherboard’s rear at the front of the chassis, inverting the conventional internal layout. This ensures that air-cooled components, such as RAM modules and VRMs, receive the coldest possible intake air before it reaches the liquid-cooling radiator at the rear.
The chassis itself is built to the same exacting standard, featuring solid steel construction with a matte black powder-coat finish applied inside and out. This deliberate choice extends to the tubing, cables, radiator, and PCB solder mask, reflecting a clear intention for a clean, professional aesthetic throughout. Furthermore, the system supports versatile deployment, functioning seamlessly as either a 19-inch rack-mountable unit or a standalone desktop unit. Depending on the configuration, it weighs between 148 and 159 lbs.

GPU Cold Plates and Water Blocks
The proprietary copper water blocks form the core of the Grando’s density, cooling not only the GPU die but also the other components like memory and voltage regulators. Each GPU ships as an off-the-shelf card, on which Comino mounts a custom cold-plate assembly. In practice, this thin-profile design reduces each card to a single-slot footprint, allowing six or even eight professional GPUs to sit side by side within a single 4U chassis. Our review unit shipped with eight NVIDIA RTX PRO 6000 Blackwell cards, each with a TDP of 600W, resulting in a total cooling requirement of 4,800W under full load.

Achieving the Comino’s 8 single slot GPU density would be nearly impossible with air cooling, since stock NVIDIA RTX PRO 6000 cards each occupy two slots and require substantial airflow. In contrast, these custom-cooled cards occupy just one slot each. The cold plates are built solidly, adding noticeable weight to each card, but that weight reflects the quality and cooling performance required at this level.
Each pair of GPUs is plumbed through a dedicated sub-manifold that consolidates both cards into a single inlet and outlet connection to the main coolant manifold. This paired approach simplifies the overall loop architecture, reduces the number of connections at the main manifold, and allows a technician to disconnect a single pair of quick-disconnect couplings to remove two cards at once, further streamlining maintenance.

Water Distribution and Manifold
At the center of the system sits a large water distribution manifold that supplies cool liquid to each GPU and CPU cold plate and provides the return path to the radiator. All connections between the manifold and the GPU’s and CPU use Comino’s “TheQ” Quick Disconnect Couplings. These stainless steel dripless fittings are color-coded with red and blue rings to clearly identify the hot and cold sides of the loop, removing any ambiguity during installation or servicing.

They leave minimal residue on the mating surface when disconnected, allowing technicians to remove or replace individual GPUs or the CPU without draining the 450ml reservoir or the rest of the loop. In this way, the Grando brings the maintenance simplicity of air-cooled systems to a high-performance liquid-cooled platform.
CPU Cooling and Memory
The CPU and its voltage regulators also benefit from a dedicated cold plate connected directly to the coolant loop, preventing the processor from becoming a bottleneck during intense multi-GPU workloads. Our review unit shipped with an AMD Turin/Genoa board featuring a single AMD EPYC 9474F 48-core processor. The cold plate mirrors the quality of the card cold-plates, machined from solid copper and secured with stainless-steel hardware.

Flanking the CPU on both sides are eight fully populated DRAM slots that support configurations up to 2TB of RAM. Our review unit came equipped with 512GB of DDR5 RAM. A support bar spans above the GPU and CPU area of the chassis, perpendicular to them, securing sensitive components like the GPU’s and maintaining chassis rigidity during transport.
Radiator and Fans
Cooling is handled by a large triple 140mm radiator mounted at the rear of the chassis, paired with three high-speed 140mm fans capable of reaching 6,200 RPM and moving up to 1,000 m³/h of airflow. The dense fin stack provided by the thick radiator underscore the thermal headroom designed into the platform, which is built to dissipate up to 6.5kW of sustained heat in our configuration.
What is perhaps most surprising is that despite that workload and those fan speeds, the unit manages to stay within a tolerable noise envelope, with sound levels sitting 70+ dB at full tilt. That is loud by workstation standards but notably restrained for a system dissipating the thermal output of a small electric furnace, which speaks to how effectively the Comino’s liquid loop transfers heat away from the components.

Front Panel and Telemetry Display
On the front panel, an LED display provides a live readout of key telemetry data, including pump status, ambient air temperature, coolant temperature, and fan speed. Users navigate the menu using illuminated buttons on the cooling module, with short presses to scroll through available data. A long press on the PB2 button opens additional menu branches, including Commands, Service settings, and an Event Log. In addition, the front I/O panel includes a VGA port for display output, alongside a serial port, multiple USB ports, and network connections for peripheral and device connectivity.

Power and Storage Architecture
Power Delivery and Redundancy
Supporting this level of compute requires equally robust power delivery. The Grando supports up to four hot-swap 1000W or 2000W CRPS modules in a redundant configuration, delivering up to 8.0kW at 180–264V. With support for 4+0, 3+1, and 2+2 redundancy modes, the system can tolerate PSU failures while maintaining continuous operation for 24/7 AI and HPC workloads.

Our review unit shipped with four Great Wall 2000W 80 Plus Platinum hot-swap power supplies, forming the full 8.0kW configuration.

Power delivery to each GPU runs through a centralized 12-pin power distribution board mounted between the GPU array and the main cable run. The Grando uses this distribution board to consolidate incoming power feeds and then branch them to each GPU in an organized, space-efficient manner.

PCIe, Storage, and Networking
The Grando comfortably supports six GPUs without compromising slot bandwidth, and the chassis scales to a full eight-card configuration for maximum density. The Comino’s ASRock Rack GENOAD8X-2T/BCM motherboard provides seven x16 and one x8 PCIe Gen 5 slots, meaning seven of the eight GPUs run at full x16 bandwidth with the eighth card operating at x8. This is a trade-off between the number of PCIe lanes a single-socket CPU can support and Comino’s reluctance to add the size, cost, and complexity of a PCIe switch plate. Moving to a dual-socket motherboard would provide more PCIe lanes but offer even fewer slots, since the 2nd socket would occupy space otherwise used by PCIe slots in the space-constrained form factor.

Running eight GPUs in a single-socket system consumes the lion’s share of available PCIe lanes, and that comes with trade-offs. Our review unit, based on AMD Genoa, has 128 PCIe Gen 5 lanes available in total. With eight GPUs consuming 120 of those lanes, the remaining 8 lanes are split x4 to each M.2 SSD slot, so it is not possible to simultaneously run eight GPUs and a full complement of NVMe drives in the rear of the chassis connected via the two MCIO connectors. In our full 8-GPU configuration, only 2 M.2 slots were available for storage. Administrators who need additional NVMe capacity alongside maximum GPU density should be aware that adding rear hot-swap NVMe storage via the back-panel cages will consume additional PCIe lanes and disable some GPU capacity in their system.
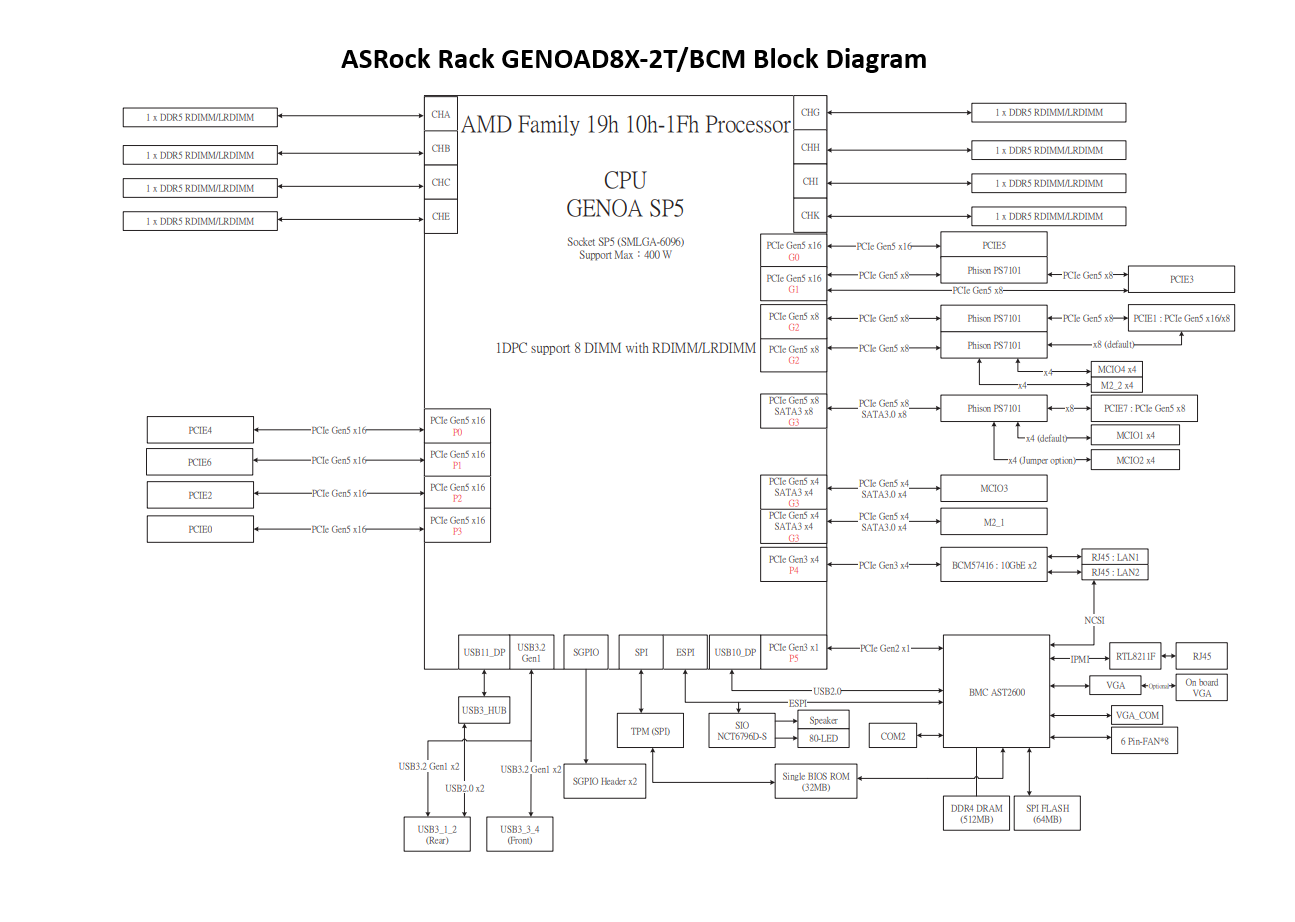
ASRock Rack GENOAD8X-2T/BCM motherboard block diagram showing CPU, PCIe Gen 5 slots, DIMM channels, M.2 slots, BMC, USB, SATA, and networking connections.
With that said, storage is equally modular and expansive, though the configuration does affect the PCIe lane budget for GPUs, which is worth planning around for the intended use case. The rear panel of our review unit features a 2.5″ drive cage that supports up to four 2.5-inch SSDs in either 4x 7mm or 2x 15mm configurations, with an optional second set of up to four available in place of the fourth PSU slot. Because our review unit required all four power-supply bays to support the full 8-GPU configuration, we had access only to the first of the two hot-swap bays. Internally, the chassis can support a 3.5-inch cage that accommodates up to four 3.5-inch drives, four 2.5-inch 15mm drives, or up to twelve 2.5-inch 7mm drives, plus four additional internal 2.5-inch 7mm SSD slots if configured.

For networking, two onboard RJ45 10 Gb/s ports powered by the Broadcom BCM57416 are standard on the motherboard, alongside a dedicated Gigabit Ethernet IPMI management port. Administrators can further increase bandwidth by installing PCIe NICs that support up to 400 Gb/s for high-bandwidth fabric connectivity, though note that additional PCIe NICs occupy GPU slots, reducing the maximum number of GPUs the system can host.

Remote Management and System Intelligence
To safeguard the hardware and optimize performance, the system includes the Comino Monitoring System (CMS). A separate, autonomous controller board drives the CMS and serves as the server’s “brain,” independent of the main operating system. In practice, this controller reads a comprehensive array of sensors that track air and coolant temperatures, humidity levels, coolant flow rates, and reservoir levels in real time. Crucially, this autonomous design enables the CMS to perform self-diagnosis and trigger emergency shutdowns upon detecting a leak or a pump failure, protecting the expensive internal hardware from damage.
A web-based GUI handles day-to-day management, providing administrators with clear visibility into cooling performance, uptime, and real-time energy consumption for the CPU and GPUs. For enterprise-scale deployments, the CMS also connects to centralized monitoring tools via REST APIs, such as Zabbix, Grafana, and InfluxDB. Together, these capabilities help administrators maintain a 3-year interservice period and keep the server running at peak efficiency without thermal throttling, even in high-ambient environments.
Beyond AI: Creative and Engineering Applications
While our testing focused on AI inference workloads, the Grando serves an equally practical role for creative professionals and engineers who need substantial local GPU compute. The 768GB of aggregate VRAM across eight RTX PRO 6000 cards unlocks capabilities that conventional workstation configurations cannot match.
FX artists and motion graphics professionals can render complex scenes with massive texture sets entirely in VRAM, eliminating the disk-swapping bottlenecks that plague productions using 8K footage or high-polygon environments. CAD engineers running computational fluid dynamics or structural simulations can tackle assemblies of unprecedented complexity without partitioning their models into multiple runs. Video editors working with multi-stream 8K RAW timelines, colorists applying ML-based noise reduction at full resolution, and 3D artists rendering path-traced finals locally rather than waiting for cloud farm availability all benefit from this density of GPU memory and compute.
The Grando does not require a full eight-GPU configuration. Comino offers the platform in four-GPU, six-GPU, and eight-GPU configurations, with all variants available for immediate shipment. Smaller studios, independent creators, and engineering teams can right-size their investment to current needs while retaining a clear upgrade path as workloads grow.
Platform Trade-offs: Density vs. Expandability
The Grando’s compact design delivers exceptional GPU density and thermal management within a standard 4U footprint, but that density involves architectural trade-offs worth understanding before deployment.
The chassis accommodates motherboards with EATX and EEB form factors, but not extended server boards found in traditional dual-socket platforms. This limits the total number of PCIe lanes available for peripherals beyond the GPU array. In our eight-GPU configuration, the AMD EPYC processor’s 128 PCIe Gen 5 lanes are almost entirely consumed by the GPUs, leaving little bandwidth for additional NVMe storage or high-speed networking beyond the onboard 10GbE ports.
This contrasts with the eight-GPU platforms we have reviewed from Dell, HPE, and Supermicro. Those systems use larger chassis, dual-socket configurations, and PCIe switch topologies to support significantly more peripheral connectivity. They typically accommodate four to eight additional NICs or DPUs alongside the full GPU complement, plus eight or more hot-swap NVMe bays, making them well-suited for distributed inference workloads that require high-bandwidth fabric interconnects.
However, that expanded capability comes at a substantial cost. Power draws exceed 8kW. Thermal loads require dedicated data center cooling infrastructure. Noise floors preclude deployment outside purpose-built machine rooms. And lead times frequently stretch six to eighteen months due to persistent supply constraints on enterprise GPU platforms.
The Grando occupies a different position. For organizations that prioritize rapid deployment, manageable operating environments, and inference or creative workloads over large-scale distributed training, the trade-offs are often favorable. Teams that need their hardware now, in an environment they can actually work with, may find the Grando’s approach to density more practical than waiting in a queue for a platform they cannot realistically deploy once it arrives.
Comino Grando Performance Testing Results

System Configuration
- Chassis: Comino Grando
- Motherboard: ASRock Rack GENOAD8X-2T/BCM
- CPU: AMD EPYC 9474F 48C
- Memory: 512GB DDR5
- GPU: 8 x NVIDIA RTX PRO 6000
- Storage: M.2 SSD
Claude Code Serving – MiniMax M2.5
Beyond traditional raw LLM inference benchmarks, we wanted to evaluate how well this hardware performs in an agentic coding workflow, specifically by serving multiple concurrent Claude Code sessions using a locally hosted model. This use case maps directly to development team productivity: how many engineers can simultaneously use an AI coding assistant served from a single node before the experience degrades?
To test this, we built a benchmark harness that generates a dataset of moderately difficult coding problems (such as implementing an LRU cache, building a CLI todo application, writing a markdown converter, and constructing a REST API) and runs each Claude Code session in a separate Docker container against the local vLLM server. A transparent proxy sits between the sessions and the inference endpoint, capturing per-request metrics for each Claude Code instance. The model used was MiniMax M2.5, served via vLLM on the system’s eight NVIDIA RTX PRO 6000 GPUs. While not the top-ranked coding model on public leaderboards, M2.5 is a capable model that many users, including our developer friends, run locally.
For a baseline reference point, we use Anthropic’s Claude Opus 4.6 average output throughput via OpenRouter.ai, one of the most popular routing services for production API access. That baseline comes in at approximately 37 tokens per second per API request.
We measured two key metrics: the average output tokens per second per Claude Code session (what each developer experiences) and the aggregate output tokens per second across all sessions (the total work the server produces).
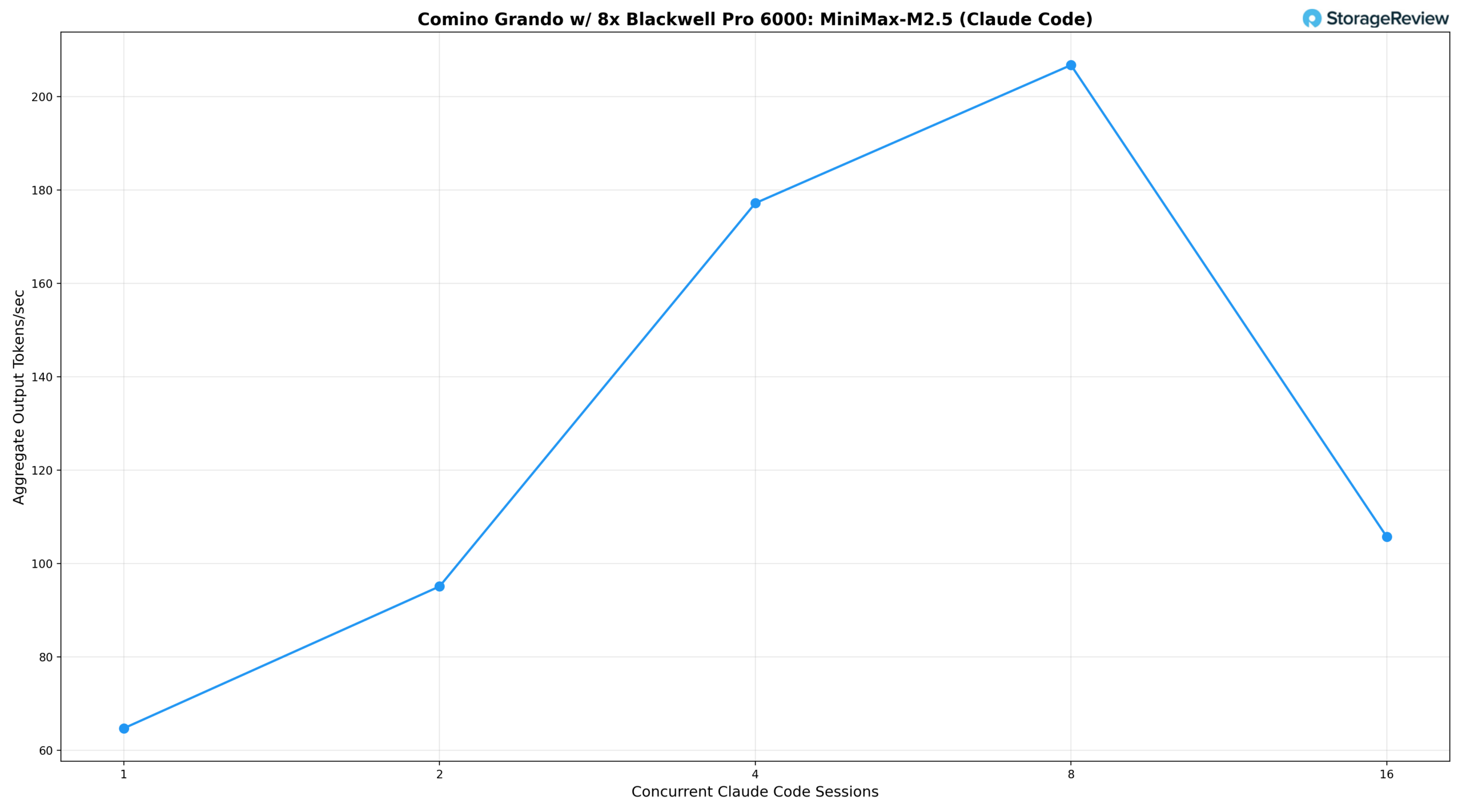
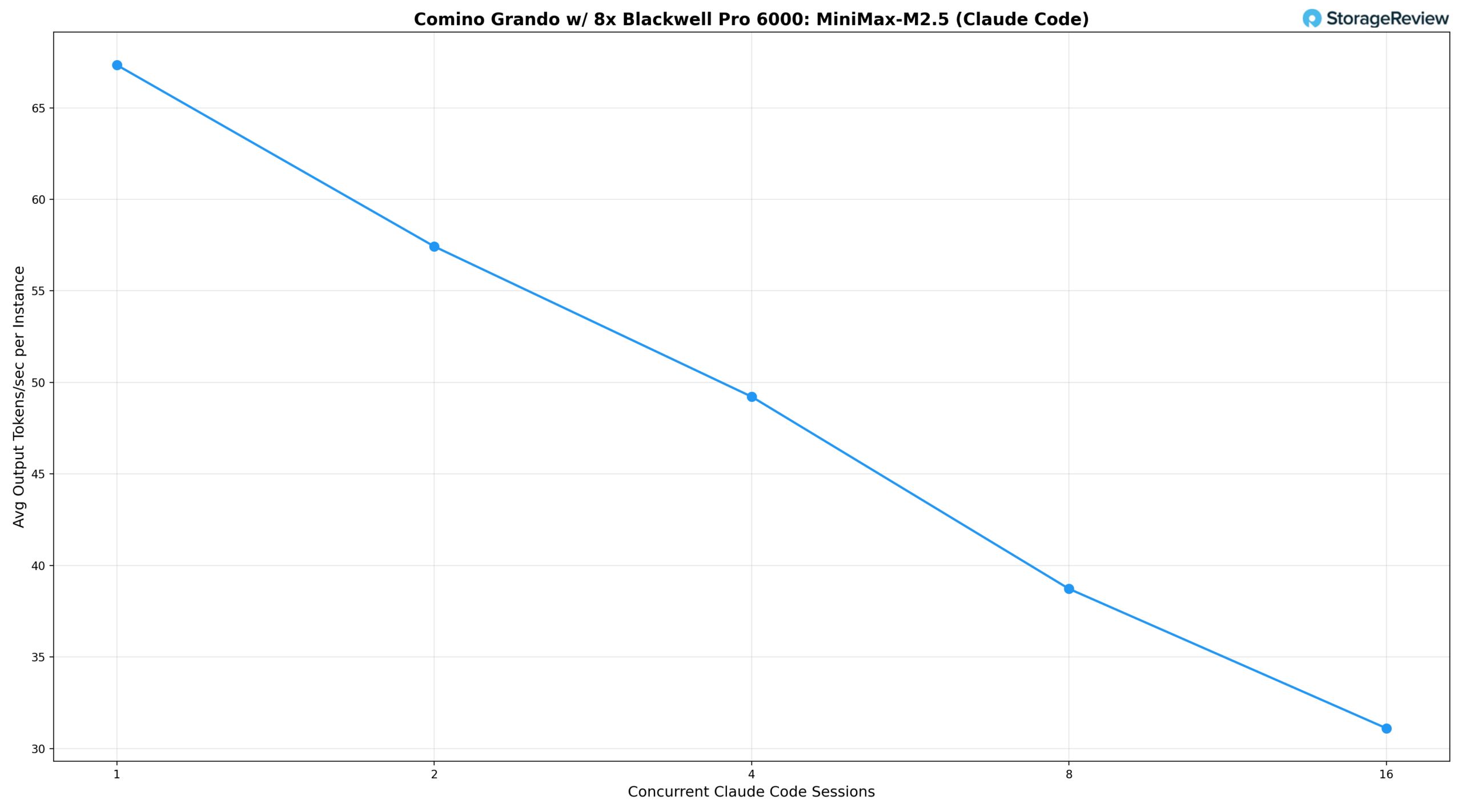
Based on the results, a single concurrent Claude Code session delivers 67.3 tok/s per user and an aggregate output of 64.7 tok/s. At two sessions, per-instance throughput drops modestly to 57.4 tok/s, while aggregate output climbs to 95.1 tok/s as vLLM’s batching begins to amortize overhead. Four concurrent sessions maintain 49.2 tok/s per user, still a highly responsive experience for interactive coding workflows, while aggregate throughput reaches 177.2 tok/s. Eight sessions represent the sweet spot for aggregate output, peaking at 206.7 tok/s total, while per-instance throughput settles at 38.7 tok/s, a level that remains comfortable for real-time code generation and iteration.
At 16 concurrent sessions, the system exhibits the classic batching trade-off: per-instance throughput drops to 31.1 tok/s, and aggregate output falls to 105.8 tok/s. This suggests that, at this concurrency level, the 230B MiniMax M2.5 model is pushing the limits of what eight GPUs can sustain without introducing meaningful latency for each user. The aggregate dip from 8 to 16 sessions reflects the memory-bandwidth demands of a large MoE architecture under heavy simultaneous decode load, rather than a scheduling inefficiency.
For organizations evaluating self-hosted AI infrastructure for developer tooling, the Grando makes a strong case. Running a frontier-class 230B model, it can comfortably serve up to eight simultaneous Claude Code sessions at throughput levels that feel genuinely interactive, with per-user speeds exceeding 38 tok/s at peak aggregate output. Teams of four to eight engineers can operate at near-optimal throughput without perceptible degradation in responsiveness.
The liquid-cooled architecture also makes this level of compute practical in environments where traditional GPU servers cannot operate. The system runs quietly enough to sit in a startup office, a small machine room, or a dedicated corner of an open workspace. Air-cooled systems with similar GPU density typically reach 90 dB or higher, which is loud enough to require dedicated data center space or, at a minimum, a closed server closet with serious acoustic treatment. The Grando can coexist with the team that uses it. Combined with full data locality, no per-token API costs, and complete control over model selection, it offers a self-hosted path that scales with a growing development team without requiring datacenter infrastructure or lockstep cost increases.
vLLM Online Serving – LLM Inference Performance
vLLM is one of the most popular high-throughput inference and serving engines for LLMs. The vLLM online serving benchmark evaluates the real-world serving performance of this inference engine under concurrent requests. It simulates production workloads by sending requests to a running vLLM server, with configurable parameters such as request rate, input and output lengths, and the number of concurrent clients. The benchmark measures key metrics, including throughput (tokens per second), time to first token, and time per output token (TPOT), helping users understand how vLLM performs under different load conditions.
We tested inference performance across a comprehensive suite of models spanning various architectures, parameter scales, and quantization strategies to evaluate throughput under different concurrency profiles.
Summary Of Results
| Model | Precision | Equal (256/256) | Prefill-Heavy (8k/1k) | Decode-Heavy (1k/8k) |
|---|---|---|---|---|
| Comino Grando w/ 8× RTX PRO 6000 Blackwell — vLLM Inference Results (tok/s, peak at BS=256) | ||||
| GPT-OSS 20B | ep_dp1 | 17,280 | 32,061 | 11,187 |
| GPT-OSS 120B | ep_dp1 | 11,726 | 21,636 | 7,570 |
| Llama 3.1 8B Instruct | FP8 | 12,109 | 20,137 | 7,353 |
| Llama 3.1 8B Instruct | FP4 | 11,954 | 20,206 | 7,239 |
| Llama 3.1 8B Instruct | BF16 | 11,752 | 17,346 | 6,155 |
| Qwen3 Coder 30B A3B | FP8 | 10,985 | 16,659 | 4,907 |
| Qwen3 Coder 30B A3B | BF16 | 10,588 | 16,680 | 4,829 |
| Mistral Small 3.1 24B | BF16 | 8,925 | 11,846 | 4,975 |
| MiniMax M2.5 (230B) | ep_dp1 | 5,753 | 7,357* | 2,555 |
| All values in tok/s, peak throughput at BS=256. *MiniMax M2.5 prefill-heavy peaked at BS=128 (7,357 tok/s); BS=256 was 7,141 tok/s. | ||||
GPT-OSS 120B and 20B
The GPT-OSS model family was tested in both 120B and 20B configurations on the Comino Grando.
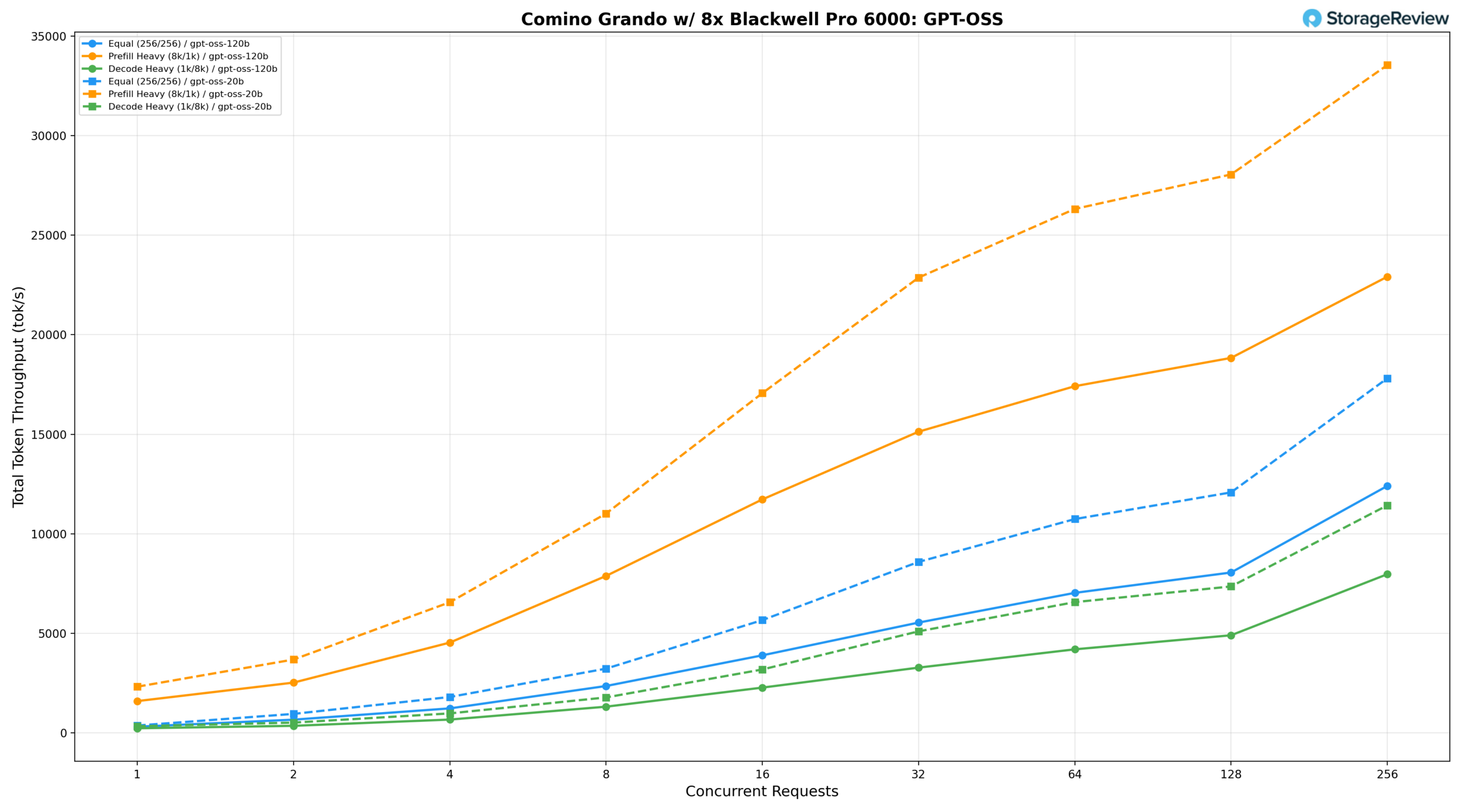
GPT-OSS 120B
Under equal workload (256/256), the 120B model delivers 268.85 tok/s at BS=1, reaches 6,666.23 tok/s at BS=64, and peaks at 11,726.04 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 1,375.69 tok/s, climbs to 16,374.19 tok/s at BS=64 and 17,944.55 tok/s at BS=128, and peaks at 21,636.41 tok/s at BS=256. Decode-heavy (1k/8k) grows from 196.28 tok/s at BS=1 to 7,569.97 tok/s at BS=256, with latency well-controlled at lower concurrency levels.
GPT-OSS 20B
The 20B model delivers 334.80 tok/s at BS=1 under equal workload, reaches 10,303.56 tok/s at BS=64, and peaks at 17,280.12 tok/s at BS=256. Prefill-heavy starts at 2,007.90 tok/s, climbs to 24,990.46 tok/s at BS=64 and 26,866.25 tok/s at BS=128, peaking at 32,060.72 tok/s at BS=256, the highest absolute prefill throughput recorded across both model sizes. Decode-heavy grows from 286.08 tok/s at BS=1 to 11,187.36 tok/s at BS=256, delivering roughly 1.5× the decode throughput of the 120B at peak concurrency while maintaining tighter latency throughout.
Qwen3 Coder 30B A3B Instruct and FP8 Instruct
The Qwen3-Coder-30B-A3B-Instruct model was tested with both BF16 and FP8 precision.
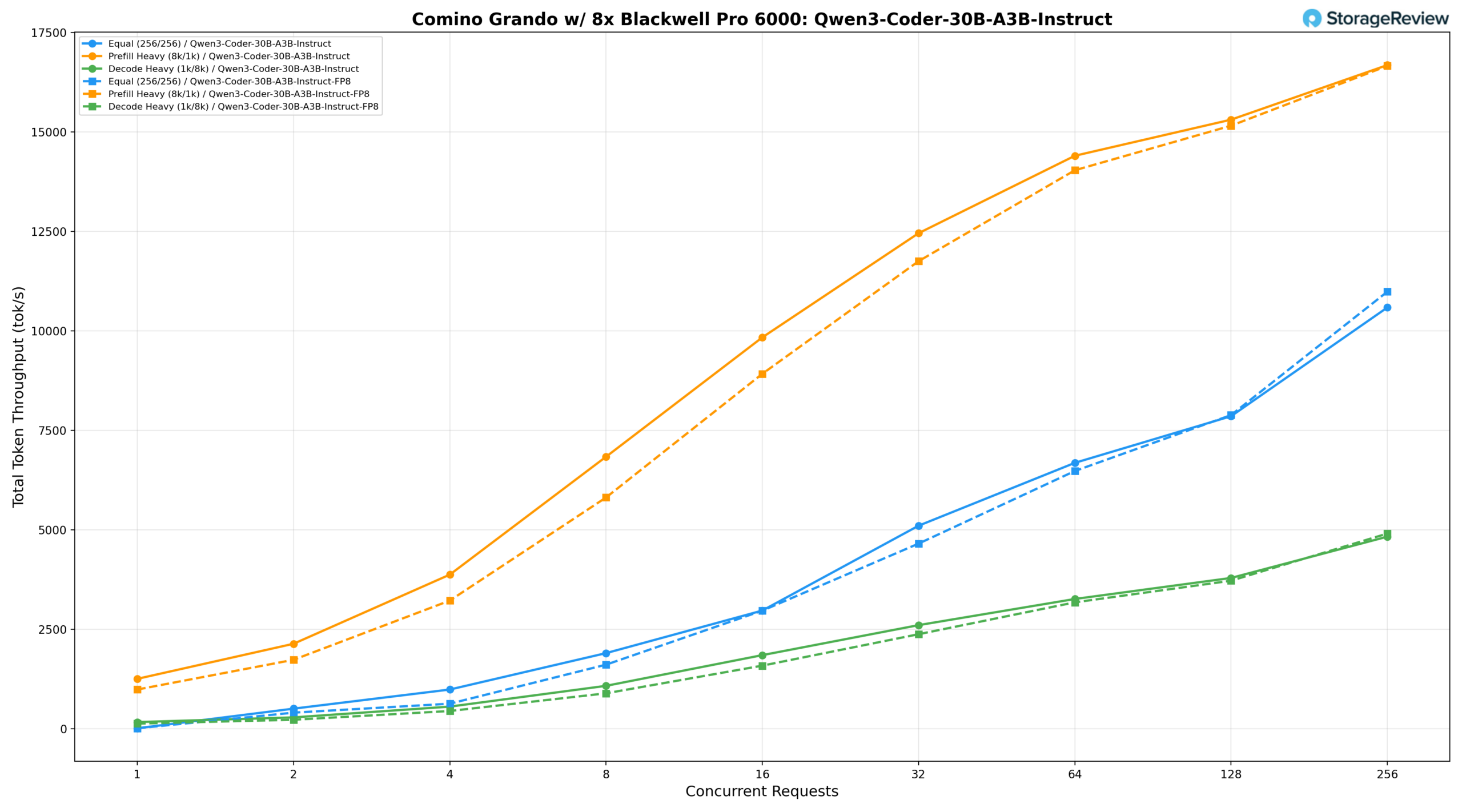
Qwen3-Coder-30B-A3B-Instruct (BF16)
Under an equal workload (256/256), the BF16 model delivers 1,902.32 tok/s at BS=8, reaches 6,683.58 tok/s at BS=64, and peaks at 10,587.56 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 1,256.03 tok/s at BS=1, climbs to 14,400.57 tok/s at BS=64 and 15,308.35 tok/s at BS=128, and peaks at 16,679.52 tok/s at BS=256. Decode-heavy (1k/8k) grows from 169.19 tok/s at BS=1 to 4,828.82 tok/s at BS=256, with latency well-controlled at lower concurrency levels.
Qwen3-Coder-30B-A3B-Instruct (FP8)
The FP8 model delivers throughput comparable to BF16 across most scenarios, with equal workload reaching 6,478.54 tok/s at BS=64 and peaking at 10,984.61 tok/s at BS=256, a slight improvement over BF16 at peak concurrency. Prefill-heavy starts at 987.48 tok/s at BS=1, climbs to 14,036.46 tok/s at BS=64 and 15,156.69 tok/s at BS=128, and peaks at 16,658.98 tok/s at BS=256. Decode-heavy grows from 130.70 tok/s at BS=1 to 4,906.51 tok/s at BS=256, marginally outpacing BF16 at peak concurrency while the two configurations remain closely matched throughout the rest of the concurrency range.
Mistral Small 3.1 24B Instruct 2503
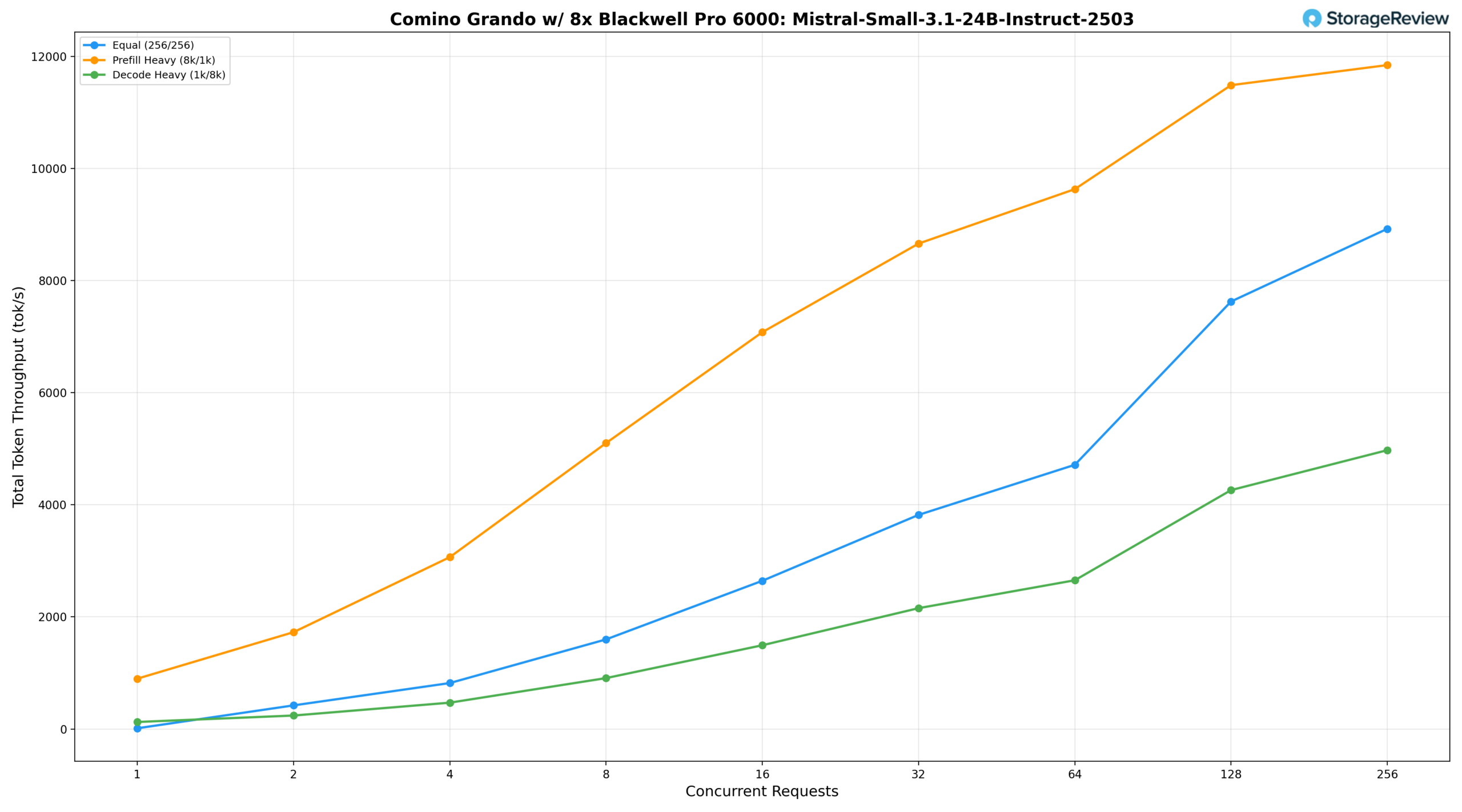
Under an equal workload (256/256), the model delivers 1,598.79 tok/s at BS=8, reaches 4,713.84 tok/s at BS=64, and scales strongly to 8,925.12 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 897.84 tok/s at BS=1, climbs to 9,632.58 tok/s at BS=64 and 11,488.13 tok/s at BS=128, peaking at 11,846.15 tok/s at BS=256. Decode-heavy (1k/8k) grows from 124.98 tok/s at BS=1 to 2,653.82 tok/s at BS=64, then accelerates noticeably at higher concurrency levels, reaching 4,262.53 tok/s at BS=128 and peaking at 4,975.06 tok/s at BS=256, reflecting the model’s ability to sustain strong decode throughput as concurrency scales.
Llama 3.1 8B Instruct
The Llama-3.1-8B-Instruct model was tested across three precision configurations on the Comino, providing a clear view of how quantization affects throughput for this model size.
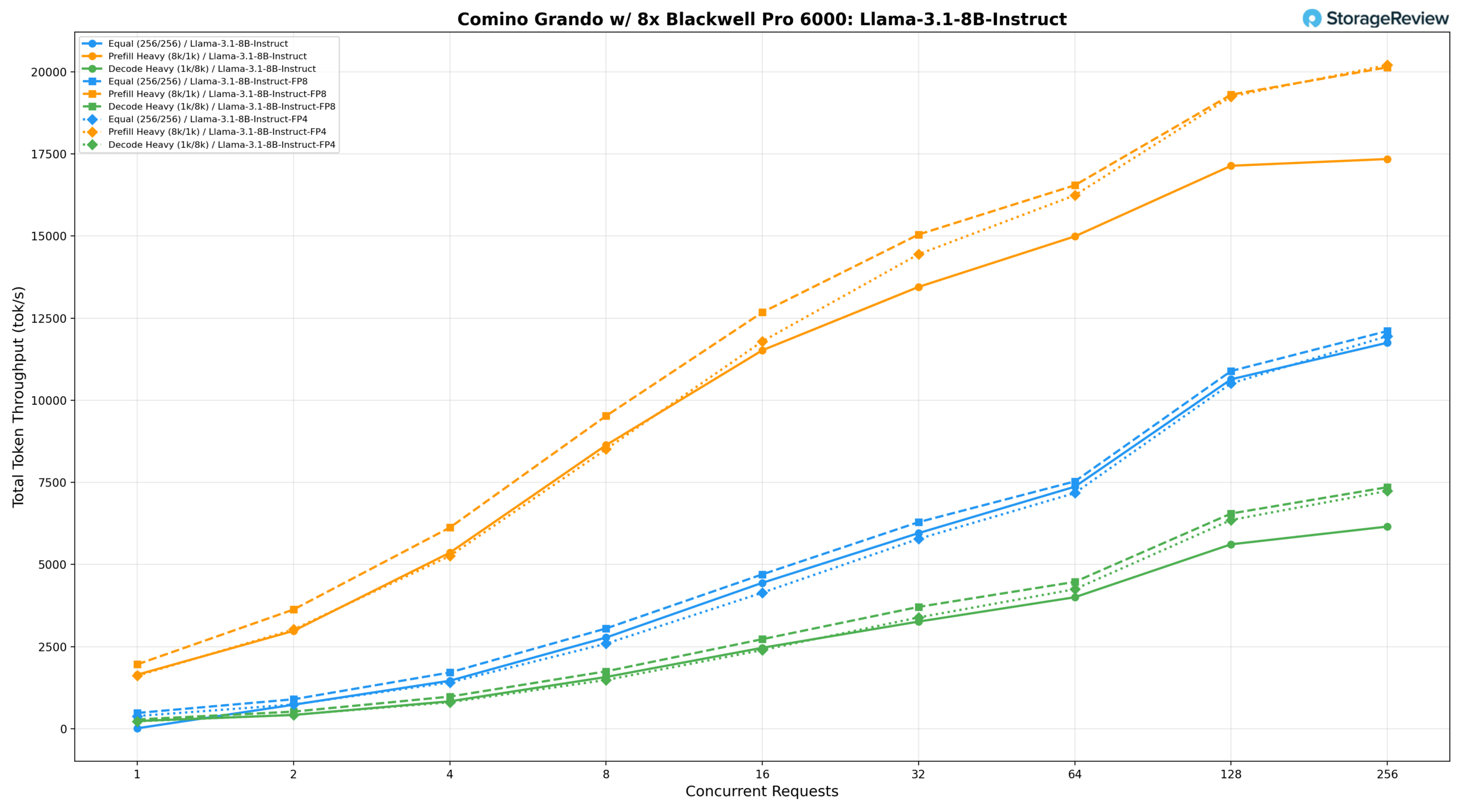
Llama 3.1 8B Instruct BF16
Under an equal workload (256/256), the BF16 model delivers 2,776.42 tok/s at BS=8, reaches 7,369.01 tok/s at BS=64, and peaks at 11,751.56 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 1,645.29 tok/s at BS=1, climbs to 14,990.47 tok/s at BS=64 and 17,140.71 tok/s at BS=128, and peaks at 17,345.80 tok/s at BS=256. Decode-heavy (1k/8k) grows from 234.78 tok/s at BS=1 to 6,154.73 tok/s at BS=256.
Llama 3.1 8B Instruct FP8
FP8 quantization delivers a meaningful uplift across all scenarios. The equal workload reaches 7,530.39 tok/s at BS=64 and peaks at 12,108.98 tok/s at BS=256. Prefill-heavy climbs to 16,546.53 tok/s at BS=64 and 19,306.49 tok/s at BS=128, peaking at 20,137.35 tok/s at BS=256, roughly a 16% gain over BF16 at peak concurrency. Decode-heavy peaks at 7,353.40 tok/s at BS=256, approximately 19% ahead of BF16.
Llama 3.1 8B Instruct FP4
FP4 delivers throughput that is closely competitive with FP8 at higher concurrency levels, though it falls slightly behind at lower batch sizes. The equal workload peaks at 11,954.40 tok/s at BS=256, and prefill-heavy reaches its highest point at 20,205.57 tok/s at BS=256, narrowly edging out FP8 at peak concurrency. Decode-heavy peaks at 7,239.29 tok/s at BS=256, remaining within a few percent of FP8 throughout, making FP4 a compelling option when memory efficiency is a priority without a meaningful sacrifice in throughput.
MiniMax M2.5
The MiniMax-M2.5 230B, tested on the Comino Grando, was the largest and most demanding model we used.
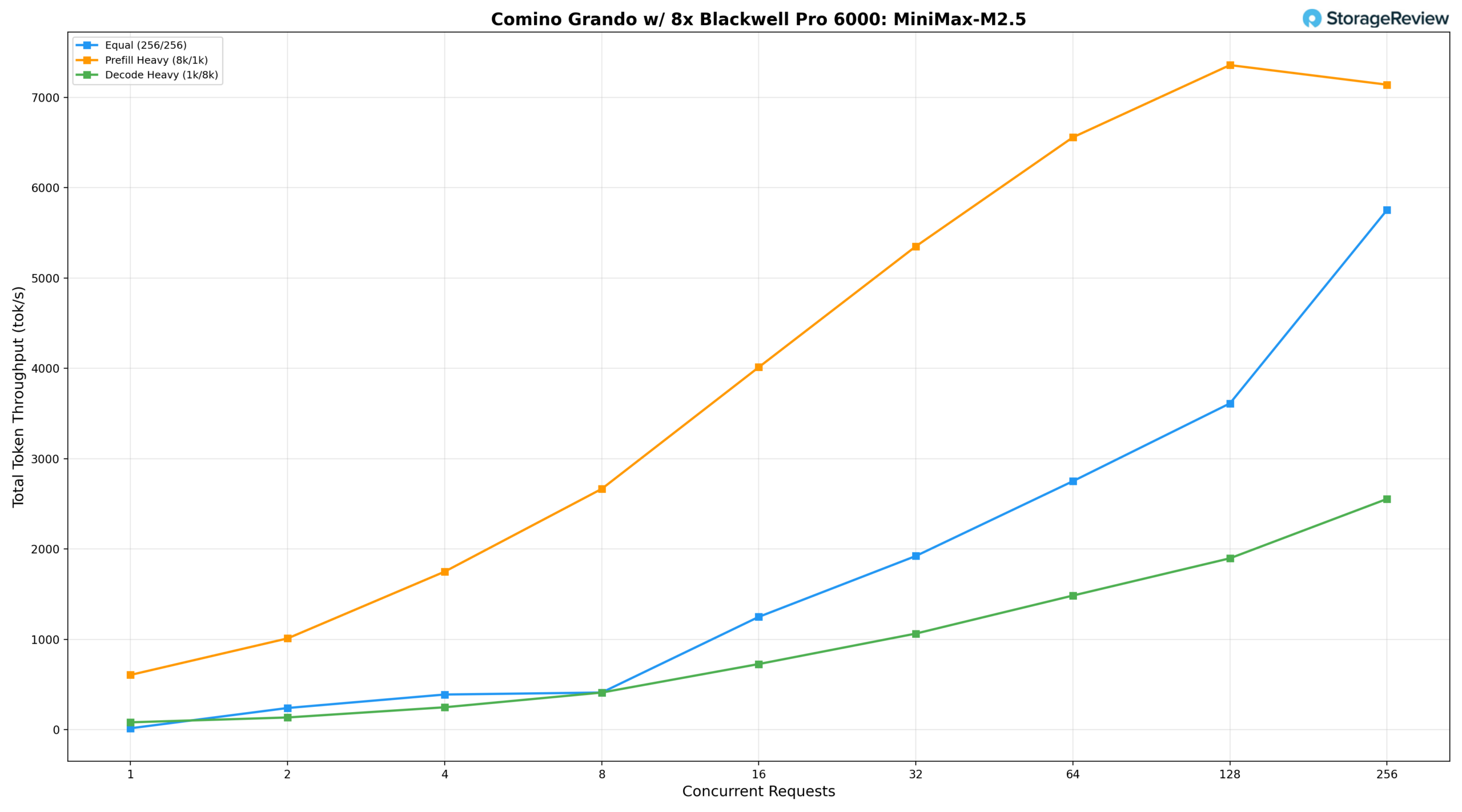
Under an equal workload (256/256), the model starts at 16.35 tok/s at BS=1, reaches 2,751.25 tok/s at BS=64, and scales strongly at higher concurrency, peaking at 5,753.24 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 606.97 tok/s at BS=1, climbs steadily to 5,351.02 tok/s at BS=32 and 6,557.92 tok/s at BS=64, reaching its peak at 7,357.26 tok/s at BS=128 before slightly tapering to 7,140.74 tok/s at BS=256, suggesting the model approaches saturation in prefill throughput beyond BS=128. Decode-heavy (1k/8k) grows consistently from 82.21 tok/s at BS=1 to 1,485.28 tok/s at BS=64, peaking at 2,554.87 tok/s at BS=256, reflecting the expected memory bandwidth demands of a 230B MoE architecture under sustained decode workloads.
Conclusion
The Comino Grando is best understood as a system purpose-built to unlock the full potential of eight NVIDIA RTX PRO 6000 GPUs. Every major design decision, from the inverted motherboard layout to the cooling loop and integrated monitoring stack, is intended to ensure those GPUs can operate continuously at full 600W TDP without thermal or power constraints.

What makes the Grando compelling is not any single feature in isolation but the way the entire system coheres. The liquid cooling is not a bolt-on addition; it is the architecture. The power delivery is redundant, hot-swappable, and scaled to the 4,800W load of eight 600W cards with headroom to spare. The monitoring system goes beyond reporting temperatures; it autonomously protects the hardware when something goes wrong. Nothing here feels like an afterthought.
The performance numbers reinforce that cohesion. Across a diverse suite of models, from Llama 3.1 8B to the 230B MiniMax M2.5, the Grando delivered throughput figures that hold up well for a self-hosted platform. Claude Code concurrency testing put a finer point on the practical value: eight engineers can run simultaneous agentic coding sessions against a locally hosted 230B model at interactive speeds, with per-user throughput exceeding 38 tok/s at peak aggregate output. Teams of four to eight can operate at near-optimal throughput without perceptible degradation.
The value of this configuration extends beyond AI inference. With 96GB of VRAM per GPU and dense multi-GPU scaling, the platform is equally well suited for high-end creative and engineering workloads, including VFX rendering, large-scale simulation, and complex CAD pipelines. The system scales down to four-GPU and two-GPU configurations, making this level of performance accessible to smaller studios and teams that still require workstation-class density.
Where the Grando differs most from the enterprise eight-GPU platforms we have reviewed is in deployment practicality. Those systems offer more PCIe lane headroom, more NIC slots, and deeper storage connectivity, but they also require dedicated data center infrastructure, draw well over 8kW, and have lead times that can stretch beyond a year. The Grando trades some of that peripheral expandability for a system that runs quietly enough to share a room with its users, dissipates less heat into the surrounding environment, and ships now. For organizations that prioritize rapid deployment and manageable operating environments over maximum fabric connectivity, the trade-off is favorable.


 Amazon
Amazon