

The HP Z2 Mini G1a Workstation marks a bold step forward in highly customizable, compact computing. Designed for professionals in fields like 3D modeling, AI development, and digital content creation, this powerhouse combines portability with precision. At the heart of this workstation is the AMD Ryzen AI Max PRO Series processor, which delivers accelerated performance for multitasking, rendering, and local LLMs.

At the core of the system lies AMD’s Ryzen AI MAX+ Pro 395, a cutting-edge processor unveiled in early 2025. The CPU clock speed boosts up to 5.1 GHz and has 16 cores, delivering strong compute performance. It is also paired with AMD Radeon 8060S integrated graphics. Moreover, like many AI products, the included neural processing unit provides an additional 50 TOPS for demanding AI workloads. Its Radeon 8060S integrated graphics make it a contender in the GPU-intensive workloads, as users can allocate up to 96GB of VRAM to it. This gives it a unique edge for leading local LLM inferencing workloads, as well as rendering and content creation.

When users configure the HP Z2 Mini G1a, this system scales differently from other systems. The CPU and GPU scale together. For example, the base configuration includes the AMD Ryzen AI Max Pro 380 with Radeon 8040S graphics and 32GB of shared memory. When you go with more memory, such as moving to 128GB, it changes the CPU and GPU as well. That change moves it to the Ryzen AI Max+ Pro 395 with Radeon 8060S graphics, with 128GB of shared memory.
The system covered in this review is the Z2 Mini G1a with the Ryzen AI Max+ Pro 395 chipset, offering a 16-core CPU paired with the Radeon 8060S graphics, both sharing 128GB of DDR5. While our system comes with dual 1TB SSDs and a list price of $4,781, its effective street price is much lower. Pricing was a considerable concern around the HP ZBook Ultra G1a we reviewed earlier this year, but thankfully, pricing and performance have substantially improved. Currently, B&H sells the top-spec Z2 Mini G1a with a 2TB SSD for just $3,342.65.
HP ZCentral Remote Boost
One of the more interesting features HP offers in its professional workstation lines is HP ZCentral Remote Boost. HP ZCentral Remote Boost is the company’s remote connection software (formerly known as HP Remote Graphics Software or RGS). It has been designed for use with physical workstations rather than virtual machines (VMs). In essence, Remote Boost connects an endpoint device to a Z workstation in your office or home, allowing users to access the system for graphics-intensive work via the endpoint device.
Multiple users can then leverage one workstation, regardless of where it might reside: in a data center, data closet, or even at the work desk. If the receiver can contact the sender system over the network, the compute resources can be fully remote, even in a WAN environment when VPNs are present.
Overall, we had an excellent end-user experience with HP Remote Boost. We encourage reading the white paper, How it Works: HP ZCentral Remote Boost, for a detailed examination of this useful technology, which is now more relevant than ever.
HP Z2 Mini G1a Specifications
| Category | Specifications |
|---|---|
| Available Operating Systems |
|
| Processor Family | AMD Ryzen AI Max PRO processor |
| Available Processors |
|
| Neural Processing Unit | AMD Ryzen AI (50 TOPS) |
| Product Colour | Jet black |
| Form Factor | Mini |
| Maximum Memory | 128 GB LPDDR5X-8533 MT/s ECC, transfer rates up to 8000 MT/s |
| Internal Storage |
|
| Available Graphics |
|
| Audio | Integrated mono speaker, Realtek ALC3205-VA2-CG, 2.0W internal mono speaker |
| Expansion Slots | 2 M.2 2280 PCIe 4×4; 1 M.2 2230 for WLAN |
| Ports and Connectors |
|
| Keyboard Options | HP USB Business Slim SmartCard CCID Keyboard; HP 125 Black Wired Keyboard; HP 320K Wired Keyboard |
| Mouse Options | HP Wired Desktop 128 Laser Mouse; HP Wired 320M Mouse; HP 125 Wired Mouse |
| Communications | LAN: Realtek RTL8125BPH-CG 2.5 GbE; WLAN: MediaTek Wi-Fi 7 MT7925 (2×2) and Bluetooth 5.4 |
| Software | HP UEFI BIOS Certification 2.7B; HP PC Hardware Diagnostics Windows; HP Image Assistant; HP Manageability Integration Kit 10; Performance Advisor 3.0 |
| Security Management | HP Secure Erase; HP Sure Click; HP BIOSphere Gen6; Sure Recover Gen4; HP Sure Admin; Hood Sensor Optional Kit; HP Client Security Manager Gen6; HP Sure Start Gen7; HP Sure Sense Gen2; HP Sure Run Gen5; Microsoft Pluton; HP Wolf Pro Security Edition |
| Management Features | High-Performance Mode, Quiet Mode, Rack Mode, Performance Mode |
| Power | 300 W internal power adapter, up to 92% efficiency, active PFC |
| Dimensions | 3.4 x 6.6 x 7.9 in; 8.55 x 16.8 x 20 cm (standard desktop orientation) |
| Weight | Starting at 5.07 lb (2.3 kg); Package starting at 9 lb (4.1 kg) |
| Ecolabels | IT ECO Declaration; SEPA; Taiwan Green Mark; Japan PC Green Label; FEMP; EPEAT Gold with Climate+; Korea MEPS |
| Energy Certification | ENERGY STAR certified |
| Sustainable Impact | Bulk packaging available; 10% ITE-derived closed loop plastic; Product Carbon Footprint; Contains at least 65% post-consumer recycled plastic; Contains at least 20% post-industrial recycled steel; QR code-enabled product portal (Dec 2025); New Energy Consumption dashboard |
| Display Support | Supports four simultaneous displays. Each Mini DisplayPort can drive one display; each Thunderbolt port can drive two displays |
Design and Build
The front of the HP Z2 Mini G1a offers a slick design with a straightforward layout. The front bezel has a cool lattice framework, with the HP logo on one side and a power button on the other. The lattice is functional, allowing air to move freely through the case without being impeded.

One side of the Z2 Mini G1a also offers a few ports, including a USB-C 10Gbps port with 15W output, as well as a USB-A port with 10GBps connectivity, and a headphone/microphone jack.

There is a wide assortment of ports on the back of this system. It includes two Mini DP 2.1, two USB 2.0, two USB 3.0 10 Gb/s, two Thunderbolt 4 USB-C 40 Gb/s, a 2.5 GbE port, and, of course, the power supply connection and a cable lock. The power supply is fully integrated, which is a nice touch, eliminating the need for a huge AC power brick. HP also supports a feature allowing greater customization, two Flex IO slots that users can change to their liking. The top slot offers a choice between a dual-port USB-A 5Gb/s combo or a 1GbE NIC with a serial port. The bottom slot can be configured with another 1GbE NIC via a serial port, an additional external power button, as well as an HP Remote System Controller for out-of-band (OOB) management.

To dig into the HP Z2 Mini G1a, the top cover slides off conveniently using a finger-latch on the backside.

A large fan + heatsink combo covers most of the motherboard, cooling the AMD Ryzen CPU/GPU combo. While the system RAM is soldered on and can’t be serviced, the Z2 Mini G1a does offer two PCIe Gen4 M.2 slots. These are accessed by removing two small screws that connect the fan assembly to the heatsink and lifting the fan assembly.

During heavy use, some fan noise became noticeable, though not as prominent or aggressive as what you might find in a larger workstation.

HP Z2 Mini G1a Performance Testing
For this review, we compare the HP Z2 Mini G1a to the HP ZBook Ultra G1a 14″ laptop that we previously wrote about. Both the workstation and the laptop contain identical components, allowing us to see how well the desktop form factor compares with a larger power envelope and increased cooling.
UL Procyon: AI Computer Vision
The Procyon AI Computer Vision Benchmark provides detailed insights into how AI inference engines perform at a professional level. By incorporating engines from multiple vendors, it delivers performance scores that accurately reflect a device’s capabilities. The benchmark evaluates state-of-the-art neural network models by comparing their AI acceleration performance across different hardware types—including CPU, GPU, and NPU—allowing users to assess relative efficiency across a range of workload sizes and conditions.
To reflect real-world AI workloads, the benchmark uses six diverse neural network models, each chosen for its relevance to modern computer vision tasks. MobileNet V3 is a compact, mobile-focused model designed for subject identification in images, while Inception V4 performs the same task using a deeper and more complex architecture.
YOLO V3 (You Only Look Once) specializes in object detection by estimating object probabilities in real-time. DeepLab V3, built on MobileNet V2, focuses on semantic image segmentation and pixel clustering. Real-ESRGAN, the most computationally demanding test, upscales images from 250×250 to 1,000×1,000 resolution. Finally, ResNet 50 is a robust classification model that enables more effective training of deep neural networks.
The HP Z2 Mini G1a slightly outpaces the HP ZBook Ultra G1a 14″ in the CPU test. The workstation scored 227 overall, while the laptop scored 186 overall. There was a noticeably faster time from the workstation, proportional throughout each category. Shown best from the REAL-ESRGAN test, resulting in 1,892.10 ms from the workstation and 2,138.97 ms from the mobile platform. Though the difference in speed is evident throughout, with the scores favoring the workstation, both end up with excellent scores.
During the GPU test, the laptop comes out on top with an overall score of 583 versus the workstation’s 528. The Radeon 8060S integrated graphics show high-performance metrics on both systems. However, on the notebook, results were slightly faster in most categories. The only exception is MobileNet V3, where the workstation scored 0.42 ms compared to 0.46 ms from the laptop. However, the opposite is true throughout the rest of the results here. Looking at the largest workload, REAL-ESRGAN, for example, the workstation had a time of 211.76 ms, roughly 11 ms behind the notebook at 200.40 ms.
Both the HP Z2 Mini G1a and the HP ZBook Ultra G1a 14″ ran well in the NPU test. Looking at the overall scores of 1,761 from the workstation and 1,773 from the notebook, it appears that the ZBook mobile platform is better here. However, the difference in almost every category, with the exceptions of DeepLab V3 and REAL-ESRGAN, is only hundredths of milliseconds. Both systems show solid performance for AI inferencing, indicating that they are comparable in performance.
| UL Procyon: AI Computer Vision Inference (Lower is better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
| CPU Times | ||
| AI Computer Vision Overall Score (higher is better) | 227 | 186 |
| MobileNet V3 | 0.75 ms | 1.09 ms |
| ResNet 50 | 5.99 ms | 6.84 ms |
| Inception V4 | 17.12 ms | 19.80 ms |
| DeepLab V3 | 21.20 ms | 28.27 ms |
| YOLO V3 | 36.58 ms | 41.64 ms |
| REAL-ESRGAN | 1,892.10 ms | 2,138.97 ms |
| GPU Times | ||
| AI Computer Vision Overall Score (higher is better) | 528 | 583 |
| MobileNet V3 | 0.42 ms | 0.46 ms |
| ResNet 50 | 3.85 ms | 3.27 ms |
| Inception V4 | 15.15 ms | 11.62 ms |
| DeepLab V3 | 10.98 ms | 10.72 ms |
| YOLO V3 | 12.64 ms | 10.57 ms |
| REAL-ESRGAN | 211.76 ms | 200.40 ms |
| NPU Times | ||
| AI Computer Vision Overall Score (higher is better) | 1,761 | 1,773 |
| MobileNet V3 | 0.27 ms | 0.27 ms |
| ResNet 50 | 0.83 ms | 0.82 ms |
| Inception V4 | 1.72 ms | 1.71 ms |
| DeepLab V3 | 4.31 ms | 4.22 ms |
| YOLO V3 | 3.17 ms | 3.15 ms |
| REAL-ESRGAN | 100.05 ms | 100.83 ms |
UL Procyon: AI Text Generation
The Procyon AI Text Generation Benchmark streamlines AI LLM performance testing by providing a concise and consistent evaluation method. It allows for repeated testing across multiple LLM models while minimizing the complexity of large model sizes and variable factors. Developed with AI hardware leaders, it optimizes the use of local AI accelerators for more reliable and efficient performance assessments. The results measured below were tested using TensorRT.
After completing AI text generation tests, the results show a consistent pattern where the HP Z2 Mini G1a performs slightly ahead of the HP ZBook Ultra G1a, though the differences remain modest. In the Phi benchmark, for instance, the Z2 Mini achieved an overall score of 965 compared to the ZBook’s 922. The time to first token was nearly identical, measured at 1.898 seconds for the Z2 Mini and 1.956 seconds for the ZBook. Output tokens per second were similarly close, at 68.967 and 64.986, respectively. These figures suggest that while the Z2 Mini processes tasks marginally faster, both systems offer comparable responsiveness during inference.
This trend continues in the Mistral and Llama3 tests. The Z2 Mini scored 850 and 766, while the ZBook posted 829 and 756. Output speed and token latency followed suit with similarly close margins. These consistent results indicate that both systems deliver similar performance levels, particularly when running mid-sized models under real-world conditions.
The Llama2 test produced the closest set of results overall. The Z2 Mini recorded a score of 936 with a time to first token of 3.813 seconds, while the ZBook achieved 929 with a time of 3.860 seconds. The small gap between these results reinforces how closely matched the systems are when handling modern AI workloads.
Overall, the Z2 Mini consistently places slightly ahead in each test, but the data shows that both systems perform nearly on par when running LLMs using TensorRT. These differences may be evident in synthetic benchmarks, but are unlikely to result in meaningful performance gaps in most usage scenarios.
| UL Procyon: AI Text Generation | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
| Phi Overall Score | 965 | 922 |
| Phi Output Time To First Token | 1.898 seconds | 1.956 seconds |
| Phi Output Tokens Per Second | 68.967 tokens/s | 64.986 tokens/s |
| Phi Overall Duration | 52.666 seconds | 55.501 seconds |
| Mistral Overall Score | 850 | 829 |
| Mistral Output Time To First Token | 2.734 seconds | 2.783 seconds |
| Mistral Output Tokens Per Second | 43.358 tokens/s | 41.992 tokens/s |
| Mistral Overall Duration | 81.716 seconds | 84.065 seconds |
| Llama3 Overall Score | 766 | 756 |
| Llama3 Output Time To First Token | 2.545 seconds | 2.578 seconds |
| Llama3 Output Tokens Per Second | 36.752 tokens/s | 36.243 tokens/s |
| Llama3 Overall Duration | 91.987 seconds | 93.200 seconds |
| Llama2 Overall Score | 936 | 929 |
| Llama2 Output Time To First Token | 3.813 seconds | 3.860 seconds |
| Llama2 Output Tokens Per Second | 24.685 tokens/s | 24.619 tokens/s |
| Llama2 Overall Duration | 136.077 seconds | 136.720 seconds |
UL Procyon: AI Image Generation
The Procyon AI Image Generation Benchmark provides a consistent and accurate method for measuring AI inference performance across various hardware, ranging from low-power NPUs to high-end GPUs. It includes three tests: Stable Diffusion XL (FP16) for high-end GPUs, Stable Diffusion 1.5 (FP16) for moderately powerful GPUs, and Stable Diffusion 1.5 (INT8) for low-power devices. The benchmark uses the optimal inference engine for each system, ensuring fair and comparable results.
To simulate real-world usage, the benchmark generates images from a standardized set of text prompts, creating a consistent text-to-image AI workload across all devices. Each test provides key performance metrics, including an overall score, total generation time, and image generation speed, enabling simple and effective comparison between models and hardware configurations.
Both the HP Z2 Mini G1a and the HP ZBook Ultra G1a were able to run two of the three image generation tests included in the Procyon AI Image Generation Benchmark. Specifically, both systems completed Stable Diffusion 1.5 using FP16 precision and the more demanding Stable Diffusion XL FP16 test. The INT8 version of Stable Diffusion 1.5 was not supported on either configuration.
In the Stable Diffusion 1.5 FP16 test, the Z2 Mini completed the workload with an overall score of 725, a total generation time of 137.815 seconds, and an image generation speed of 8.613 seconds per image. The ZBook produced comparable results, with an overall score of 648, a total time of 154.203 seconds, and 9.638 seconds per image. These figures suggest that the Z2 Mini maintains a modest lead in processing efficiency, even though both systems share the same Ryzen AI Max+ PRO 395 processor and Radeon 8060S GPU.
A similar pattern appears in the Stable Diffusion XL FP16 test. The Z2 Mini achieved an overall score of 570 and completed the benchmark in 1,052.468 seconds, generating images at 65.779 seconds per image. The ZBook, in comparison, finished with a score of 451 and a total time of 1,329.592 seconds, with an image speed of 83.100 seconds per image. While both systems are capable of handling these larger models, the Z2 Mini consistently completes the tasks more quickly, reflecting slightly more optimized performance under identical hardware constraints.
| UL Procyon: AI Image Generation | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
| Stable Diffusion 1.5 (FP16) – Overall Score | 725 | 648 |
| Stable Diffusion 1.5 (FP16) – Overall Time | 137.815 seconds | 154.203 seconds |
| Stable Diffusion 1.5 (FP16) – Image Generation Speed | 8.613 s/image | 9.638 s/image |
| Stable Diffusion 1.5 (INT8) – Overall Score | N/A | N/A |
| Stable Diffusion 1.5 (INT8) – Overall Time | N/A | N/A |
| Stable Diffusion 1.5 (INT8) – Image Generation Speed | N/A | N/A |
| Stable Diffusion XL (FP16) – Overall Score | 570 | 451 |
| Stable Diffusion XL (FP16) – Overall Time | 1,052.468 seconds | 1,329.592 seconds |
| Stable Diffusion XL (FP16) – Image Generation Speed | 65.779 s/image | 83.100 s/image |
SPECworkstation 4
The SPECworkstation 4.0 benchmark is a comprehensive tool for evaluating all key aspects of workstation performance. It offers a real-world measure of CPU, graphics, accelerator, and disk performance, ensuring professionals have the data to make informed decisions about their hardware investments. The benchmark includes a dedicated set of tests focusing on AI and ML workloads, including data science tasks and ONNX runtime-based inference tests, reflecting the growing importance of AI/ML in workstation environments. It encompasses seven industry verticals and four hardware subsystems, providing a detailed and relevant measure of the performance of today’s workstations.
Results show that the Z2 Mini generally scores higher across most categories, reflecting a slight performance advantage in sustained workloads. In the Energy test, the Z2 Mini scored 2.50, compared to 2.20 for the ZBook. Financial Services showed a wider gap, with scores of 2.35 for the workstation and 1.60 for the laptop. Life Sciences followed a similar trend, with the Z2 Mini at 2.60 and the ZBook at 2.20. Media and Entertainment returned 2.22 and 1.90, while Product Design saw scores of 2.00 for the workstation and 1.74 for the laptop.
The only instance where the ZBook edged ahead was in Productivity and Development, where it recorded a score of 1.03 compared to the Z2 Mini’s 1.00. While these differences are not dramatic, they suggest that the Z2 Mini may deliver slightly more consistent throughput in workstation-class applications, even though both systems share the same processor and GPU.
| SPECworkstation 4.0.0 (Higher is better) |
HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
| Energy | 2.50 | 2.20 |
| Financial Services | 2.35 | 1.60 |
| Life Sciences | 2.60 | 2.20 |
| Media & Entertainment | 2.22 | 1.90 |
| Product Design | 2.00 | 1.74 |
| Productivity & Development | 1.00 | 1.03 |
Luxmark
Luxmark is a GPU benchmark that utilizes LuxRender, an open-source ray-tracing renderer, to evaluate a system’s performance in handling highly detailed 3D scenes. This benchmark is relevant for assessing the graphical rendering capabilities of servers and workstations, especially for visual effects and architectural visualization applications, where accurate light simulation is crucial.
Both the HP Z2 Mini G1a and the HP ZBook Ultra G1a performed well in this test, reflecting the strength of the Ryzen AI Max+ PRO 395 paired with the Radeon 8060S. In the Hallbench scene, the Z2 Mini achieved a score of 8,477, slightly ahead of the ZBook’s 7,833. Similarly, in the Food scene, the scores were 3,943 for the workstation and 3,915 for the laptop. These results show only minimal variance, suggesting both systems are well-suited for light to moderate 3D rendering workloads.
Notably, both devices benefit from flexible memory allocation, allowing dynamic sharing of RAM between CPU and GPU tasks. This capability contributes to their ability to handle rendering tasks efficiently, even in compact form factors typically not associated with intensive graphics performance.
| Luxmark (Higher is better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
| Hallbench | 8,477 | 7,833 |
| Food | 3,943 | 3,915 |
7-Zip Compression
The 7-Zip Compression Benchmark evaluates CPU performance during compression and decompression tasks, measuring ratings in GIPS (Giga Instructions Per Second) and CPU usage. Higher GIPS and efficient CPU usage indicate superior performance.
Focusing on the resulting ratings, both the HP Z2 Mini G1a and the HP ZBook Ultra G1a deliver strong, closely matched performance. During compression, the Z2 Mini achieved a resulting rating of 139.298 GIPS, slightly behind the ZBook’s 139.617 GIPS. In decompression, however, the Z2 Mini posted a higher resulting rating of 163.969 GIPS, compared to 174.046 GIPS on the ZBook.
Taking both workloads into account, the total resulting rating was 151.634 GIPS for the Z2 Mini and 156.832 GIPS for the ZBook. These results indicate that while both systems are highly capable of managing compression-heavy workflows, the ZBook has a slight advantage in overall throughput, particularly during decompression phases.
| 7-Zip Compression Benchmark (Higher is Better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) | |||
| Compressing | |||||
| Current CPU Usage | 2,734% | 2,868% | |||
| Current Rating/Usage | 5.136 GIPS | 4.883 GIPS | |||
| Current Rating | 140.405 GIPS | 140.061 GIPS | |||
| Resulting CPU Usage | 2,718% | 2,855% | |||
| Resulting Rating/Usage | 5.126 GIPS | 4.890 GIPS | |||
| Resulting Rating | 139.298 GIPS | 139.617 GIPS | |||
| Decompressing | |||||
| Current CPU Usage | 2,343% | 2,904% | |||
| Current Rating/Usage | 6.805 GIPS | 6.029 GIPS | |||
| Current Rating | 159.451 GIPS | 175.104 GIPS | |||
| Resulting CPU Usage | 2,414% | 2,887% | |||
| Resulting Rating/Usage | 6.793 GIPS | 6.028 GIPS | |||
| Resulting Rating | 163.969 GIPS | 174.046 GIPS | |||
| Total Rating | |||||
| Total CPU Usage | 2,566% | 2,871% | |||
| Total Rating/Usage | 5.959 GIPS | 5.459 GIPS | |||
| Total Rating | 151.634 GIPS | 156.832 GIPS | |||
Blackmagic RAW Speed Test
The Blackmagic RAW Speed Test is a performance benchmarking tool that measures a system’s capabilities for handling video playback and editing using the Blackmagic RAW codec. It evaluates how well a system can decode and play back high-resolution video files, providing frame rates for both CPU- and GPU-based processing.
In the 8K CPU test, the HP Z2 Mini G1a achieved 124 frames per second, outperforming the HP ZBook Ultra G1a, which scored 102 frames per second. This suggests a slight advantage for the workstation in raw CPU-based decoding tasks. However, the GPU-accelerated results using OpenCL show the opposite trend. The ZBook produced a slightly higher frame rate of 78 frames per second, compared to 74 frames per second on the Z2 Mini.
| Blackmagic RAW Speed Test | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
|---|---|---|
| 8K CPU | 124 FPS | 102 FPS |
| 8K OPENCL | 74 FPS | 78 FPS |
Blackmagic Disk Speed Test
The Blackmagic Disk Speed Test evaluates storage performance by measuring read and write speeds, providing insights into a system’s ability to handle data-intensive tasks, such as video editing and large file transfers.
The HP Z2 Mini G1a offers two PCIe Gen4 slots, with both being very easy to access and upgrade. The SSD performance may shift slightly depending on which part is sourced in your specific build.
| Disk Speed Test (higher is better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
| Read | 4,549.3 MB/s | 4,547.3 MB/s |
| Write | 5,344 MB/s | 4,264.8 MB/s |
Blender Benchmark
Blender is an open-source 3D modeling application. This benchmark was run using the Blender Benchmark utility. The score is measured in samples per minute, with higher values indicating better performance.
The HP Z2 Mini G1a consistently outperformed the HP ZBook Ultra G1a in all three tested scenes. In the Monster project, the Z2 Mini reached 224.3 samples per minute, compared to 189.29 on the ZBook. The Junkshop scene followed with 149.5 and 129.42 samples per minute, respectively. Finally, in the Classroom scene, the Z2 Mini processed 116.3 samples per minute, while the ZBook completed 94.14 samples per minute.
| Blender Benchmark CPU (Samples per minute, Higher is better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
| Monster | 224.3 samples/m | 189.29 samples/m |
| Junkshop | 149.5 samples/m | 129.42 samples/m |
| Classroom | 116.3 samples/m | 94.14 samples/m |
When shifting to GPU-based rendering using Blender’s OptiX engine, the results show a more balanced performance split between the two systems. In the Monster scene, the HP ZBook Ultra G1a rendered 661.50 samples per minute, slightly ahead of the Z2 Mini’s 616.1 samples per minute. This suggests a slight GPU-side advantage for the ZBook in this specific scene, despite identical Radeon 8060S graphics across both devices.
In the Junkshop and Classroom tests, however, the Z2 Mini regains a narrow lead. It achieved 350.6 and 342.7 samples per minute, respectively, while the ZBook scored 341.92 and 333.26 in the same scenes. These differences are relatively minor and fall within expected variance, indicating both systems deliver closely matched GPU rendering performance under OptiX.
| Blender Benchmark GPU (Samples per minute, Higher is better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
| Monster | 745.55 samples/m | 661.50 samples/m |
| Junkshop | 366.54 samples/m | 341.92 samples/m |
| Classroom | 359.01 samples/m | 333.26 samples/m |
y-cruncher
y-cruncher is a multithreaded and scalable program that can compute Pi and other mathematical constants to trillions of digits. Since its launch in 2009, it has become a popular benchmarking and stress-testing application for overclockers and hardware enthusiasts.
The HP Z2 Mini G1a metrics are consistent with the HP ZBook Ultra G1a 14″. The workstation offered a subtle edge across all the computational increments, starting with the 1-billion-size test measuring 12.965 seconds. In both the 2.5-billion and 5-billion tests, the gap widens by a couple of seconds. The results of 34.533 s for 2.5 billion and 75.021 seconds for 5 billion are solid. When the workstation completed the 10-billion-digits portion, it pulled out ahead with a 160.252-second completion time, which ended up 11 seconds faster than the ZBook, primarily due to slight power limitations on the laptop.
| Y-Cruncher (Total Computation Time) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
|---|---|---|
| 1 Billion | 12.965 seconds | 12.93 seconds |
| 2.5 Billion | 34.533 seconds | 34.91 seconds |
| 5 Billion | 75.021 seconds | 78.19 seconds |
| 10 Billion | 160.252 seconds | 171.72 seconds |
Geekbench 6
Geekbench 6 is a cross-platform benchmark that measures overall system performance.
The results from the HP Z2 Mini G1a are no surprise here. CPU scores are nearly identical to the laptop at 2,862 Single-Core and 12,210 Multi-Core. For similar reasons as previously talked about, the GPU OpenCL score trended higher at 91,591. Provided scores suggest CPU-heavy tasks will not be an issue for this system. As for the GPU, Radeon 8060S integrated graphics are comparable to new graphics cards from around 2019, great for mini workstations.
| Geekbench 6 (Higher is better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
|---|---|---|
| CPU Single-Core | 2,862 | 2,825 |
| CPU Multi-Core | 17,210 | 17,562 |
| GPU OpenCL | 91,591 | 85,337 |
Cinebench R23
Cinebench R23 is a widely recognized benchmark for evaluating CPU performance in 3D rendering workloads. Using the Cinema 4D engine, it measures how well a processor handles both single-threaded and multithreaded tasks, offering insight into overall responsiveness and parallel processing capabilities.
In the multi-core test, the HP Z2 Mini G1a posted a score of 37,156, significantly ahead of the HP ZBook Ultra G1a, which scored 29,112. This suggests the Z2 Mini is better equipped to sustain heavier, multithreaded rendering workloads, likely due to more favorable thermal conditions in its chassis.
For single-core performance, the two systems delivered nearly identical results. The Z2 Mini scored 2,020 while the ZBook followed closely with 1,984. These figures indicate that both devices offer similar performance in lightly threaded tasks such as viewport interaction or basic modeling operations.
| Cinebench R23 (Higher is better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
|---|---|---|
| Multi-Core | 37,156 | 29,112 |
| Single-Core | 2,020 | 1,984 |
Cinebench 2024
Cinebench 2024 builds on the foundation of R23 by introducing GPU-based rendering tests alongside its continued focus on CPU performance. For this segment, we examine only the CPU scores, which provide updated insight into how well each system handles modern 3D rendering tasks.
In the multi-core test, the HP Z2 Mini G1a scored 1,906, outperforming the HP ZBook Ultra G1a’s score of 1,579. This follows the same pattern seen in R23, where the Z2 Mini demonstrated more efficient multithreaded throughput, likely benefiting from better sustained performance under load.
Single-core results were nearly identical. The Z2 Mini recorded 112 points, while the ZBook finished just one point behind at 111. This suggests similar performance for tasks that rely on individual threads, such as light editing or real-time application interactions.
| Cinebench 2024 (Higher is better) | HP Z2 Mini G1a (Ryzen AI Max+ PRO 395 | Radeon 8060S) | HP ZBook Ultra G1a 14″ (Ryzen AI Max+ PRO 395 | Radeon 8060S) |
|---|---|---|
| Multi-Core | 1,906 | 1,579 |
| Single-Core | 112 | 111 |
Ollama Gemma3 LLM Performance
To evaluate how the HP Z2 Mini G1a handles large language model (LLM) inference under real-world workloads, we used Ollama with a prompt designed to analyze the performance sections of this review. The models tested span from 1.5B up to 70B parameters, with Gemma3 variants used where applicable. This workload stresses both GPU and CPU resources, especially with long prompt sequences that challenge memory capacity, inference throughput, and compute stability.
Smaller models such as Ollama 1.5B and 7B executed quickly, completing in 4.76 and 36.65 seconds, respectively. Prompt evaluation for both was efficient, with token processing rates of 716.99 tokens per second for the 1.5B model and 799.29 tokens per second for the 7B. However, the output evaluation rate drops as model size increases. At 1.5B, output tokens were generated at 112.18 tokens per second, while the 7B model completed at 36.86 tokens per second.
As expected, performance scales down with increasing model size. The 14B model took nearly 65 seconds to complete, with generation speed slowing to 18.90 tokens per second. The 32B model saw a more significant slowdown, taking 94.29 seconds total and producing output at 9.38 tokens per second. The most computationally demanding test, the 70B model, required 164.73 seconds and generated tokens at just 4.24 tokens per second.
While initial prompt evaluation remains efficient across all sizes due to KV caching optimizations, total generation time and token output rates degrade predictably as model size and memory demands increase. The HP Z2 Mini G1a demonstrates it can scale up to the 70B tier, but users should expect noticeable slowdowns in responsiveness beyond 14B for long or complex prompts.
| Ollama 1.5B | Total Duration (s) | Load Duration (ms) | Prompt Eval Count (tokens) | Prompt Eval Duration (ms) | Prompt Eval Rate | Eval Count (tokens) | Eval Duration (s) | Eval Rate |
|---|---|---|---|---|---|---|---|---|
| HP Z2 Mini g1a | 4.76 s | 17.21 ms | 22 | 30.68 ms | 716.99 tk/s | 528 | 4.71 s | 112.18 tk/s |
| Ollama 7B | ||||||||
| HP Z2 Mini g1a | 36.65 s | 18.21 ms | 22 | 27.52 ms | 799.29 tk/s | 1349 | 36.06 s | 36.86 tk/s |
| Ollama 14B | ||||||||
| HP Z2 Mini g1a | 64.97 s | 18.66 ms | 22 | 28.41 ms | 774.37 tk/s | 1227 | 64.92 s | 18.90 tk/s |
| Ollama 32B | ||||||||
| HP Z2 Mini g1a | 94.29 s | 73.83 ms | 22 | 69.27 ms | 317.61 tk/s | 883 | 94.14 s | 9.38 tk/s |
| Ollama 70B | ||||||||
| HP Z2 Mini g1a | 164.73 s | 21.97 ms | 22 | 38.90 ms | 565.52 tk/s | 699 | 164.67 s | 4.24 tk/s |
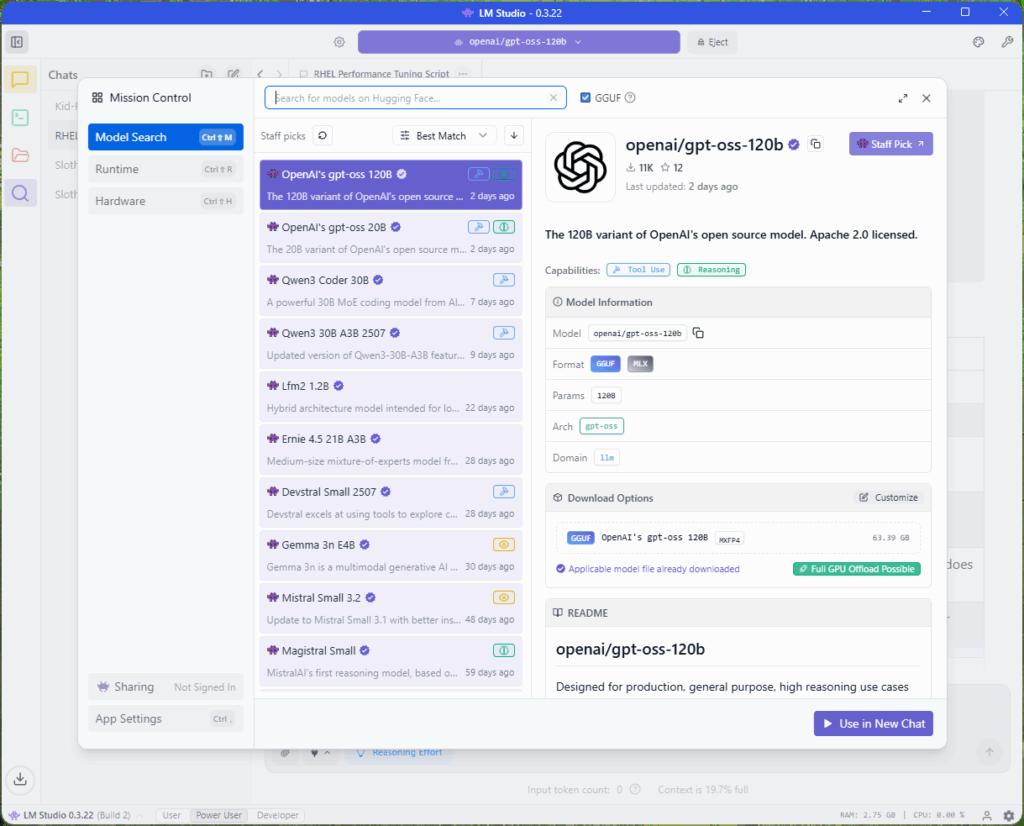
Support for OpenAI’s New GPT-OSS 120B Model
A few days ago, OpenAI released its first open-source LLM releases in a long time: the GPT-OSS 120B and 20B models. The GPT-OSS 120B represents a breakthrough as one of the first models natively trained with MXFP4 quantization. According to OpenAI, the models undergo post-training with MoE weight quantization to MXFP4 format, reducing weights to just 4.25 bits per parameter. Since MoE weights constitute over 90% of the total parameter count, this aggressive quantization enables the 120B model to fit on a single 80GB H100 GPU or, in our case, the Ryzen AI Max+ PRO 395 with its 96GB of shared memory. This alignment with industry trends is particularly significant, as lower-precision Mixture of Experts models become increasingly prevalent, allowing devices with lower compute to still deliver outstanding performance in inference.
This native MXFP4 training also provides a crucial advantage. When further quantizing to Int4 for deployment on the AI Max+ PRO 395, the quality degradation is minimal compared to the substantial losses typically seen when quantizing from BF16 to Int4. The result is that GPT-OSS 120B stands as one of the best-performing models you can run on the AI Max+ PRO 395, delivering near-full quality.
By leveraging this lower-precision architecture trend, the Z2 Mini G1a transforms what would traditionally require enterprise-grade hardware costing three times as much (like the NVIDIA RTX 6000 Pro with 96GB VRAM) into an accessible workstation solution for large-scale LLM experimentation.
As shown in LM Studio, the system detects the Radeon 8060S GPU with 96GB of VRAM and confirms compatibility for model execution. The configuration also supports offloading KV cache to GPU memory, further enhancing inference efficiency for long prompts or extended conversations. With OpenAI’s strict model guardrails enabled, the system remains protected against overload, even during heavy LLM workloads.
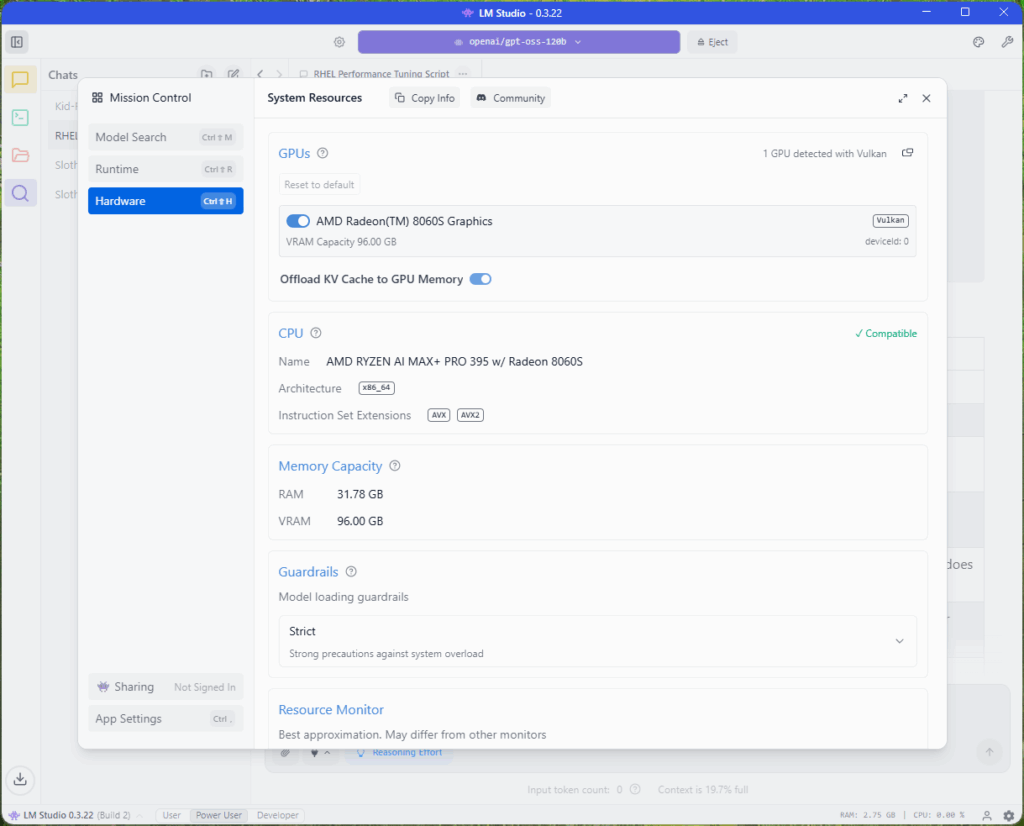
Our installed runtime extension packs include ROCm llama.cpp (Windows), Vulkan llama.cpp (Windows), CPU llama.cpp (Windows), and the Harmony framework. CUDA is also listed but not usable, as it requires an NVIDIA GPU, and the system is equipped with an AMD Radeon 8060S.
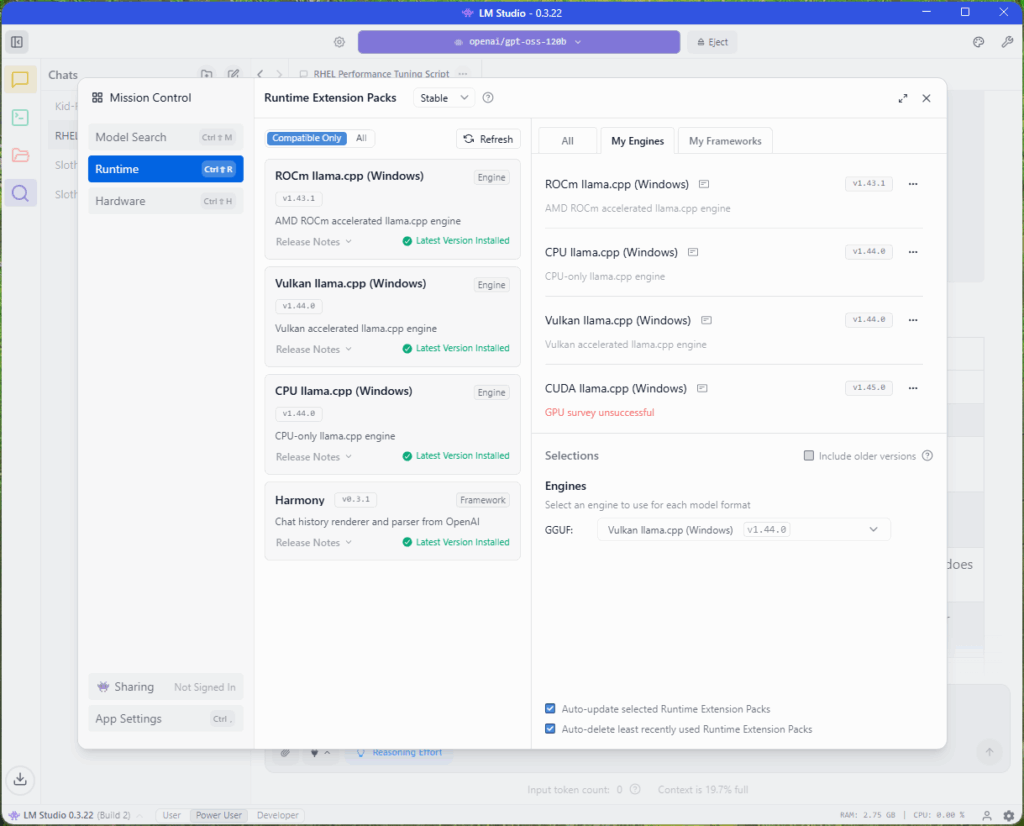
For this run, the image below shows the OpenAI GPT OSS 120B model referenced earlier, along with its format, architecture, and size. It uses the GGUF format, has a total size of 63.39 GB, and is configured for full GPU offload.
In terms of use, the HP Z2 Mini G1a was surprisingly performant using the 120B parameter model, maintaining a rate close to 40 tokens/sec. We worked through several detailed conversations with the LLM. The quality of the responses was much better than using smaller models, which many systems are limited to due to VRAM constraints.
Looking at the system stats with the LLM running, we saw the GPU consuming just below 100W of power, and temperatures stayed in check at 51-54 °C across the GPU and CPU.
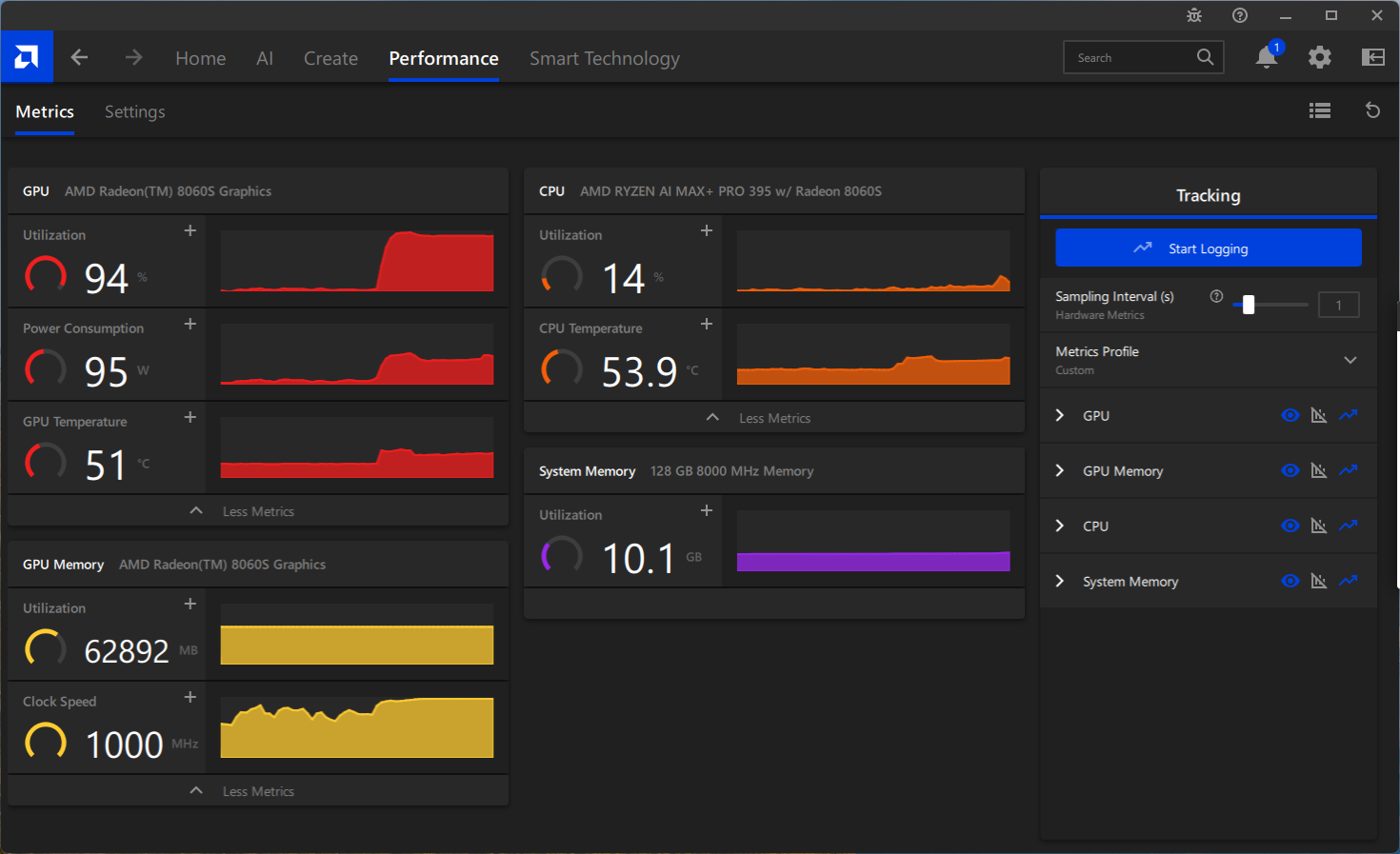
Conclusion
The HP Z2 Mini G1a is one of the most surprising systems we’ve tested this year. On paper, it looks like a compact desktop with integrated graphics. In practice, this small workstation consistently delivers performance well beyond expectations, especially when it comes to AI workloads. At a street price around $3,300, it competes with much larger and more expensive systems, including those equipped with high-end discrete GPUs.
This system also gives us a chance to revisit the HP ZBook Ultra G1a 14-inch laptop we reviewed earlier this year. At that time, we were frustrated by its high price and lackluster performance, particularly in AI-focused tasks. Despite using similar AMD hardware, the laptop struggled with inferencing, and we emphasized that the AI performance fell short of marketing claims. We walked away unimpressed.
What a difference a few months and a serious software update can make. Thanks to AMD’s continued work on their drivers and runtime support, the Ryzen AI Max+ Pro 395 now performs as we had hoped. With 128GB of shared memory and up to 96GB available as VRAM, the Z2 Mini G1a can run massive local models like OpenAI’s GPT-OSS 120B with surprising ease. That kind of capability used to require a $10,000 workstation with an RTX 6000 or similar GPU. Now, it fits in a compact chassis at a fraction of the cost.
HP deserves praise for more than just component choices. The Z2 Mini G1a is thoughtfully designed with strong thermal performance, excellent port flexibility, and optional features like Flex IO and HP ZCentral Remote Boost that add meaningful value in professional environments.
This system resets expectations for what a small-form-factor workstation can deliver. It combines impressive local AI performance, intelligent design, and a price that feels almost too good to be true. For that reason, the HP Z2 Mini G1a earns our Editor’s Choice award. It is that good.



 Amazon
Amazon